 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Contrastive Language-Vision AI Models Pretrained on Web-Scraped Multimodal Data Exhibit Sexual Objectification Bias
Dec 21, 2022
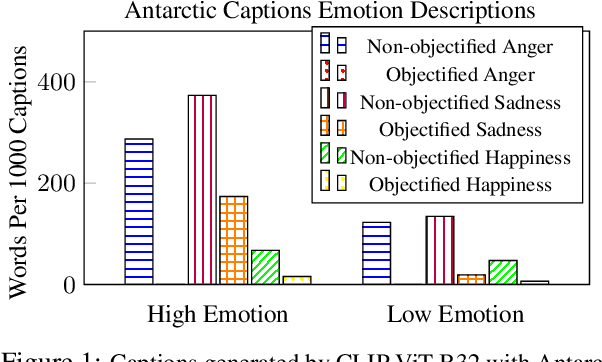
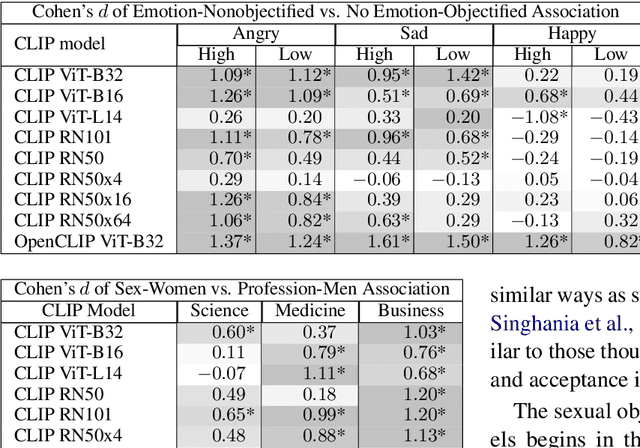
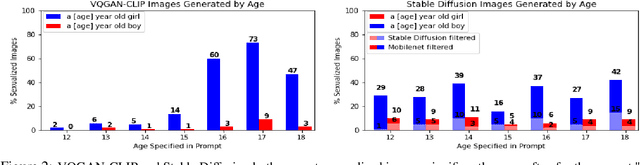
Nine language-vision AI models trained on web scrapes with the Contrastive Language-Image Pretraining (CLIP) objective are evaluated for evidence of a bias studied by psychologists: the sexual objectification of girls and women, which occurs when a person's human characteristics are disregarded and the person is treated as a body or a collection of body parts. A first experiment uses standardized images of women from the Sexual OBjectification and EMotion Database, and finds that, commensurate with prior research in psychology, human characteristics are disassociated from images of objectified women: the model's recognition of emotional state is mediated by whether the subject is fully or partially clothed. Embedding association tests (EATs) return significant effect sizes for both anger (d >.8) and sadness (d >.5). A second experiment measures the effect in a representative application: an automatic image captioner (Antarctic Captions) includes words denoting emotion less than 50% as often for images of partially clothed women than for images of fully clothed women. A third experiment finds that images of female professionals (scientists, doctors, executives) are likely to be associated with sexual descriptions relative to images of male professionals. A fourth experiment shows that a prompt of "a [age] year old girl" generates sexualized images (as determined by an NSFW classifier) up to 73% of the time for VQGAN-CLIP (age 17), and up to 40% of the time for Stable Diffusion (ages 14 and 18); the corresponding rate for boys never surpasses 9%. The evidence indicates that language-vision AI models trained on automatically collected web scrapes learn biases of sexual objectification, which propagate to downstream applications.
