 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalytic Bridge Diffusions for Controlled Path Generation
May 03, 2026Most modern bridge-diffusion methods achieve finite-time transport by specifying an interpolation, Schrödinger-bridge, or stochastic-control objective and then learning the associated score or drift field with a neural network. In contrast, we identify a restricted but sufficiently broad and analytically solvable class in which the score, intermediate marginals, and protocol gradients are available in closed form without inner stochastic simulation loops and without neural networks in the optimization loop. We recast the classical linear--quadratic--Gaussian (LQG) stochastic-control structure as a transport problem of the Path Integral Diffusion (PID) type. In classical LQG control, linear dynamics, Gaussian noise, and quadratic costs lead to Riccati equations and closed-form optimal feedback. In LQ-GM-PID, we retain the linear--quadratic stochastic-control backbone, but replace terminal state regulation by a prescribed terminal probability density and allow both the initial and terminal laws to be Gaussian Mixtures (GM). Moreover, LQ-GM-PID turns bridge diffusion from a tool for terminal target matching alone into a tool for path shaping. We demonstrate this on a 2D corridor task, a 2D multi-entrance transport task, and a high-dimensional scaling study with $d=32$ and $M=16$ Gaussian-mixture terminal modes, all with sub-50\,ms analytic precompute on a laptop. We position LQ-GM-PID as an analytically solvable reference model for the state-of-the-art neural bridge-diffusion and generative-transport methods: a controlled setting in which neural approximations, score estimates, path-shaping objectives, and protocol-learning procedures can be tested against exact quantities.
Temporal Memory for Resource-Constrained Agents: Continual Learning via Stochastic Compress-Add-Smooth
Mar 31, 2026An agent that operates sequentially must incorporate new experience without forgetting old experience, under a fixed memory budget. We propose a framework in which memory is not a parameter vector but a stochastic process: a Bridge Diffusion on a replay interval $[0,1]$, whose terminal marginal encodes the present and whose intermediate marginals encode the past. New experience is incorporated via a three-step \emph{Compress--Add--Smooth} (CAS) recursion. We test the framework on the class of models with marginal probability densities modeled via Gaussian mixtures of fixed number of components~$K$ in $d$ dimensions; temporal complexity is controlled by a fixed number~$L$ of piecewise-linear protocol segments whose nodes store Gaussian-mixture states. The entire recursion costs $O(LKd^2)$ flops per day -- no backpropagation, no stored data, no neural networks -- making it viable for controller-light hardware. Forgetting in this framework arises not from parameter interference but from lossy temporal compression: the re-approximation of a finer protocol by a coarser one under a fixed segment budget. We find that the retention half-life scales linearly as $a_{1/2}\approx c\,L$ with a constant $c>1$ that depends on the dynamics but not on the mixture complexity~$K$, the dimension~$d$, or the geometry of the target family. The constant~$c$ admits an information-theoretic interpretation analogous to the Shannon channel capacity. The stochastic process underlying the bridge provides temporally coherent ``movie'' replay -- compressed narratives of the agent's history, demonstrated visually on an MNIST latent-space illustration. The framework provides a fully analytical ``Ising model'' of continual learning in which the mechanism, rate, and form of forgetting can be studied with mathematical precision.
Sampling Decisions
Mar 17, 2025In this manuscript we introduce a novel Decision Flow (DF) framework for sampling from a target distribution while incorporating additional guidance from a prior sampler. DF can be viewed as an AI driven algorithmic reincarnation of the Markov Decision Process (MDP) approach in Stochastic Optimal Control. It extends the continuous space, continuous time path Integral Diffusion sampling technique to discrete time and space, while also generalizing the Generative Flow Network framework. In its most basic form, an explicit, Neural Network (NN) free formulation, DF leverages the linear solvability of the the underlying MDP to adjust the transition probabilities of the prior sampler. The resulting Markov Process is expressed as a convolution of the reverse time Green's function of the prior sampling with the target distribution. We illustrate the DF framework through an example of sampling from the Ising model, discuss potential NN based extensions, and outline how DF can enhance guided sampling across various applications.
