 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Complete Solution for Vehicle Re-ID in Surround-view Camera System
Dec 08, 2022
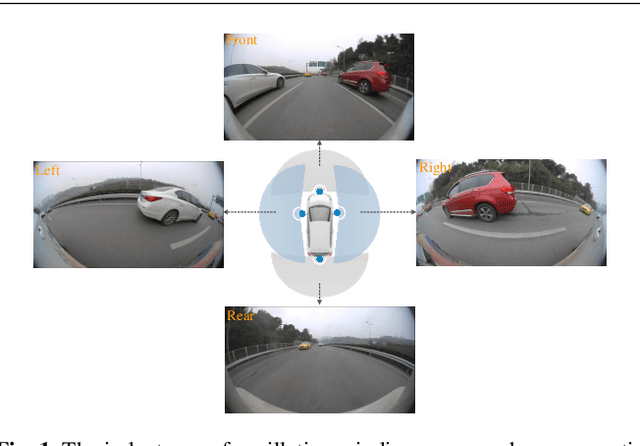


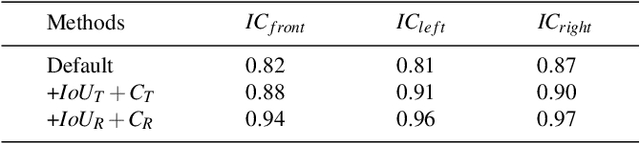
Vehicle re-identification (Re-ID) is a critical component of the autonomous driving perception system, and research in this area has accelerated in recent years. However, there is yet no perfect solution to the vehicle re-identification issue associated with the car's surround-view camera system. Our analysis identifies two significant issues in the aforementioned scenario: i) It is difficult to identify the same vehicle in many picture frames due to the unique construction of the fisheye camera. ii) The appearance of the same vehicle when seen via the surround vision system's several cameras is rather different. To overcome these issues, we suggest an integrative vehicle Re-ID solution method. On the one hand, we provide a technique for determining the consistency of the tracking box drift with respect to the target. On the other hand, we combine a Re-ID network based on the attention mechanism with spatial limitations to increase performance in situations involving multiple cameras. Finally, our approach combines state-of-the-art accuracy with real-time performance. We will soon make the source code and annotated fisheye dataset available.
* 11 pages, 10 figures. arXiv admin note: substantial text overlap with arXiv:2006.16503
Lecture notes on the design of low-pass digital filters with wireless-communication applications
Nov 14, 2022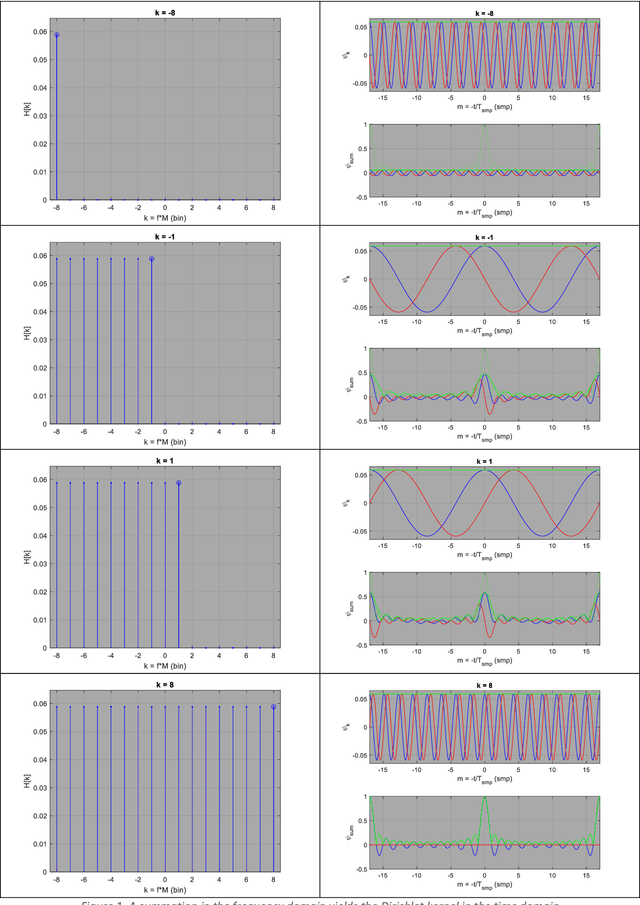
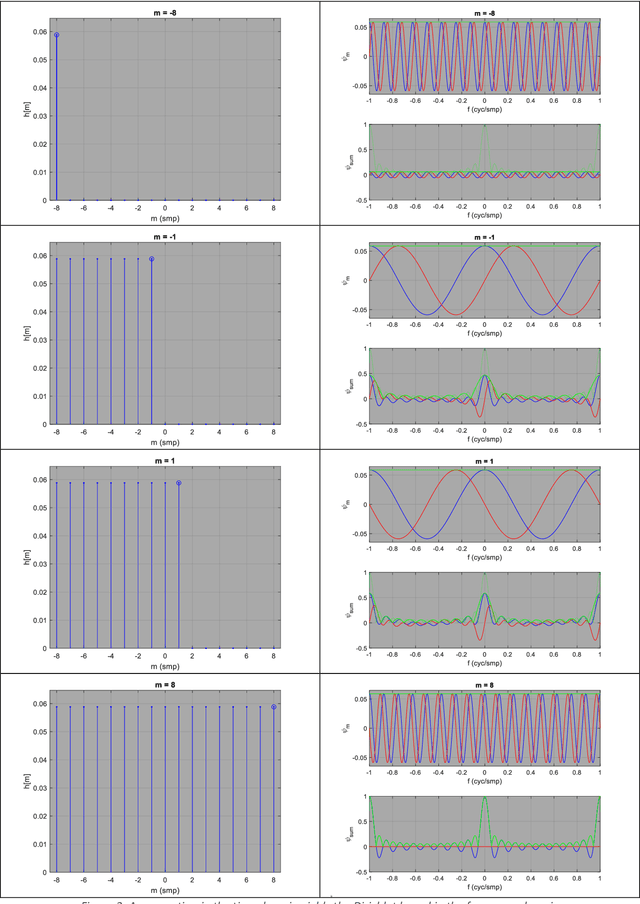
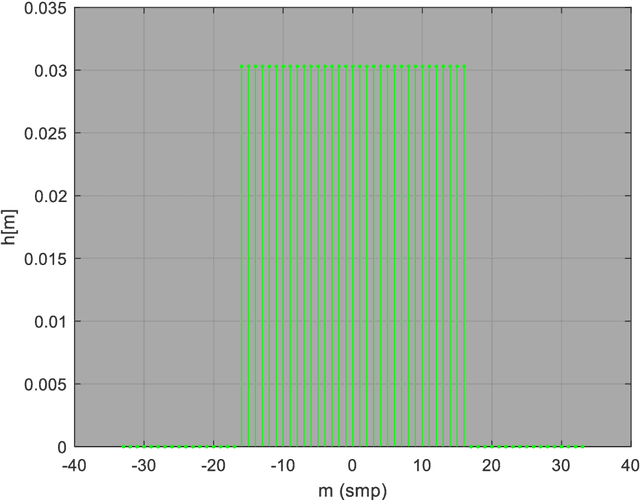
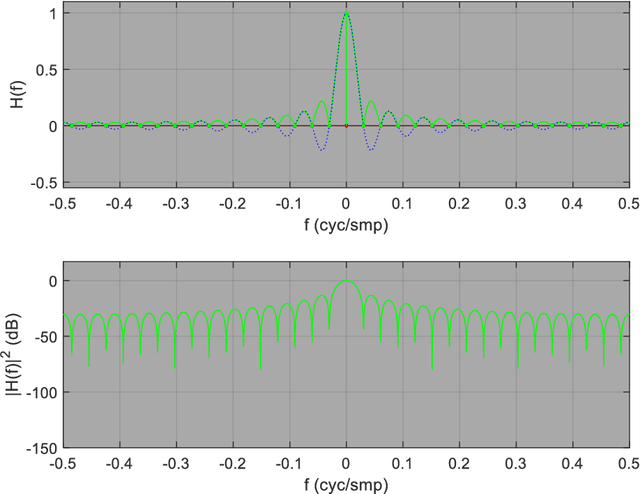
