 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Random Projection Layers for Multidimensional Time Sires Forecasting
Feb 16, 2024
All-Multi-Layer Perceptron (all-MLP) mixer models have been shown to be effective for time series forecasting problems. However, when such a model is applied to high-dimensional time series (e.g., the time series in a spatial-temporal dataset), its performance is likely to degrade due to overfitting issues. In this paper, we propose an all-MLP time series forecasting architecture, referred to as RPMixer. Our method leverages the ensemble-like behavior of deep neural networks, where each individual block within the network acts like a base learner in an ensemble model, especially when identity mapping residual connections are incorporated. By integrating random projection layers into our model, we increase the diversity among the blocks' outputs, thereby enhancing the overall performance of RPMixer. Extensive experiments conducted on large-scale spatial-temporal forecasting benchmark datasets demonstrate that our proposed method outperforms alternative methods, including both spatial-temporal graph models and general forecasting models.
Quaternion recurrent neural network with real-time recurrent learning and maximum correntropy criterion
Feb 22, 2024We develop a robust quaternion recurrent neural network (QRNN) for real-time processing of 3D and 4D data with outliers. This is achieved by combining the real-time recurrent learning (RTRL) algorithm and the maximum correntropy criterion (MCC) as a loss function. While both the mean square error and maximum correntropy criterion are viable cost functions, it is shown that the non-quadratic maximum correntropy loss function is less sensitive to outliers, making it suitable for applications with multidimensional noisy or uncertain data. Both algorithms are derived based on the novel generalised HR (GHR) calculus, which allows for the differentiation of real functions of quaternion variables and offers the product and chain rules, thus enabling elegant and compact derivations. Simulation results in the context of motion prediction of chest internal markers for lung cancer radiotherapy, which includes regular and irregular breathing sequences, support the analysis.
Dynamic Anchor Selection and Real-Time Pose Prediction for Ultra-wideband Tagless Gate
Feb 22, 2024Ultra-wideband (UWB) is emerging as a promising solution that can realize proximity services, such as UWB tagless gate (UTG), thanks to centimeter-level localization accuracy based on two different ranging methods such as downlink time-difference of arrival (DL-TDoA) and double-sided two-way ranging (DS-TWR). The UTG is a UWB-based proximity service that provides a seamless gate pass system without requiring real-time mobile device (MD) tapping. The location of MD is calculated using DL-TDoA, and the MD communicates with the nearest UTG using DS-TWR to open the gate. Therefore, the knowledge about the exact location of MD is the main challenge of UTG, and hence we provide the solutions for both DL-TDoA and DS-TWR. In this paper, we propose dynamic anchor selection for extremely accurate DL-TDoA localization and pose prediction for DS-TWR, called DynaPose. The pose is defined as the actual location of MD on the human body, which affects the localization accuracy. DynaPose is based on line-of-sight (LOS) and non-LOS (NLOS) classification using deep learning for anchor selection and pose prediction. Deep learning models use the UWB channel impulse response and the inertial measurement unit embedded in the smartphone. DynaPose is implemented on Samsung Galaxy Note20 Ultra and Qorvo UWB board to show the feasibility and applicability. DynaPose achieves a LOS/NLOS classification accuracy of 0.984, 62% higher DL-TDoA localization accuracy, and ultimately detects four different poses with an accuracy of 0.961 in real-time.