Semi-Structured Object Sequence Encoders
Jan 10, 2023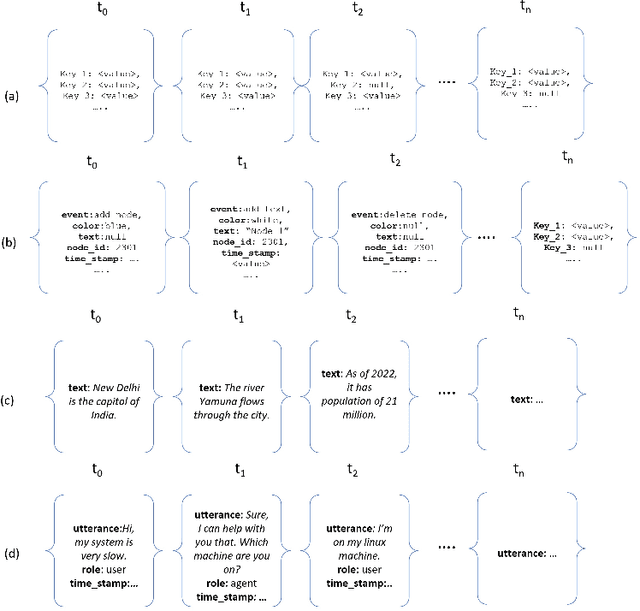

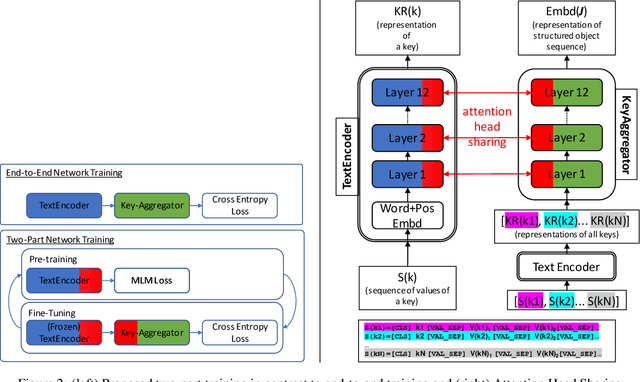
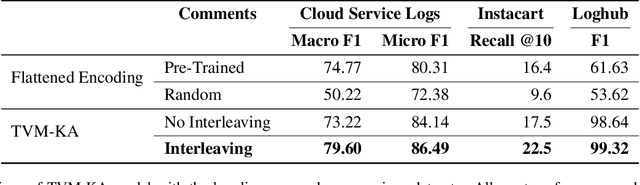
In this paper we explore the task of modeling (semi) structured object sequences; in particular we focus our attention on the problem of developing a structure-aware input representation for such sequences. In such sequences, we assume that each structured object is represented by a set of key-value pairs which encode the attributes of the structured object. Given a universe of keys, a sequence of structured objects can then be viewed as an evolution of the values for each key, over time. We encode and construct a sequential representation using the values for a particular key (Temporal Value Modeling - TVM) and then self-attend over the set of key-conditioned value sequences to a create a representation of the structured object sequence (Key Aggregation - KA). We pre-train and fine-tune the two components independently and present an innovative training schedule that interleaves the training of both modules with shared attention heads. We find that this iterative two part-training results in better performance than a unified network with hierarchical encoding as well as over, other methods that use a {\em record-view} representation of the sequence \cite{de2021transformers4rec} or a simple {\em flattened} representation of the sequence. We conduct experiments using real-world data to demonstrate the advantage of interleaving TVM-KA on multiple tasks and detailed ablation studies motivating our modeling choices. We find that our approach performs better than flattening sequence objects and also allows us to operate on significantly larger sequences than existing methods.
