 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControl Synthesis of Cyber-Physical Systems for Real-Time Specifications through Causation-Guided Reinforcement Learning
Oct 09, 2025In real-time and safety-critical cyber-physical systems (CPSs), control synthesis must guarantee that generated policies meet stringent timing and correctness requirements under uncertain and dynamic conditions. Signal temporal logic (STL) has emerged as a powerful formalism of expressing real-time constraints, with its semantics enabling quantitative assessment of system behavior. Meanwhile, reinforcement learning (RL) has become an important method for solving control synthesis problems in unknown environments. Recent studies incorporate STL-based reward functions into RL to automatically synthesize control policies. However, the automatically inferred rewards obtained by these methods represent the global assessment of a whole or partial path but do not accumulate the rewards of local changes accurately, so the sparse global rewards may lead to non-convergence and unstable training performances. In this paper, we propose an online reward generation method guided by the online causation monitoring of STL. Our approach continuously monitors system behavior against an STL specification at each control step, computing the quantitative distance toward satisfaction or violation and thereby producing rewards that reflect instantaneous state dynamics. Additionally, we provide a smooth approximation of the causation semantics to overcome the discontinuity of the causation semantics and make it differentiable for using deep-RL methods. We have implemented a prototype tool and evaluated it in the Gym environment on a variety of continuously controlled benchmarks. Experimental results show that our proposed STL-guided RL method with online causation semantics outperforms existing relevant STL-guided RL methods, providing a more robust and efficient reward generation framework for deep-RL.
Dynamic Predictive Sampling Analog to Digital Converter for Sparse Signal Sensing
Nov 17, 2022This paper presents a dynamic predictive sampling (DPS) based analog-to-digital converter (ADC) that provides a non-uniform sampling of input analog continuous-time signals. The processing unit generates a dynamic prediction of the input signal using two prior-quantized samplings to compute digital values of an upper threshold and a lower threshold. The digital threshold values are converted to analog thresholds to form a tracking window. A comparator compares the input analog signal with the tracking window to determine if the prediction is successful. A counter records timestamps between the unsuccessful predictions, which are the selected sampling points for quantization. No quantization is performed for successfully predicted sampling points so that the data throughput and power can be saved. The proposed circuits were designed as a 10-bit ADC using 0.18 micro CMOS process sampling at 1 kHz. The results show that the proposed system can achieve a data compression factor of 6.17 and a power saving factor of 31% compared to a Nyquist rate SAR ADC for ECG monitoring.
Fully Digital Second-order Level-crossing Sampling ADC for Data Saving in Sensing Sparse Signals
Nov 17, 2022This paper presents a fully integrated second-order level-crossing sampling data converter for real-time data compression and feature extraction. Compared with level-sampling ADCs which sample at fixed voltage levels, the proposed circuits updates tracking thresholds using linear extrapolation, which forms a second-order level-crossing sampling ADC that has sloped sampling levels. The computing is done digitally and is implemented by modifying the digital control logic of a conventional SAR ADC. The system selects only the turning points in the input waveform for quantization. The output of the proposed data converter consists of both the digital value of the selected sampling points and the timestamp between the selected sampling points. The main advantages are data savings and power savings for the data converter and the following digital signal processing or communication circuits, which are ideal for low-power sensors. The test chip was fabricated using a 180nm CMOS process. The proposed ADC saves 30% compared to a conventional SAR ADC and achieves a compression factor of 6.17 for tracking ECG signals.
WeightMom: Learning Sparse Networks using Iterative Momentum-based pruning
Aug 11, 2022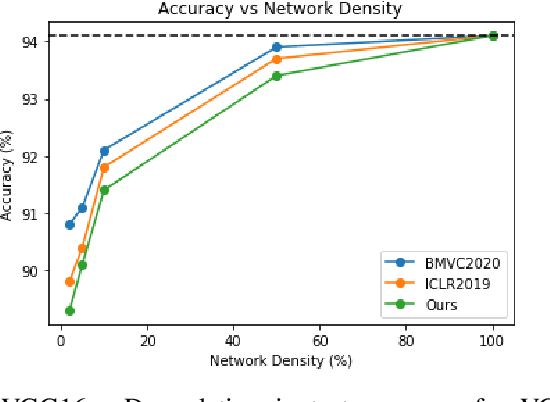
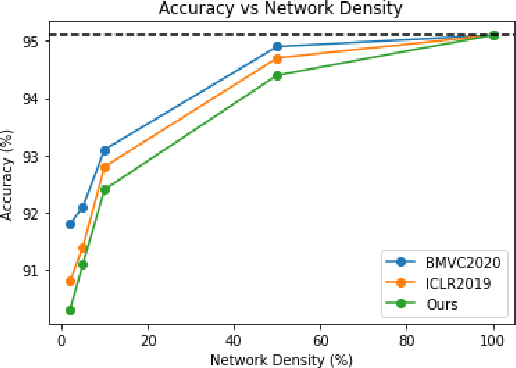
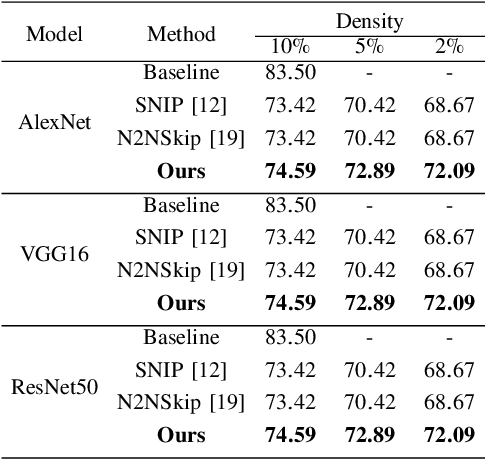
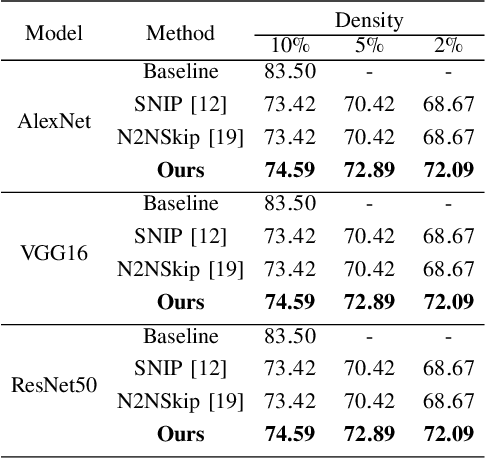
Deep Neural Networks have been used in a wide variety of applications with significant success. However, their highly complex nature owing to comprising millions of parameters has lead to problems during deployment in pipelines with low latency requirements. As a result, it is more desirable to obtain lightweight neural networks which have the same performance during inference time. In this work, we propose a weight based pruning approach in which the weights are pruned gradually based on their momentum of the previous iterations. Each layer of the neural network is assigned an importance value based on their relative sparsity, followed by the magnitude of the weight in the previous iterations. We evaluate our approach on networks such as AlexNet, VGG16 and ResNet50 with image classification datasets such as CIFAR-10 and CIFAR-100. We found that the results outperformed the previous approaches with respect to accuracy and compression ratio. Our method is able to obtain a compression of 15% for the same degradation in accuracy on both the datasets.