 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Quantum Control based on Deep Reinforcement Learning
Dec 14, 2022
In this thesis, we consider two simple but typical control problems and apply deep reinforcement learning to them, i.e., to cool and control a particle which is subject to continuous position measurement in a one-dimensional quadratic potential or in a quartic potential. We compare the performance of reinforcement learning control and conventional control strategies on the two problems, and show that the reinforcement learning achieves a performance comparable to the optimal control for the quadratic case, and outperforms conventional control strategies for the quartic case for which the optimal control strategy is unknown. To our knowledge, this is the first time deep reinforcement learning is applied to quantum control problems in continuous real space. Our research demonstrates that deep reinforcement learning can be used to control a stochastic quantum system in real space effectively as a measurement-feedback closed-loop controller, and our research also shows the ability of AI to discover new control strategies and properties of the quantum systems that are not well understood, and we can gain insights into these problems by learning from the AI, which opens up a new regime for scientific research.
DialogQAE: N-to-N Question Answer Pair Extraction from Customer Service Chatlog
Dec 14, 2022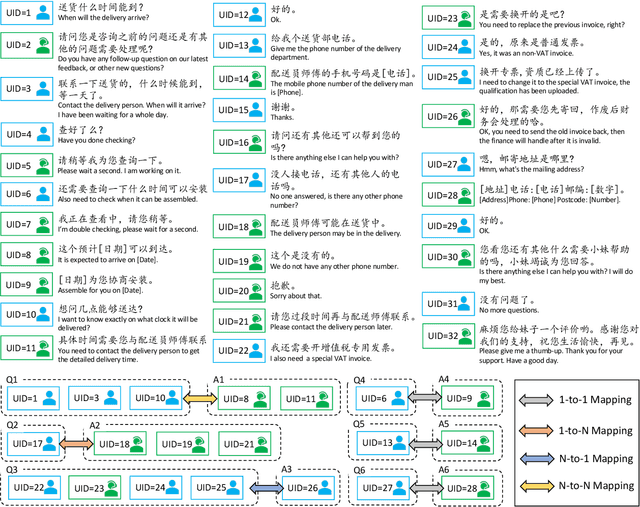
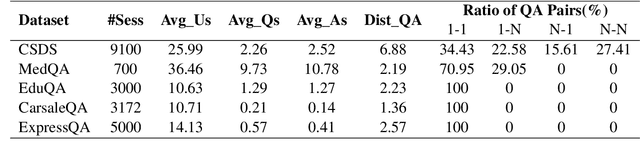

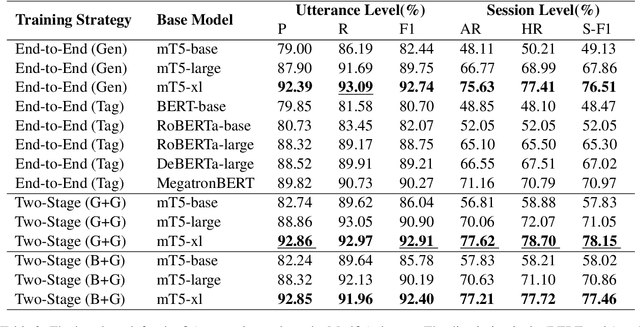
Harvesting question-answer (QA) pairs from customer service chatlog in the wild is an efficient way to enrich the knowledge base for customer service chatbots in the cold start or continuous integration scenarios. Prior work attempts to obtain 1-to-1 QA pairs from growing customer service chatlog, which fails to integrate the incomplete utterances from the dialog context for composite QA retrieval. In this paper, we propose N-to-N QA extraction task in which the derived questions and corresponding answers might be separated across different utterances. We introduce a suite of generative/discriminative tagging based methods with end-to-end and two-stage variants that perform well on 5 customer service datasets and for the first time setup a benchmark for N-to-N DialogQAE with utterance and session level evaluation metrics. With a deep dive into extracted QA pairs, we find that the relations between and inside the QA pairs can be indicators to analyze the dialogue structure, e.g. information seeking, clarification, barge-in and elaboration. We also show that the proposed models can adapt to different domains and languages, and reduce the labor cost of knowledge accumulation in the real-world product dialogue platform.