The low-pass filter is a fundamental building block from which digital signal-processing systems (e.g. radio and radar) are built. Signals in the electromagnetic spectrum extend over all timescales/frequencies and are used to transmit and receive very long or very short pulses of very narrow or very wide bandwidth. Time/Frequency agility is the key for optimal spectrum utilization (i.e. to suppress interference and enhance propagation) and low-pass filtering is the low-level digital mechanism for manoeuvre in this domain. By increasing and decreasing the bandwidth of a low-pass filter, thus decreasing and increasing its pulse duration, the engineer may shift energy concentration between frequency and time. Simple processes for engineering such components are described and explained below. These lecture notes are part of a short course that is intended to help recent engineering graduates design low-pass digital filters for this purpose, who have had some exposure to the topic during their studies, and who are now interested in the sending and receiving signals over the electromagnetic spectrum, in wireless communication (i.e. radio) and remote sensing (e.g. radar) applications, for instance. The best way to understand the material is to interact with the spectrum using receivers and or transmitters and software-defined radio development-kits provide a convenient platform for experimentation. Fortunately, wireless communication in the radio-frequency spectrum is an ideal application for the illustration of waveform agility in the electromagnetic spectrum. In Parts I and II, the theoretical foundations of digital low-pass filters are presented, i.e. signals-and-systems theory, then in Part III they are applied to the problem of radio communication and used to concentrate energy in time or frequency.