Space-Time Bridge-Diffusion
Feb 13, 2024



In this study, we introduce a novel method for generating new synthetic samples that are independent and identically distributed (i.i.d.) from high-dimensional real-valued probability distributions, as defined implicitly by a set of Ground Truth (GT) samples. Central to our method is the integration of space-time mixing strategies that extend across temporal and spatial dimensions. Our methodology is underpinned by three interrelated stochastic processes designed to enable optimal transport from an easily tractable initial probability distribution to the target distribution represented by the GT samples: (a) linear processes incorporating space-time mixing that yield Gaussian conditional probability densities, (b) their bridge-diffusion analogs that are conditioned to the initial and final state vectors, and (c) nonlinear stochastic processes refined through score-matching techniques. The crux of our training regime involves fine-tuning the nonlinear model, and potentially the linear models - to align closely with the GT data. We validate the efficacy of our space-time diffusion approach with numerical experiments, laying the groundwork for more extensive future theory and experiments to fully authenticate the method, particularly providing a more efficient (possibly simulation-free) inference.
U-Turn Diffusion
Aug 14, 2023We present a comprehensive examination of score-based diffusion models of AI for generating synthetic images. These models hinge upon a dynamic auxiliary time mechanism driven by stochastic differential equations, wherein the score function is acquired from input images. Our investigation unveils a criterion for evaluating efficiency of the score-based diffusion models: the power of the generative process depends on the ability to de-construct fast correlations during the reverse/de-noising phase. To improve the quality of the produced synthetic images, we introduce an approach coined "U-Turn Diffusion". The U-Turn Diffusion technique starts with the standard forward diffusion process, albeit with a condensed duration compared to conventional settings. Subsequently, we execute the standard reverse dynamics, initialized with the concluding configuration from the forward process. This U-Turn Diffusion procedure, combining forward, U-turn, and reverse processes, creates a synthetic image approximating an independent and identically distributed (i.i.d.) sample from the probability distribution implicitly described via input samples. To analyze relevant time scales we employ various analytical tools, including auto-correlation analysis, weighted norm of the score-function analysis, and Kolmogorov-Smirnov Gaussianity test. The tools guide us to establishing that the Kernel Intersection Distance, a metric comparing the quality of synthetic samples with real data samples, is minimized at the optimal U-turn time.
A Physics-Informed Machine Learning for Electricity Markets: A NYISO Case Study
Mar 31, 2023



This paper addresses the challenge of efficiently solving the optimal power flow problem in real-time electricity markets. The proposed solution, named Physics-Informed Market-Aware Active Set learning OPF (PIMA-AS-OPF), leverages physical constraints and market properties to ensure physical and economic feasibility of market-clearing outcomes. Specifically, PIMA-AS-OPF employs the active set learning technique and expands its capabilities to account for curtailment in load or renewable power generation, which is a common challenge in real-world power systems. The core of PIMA-AS-OPF is a fully-connected neural network that takes the net load and the system topology as input. The outputs of this neural network include active constraints such as saturated generators and transmission lines, as well as non-zero load shedding and wind curtailments. These outputs allow for reducing the original market-clearing optimization to a system of linear equations, which can be solved efficiently and yield both the dispatch decisions and the locational marginal prices (LMPs). The dispatch decisions and LMPs are then tested for their feasibility with respect to the requirements for efficient market-clearing results. The accuracy and scalability of the proposed method is tested on a realistic 1814-bus NYISO system with current and future renewable energy penetration levels.
Exact Fractional Inference via Re-Parametrization & Interpolation between Tree-Re-Weighted- and Belief Propagation- Algorithms
Jan 25, 2023Inference efforts -- required to compute partition function, $Z$, of an Ising model over a graph of $N$ ``spins" -- are most likely exponential in $N$. Efficient variational methods, such as Belief Propagation (BP) and Tree Re-Weighted (TRW) algorithms, compute $Z$ approximately minimizing respective (BP- or TRW-) free energy. We generalize the variational scheme building a $\lambda$-fractional-homotopy, $Z^{(\lambda)}$, where $\lambda=0$ and $\lambda=1$ correspond to TRW- and BP-approximations, respectively, and $Z^{(\lambda)}$ decreases with $\lambda$ monotonically. Moreover, this fractional scheme guarantees that in the attractive (ferromagnetic) case $Z^{(TRW)}\geq Z^{(\lambda)}\geq Z^{(BP)}$, and there exists a unique (``exact") $\lambda_*$ such that, $Z=Z^{(\lambda_*)}$. Generalizing the re-parametrization approach of \cite{wainwright_tree-based_2002} and the loop series approach of \cite{chertkov_loop_2006}, we show how to express $Z$ as a product, $\forall \lambda:\ Z=Z^{(\lambda)}{\cal Z}^{(\lambda)}$, where the multiplicative correction, ${\cal Z}^{(\lambda)}$, is an expectation over a node-independent probability distribution built from node-wise fractional marginals. Our theoretical analysis is complemented by extensive experiments with models from Ising ensembles over planar and random graphs of medium- and large- sizes. The empirical study yields a number of interesting observations, such as (a) ability to estimate ${\cal Z}^{(\lambda)}$ with $O(N^4)$ fractional samples; (b) suppression of $\lambda_*$ fluctuations with increase in $N$ for instances from a particular random Ising ensemble.