Flow Lenia: Mass conservation for the study of virtual creatures in continuous cellular automata
Dec 14, 2022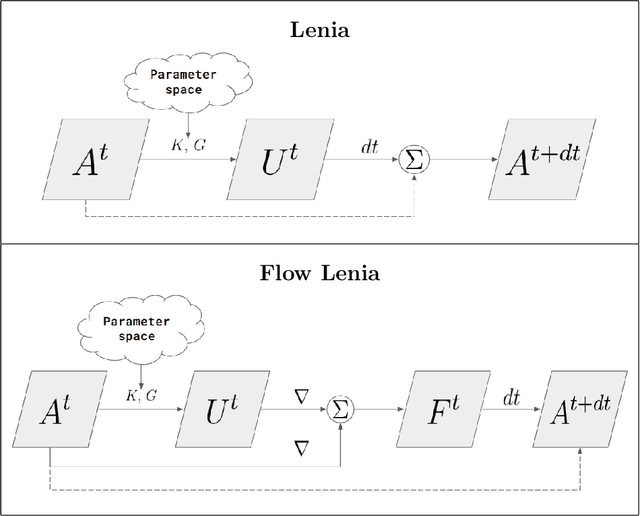
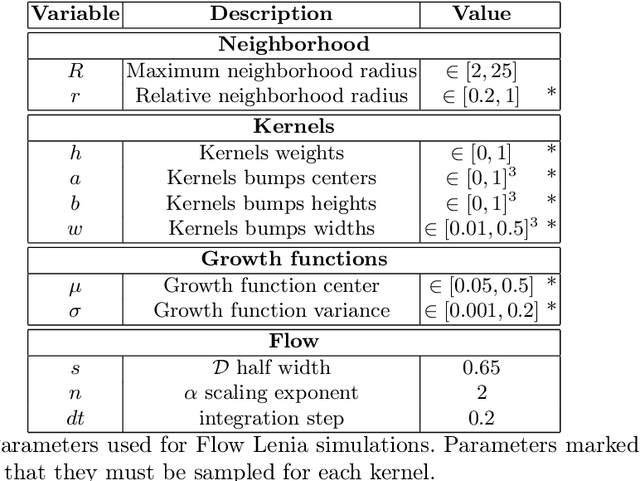
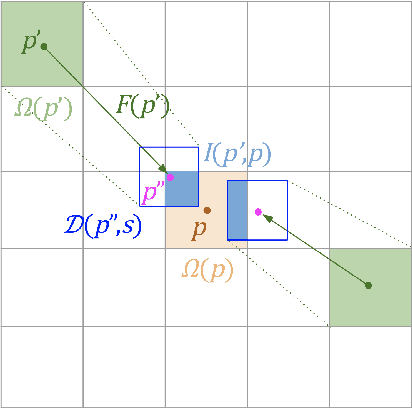

Lenia is a family of cellular automata (CA) generalizing Conway's Game of Life to continuous space, time and states. Lenia has attracted a lot of attention because of the wide diversity of self-organizing patterns it can generate. Among those, some spatially localized patterns (SLPs) resemble life-like artificial creatures. However, those creatures are found in only a small subspace of the Lenia parameter space and are not trivial to discover, necessitating advanced search algorithms. We hypothesize that adding a mass conservation constraint could facilitate the emergence of SLPs. We propose here an extension of the Lenia model, called Flow Lenia, which enables mass conservation. We show a few observations demonstrating its effectiveness in generating SLPs with complex behaviors. Furthermore, we show how Flow Lenia enables the integration of the parameters of the CA update rules within the CA dynamics, making them dynamic and localized. This allows for multi-species simulations, with locally coherent update rules that define properties of the emerging creatures, and that can be mixed with neighbouring rules. We argue that this paves the way for the intrinsic evolution of self-organized artificial life forms within continuous CAs.