Temporal Modeling Matters: A Novel Temporal Emotional Modeling Approach for Speech Emotion Recognition
Nov 14, 2022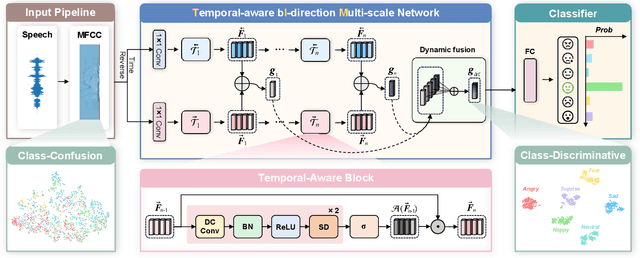
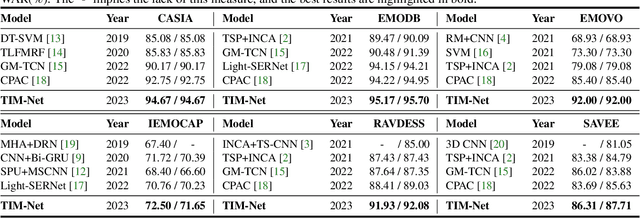


Speech emotion recognition (SER) plays a vital role in improving the interactions between humans and machines by inferring human emotion and affective states from speech signals. Whereas recent works primarily focus on mining spatiotemporal information from hand-crafted features, we explore how to model the temporal patterns of speech emotions from dynamic temporal scales. Towards that goal, we introduce a novel temporal emotional modeling approach for SER, termed Temporal-aware bI-direction Multi-scale Network (TIM-Net), which learns multi-scale contextual affective representations from various time scales. Specifically, TIM-Net first employs temporal-aware blocks to learn temporal affective representation, then integrates complementary information from the past and the future to enrich contextual representations, and finally, fuses multiple time scale features for better adaptation to the emotional variation. Extensive experimental results on six benchmark SER datasets demonstrate the superior performance of TIM-Net, gaining 2.34% and 2.61% improvements of the average UAR and WAR over the second-best on each corpus. Remarkably, TIM-Net outperforms the latest domain-adaptation method on the cross-corpus SER tasks, demonstrating strong generalizability.
Easy Guided Decoding in Providing Suggestions for Interactive Machine Translation
Nov 14, 2022
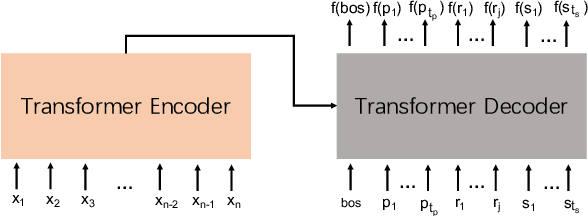


Fully machine translation scarcely guarantees error-free results. Humans perform post-editing on machine generated translations to correct errors in the scenario of computer aided translation. In favor of expediting the post-editing process, recent works have investigated machine translation in an interactive mode, where machines can automatically refine the rest of translations constrained on human's edits. In this paper, we utilize the parameterized objective function of neural machine translation and propose an easy constrained decoding algorithm to improve the translation quality without additional training. We demonstrate its capability and time efficiency on a benchmark dataset, WeTS, where it conditions on humans' guidelines by selecting spans with potential errors. In the experimental results, our algorithm is significantly superior to state-of-the-art lexically constrained decoding method by an increase of 10.37 BLEU in translation quality and a decrease of 63.4% in time cost on average. It even outperforms the benchmark systems trained with a large amount of annotated data on WeTS in English-German and German-English.
