 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RF-Flashlight Testbed for Verification of Real-Time Geofencing of EESS Radiometers and Millimeter-Wave Ground-to-Satellite Propagation Models
Feb 28, 2024
A simple 'RF-flashlight' (or ground to satellite) interference testbed is proposed to experimentally verify real-time geofencing (RTG) for protecting passive Earth Exploration Satellite Services (EESS) radiometer measurements from 5G or 6G mm-wave transmissions, and ground to satellite propagation models used in the interference modeling of this spectrum coexistence scenario. RTG is a stronger EESS protection mechanism than the current methodology recommended by the ITU based on a worst-case interference threshold while simultaneously enabling dynamic spectrum sharing and coexistence with 5G or 6G wireless networks. Similarly, verifying more sophisticated RF propagation models that include ground topology, buildings, and non-line-of-sight paths will provide better estimates of interference than the current ITU line-of-sight model and, thus, a more reliable basis for establishing a consensus among the spectrum stakeholders.
EarthLoc: Astronaut Photography Localization by Indexing Earth from Space
Mar 11, 2024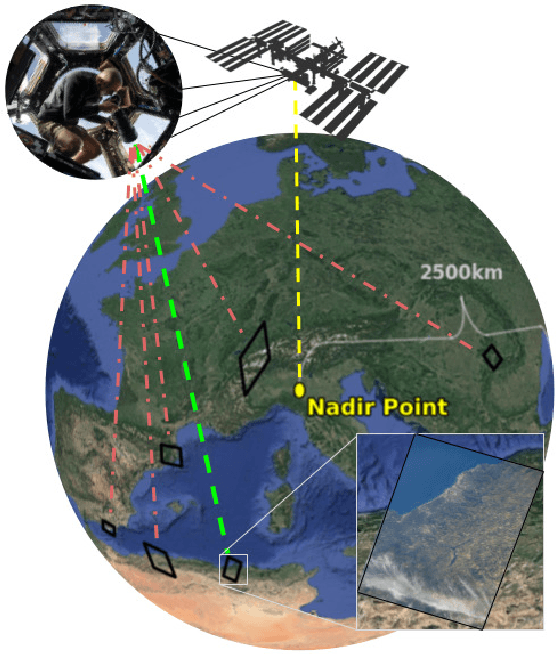
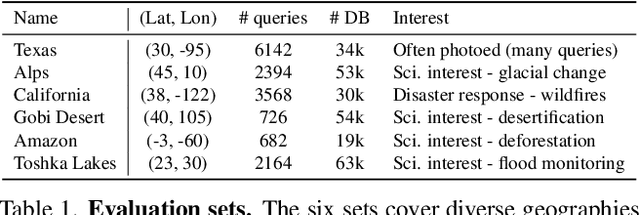

Astronaut photography, spanning six decades of human spaceflight, presents a unique Earth observations dataset with immense value for both scientific research and disaster response. Despite its significance, accurately localizing the geographical extent of these images, crucial for effective utilization, poses substantial challenges. Current manual localization efforts are time-consuming, motivating the need for automated solutions. We propose a novel approach - leveraging image retrieval - to address this challenge