Multi-Scale Feature Fusion Transformer Network for End-to-End Single Channel Speech Separation
Dec 14, 2022
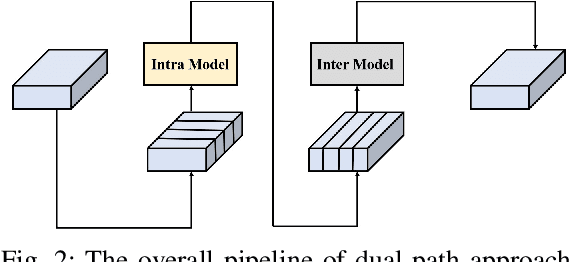
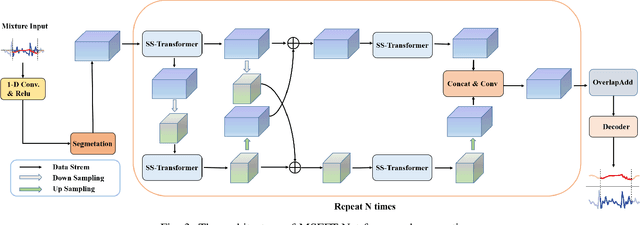
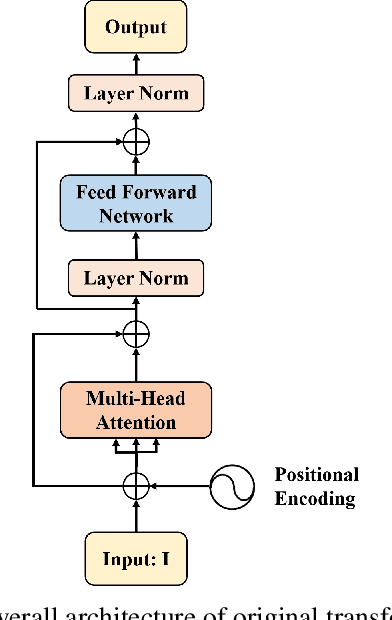
Recently studies on time-domain audio separation networks (TasNets) have made a great stride in speech separation. One of the most representative TasNets is a network with a dual-path segmentation approach. However, the original model called DPRNN used a fixed feature dimension and unchanged segment size throughout all layers of the network. In this paper, we propose a multi-scale feature fusion transformer network (MSFFT-Net) based on the conventional dual-path structure for single-channel speech separation. Unlike the conventional dual-path structure where only one processing path exists, adopting several iterative blocks with alternative intra-chunk and inter-chunk operations to capture local and global context information, the proposed MSFFT-Net has multiple parallel processing paths where the feature information can be exchanged between multiple parallel processing paths. Experiments show that our proposed networks based on multi-scale feature fusion structure have achieved better results than the original dual-path model on the benchmark dataset-WSJ0-2mix, where the SI-SNRi score of MSFFT-3P is 20.7dB (1.47% improvement), and MSFFT-2P is 21.0dB (3.45% improvement), which achieves SOTA on WSJ0-2mix without any data augmentation method.