Machine Learning for Electricity Market Clearing
May 23, 2022
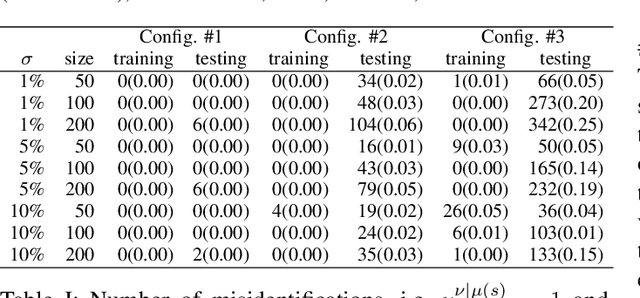

This paper seeks to design a machine learning twin of the optimal power flow (OPF) optimization, which is used in market-clearing procedures by wholesale electricity markets. The motivation for the proposed approach stems from the need to obtain the digital twin, which is much faster than the original, while also being sufficiently accurate and producing consistent generation dispatches and locational marginal prices (LMPs), which are primal and dual solutions of the OPF optimization, respectively. Availability of market-clearing tools based on this approach will enable computationally tractable evaluation of multiple dispatch scenarios under a given unit commitment. Rather than direct solution of OPF, the Karush-Kuhn-Tucker (KKT) conditions for the OPF problem in question may be written, and in parallel the LMPs of generators and loads may be expressed in terms of the OPF Lagrangian multipliers. Also, taking advantage of the practical fact that many of the Lagrangian multipliers associated with lines will be zero (thermal limits are not binding), we build and train an ML scheme which maps flexible resources (loads and renewables) to the binding lines, and supplement it with an efficient power-grid aware linear map to optimal dispatch and LMPs. The scheme is validated and illustrated on IEEE models. We also report a trade of analysis between quality of the reconstruction and number of samples needed to train the model.
* Accepted for presentation in 11th Bulk Power Systems Dynamics Sympsium (IREP 2022), July 25-30, 2022, Banff, Canada
Model Reduction of Swing Equations with Physics Informed PDE
Oct 26, 2021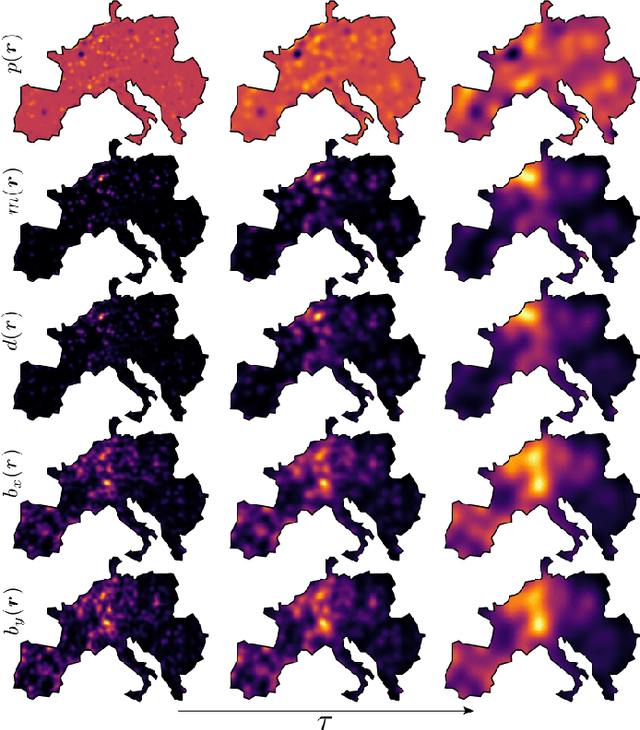