Robust MITL planning under uncertain navigation times
Mar 06, 2024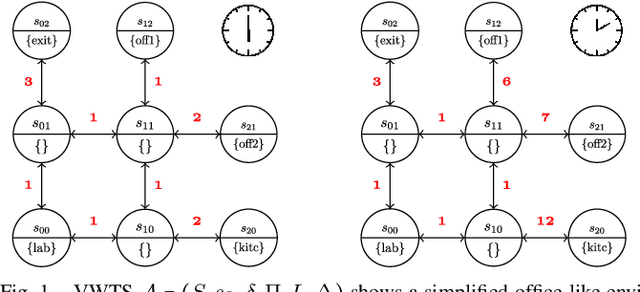
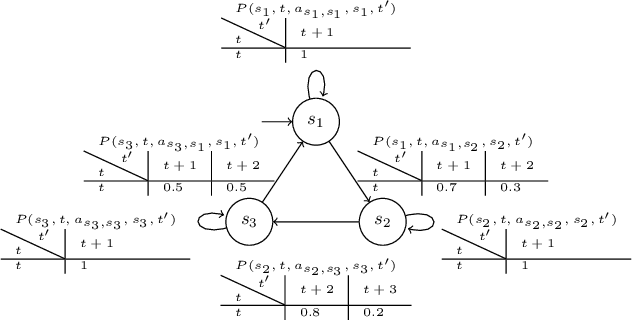
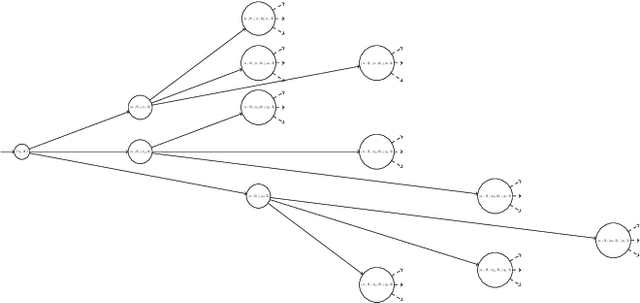
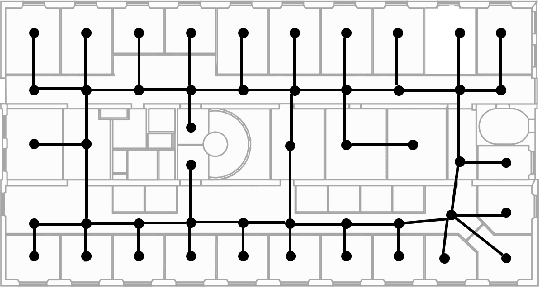
In environments like offices, the duration of a robot's navigation between two locations may vary over time. For instance, reaching a kitchen may take more time during lunchtime since the corridors are crowded with people heading the same way. In this work, we address the problem of routing in such environments with tasks expressed in Metric Interval Temporal Logic (MITL) - a rich robot task specification language that allows us to capture explicit time requirements. Our objective is to find a strategy that maximizes the temporal robustness of the robot's MITL task. As the first step towards a solution, we define a Mixed-integer linear programming approach to solving the task planning problem over a Varying Weighted Transition System, where navigation durations are deterministic but vary depending on the time of day. Then, we apply this planner to optimize for MITL temporal robustness in Markov Decision Processes, where the navigation durations between physical locations are uncertain, but the time-dependent distribution over possible delays is known. Finally, we develop a receding horizon planner for Markov Decision Processes that preserves guarantees over MITL temporal robustness. We show the scalability of our planning algorithms in simulations of robotic tasks.
Stochastic Approximation with Delayed Updates: Finite-Time Rates under Markovian Sampling
Feb 19, 2024Motivated by applications in large-scale and multi-agent reinforcement learning, we study the non-asymptotic performance of stochastic approximation (SA) schemes with delayed updates under Markovian sampling. While the effect of delays has been extensively studied for optimization, the manner in which they interact with the underlying Markov process to shape the finite-time performance of SA remains poorly understood. In this context, our first main contribution is to show that under time-varying bounded delays, the delayed SA update rule guarantees exponentially fast convergence of the \emph{last iterate} to a ball around the SA operator's fixed point. Notably, our bound is \emph{tight} in its dependence on both the maximum delay $\tau_{max}$, and the mixing time $\tau_{mix}$. To achieve this tight bound, we develop a novel inductive proof technique that, unlike various existing delayed-optimization analyses, relies on establishing uniform boundedness of the iterates. As such, our proof may be of independent interest. Next, to mitigate the impact of the maximum delay on the convergence rate, we provide the first finite-time analysis of a delay-adaptive SA scheme under Markovian sampling. In particular, we show that the exponent of convergence of this scheme gets scaled down by $\tau_{avg}$, as opposed to $\tau_{max}$ for the vanilla delayed SA rule; here, $\tau_{avg}$ denotes the average delay across all iterations. Moreover, the adaptive scheme requires no prior knowledge of the delay sequence for step-size tuning. Our theoretical findings shed light on the finite-time effects of delays for a broad class of algorithms, including TD learning, Q-learning, and stochastic gradient descent under Markovian sampling.