Particle-Based Score Estimation for State Space Model Learning in Autonomous Driving
Dec 14, 2022
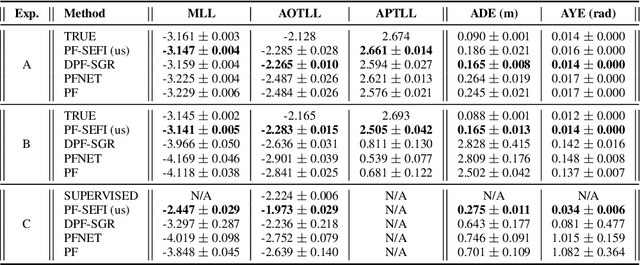
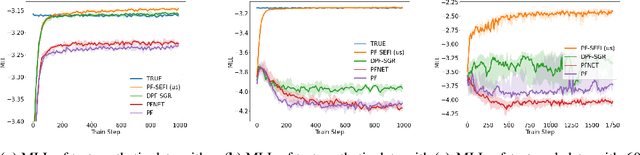
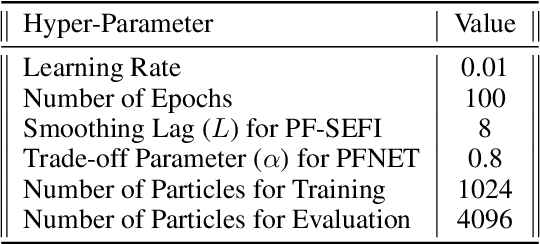
Multi-object state estimation is a fundamental problem for robotic applications where a robot must interact with other moving objects. Typically, other objects' relevant state features are not directly observable, and must instead be inferred from observations. Particle filtering can perform such inference given approximate transition and observation models. However, these models are often unknown a priori, yielding a difficult parameter estimation problem since observations jointly carry transition and observation noise. In this work, we consider learning maximum-likelihood parameters using particle methods. Recent methods addressing this problem typically differentiate through time in a particle filter, which requires workarounds to the non-differentiable resampling step, that yield biased or high variance gradient estimates. By contrast, we exploit Fisher's identity to obtain a particle-based approximation of the score function (the gradient of the log likelihood) that yields a low variance estimate while only requiring stepwise differentiation through the transition and observation models. We apply our method to real data collected from autonomous vehicles (AVs) and show that it learns better models than existing techniques and is more stable in training, yielding an effective smoother for tracking the trajectories of vehicles around an AV.
Introduction of a tree-based technique for efficient and real-time label retrieval in the object tracking system
May 31, 2022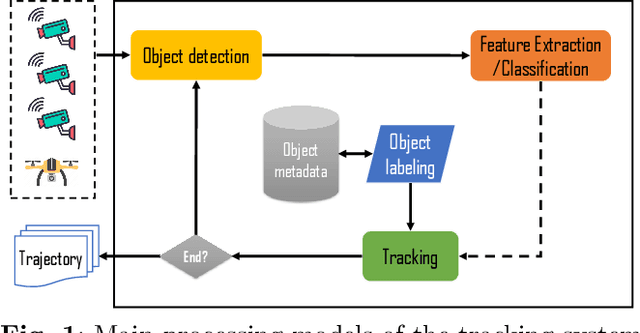
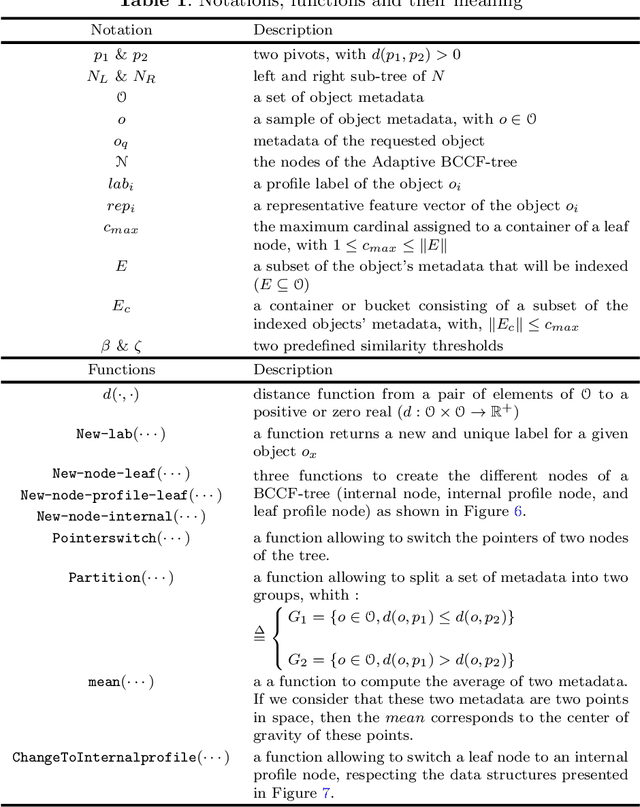
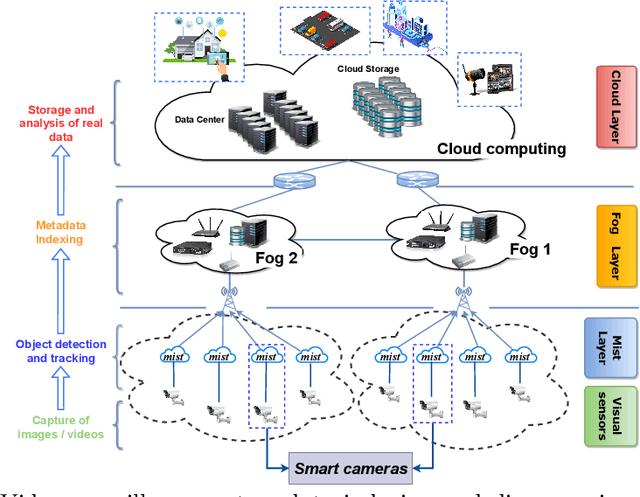
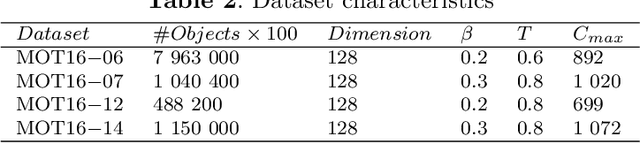