Joint Jammer Mitigation and Data Detection for Smart, Distributed, and Multi-Antenna Jammers
Nov 14, 2022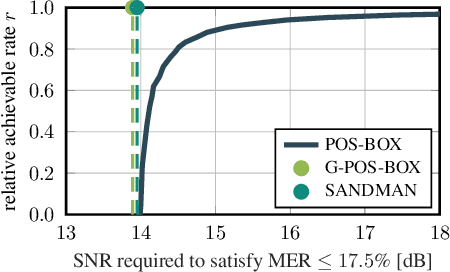
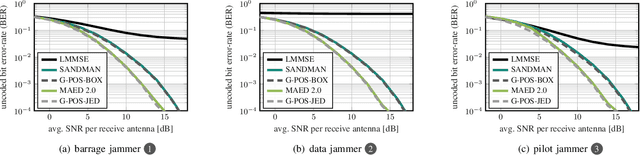
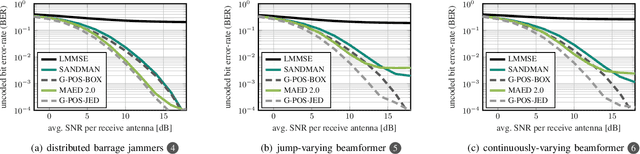
Multi-antenna (MIMO) processing is a promising solution to the problem of jammer mitigation. Existing methods mitigate the jammer based on an estimate of its subspace (or receive statistics) acquired through a dedicated training phase. This strategy has two main drawbacks: (i) it reduces the communication rate since no data can be transmitted during the training phase and (ii) it can be evaded by smart or multi-antenna jammers that are quiet during the training phase or that dynamically change their subspace through time-varying beamforming. To address these drawbacks, we propose Joint jammer Mitigation and data Detection (JMD), a novel paradigm for MIMO jammer mitigation. The core idea is to estimate and remove the jammer interference subspace jointly with detecting the transmit data over multiple time slots. Doing so removes the need for a dedicated and rate-reducing training period while mitigating smart and dynamic multi-antenna jammers. We instantiate our paradigm with SANDMAN, a simple and practical algorithm for multi-user MIMO uplink JMD. Extensive simulations demonstrate the efficacy of JMD, and of SANDMAN in particular, for jammer mitigation.
A Comparison of Automatic Labelling Approaches for Sentiment Analysis
Nov 05, 2022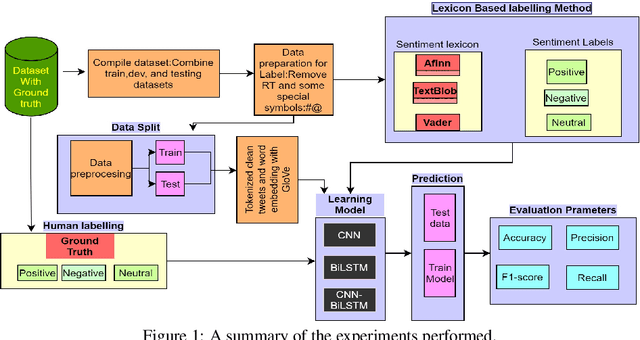

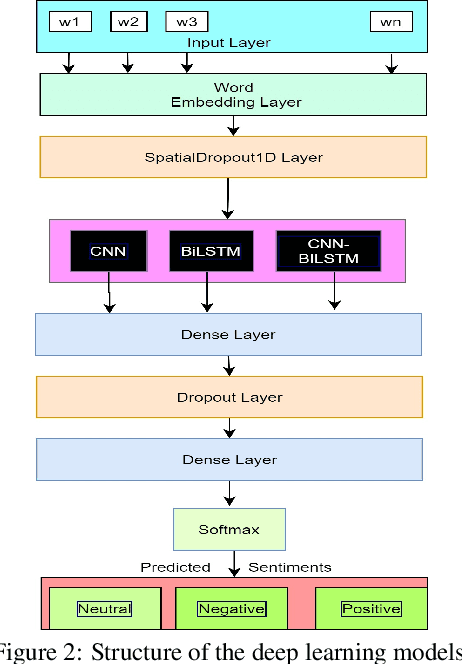

Labelling a large quantity of social media data for the task of supervised machine learning is not only time-consuming but also difficult and expensive. On the other hand, the accuracy of supervised machine learning models is strongly related to the quality of the labelled data on which they train, and automatic sentiment labelling techniques could reduce the time and cost of human labelling. We have compared three automatic sentiment labelling techniques: TextBlob, Vader, and Afinn to assign sentiments to tweets without any human assistance. We compare three scenarios: one uses training and testing datasets with existing ground truth labels; the second experiment uses