Structural Knowledge Informed Continual Multivariate Time Series Forecasting
Feb 20, 2024Recent studies in multivariate time series (MTS) forecasting reveal that explicitly modeling the hidden dependencies among different time series can yield promising forecasting performance and reliable explanations. However, modeling variable dependencies remains underexplored when MTS is continuously accumulated under different regimes (stages). Due to the potential distribution and dependency disparities, the underlying model may encounter the catastrophic forgetting problem, i.e., it is challenging to memorize and infer different types of variable dependencies across different regimes while maintaining forecasting performance. To address this issue, we propose a novel Structural Knowledge Informed Continual Learning (SKI-CL) framework to perform MTS forecasting within a continual learning paradigm, which leverages structural knowledge to steer the forecasting model toward identifying and adapting to different regimes, and selects representative MTS samples from each regime for memory replay. Specifically, we develop a forecasting model based on graph structure learning, where a consistency regularization scheme is imposed between the learned variable dependencies and the structural knowledge while optimizing the forecasting objective over the MTS data. As such, MTS representations learned in each regime are associated with distinct structural knowledge, which helps the model memorize a variety of conceivable scenarios and results in accurate forecasts in the continual learning context. Meanwhile, we develop a representation-matching memory replay scheme that maximizes the temporal coverage of MTS data to efficiently preserve the underlying temporal dynamics and dependency structures of each regime. Thorough empirical studies on synthetic and real-world benchmarks validate SKI-CL's efficacy and advantages over the state-of-the-art for continual MTS forecasting tasks.
Image-Guided Autonomous Guidewire Navigation in Robot-Assisted Endovascular Interventions using Reinforcement Learning
Mar 09, 2024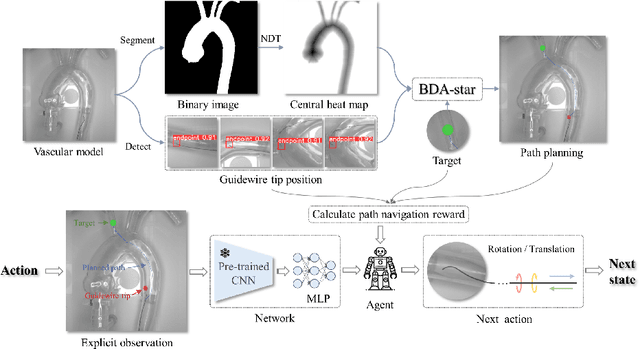
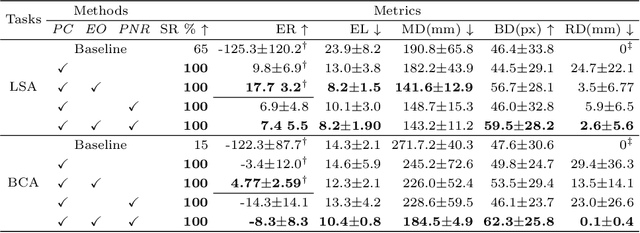

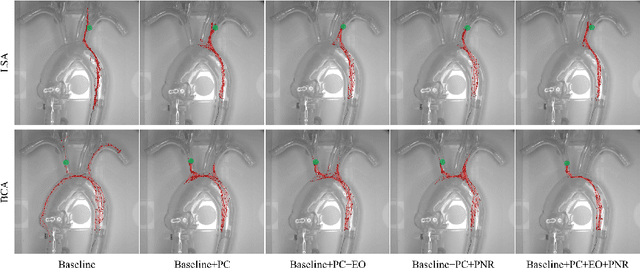
Autonomous robots in endovascular interventions possess the potential to navigate guidewires with safety and reliability, while reducing human error and shortening surgical time. However, current methods of guidewire navigation based on Reinforcement Learning (RL) depend on manual demonstration data or magnetic guidance. In this work, we propose an Image-guided Autonomous Guidewire Navigation (IAGN) method. Specifically, we introduce BDA-star, a path planning algorithm with boundary distance constraints, for the trajectory planning of guidewire navigation. We established an IAGN-RL environment where the observations are real-time guidewire feeding images highlighting the position of the guidewire tip and the planned path. We proposed a reward function based on the distances from both the guidewire tip to the planned path and the target to evaluate the agent's actions. Furthermore, in policy network, we employ a pre-trained convolutional neural network to extract features, mitigating stability issues and slow convergence rates associated with direct learning from raw pixels. Experiments conducted on the aortic simulation IAGN platform demonstrated that the proposed method, targeting the left subclavian artery and the brachiocephalic artery, achieved a 100% guidewire navigation success rate, along with reduced movement and retraction distances and trajectories tend to the center of the vessels.