This paper addresses the issue of the real-time tracking quality of moving objects in large-scale video surveillance systems. During the tracking process, the system assigns an identifier or label to each tracked object to distinguish it from other objects. In such a mission, it is essential to keep this identifier for the same objects, whatever the area, the time of their appearance, or the detecting camera. This is to conserve as much information about the tracking object as possible, decrease the number of ID switching (ID-Sw), and increase the quality of object tracking. To accomplish object labeling, a massive amount of data collected by the cameras must be searched to retrieve the most similar (nearest neighbor) object identifier. Although this task is simple, it becomes very complex in large-scale video surveillance networks, where the data becomes very large. In this case, the label retrieval time increases significantly with this increase, which negatively affects the performance of the real-time tracking system. To avoid such problems, we propose a new solution to automatically label multiple objects for efficient real-time tracking using the indexing mechanism. This mechanism organizes the metadata of the objects extracted during the detection and tracking phase in an Adaptive BCCF-tree. The main advantage of this structure is: its ability to index massive metadata generated by multi-cameras, its logarithmic search complexity, which implicitly reduces the search response time, and its quality of research results, which ensure coherent labeling of the tracked objects. The system load is distributed through a new Internet of Video Things infrastructure-based architecture to improve data processing and real-time object tracking performance. The experimental evaluation was conducted on a publicly available dataset generated by multi-camera containing different crowd activities.
Masked Wavelet Representation for Compact Neural Radiance Fields
Dec 18, 2022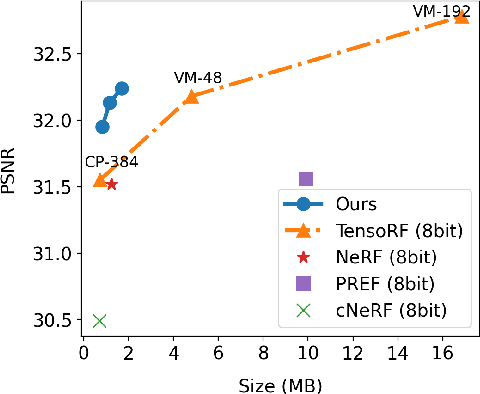
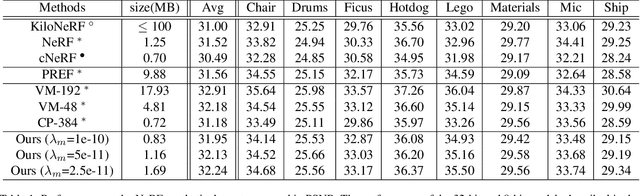
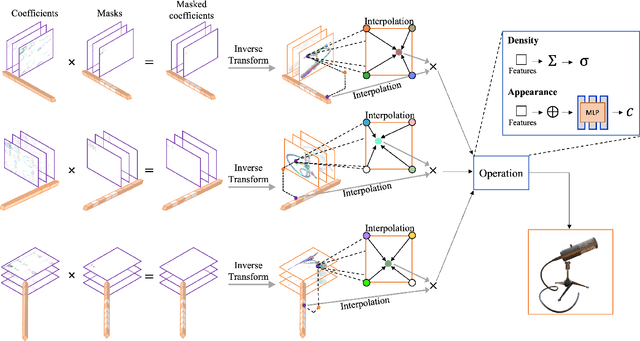
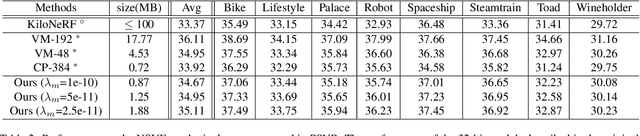