MGTANet: Encoding Sequential LiDAR Points Using Long Short-Term Motion-Guided Temporal Attention for 3D Object Detection
Dec 01, 2022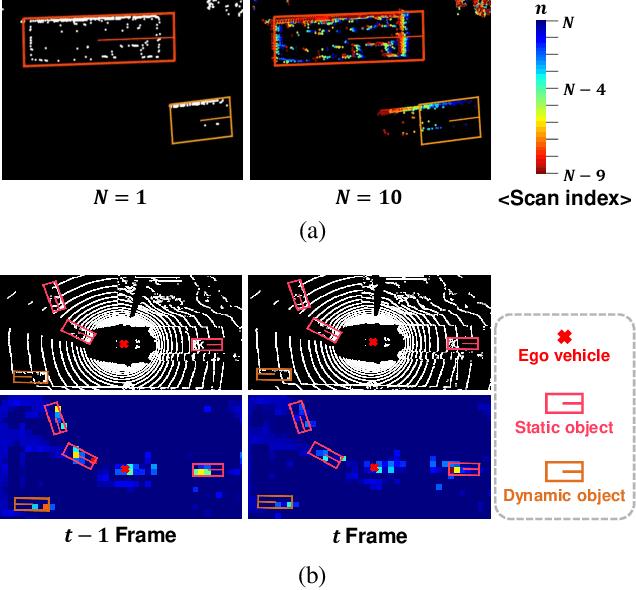
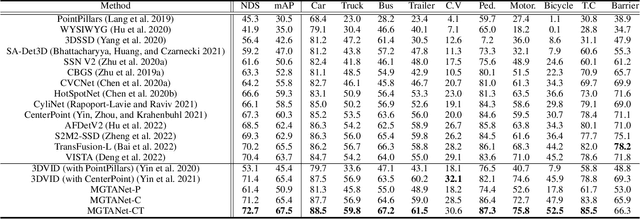
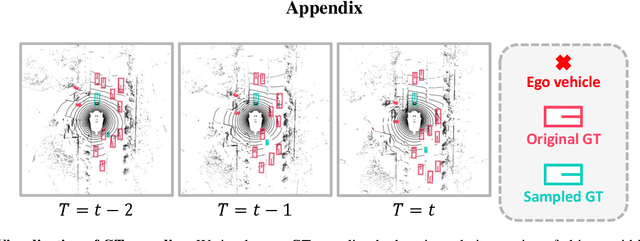
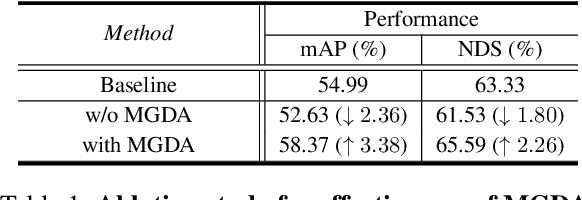
Most scanning LiDAR sensors generate a sequence of point clouds in real-time. While conventional 3D object detectors use a set of unordered LiDAR points acquired over a fixed time interval, recent studies have revealed that substantial performance improvement can be achieved by exploiting the spatio-temporal context present in a sequence of LiDAR point sets. In this paper, we propose a novel 3D object detection architecture, which can encode LiDAR point cloud sequences acquired by multiple successive scans. The encoding process of the point cloud sequence is performed on two different time scales. We first design a short-term motion-aware voxel encoding that captures the short-term temporal changes of point clouds driven by the motion of objects in each voxel. We also propose long-term motion-guided bird's eye view (BEV) feature enhancement that adaptively aligns and aggregates the BEV feature maps obtained by the short-term voxel encoding by utilizing the dynamic motion context inferred from the sequence of the feature maps. The experiments conducted on the public nuScenes benchmark demonstrate that the proposed 3D object detector offers significant improvements in performance compared to the baseline methods and that it sets a state-of-the-art performance for certain 3D object detection categories. Code is available at https://github.com/HYjhkoh/MGTANet.git
RISNet: a Dedicated Scalable Neural Network Architecture for Optimization of Reconfigurable Intelligent Surfaces
Dec 06, 2022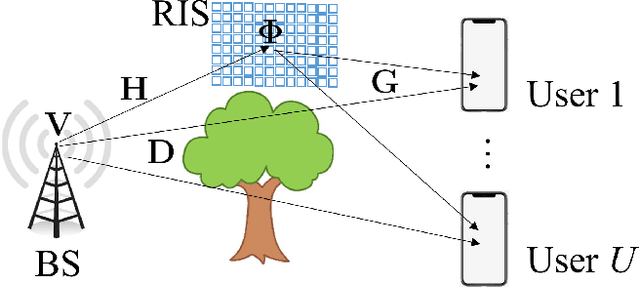