Broadened-beam Uniform Rectangular Array Coefficient Design in LEO SatComs Under Quality of Service and Constant Modulus Constraints
Mar 12, 2024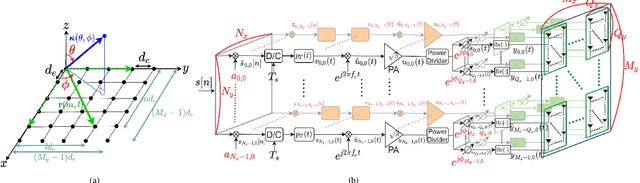
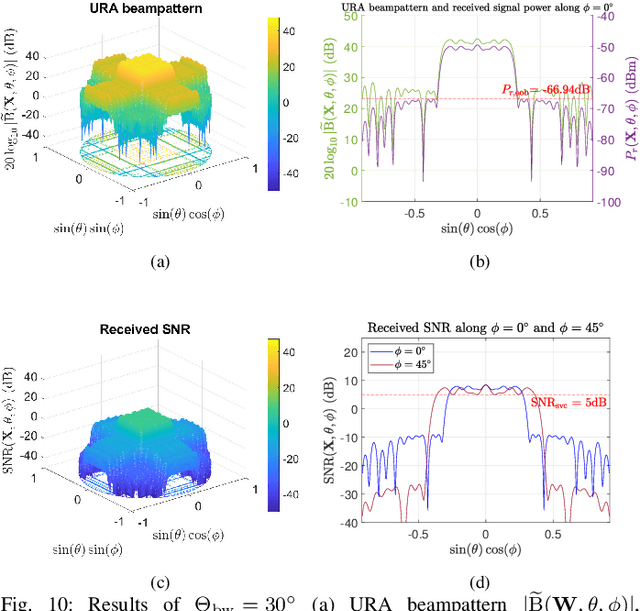
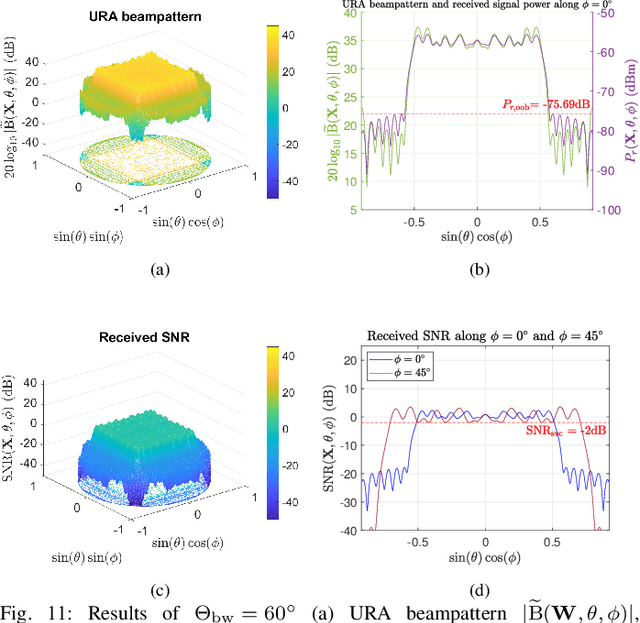
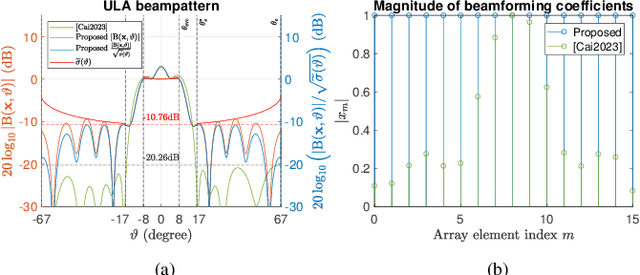
Satellite communications (SatComs) are anticipated to provide global Internet access. Low Earth orbit (LEO) satellites (SATs) have the advantage of providing higher downlink capacity owing to their smaller link budget compared with medium Earth orbit (MEO) and geostationary Earth orbit (GEO) SATs. In this paper, beam-broadening algorithms for uniform rectangular arrays (URAs) in LEO SatComs were studied. The proposed method is the first of its kind that jointly considers the path loss variation from SAT to user terminal (UT) due to the Earth's curvature to guarantee quality of service (QoS) inspired by the synthesis of isoflux radiation patterns in the literature, constant modulus constraint (CMC) favored for maximizing power amplifier (PA) efficiency, and out-of-beam radiation suppression to avoid interference. A URA design problem is formulated and decomposed into two uniform linear array (ULA) design subproblems utilizing the idea of Kronecker product beamforming to reduce the computational complexity of designing URA.The non-convex ULA subproblems are solved by a convex iterative algorithm. Simulation results reveal the advantages of the proposed method for suppressing out-of-beam radiation and achieving design criteria. In addition, channel capacity evaluation is carried out and shows that the proposed ``broadened-beam" beamformers can offer capacities that are at least four times greater than ``narrow-beam" beamformers employing an array steering vector when beam transition time is taken into account. The proposed method holds potential for LEO broadcasting applications such as digital video broadcasting (DVB).
