 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
UAV Tracking with Lidar as a Camera Sensors in GNSS-Denied Environments
Mar 01, 2023
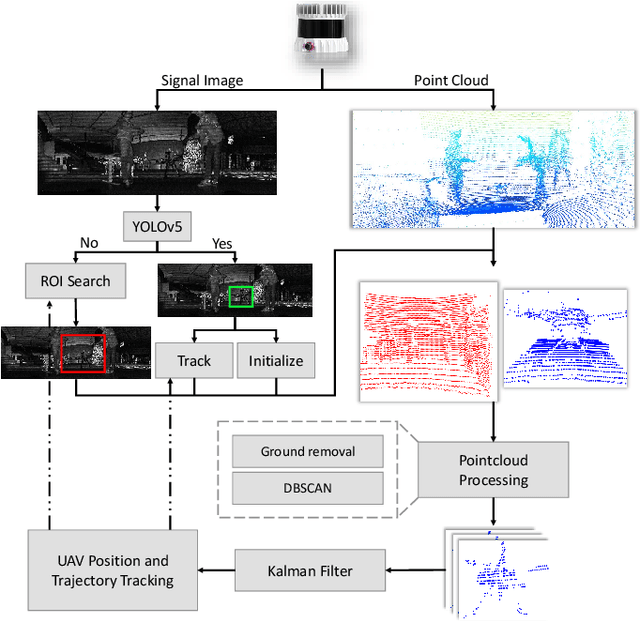
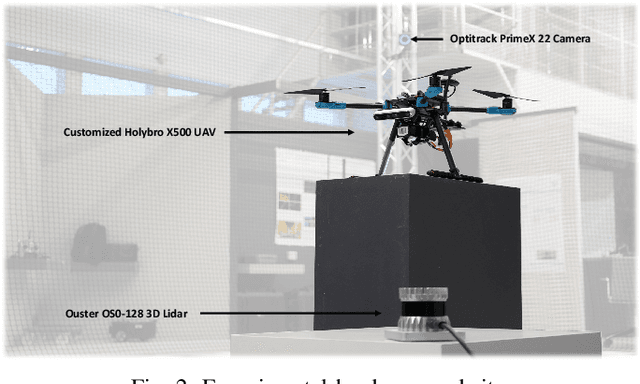
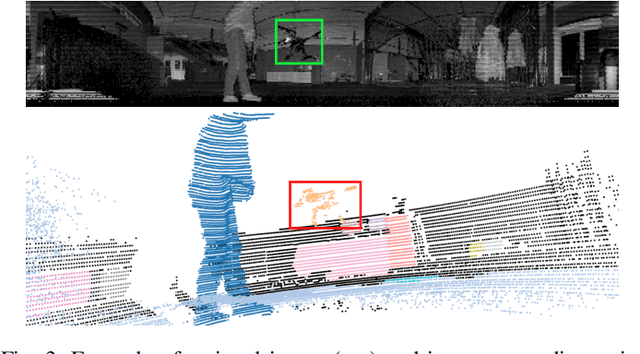
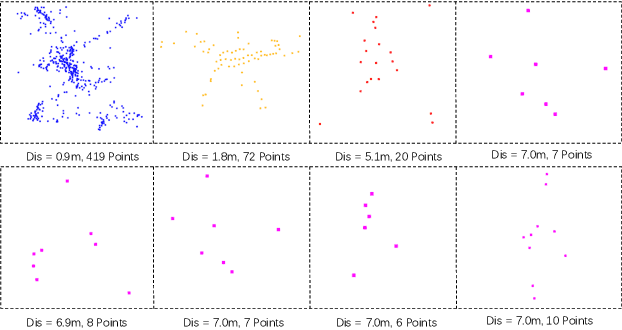
LiDAR has become one of the primary sensors in robotics and autonomous system for high-accuracy situational awareness. In recent years, multi-modal LiDAR systems emerged, and among them, LiDAR-as-a-camera sensors provide not only 3D point clouds but also fixed-resolution 360{\deg}panoramic images by encoding either depth, reflectivity, or near-infrared light in the image pixels. This potentially brings computer vision capabilities on top of the potential of LiDAR itself. In this paper, we are specifically interested in utilizing LiDARs and LiDAR-generated images for tracking Unmanned Aerial Vehicles (UAVs) in real-time which can benefit applications including docking, remote identification, or counter-UAV systems, among others. This is, to the best of our knowledge, the first work that explores the possibility of fusing the images and point cloud generated by a single LiDAR sensor to track a UAV without a priori known initialized position. We trained a custom YOLOv5 model for detecting UAVs based on the panoramic images collected in an indoor experiment arena with a MOCAP system. By integrating with the point cloud, we are able to continuously provide the position of the UAV. Our experiment demonstrated the effectiveness of the proposed UAV tracking approach compared with methods based only on point clouds or images. Additionally, we evaluated the real-time performance of our approach on the Nvidia Jetson Nano, a popular mobile computing platform.