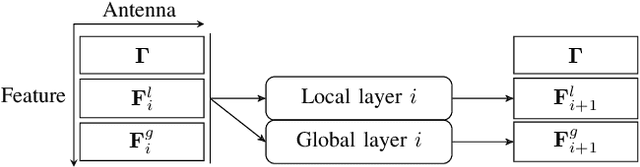
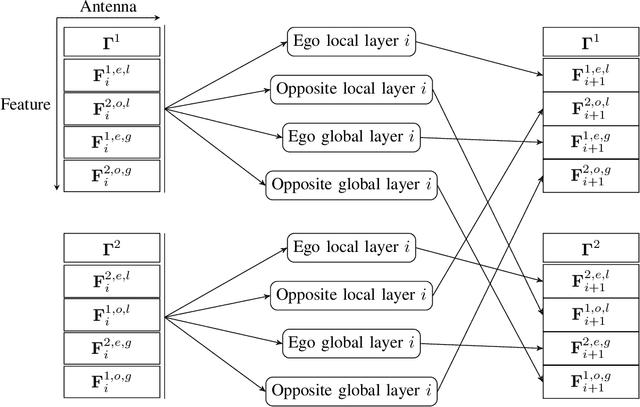
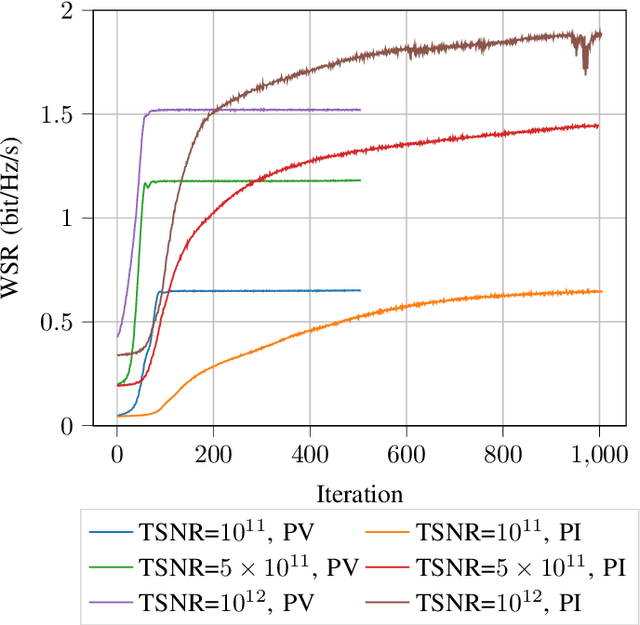
The reconfigurable intelligent surface (RIS) is a promising technology for next-generation wireless communication. It comprises many passive antennas, which reflect signals from the transmitter to the receiver with adjusted phases without changing the amplitude. The large number of the antennas enables a huge potential of signal processing despite the simple functionality of a single antenna. However, it also makes the RIS configuration a high dimensional problem, which might not have a closed-form solution and has a high complexity and, as a result, severe difficulty in online real-time application if we apply iterative numerical solutions. In this paper, we introduce a machine learning approach to maximize the weighted sum-rate (WSR). We propose a dedicated neural network architecture called RISNet. The RIS optimization is designed according to the RIS property of product and direct channel and homogeneous RIS antennas. The architecture is scalable due to the fact that the number of trainable parameters is independent from the number of RIS antennas (because all antennas share the same parameters). The weighted minimum mean squared error (WMMSE) precoding is applied and an alternating optimization (AO) training procedure is designed. Testing results show that the proposed approach outperforms the state-of-the-art block coordinate descent (BCD) algorithm. Moreover, although the training takes several hours, online testing with trained model (application) is almost instant, which makes it feasible for real-time application. Compared to it, the BCD algorithm requires much more convergence time. Therefore, the proposed method outperforms the state-of-the-art algorithm in both performance and complexity.