automatic labels as training and testing datasets; and the third experiment uses three automatic labelling techniques to label the training dataset and uses the ground truth labels for testing. The experiments were evaluated on two Twitter datasets: SemEval-2013 (DS-1) and SemEval-2016 (DS-2). Results show that the Afinn labelling technique obtains the highest accuracy of 80.17% (DS-1) and 80.05% (DS-2) using a BiLSTM deep learning model. These findings imply that automatic text labelling could provide significant benefits, and suggest a feasible alternative to the time and cost of human labelling efforts.
Direct deduction of chemical class from NMR spectra
Nov 06, 2022
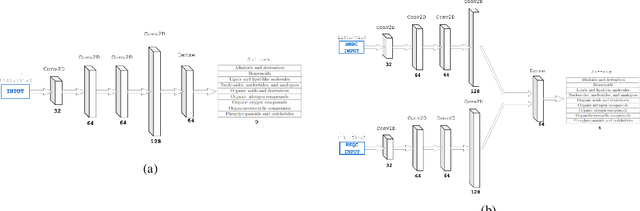
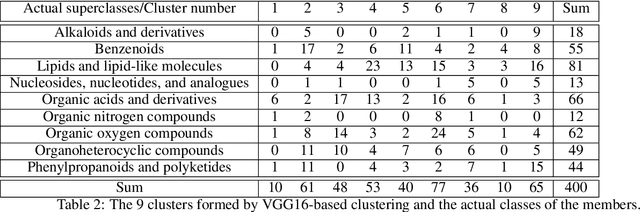

This paper presents a proof-of-concept method for classifying chemical compounds directly from NMR data without doing structure elucidation. This can help to reduce time in finding good structure candidates, as in most cases matching must be done by a human engineer, or at the very least a process for matching must be meaningfully interpreted by one. Therefore, for a long time automation in the area of NMR has been actively sought. The method identified as suitable for the classification is a convolutional neural network (CNN). Other methods, including clustering and image registration, have not been found suitable for the task in a comparative analysis. The result shows that deep learning can offer solutions to automation problems in cheminformatics.
A Dynamic Meta-Learning Model for Time-Sensitive Cold-Start Recommendations
Apr 03, 2022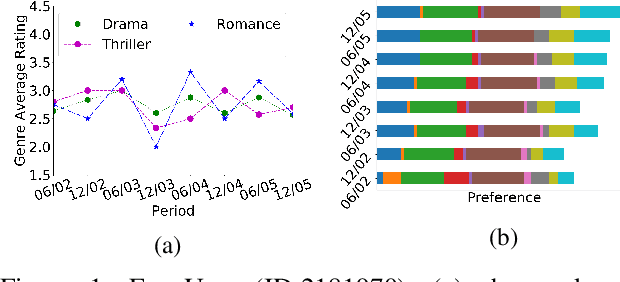
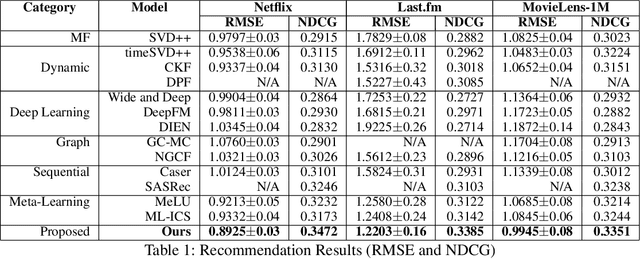
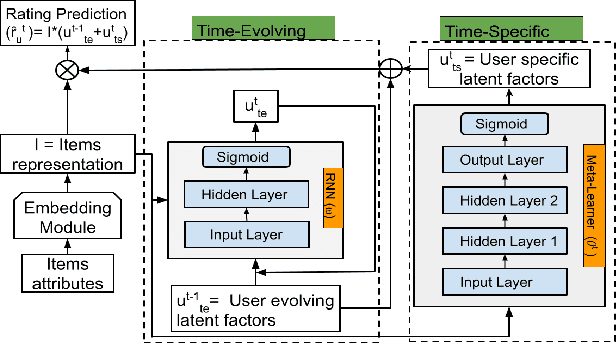
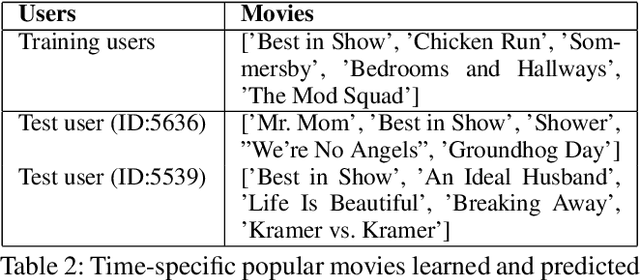
We present a novel dynamic recommendation model that focuses on users who have interactions in the past but turn relatively inactive recently. Making effective recommendations to these time-sensitive cold-start users is critical to maintain the user base of a recommender system. Due to the sparse recent interactions, it is challenging to capture these users' current preferences precisely. Solely relying on their historical interactions may also lead to outdated recommendations