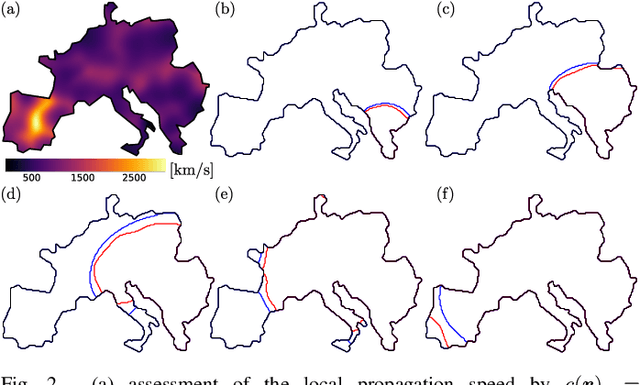
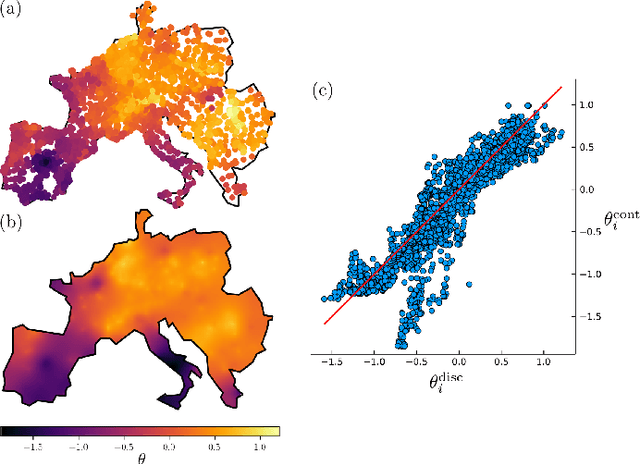
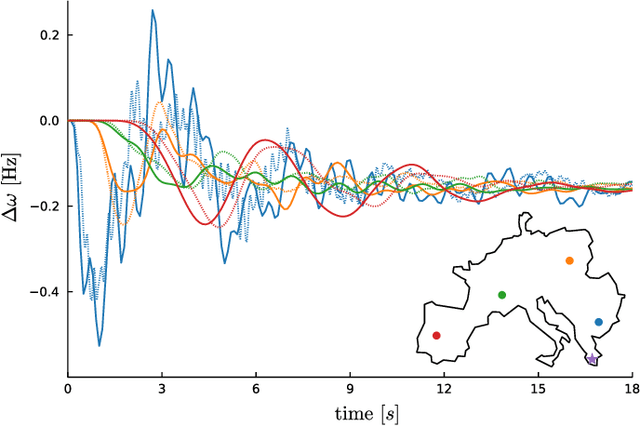
This manuscript is the first step towards building a robust and efficient model reduction methodology to capture transient dynamics in a transmission level electric power system. Such dynamics is normally modeled on seconds-to-tens-of-seconds time scales by the so-called swing equations, which are ordinary differential equations defined on a spatially discrete model of the power grid. We suggest, following Seymlyen (1974) and Thorpe, Seyler and Phadke (1999), to map the swing equations onto a linear, inhomogeneous Partial Differential Equation (PDE) of parabolic type in two space and one time dimensions with time-independent coefficients and properly defined boundary conditions. The continuous two-dimensional spatial domain is defined by a geographical map of the area served by the power grid, and associated with the PDE coefficients derived from smoothed graph-Laplacian of susceptances, machine inertia and damping. Inhomogeneous source terms represent spatially distributed injection/consumption of power. We illustrate our method on PanTaGruEl (Pan-European Transmission Grid and ELectricity generation model). We show that, when properly coarse-grained, i.e. with the PDE coefficients and source terms extracted from a spatial convolution procedure of the respective discrete coefficients in the swing equations, the resulting PDE reproduces faithfully and efficiently the original swing dynamics. We finally discuss future extensions of this work, where the presented PDE-based reduced modeling will initialize a physics-informed machine learning approach for real-time modeling, $n-1$ feasibility assessment and transient stability analysis of power systems.