Neural radiance fields (NeRF) have demonstrated the potential of coordinate-based neural representation (neural fields or implicit neural representation) in neural rendering. However, using a multi-layer perceptron (MLP) to represent a 3D scene or object requires enormous computational resources and time. There have been recent studies on how to reduce these computational inefficiencies by using additional data structures, such as grids or trees. Despite the promising performance, the explicit data structure necessitates a substantial amount of memory. In this work, we present a method to reduce the size without compromising the advantages of having additional data structures. In detail, we propose using the wavelet transform on grid-based neural fields. Grid-based neural fields are for fast convergence, and the wavelet transform, whose efficiency has been demonstrated in high-performance standard codecs, is to improve the parameter efficiency of grids. Furthermore, in order to achieve a higher sparsity of grid coefficients while maintaining reconstruction quality, we present a novel trainable masking approach. Experimental results demonstrate that non-spatial grid coefficients, such as wavelet coefficients, are capable of attaining a higher level of sparsity than spatial grid coefficients, resulting in a more compact representation. With our proposed mask and compression pipeline, we achieved state-of-the-art performance within a memory budget of 2 MB. Our code is available at https://github.com/daniel03c1/masked_wavelet_nerf.
Time Series Prediction by Multi-task GPR with Spatiotemporal Information Transformation
Apr 26, 2022
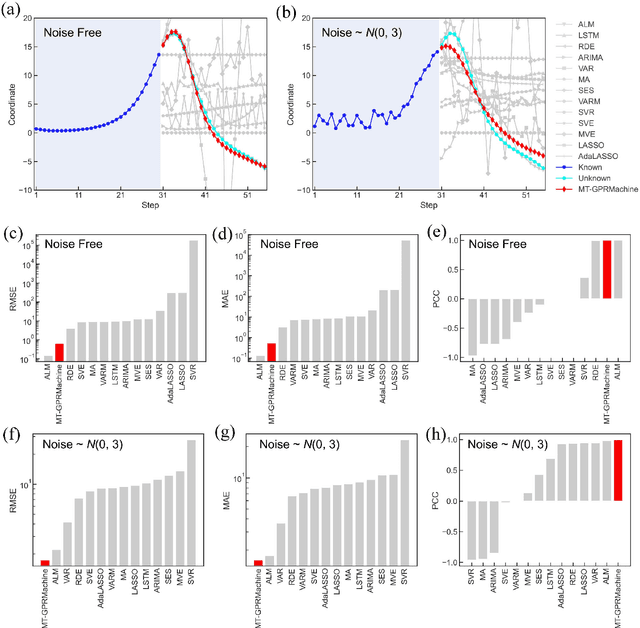
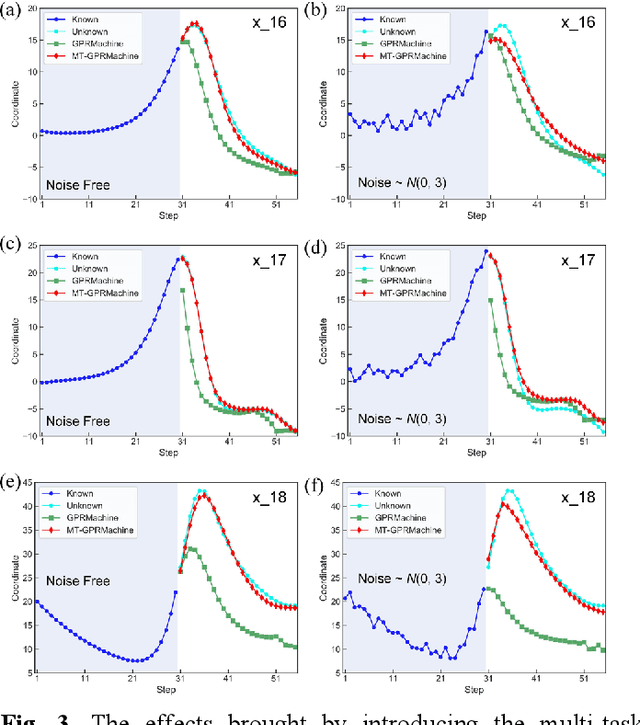
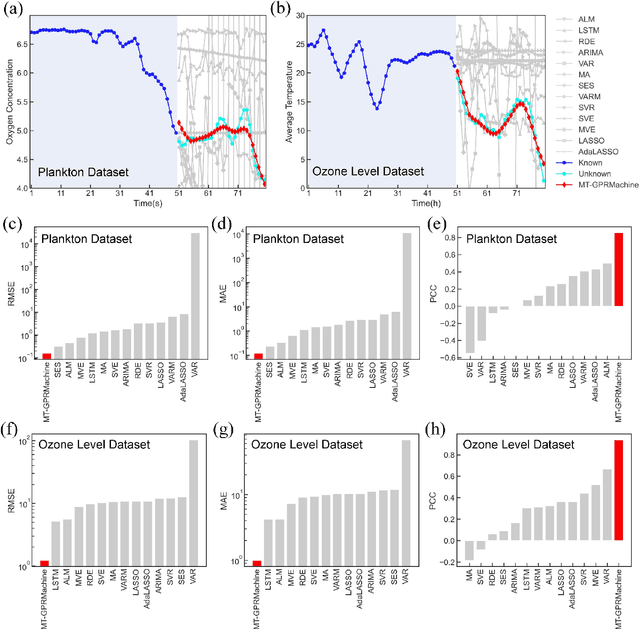
Making an accurate prediction of an unknown system only from a short-term time series is difficult due to the lack of sufficient information, especially in a multi-step-ahead manner. However, a high-dimensional short-term time series contains rich dynamical information, and also becomes increasingly available in many fields. In this work, by exploiting spatiotemporal information (STI) transformation scheme that transforms such high-dimensional/spatial