A Divide-Align-Conquer Strategy for Program Synthesis
Jan 08, 2023
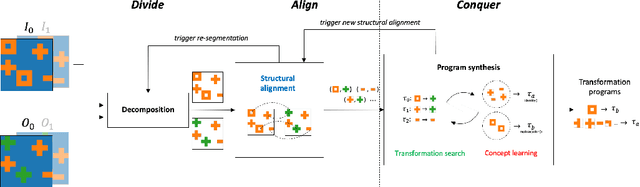
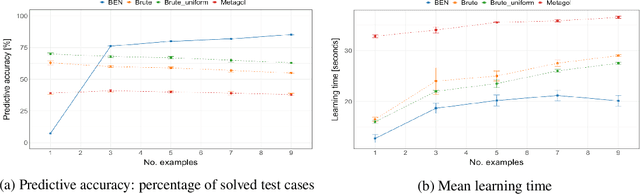
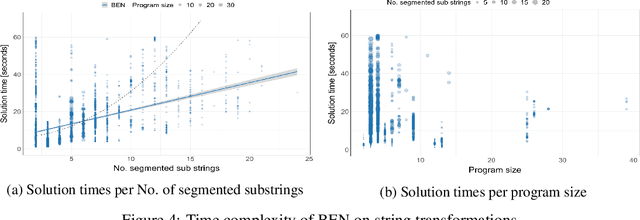
A major bottleneck in search-based program synthesis is the exponentially growing search space which makes learning large programs intractable. Humans mitigate this problem by leveraging the compositional nature of the real world: In structured domains, a logical specification can often be decomposed into smaller, complementary solution programs. We show that compositional segmentation can be applied in the programming by examples setting to divide the search for large programs across multiple smaller program synthesis problems. For each example, we search for a decomposition into smaller units which maximizes the reconstruction accuracy in the output under a latent task program. A structural alignment of the constituent parts in the input and output leads to pairwise correspondences used to guide the program synthesis search. In order to align the input/output structures, we make use of the Structure-Mapping Theory (SMT), a formal model of human analogical reasoning which originated in the cognitive sciences. We show that decomposition-driven program synthesis with structural alignment outperforms Inductive Logic Programming (ILP) baselines on string transformation tasks even with minimal knowledge priors. Unlike existing methods, the predictive accuracy of our agent monotonically increases for additional examples and achieves an average time complexity of $\mathcal{O}(m)$ in the number $m$ of partial programs for highly structured domains such as strings. We extend this method to the complex setting of visual reasoning in the Abstraction and Reasoning Corpus (ARC) for which ILP methods were previously infeasible.
STPrivacy: Spatio-Temporal Tubelet Sparsification and Anonymization for Privacy-preserving Action Recognition
Jan 08, 2023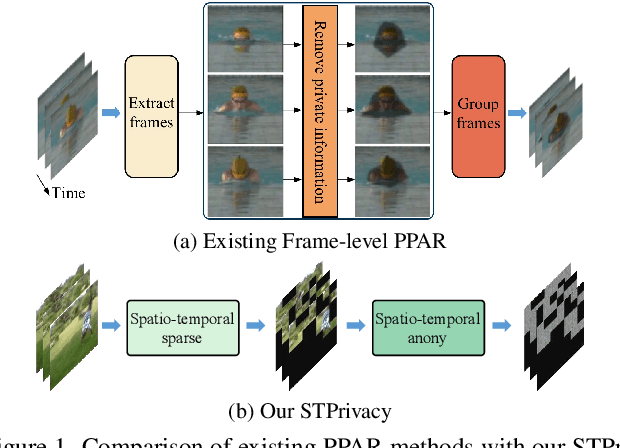
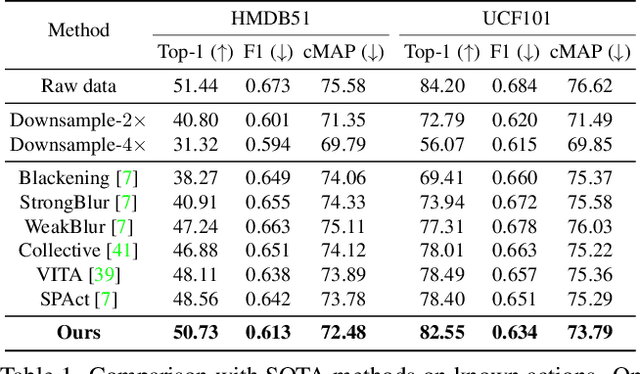
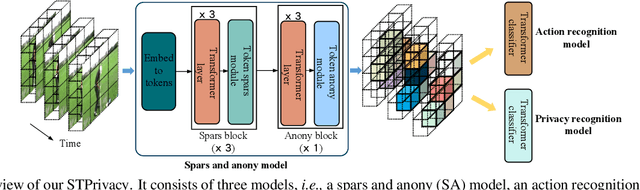
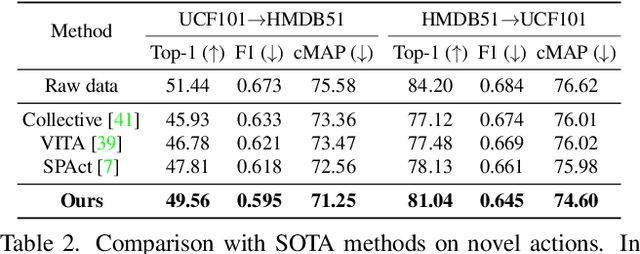
Recently privacy-preserving action recognition (PPAR) has been becoming an appealing video understanding problem. Nevertheless, existing works focus on the frame-level (spatial) privacy preservation, ignoring the privacy leakage from a whole video and destroying the temporal continuity of actions. In this paper, we present a novel PPAR paradigm, i.e., performing privacy preservation from both spatial and temporal perspectives, and propose a STPrivacy framework. For the first time, our STPrivacy applies