efficiently. We introduce innovative training techniques, including Year-Wise Data Augmentation and a Neutral-Aware Multi-Similarity Loss, which contribute to the development of a high-performance model, EarthLoc. We develop six evaluation datasets and perform a comprehensive benchmark comparing EarthLoc to existing methods, showcasing its superior efficiency and accuracy. Our approach marks a significant advancement in automating the localization of astronaut photography, which will help bridge a critical gap in Earth observations data. Code and datasets are available at https://github.com/gmberton/EarthLoc
Ricci flow-based brain surface covariance descriptors for Alzheimer disease
Mar 11, 2024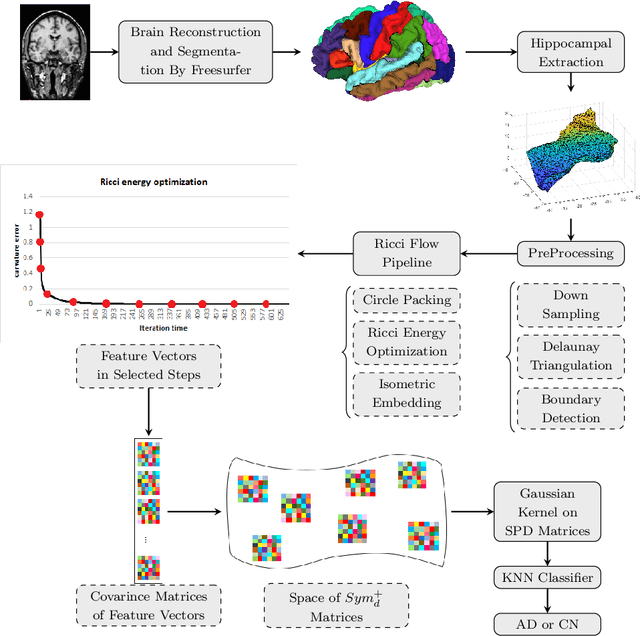
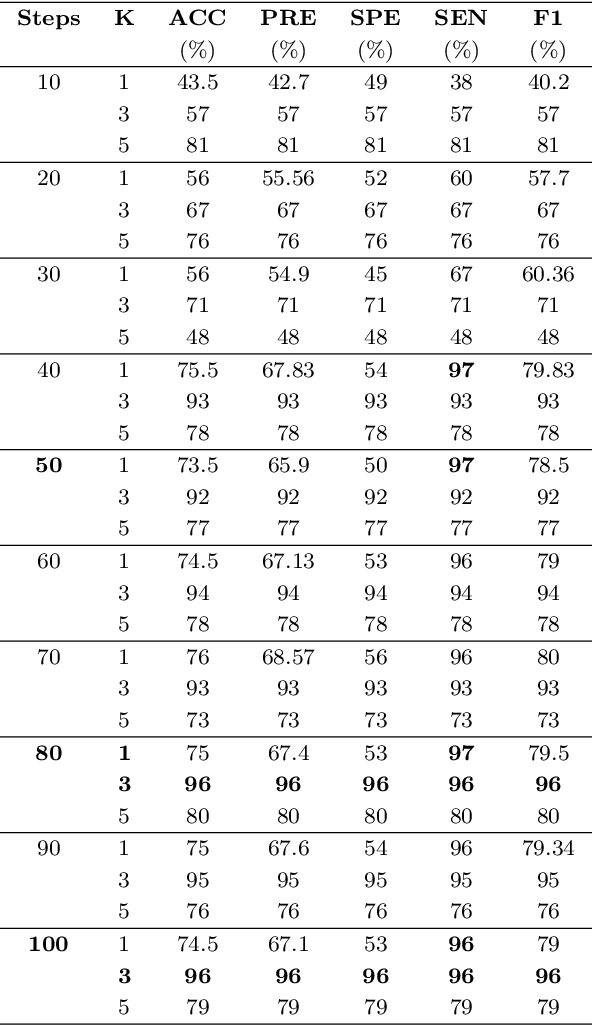

Automated feature extraction from MRI brain scans and diagnosis of Alzheimer's disease are ongoing challenges. With advances in 3D imaging technology, 3D data acquisition is becoming more viable and efficient than its 2D counterpart. Rather than using feature-based vectors, in this paper, for the first time, we suggest a pipeline to extract novel covariance-based descriptors from the cortical surface using the Ricci energy optimization. The covariance descriptors are components of the nonlinear manifold of symmetric positive-definite matrices, thus we focus on using the Gaussian radial basis function to apply manifold-based classification to the 3D shape problem. Applying this novel signature to the analysis of abnormal cortical brain morphometry allows for diagnosing Alzheimer's disease. Experimental studies performed on about two hundred 3D MRI brain models, gathered from Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset demonstrate the effectiveness of our descriptors in achieving remarkable classification accuracy.