information to temporal information, we developed a new method called MT-GPRMachine to achieve accurate prediction from a short-term time series. Specifically, we first construct a specific multi-task GPR which is multiple linked STI mappings to transform high dimensional/spatial information into temporal/dynamical information of any given target variable, and then makes multi step-ahead prediction of the target variable by solving those STI mappings. The multi-step-ahead prediction results on various synthetic and real-world datasets clearly validated that MT-GPRMachine outperformed other existing approaches.
Investigation of reinforcement learning for shape optimization of profile extrusion dies
Dec 23, 2022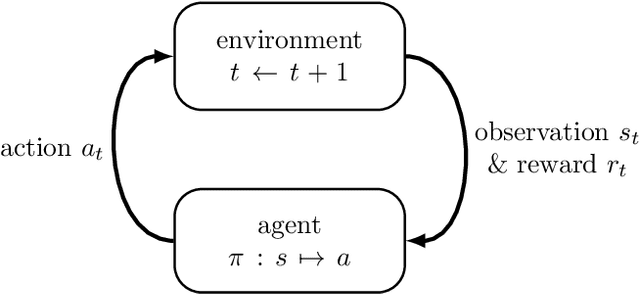
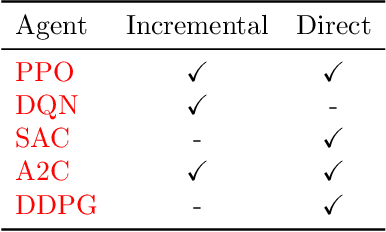
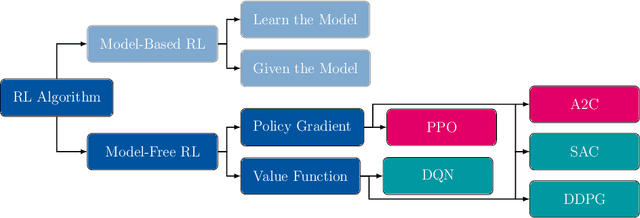

Profile extrusion is a continuous production process for manufacturing plastic profiles from molten polymer. Especially interesting is the design of the die, through which the melt is pressed to attain the desired shape. However, due to an inhomogeneous velocity distribution at the die exit or residual stresses inside the extrudate, the final shape of the manufactured part often deviates from the desired one. To avoid these deviations, the shape of the die can be computationally optimized, which has already been investigated in the literature using classical optimization approaches. A new approach in the field of shape optimization is the utilization of Reinforcement Learning (RL) as a learning-based optimization algorithm. RL is based on trial-and-error interactions of an agent with an environment. For each action, the agent is rewarded and informed about the subsequent state of the environment. While not necessarily superior to classical, e.g., gradient-based or evolutionary, optimization algorithms for one single problem, RL techniques are expected to perform especially well when similar optimization tasks are repeated since the agent learns a more general strategy for generating optimal shapes instead of concentrating on just