vision Transformers to PPAR and regards a video as a sequence of spatio-temporal tubelets, showing outstanding advantages over previous convolutional methods. Specifically, our STPrivacy adaptively treats privacy-containing tubelets in two different manners. The tubelets irrelevant to actions are directly abandoned, i.e., sparsification, and not published for subsequent tasks. In contrast, those highly involved in actions are anonymized, i.e., anonymization, to remove private information. These two transformation mechanisms are complementary and simultaneously optimized in our unified framework. Because there is no large-scale benchmarks, we annotate five privacy attributes for two of the most popular action recognition datasets, i.e., HMDB51 and UCF101, and conduct extensive experiments on them. Moreover, to verify the generalization ability of our STPrivacy, we further introduce a privacy-preserving facial expression recognition task and conduct experiments on a large-scale video facial attributes dataset, i.e., Celeb-VHQ. The thorough comparisons and visualization analysis demonstrate our significant superiority over existing works. The appendix contains more details and visualizations.
Practical Exposure Correction: Great Truths Are Always Simple
Dec 29, 2022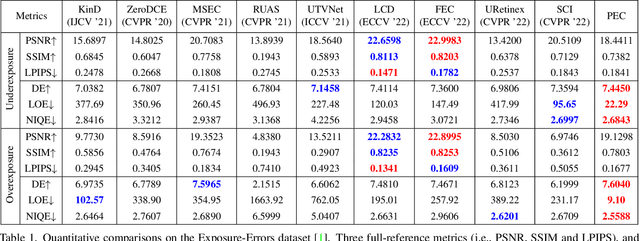
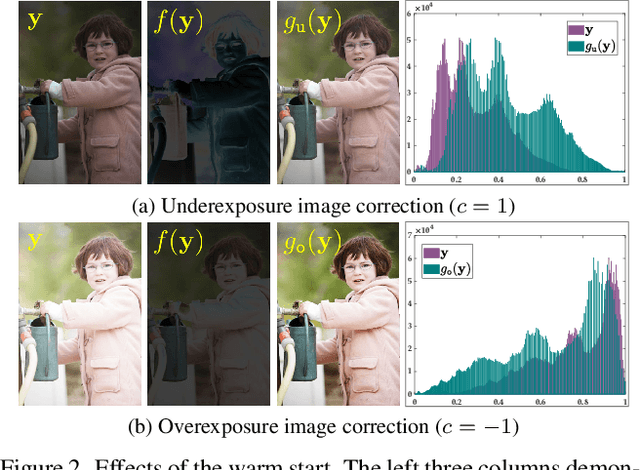
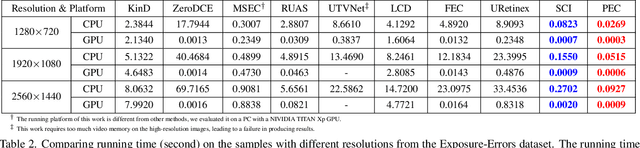
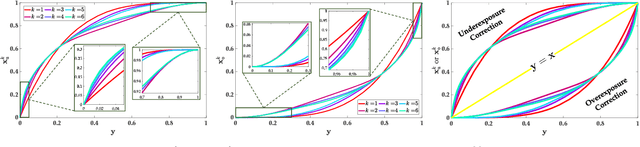
Improving the visual quality of the given degraded observation by correcting exposure level is a fundamental task in the computer vision community. Existing works commonly lack adaptability towards unknown scenes because of the data-driven patterns (deep networks) and limited regularization (traditional optimization), and they usually need time-consuming inference. These two points heavily limit their practicability. In this paper, we establish a Practical Exposure Corrector (PEC) that assembles the characteristics of efficiency and performance. To be concrete, we rethink the exposure correction to provide a linear solution with exposure-sensitive compensation. Around generating the compensation, we introduce an exposure adversarial function as the key engine to fully extract valuable information from the observation. By applying the defined function, we construct a segmented shrinkage iterative scheme to generate the desired compensation. Its shrinkage nature supplies powerful support for algorithmic stability and robustness. Extensive experimental evaluations fully reveal the superiority of our proposed PEC. The code is available at https://rsliu.tech/PEC.