Optimistic Safety for Linearly-Constrained Online Convex Optimization
Mar 09, 2024
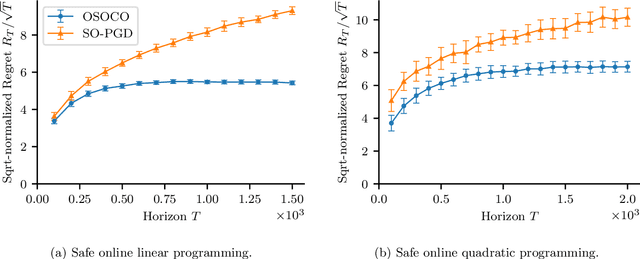
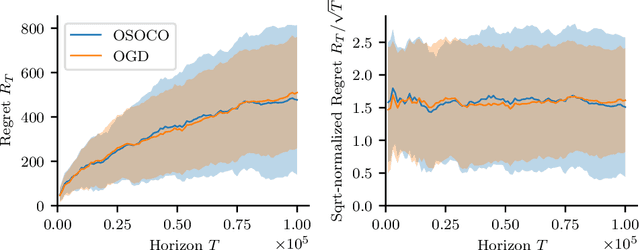
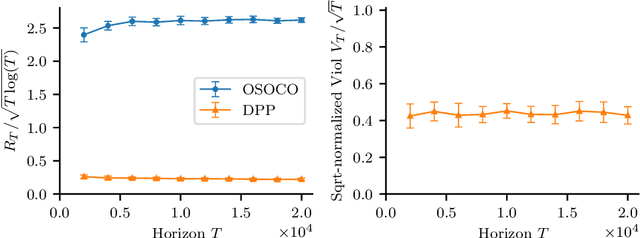
The setting of online convex optimization (OCO) under unknown constraints has garnered significant attention in recent years. In this work, we consider a version of this problem with static linear constraints that the player receives noisy feedback of and must always satisfy. By leveraging our novel design paradigm of optimistic safety, we give an algorithm for this problem that enjoys $\tilde{\mathcal{O}}(\sqrt{T})$ regret. This improves on the previous best regret bound of $\tilde{\mathcal{O}}(T^{2/3})$ while using only slightly stronger assumptions of independent noise and an oblivious adversary. Then, by recasting this problem as OCO under time-varying stochastic linear constraints, we show that our algorithm enjoys the same regret guarantees in such a setting and never violates the constraints in expectation. This contributes to the literature on OCO under time-varying stochastic constraints, where the state-of-the-art algorithms enjoy $\tilde{\mathcal{O}}(\sqrt{T})$ regret and $\tilde{\mathcal{O}}(\sqrt{T})$ violation when the constraints are convex and the player receives full feedback. Additionally, we provide a version of our algorithm that is more computationally efficient and give numerical experiments comparing it with benchmark algorithms.
IMU as an Input vs. a Measurement of the State in Inertial-Aided State Estimation
Mar 09, 2024
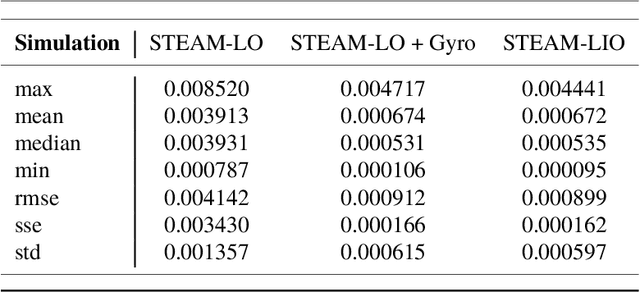
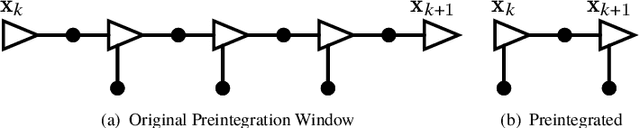
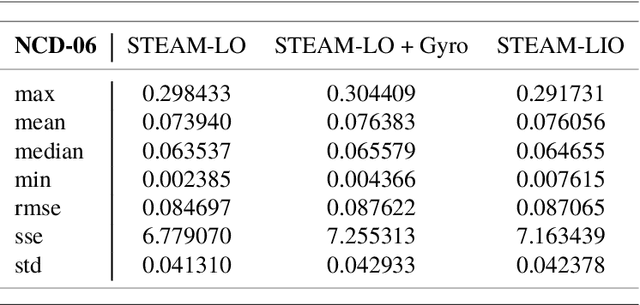
In this technical report, we compare treating an IMU as an input to a motion model against treating it as a measurement of the state in a continuous-time state estimation framework. Treating IMU measurements as inputs to a motion model and then preintegrating these measurements has almost become a de-facto standard in many robotics applications. However, this approach has a few shortcomings. First, it conflates the IMU measurement noise with the underlying process noise. Second, it is unclear how the state will be propagated in the case of IMU measurement dropout. Third, it does not lend itself well to dealing with multiple high-rate sensors such as a lidar and an IMU or multiple IMUs. In this work, we methodically compare the performance of these two approaches on a 1D simulation and show that they perform identically, assuming that each method's hyperparameters have been tuned on a training set. We show how to preintegrate heterogeneous factors using Gaussian process interpolation. We also provide results for our continuous-time lidar-inertial odometry in simulation and on the Newer College Dataset. Code for our lidar-inertial odometry can be found at: https://github.com/utiasASRL/steam_icp
RLPeri: Accelerating Visual Perimetry Test with Reinforcement Learning and Convolutional Feature Extraction