misaligned with their recent interests. The proposed model leverages historical and current user-item interactions and dynamically factorizes a user's (latent) preference into time-specific and time-evolving representations that jointly affect user behaviors. These latent factors further interact with an optimized item embedding to achieve accurate and timely recommendations. Experiments over real-world data help demonstrate the effectiveness of the proposed time-sensitive cold-start recommendation model.
Analysis and application of multispectral data for water segmentation using machine learning
Dec 16, 2022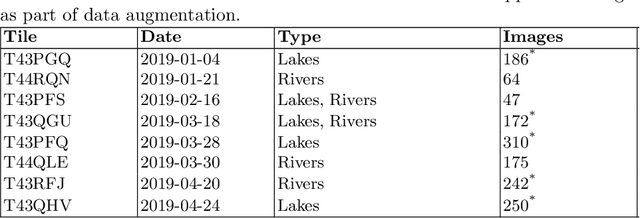


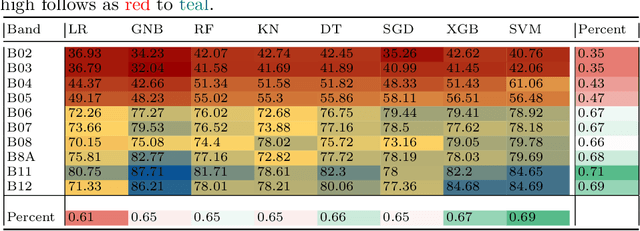
Monitoring water is a complex task due to its dynamic nature, added pollutants, and land build-up. The availability of high-resolu-tion data by Sentinel-2 multispectral products makes implementing remote sensing applications feasible. However, overutilizing or underutilizing multispectral bands of the product can lead to inferior performance. In this work, we compare the performances of ten out of the thirteen bands available in a Sentinel-2 product for water segmentation using eight machine learning algorithms. We find that the shortwave infrared bands (B11 and B12) are the most superior for segmenting water bodies. B11 achieves an overall accuracy of $71\%$ while B12 achieves $69\%$ across all algorithms on the test site. We also find that the Support Vector Machine (SVM) algorithm is the most favourable for single-band water segmentation. The SVM achieves an overall accuracy of $69\%$ across the tested bands over the given test site. Finally, to demonstrate the effectiveness of choosing the right amount of data, we use only B11 reflectance data to train an artificial neural network, BandNet. Even with a basic architecture, BandNet is proportionate to known architectures for semantic and water segmentation, achieving a $92.47$ mIOU on the test site. BandNet requires only a fraction of the time and resources to train and run inference, making it suitable to be deployed on web applications to run and monitor water bodies in localized regions. Our codebase is available at https://github.com/IamShubhamGupto/BandNet.