Zero-Shot Object Segmentation through Concept Distillation from Generative Image Foundation Models
Dec 29, 2022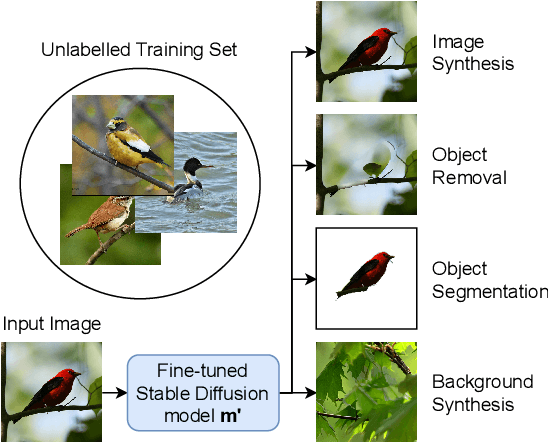
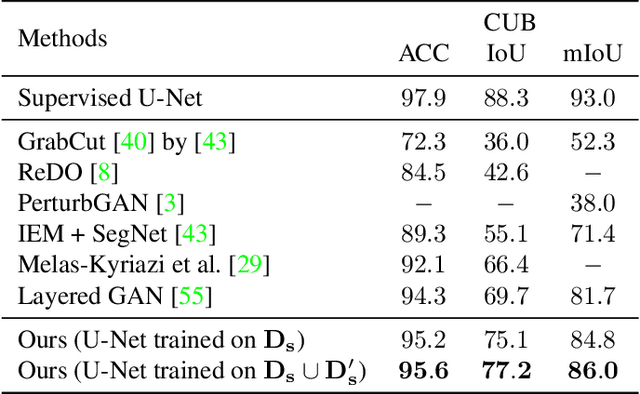
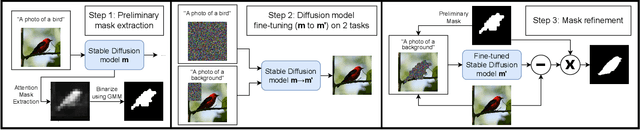

Curating datasets for object segmentation is a difficult task. With the advent of large-scale pre-trained generative models, conditional image generation has been given a significant boost in result quality and ease of use. In this paper, we present a novel method that enables the generation of general foreground-background segmentation models from simple textual descriptions, without requiring segmentation labels. We leverage and explore pre-trained latent diffusion models, to automatically generate weak segmentation masks for concepts and objects. The masks are then used to fine-tune the diffusion model on an inpainting task, which enables fine-grained removal of the object, while at the same time providing a synthetic foreground and background dataset. We demonstrate that using this method beats previous methods in both discriminative and generative performance and closes the gap with fully supervised training while requiring no pixel-wise object labels. We show results on the task of segmenting four different objects (humans, dogs, cars, birds).
A systems design approach for the co-design of a humanoid robot arm
Dec 29, 2022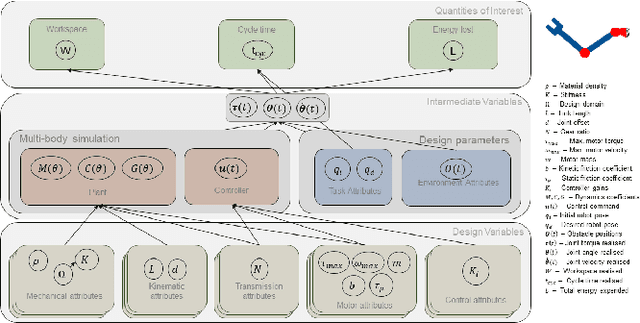
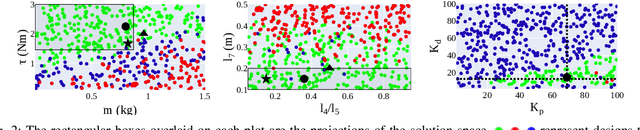

Classically, the development of humanoid robots has been sequential and iterative. Such bottom-up design procedures rely heavily on intuition and are often biased by the designer's experience. Exploiting the non-linear coupled design space of robots is non-trivial and requires a systematic procedure for exploration. We adopt the top-down design strategy, the V-model, used in automotive and aerospace industries. Our co-design approach identifies non-intuitive designs from within the design space and obtains the maximum permissible range of the design variables as a solution space, to physically realise the obtained design. We show that by constructing the solution space, one can (1) decompose higher-level requirements onto sub-system-level requirements with tolerance, alleviating the "chicken-or-egg" problem during the design process, (2) decouple the robot's morphology from its controller, enabling greater design flexibility, (3) obtain independent sub-system level requirements, reducing the development time by parallelising the development process.