Learning Input-agnostic Manipulation Directions in StyleGAN with Text Guidance
Feb 26, 2023With the advantages of fast inference and human-friendly flexible manipulation, image-agnostic style manipulation via text guidance enables new applications that were not previously available. The state-of-the-art text-guided image-agnostic manipulation method embeds the representation of each channel of StyleGAN independently in the Contrastive Language-Image Pre-training (CLIP) space, and provides it in the form of a Dictionary to quickly find out the channel-wise manipulation direction during inference time. However, in this paper we argue that this dictionary which is constructed by controlling single channel individually is limited to accommodate the versatility of text guidance since the collective and interactive relation among multiple channels are not considered. Indeed, we show that it fails to discover a large portion of manipulation directions that can be found by existing methods, which manually manipulates latent space without texts. To alleviate this issue, we propose a novel method that learns a Dictionary, whose entry corresponds to the representation of a single channel, by taking into account the manipulation effect coming from the interaction with multiple other channels. We demonstrate that our strategy resolves the inability of previous methods in finding diverse known directions from unsupervised methods and unknown directions from random text while maintaining the real-time inference speed and disentanglement ability.
Frugal day-ahead forecasting of multiple local electricity loads by aggregating adaptive models
Feb 16, 2023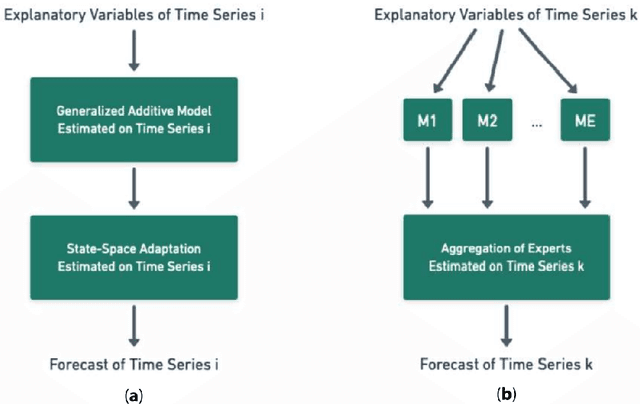
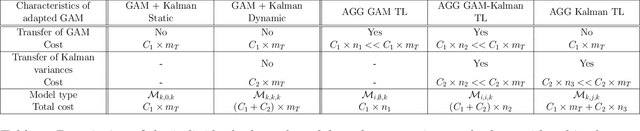
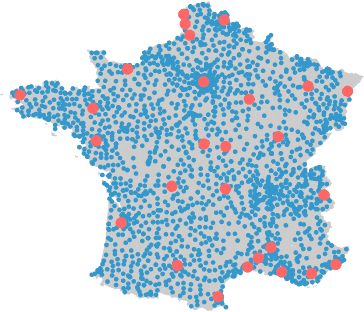
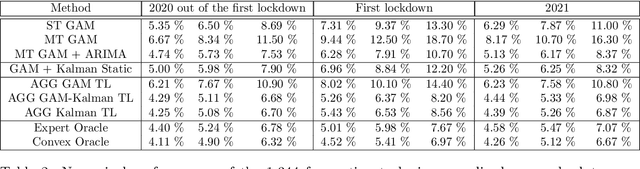
We focus on day-ahead electricity load forecasting of substations of the distribution network in France; therefore, our problem lies between the instability of a single consumption and the stability of a countrywide total demand. Moreover, we are interested in forecasting the loads of over one thousand substations; consequently, we are in the context of forecasting multiple time series. To that end, we rely on an adaptive methodology that provided excellent results at a national scale; the idea is to combine generalized additive models with state-space representations. However, the extension of this methodology to the prediction of over a thousand time series raises a computational issue. We solve it by developing a frugal variant, reducing the number of parameters estimated; we estimate the forecasting models only for a few time series and achieve transfer learning by relying on aggregation of experts. It yields a reduction of computational needs and their associated emissions. We build several variants, corresponding to different levels of parameter transfer, and we look for the best trade-off between accuracy and frugality. The selected method achieves competitive results compared to state-of-the-art individual models. Finally, we highlight the interpretability of the models, which is important for operational applications.