one single problem. In this work, we investigate this approach by applying it to two 2D test cases. The flow-channel geometry can be modified by the RL agent using so-called Free-Form Deformation, a method where the computational mesh is embedded into a transformation spline, which is then manipulated based on the control-point positions. In particular, we investigate the impact of utilizing different agents on the training progress and the potential of wall time saving by utilizing multiple environments during training.
Resource Allocation of Federated Learning for the Metaverse with Mobile Augmented Reality
Nov 18, 2022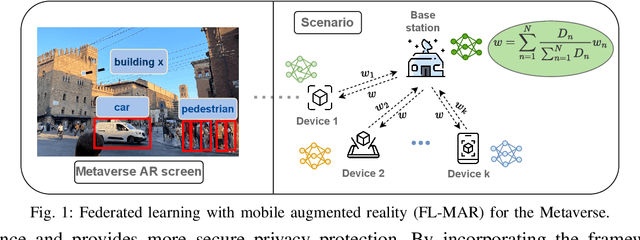
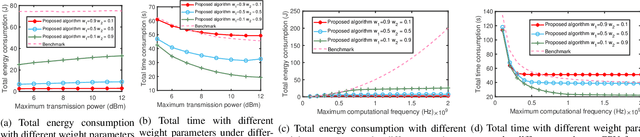
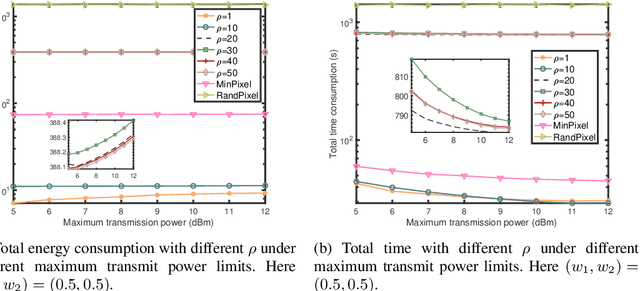
The Metaverse has received much attention recently. Metaverse applications via mobile augmented reality (MAR) require rapid and accurate object detection to mix digital data with the real world. Federated learning (FL) is an intriguing distributed machine learning approach due to its privacy-preserving characteristics. Due to privacy concerns and the limited computation resources on mobile devices, we incorporate FL into MAR systems of the Metaverse to train a model cooperatively. Besides, to balance the trade-off between energy, execution latency and model accuracy, thereby accommodating different demands and application scenarios, we formulate an optimization problem to minimize a weighted combination of total energy consumption, completion time and model accuracy. Through decomposing the non-convex optimization problem into two subproblems, we devise a resource allocation algorithm to determine the bandwidth allocation, transmission power, CPU frequency and video frame resolution for each participating device. We further present the convergence analysis and computational complexity of the proposed algorithm. Numerical results show that our proposed algorithm has better performance (in terms of energy consumption, completion time and model accuracy) under different weight parameters compared to existing benchmarks.