HADA: A Graph-based Amalgamation Framework in Image-text Retrieval
Jan 11, 2023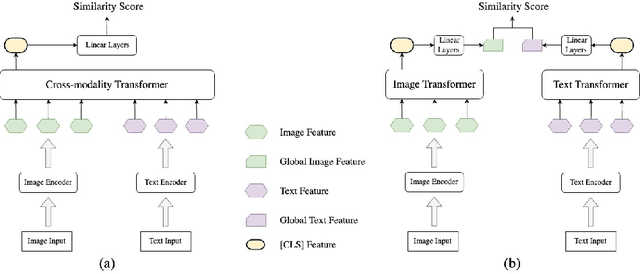
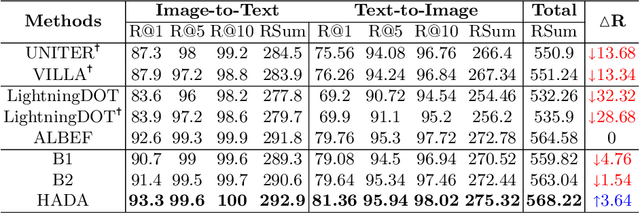
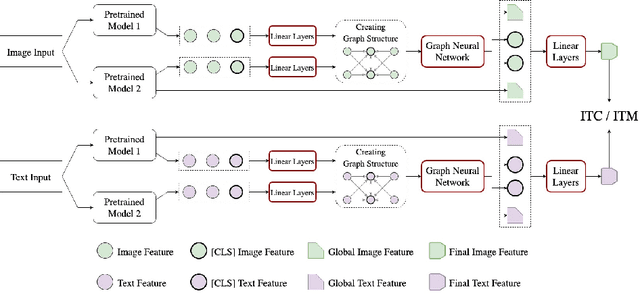
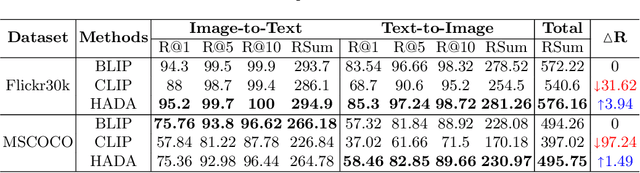
Many models have been proposed for vision and language tasks, especially the image-text retrieval task. All state-of-the-art (SOTA) models in this challenge contained hundreds of millions of parameters. They also were pretrained on a large external dataset that has been proven to make a big improvement in overall performance. It is not easy to propose a new model with a novel architecture and intensively train it on a massive dataset with many GPUs to surpass many SOTA models, which are already available to use on the Internet. In this paper, we proposed a compact graph-based framework, named HADA, which can combine pretrained models to produce a better result, rather than building from scratch. First, we created a graph structure in which the nodes were the features extracted from the pretrained models and the edges connecting them. The graph structure was employed to capture and fuse the information from every pretrained model with each other. Then a graph neural network was applied to update the connection between the nodes to get the representative embedding vector for an image and text. Finally, we used the cosine similarity to match images with their relevant texts and vice versa to ensure a low inference time. Our experiments showed that, although HADA contained a tiny number of trainable parameters, it could increase baseline performance by more than 3.6% in terms of evaluation metrics in the Flickr30k dataset. Additionally, the proposed model did not train on any external dataset and did not require many GPUs but only 1 to train due to its small number of parameters. The source code is available at https://github.com/m2man/HADA.