Active Learning of Discrete-Time Dynamics for Uncertainty-Aware Model Predictive Control
Oct 23, 2022
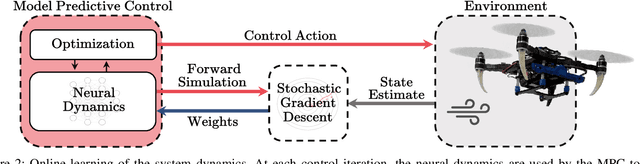


Model-based control requires an accurate model of the system dynamics for precisely and safely controlling the robot in complex and dynamic environments. Moreover, in presence of variations in the operating conditions, the model should be continuously refined to compensate for dynamics changes. In this paper, we propose a self-supervised learning approach to actively model robot discrete-time dynamics. We combine offline learning from past experience and online learning from present robot interaction with the unknown environment. These two ingredients enable highly sample-efficient and adaptive learning for accurate inference of the model dynamics in real-time even in operating regimes significantly different from the training distribution. Moreover, we design an uncertainty-aware model predictive controller that is conditioned to the aleatoric (data) uncertainty of the learned dynamics. The controller actively selects the optimal control actions that (i) optimize the control performance and (ii) boost the online learning sample efficiency. We apply the proposed method to a quadrotor system in multiple challenging real-world experiments. Our approach exhibits high flexibility and generalization capabilities by consistently adapting to unseen flight conditions, while it significantly outperforms classical and adaptive control baselines.
Subspace Perturbation Analysis for Data-Driven Radar Target Localization
Mar 14, 2023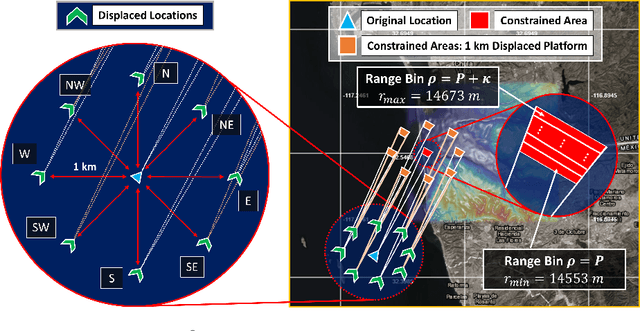
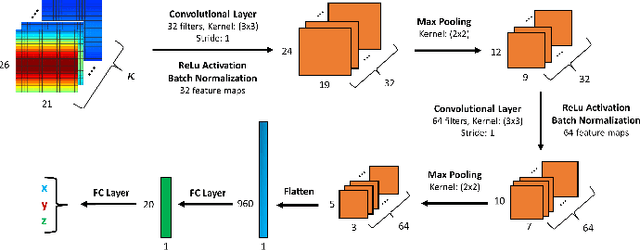
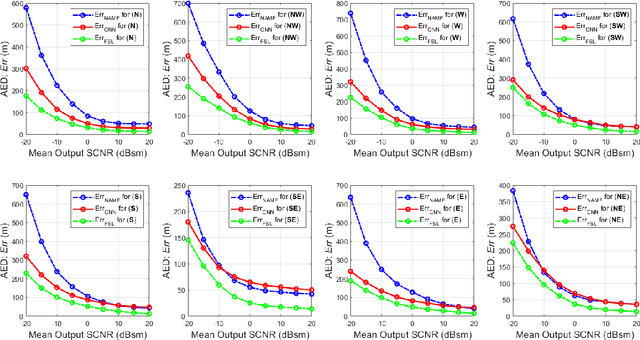

Recent works exploring data-driven approaches to classical problems in adaptive radar have demonstrated promising results pertaining to the task of radar target localization. Via the use of space-time adaptive processing (STAP) techniques and convolutional neural networks, these data-driven approaches to target localization have helped benchmark the performance of neural networks for matched scenarios. However, the thorough bridging of these topics across mismatched scenarios still remains an open problem. As such, in this work, we augment our data-driven approach to radar target localization by performing a subspace perturbation analysis, which allows us to benchmark the localization accuracy of our proposed deep learning framework across mismatched scenarios. To evaluate this framework, we generate comprehensive datasets by randomly placing targets of variable strengths in mismatched constrained areas via RFView, a high-fidelity, site-specific modeling and simulation tool. For the radar returns from these constrained areas, we generate heatmap tensors in range, azimuth, and elevation using the normalized adaptive matched filter (NAMF) test statistic. We estimate target locations from these heatmap tensors using a convolutional neural network, and demonstrate that the predictive performance of our framework in the presence of mismatches can be predetermined.