Experimental analysis of the TRC benchmark system
Mar 12, 2024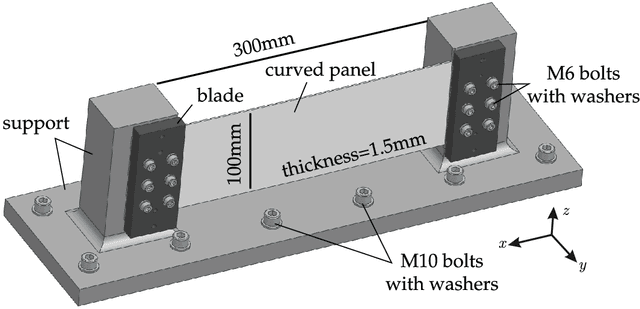

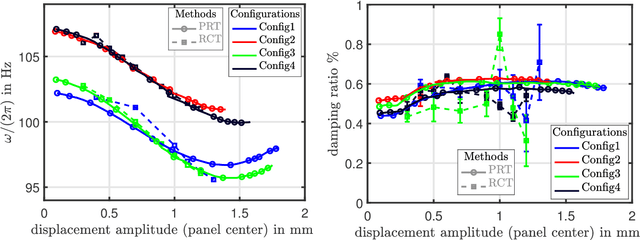
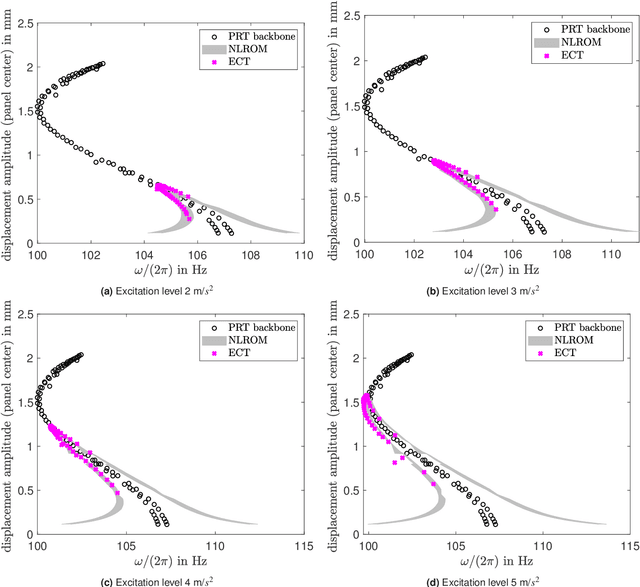
The Tribomechadynamics Research Challenge (TRC) was a blind prediction of the vibration behavior of a thin plate clamped on two sides using bolted joints. The first bending mode's natural frequency and damping ratio were requested as function of the amplitude, starting from the linear regime until high levels, where both frictional contact and nonlinear bending-stretching coupling become relevant. The predictions were confronted with experimental results in a companion paper; the present article addresses the experimental analysis of this benchmark system. Amplitude-dependent modal data was obtained from phase resonance and response controlled tests. An original variant of response controlled testing is proposed: Instead of a fixed frequency interval, a fixed phase interval is analyzed. This way, the high excitation levels required outside resonance, which could activate unwanted exciter nonlinearity, are avoided. Consistency of testing methods is carefully analyzed. Overall, these measures have permitted to gain high confidence in the acquired modal data. The different sources of the remaining uncertainty were further analyzed. A low reassembly-variability but a moderate time-variability were identified, where the latter is attributed to some thermal sensitivity of the system. Two nominally identical plates were analyzed, which both have an appreciable initial curvature, and a significant effect on the vibration behavior was found depending on whether the plate is aligned/misaligned with the support structure. Further, a 1:2 nonlinear modal interaction with the first torsion mode was observed, which only occurs in the aligned configurations.