Mar 08, 2024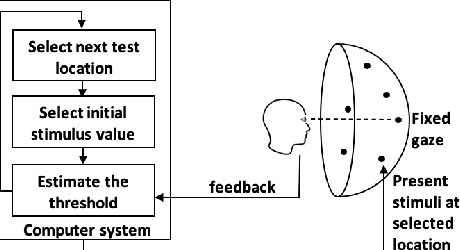
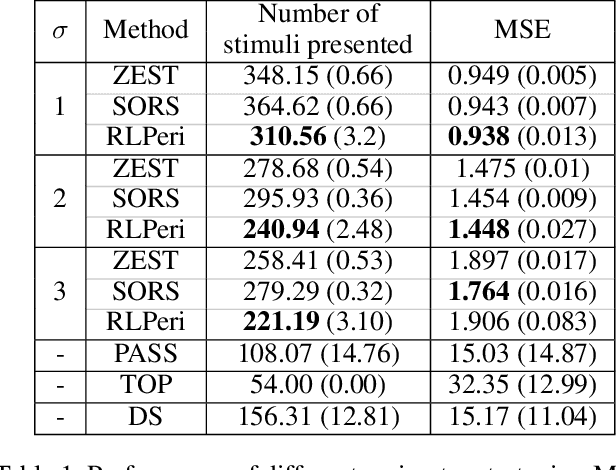
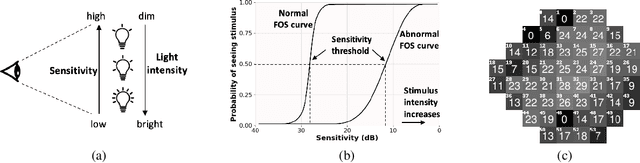
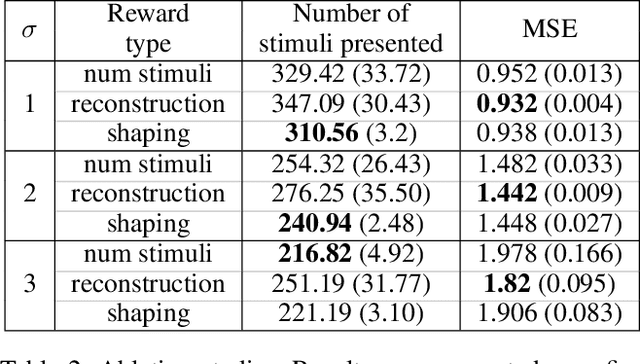
Visual perimetry is an important eye examination that helps detect vision problems caused by ocular or neurological conditions. During the test, a patient's gaze is fixed at a specific location while light stimuli of varying intensities are presented in central and peripheral vision. Based on the patient's responses to the stimuli, the visual field mapping and sensitivity are determined. However, maintaining high levels of concentration throughout the test can be challenging for patients, leading to increased examination times and decreased accuracy. In this work, we present RLPeri, a reinforcement learning-based approach to optimize visual perimetry testing. By determining the optimal sequence of locations and initial stimulus values, we aim to reduce the examination time without compromising accuracy. Additionally, we incorporate reward shaping techniques to further improve the testing performance. To monitor the patient's responses over time during testing, we represent the test's state as a pair of 3D matrices. We apply two different convolutional kernels to extract spatial features across locations as well as features across different stimulus values for each location. Through experiments, we demonstrate that our approach results in a 10-20% reduction in examination time while maintaining the accuracy as compared to state-of-the-art methods. With the presented approach, we aim to make visual perimetry testing more efficient and patient-friendly, while still providing accurate results.
* Published at AAAI-24
Space-Time Bridge-Diffusion
Feb 13, 2024In this study, we introduce a novel method for generating new synthetic samples that are independent and identically distributed (i.i.d.) from high-dimensional real-valued probability distributions, as defined implicitly by a set of Ground Truth (GT) samples. Central to our method is the integration of space-time mixing strategies that extend across temporal and spatial dimensions. Our methodology is underpinned by three interrelated stochastic processes designed to enable optimal transport from an easily tractable initial probability distribution to the target distribution represented by the GT samples: (a) linear processes incorporating space-time mixing that yield Gaussian conditional probability densities, (b) their bridge-diffusion analogs that are conditioned to the initial and final state vectors, and (c) nonlinear stochastic processes refined through score-matching techniques. The crux of our training regime involves fine-tuning the nonlinear model, and potentially the linear models - to align closely with the GT data. We validate the efficacy of our space-time diffusion approach with numerical experiments, laying the groundwork for more extensive future theory and experiments to fully authenticate the method, particularly providing a more efficient (possibly simulation-free) inference.