Neural Video Compression with Diverse Contexts
Mar 14, 2023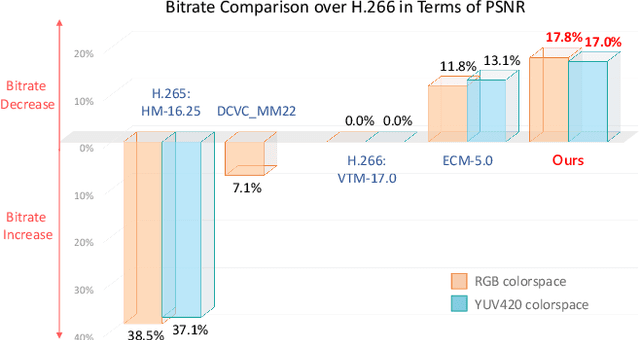
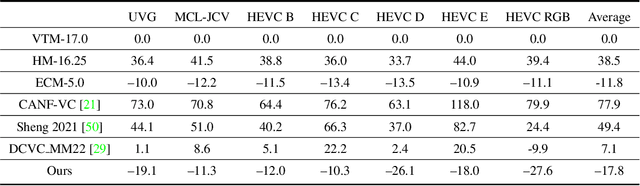
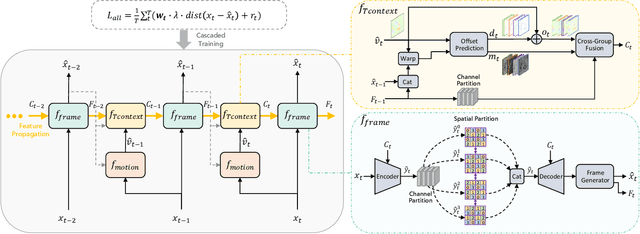
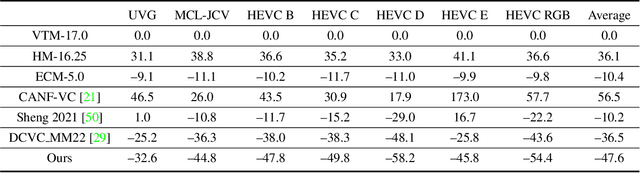
For any video codecs, the coding efficiency highly relies on whether the current signal to be encoded can find the relevant contexts from the previous reconstructed signals. Traditional codec has verified more contexts bring substantial coding gain, but in a time-consuming manner. However, for the emerging neural video codec (NVC), its contexts are still limited, leading to low compression ratio. To boost NVC, this paper proposes increasing the context diversity in both temporal and spatial dimensions. First, we guide the model to learn hierarchical quality patterns across frames, which enriches long-term and yet high-quality temporal contexts. Furthermore, to tap the potential of optical flow-based coding framework, we introduce a group-based offset diversity where the cross-group interaction is proposed for better context mining. In addition, this paper also adopts a quadtree-based partition to increase spatial context diversity when encoding the latent representation in parallel. Experiments show that our codec obtains 23.5% bitrate saving over previous SOTA NVC. Better yet, our codec has surpassed the under-developing next generation traditional codec/ECM in both RGB and YUV420 colorspaces, in terms of PSNR. The codes are at https://github.com/microsoft/DCVC.