Physics Informed Machine Learning of SPH: Machine Learning Lagrangian Turbulence
Oct 25, 2021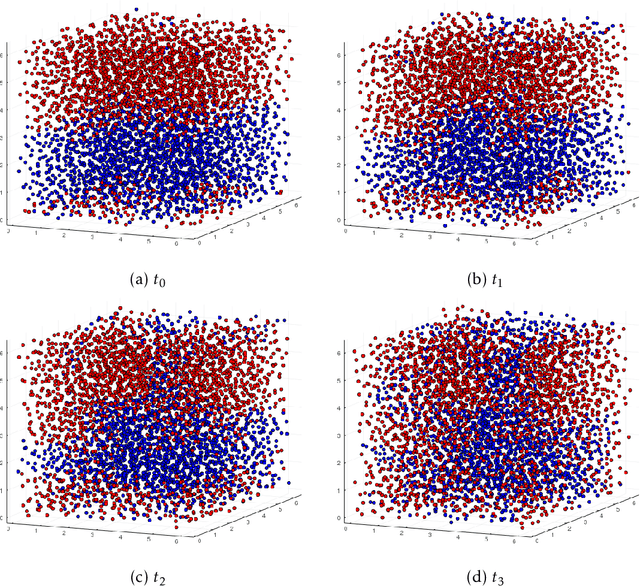
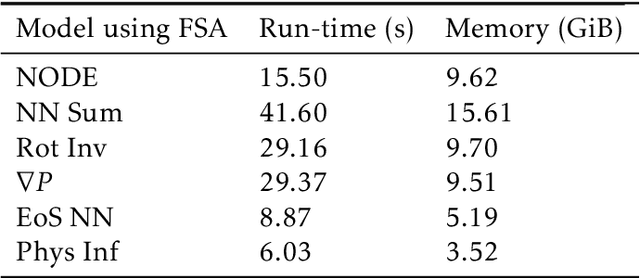
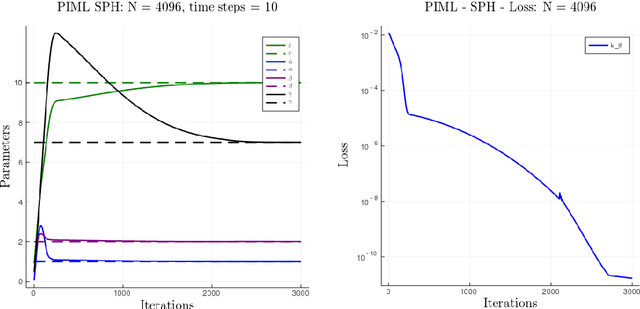
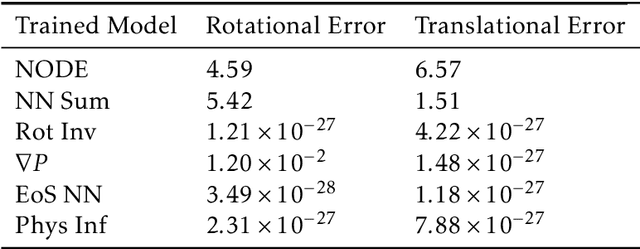
Smoothed particle hydrodynamics (SPH) is a mesh-free Lagrangian method for obtaining approximate numerical solutions of the equations of fluid dynamics; which has been widely applied to weakly- and strongly compressible turbulence in astrophysics and engineering applications. We present a learn-able hierarchy of parameterized and "physics-explainable" SPH informed fluid simulators using both physics based parameters and Neural Networks (NNs) as universal function approximators. Our learning algorithm develops a mixed mode approach, mixing forward and reverse mode automatic differentiation with forward and adjoint based sensitivity analyses to efficiently perform gradient based optimization. We show that our physics informed learning method is capable of: (a) solving inverse problems over the physically interpretable parameter space, as well as over the space of NN parameters; (b) learning Lagrangian statistics of turbulence (interpolation); (c) combining Lagrangian trajectory based, probabilistic, and Eulerian field based loss functions; and (d) extrapolating beyond training sets into more complex regimes of interest. Furthermore, this hierarchy of models gradually introduces more physical structure, which we show improves interpretability, generalizability (over larger ranges of time scales and Reynolds numbers), preservation of physical symmetries, and requires less training data.