Triformer: Triangular, Variable-Specific Attentions for Long Sequence Multivariate Time Series Forecasting--Full Version
Apr 28, 2022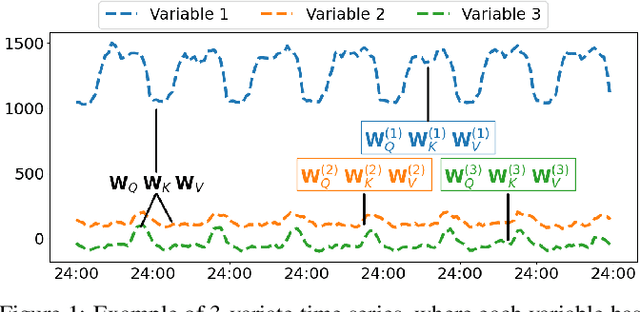
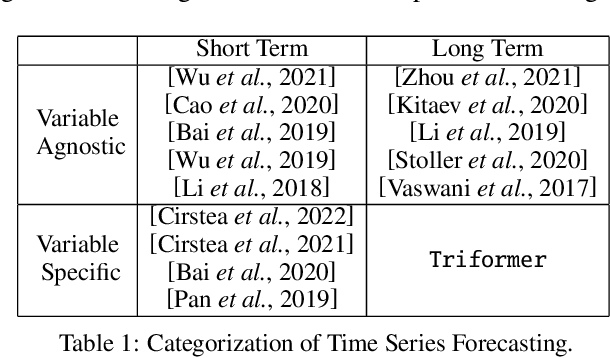
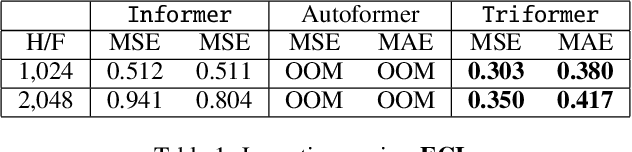
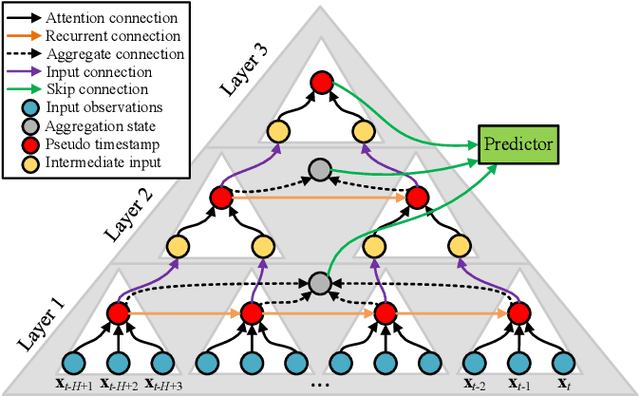
A variety of real-world applications rely on far future information to make decisions, thus calling for efficient and accurate long sequence multivariate time series forecasting. While recent attention-based forecasting models show strong abilities in capturing long-term dependencies, they still suffer from two key limitations. First, canonical self attention has a quadratic complexity w.r.t. the input time series length, thus falling short in efficiency. Second, different variables' time series often have distinct temporal dynamics, which existing studies fail to capture, as they use the same model parameter space, e.g., projection matrices, for all variables' time series, thus falling short in accuracy. To ensure high efficiency and accuracy, we propose Triformer, a triangular, variable-specific attention. (i) Linear complexity: we introduce a novel patch attention with linear complexity. When stacking multiple layers of the patch attentions, a triangular structure is proposed such that the layer sizes shrink exponentially, thus maintaining linear complexity. (ii) Variable-specific parameters: we propose a light-weight method to enable distinct sets of model parameters for different variables' time series to enhance accuracy without compromising efficiency and memory usage. Strong empirical evidence on four datasets from multiple domains justifies our design choices, and it demonstrates that Triformer outperforms state-of-the-art methods w.r.t. both accuracy and efficiency. This is an extended version of "Triformer: Triangular, Variable-Specific Attentions for Long Sequence Multivariate Time Series Forecasting", to appear in IJCAI 2022 [Cirstea et al., 2022a], including additional experimental results.