Physics-constrained Active Learning for Soil Moisture Estimation and Optimal Sensor Placement
Mar 12, 2024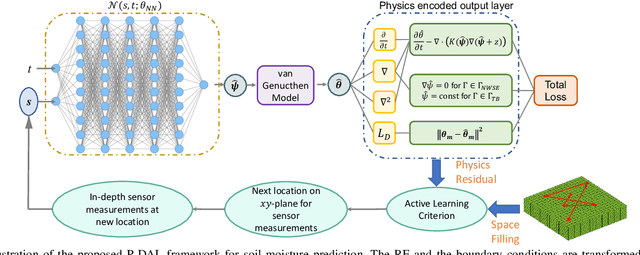
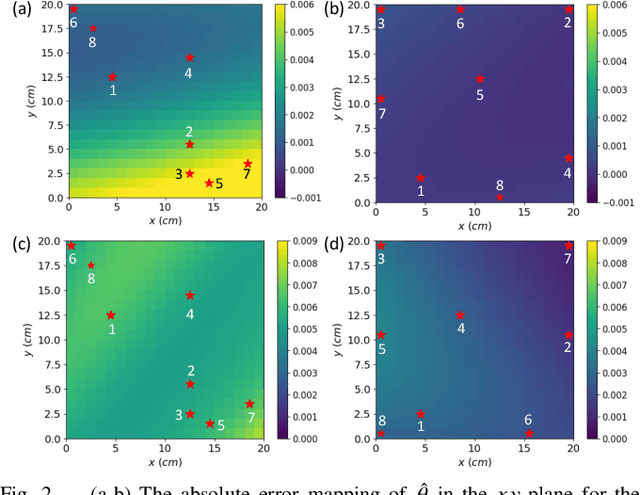
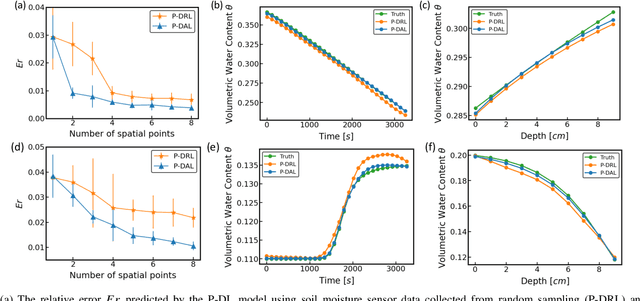
Soil moisture is a crucial hydrological state variable that has significant importance to the global environment and agriculture. Precise monitoring of soil moisture in crop fields is critical to reducing agricultural drought and improving crop yield. In-situ soil moisture sensors, which are buried at pre-determined depths and distributed across the field, are promising solutions for monitoring soil moisture. However, high-density sensor deployment is neither economically feasible nor practical. Thus, to achieve a higher spatial resolution of soil moisture dynamics using a limited number of sensors, we integrate a physics-based agro-hydrological model based on Richards' equation in a physics-constrained deep learning framework to accurately predict soil moisture dynamics in the soil's root zone. This approach ensures that soil moisture estimates align well with sensor observations while obeying physical laws at the same time. Furthermore, to strategically identify the locations for sensor placement, we introduce a novel active learning framework that combines space-filling design and physics residual-based sampling to maximize data acquisition potential with limited sensors. Our numerical results demonstrate that integrating Physics-constrained Deep Learning (P-DL) with an active learning strategy within a unified framework--named the Physics-constrained Active Learning (P-DAL) framework--significantly improves the predictive accuracy and effectiveness of field-scale soil moisture monitoring using in-situ sensors.