Premonition: Using Generative Models to Preempt Future Data Changes in Continual Learning
Mar 12, 2024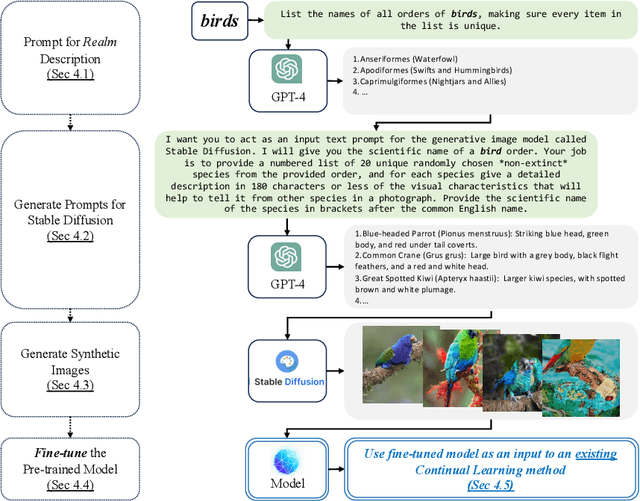


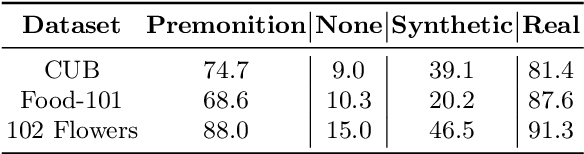
Continual learning requires a model to adapt to ongoing changes in the data distribution, and often to the set of tasks to be performed. It is rare, however, that the data and task changes are completely unpredictable. Given a description of an overarching goal or data theme, which we call a realm, humans can often guess what concepts are associated with it. We show here that the combination of a large language model and an image generation model can similarly provide useful premonitions as to how a continual learning challenge might develop over time. We use the large language model to generate text descriptions of semantically related classes that might potentially appear in the data stream in future. These descriptions are then rendered using Stable Diffusion to generate new labelled image samples. The resulting synthetic dataset is employed for supervised pre-training, but is discarded prior to commencing continual learning, along with the pre-training classification head. We find that the backbone of our pre-trained networks can learn representations useful for the downstream continual learning problem, thus becoming a valuable input to any existing continual learning method. Although there are complexities arising from the domain gap between real and synthetic images, we show that pre-training models in this manner improves multiple Class Incremenal Learning (CIL) methods on fine-grained image classification benchmarks. Supporting code can be found at https://github.com/cl-premonition/premonition.