VANP: Learning Where to See for Navigation with Self-Supervised Vision-Action Pre-Training
Mar 12, 2024
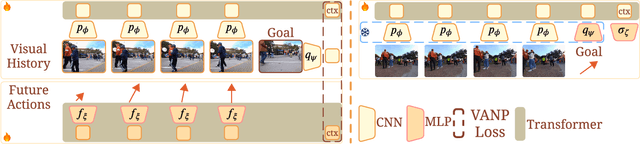

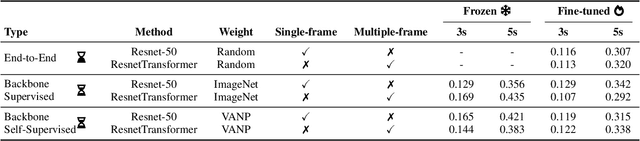
Humans excel at efficiently navigating through crowds without collision by focusing on specific visual regions relevant to navigation. However, most robotic visual navigation methods rely on deep learning models pre-trained on vision tasks, which prioritize salient objects -- not necessarily relevant to navigation and potentially misleading. Alternative approaches train specialized navigation models from scratch, requiring significant computation. On the other hand, self-supervised learning has revolutionized computer vision and natural language processing, but its application to robotic navigation remains underexplored due to the difficulty of defining effective self-supervision signals. Motivated by these observations, in this work, we propose a Self-Supervised Vision-Action Model for Visual Navigation Pre-Training (VANP). Instead of detecting salient objects that are beneficial for tasks such as classification or detection, VANP learns to focus only on specific visual regions that are relevant to the navigation task. To achieve this, VANP uses a history of visual observations, future actions, and a goal image for self-supervision, and embeds them using two small Transformer Encoders. Then, VANP maximizes the information between the embeddings by using a mutual information maximization objective function. We demonstrate that most VANP-extracted features match with human navigation intuition. VANP achieves comparable performance as models learned end-to-end with half the training time and models trained on a large-scale, fully supervised dataset, i.e., ImageNet, with only 0.08% data.
LHMap-loc: Cross-Modal Monocular Localization Using LiDAR Point Cloud Heat Map
Mar 11, 2024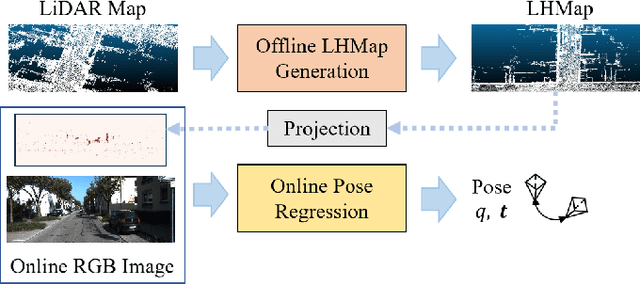
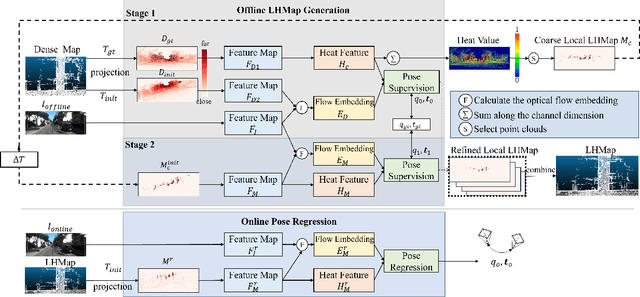
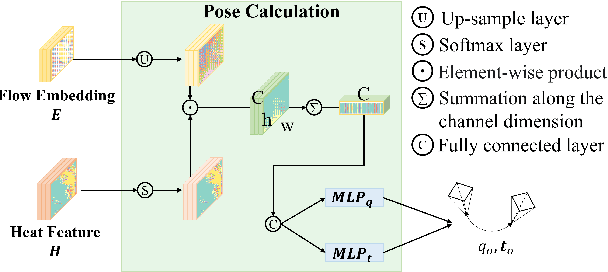

Localization using a monocular camera in the pre-built LiDAR point cloud map has drawn increasing attention in the field of autonomous driving and mobile robotics. However, there are still many challenges (e.g. difficulties of map storage, poor localization robustness in large scenes) in accurately and efficiently implementing cross-modal localization. To solve these problems, a novel pipeline termed LHMap-loc is proposed, which achieves accurate and efficient monocular localization in LiDAR maps. Firstly, feature encoding is carried out on the original LiDAR point cloud map by generating offline heat point clouds, by which the size of the original LiDAR map is compressed. Then, an end-to-end online pose regression network is designed based on optical flow estimation and spatial attention to achieve real-time monocular visual localization in a pre-built map. In addition, a series of experiments have been conducted to prove the effectiveness of the proposed method. Our code is available at: https://github.com/IRMVLab/LHMap-loc.