GoNet: An Approach-Constrained Generative Grasp Sampling Network
Mar 14, 2023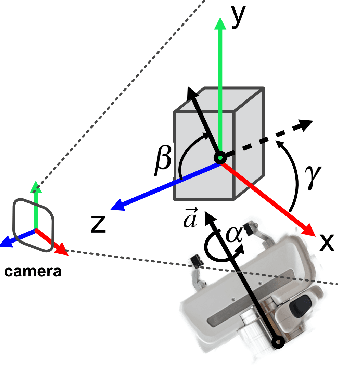

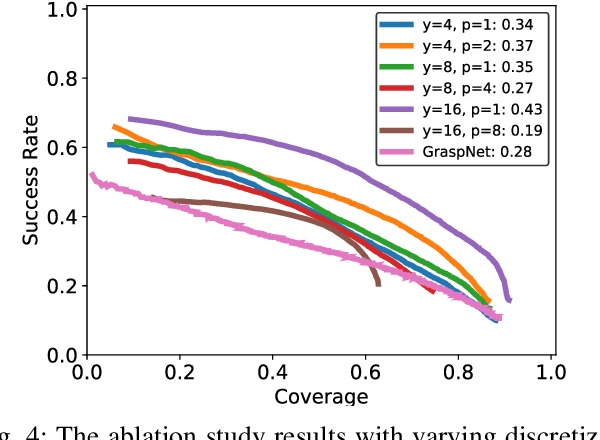
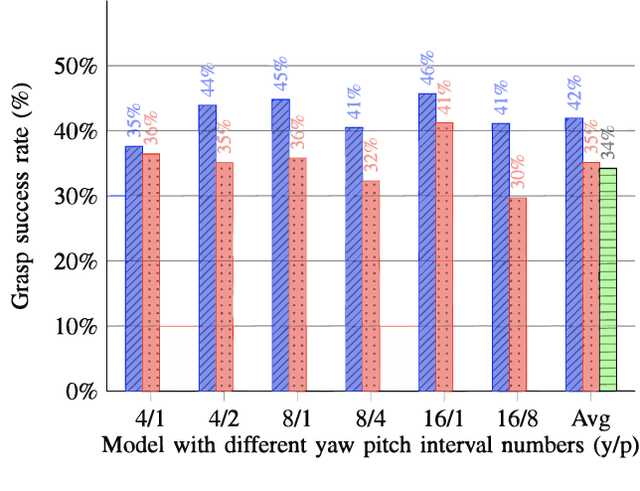
Constraining the approach direction of grasps is important when picking objects in confined spaces, such as when emptying a shelf. Yet, such capabilities are not available in state-of-the-art data-driven grasp sampling methods that sample grasps all around the object. In this work, we address the specific problem of training approach-constrained data-driven grasp samplers and how to generate good grasping directions automatically. Our solution is GoNet: a generative grasp sampler that can constrain the grasp approach direction to lie close to a specified direction. This is achieved by discretizing SO(3) into bins and training GoNet to generate grasps from those bins. At run-time, the bin aligning with the second largest principal component of the observed point cloud is selected. GoNet is benchmarked against GraspNet, a state-of-the-art unconstrained grasp sampler, in an unconfined grasping experiment in simulation and on an unconfined and confined grasping experiment in the real world. The results demonstrate that GoNet achieves higher success-over-coverage in simulation and a 12%-18% higher success rate in real-world table-picking and shelf-picking tasks than the baseline.
Reachability Analysis of Neural Networks with Uncertain Parameters
Mar 14, 2023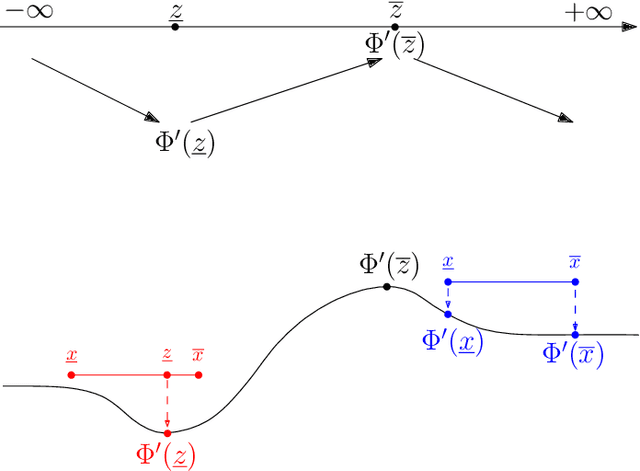

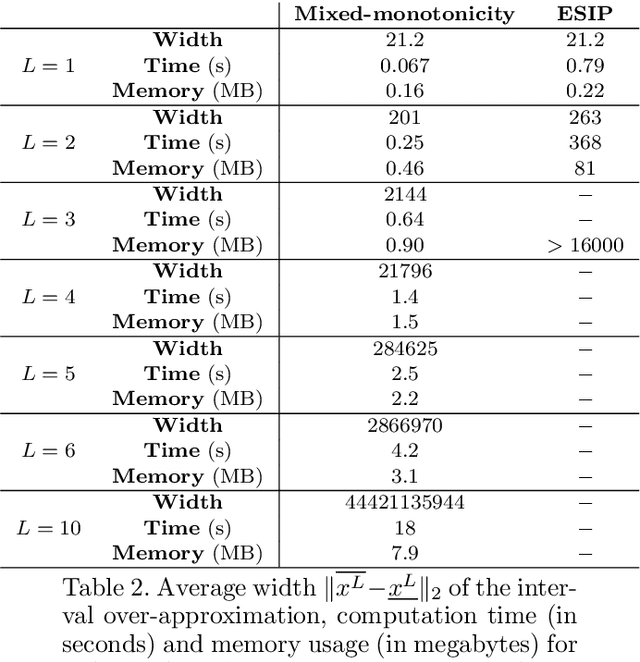
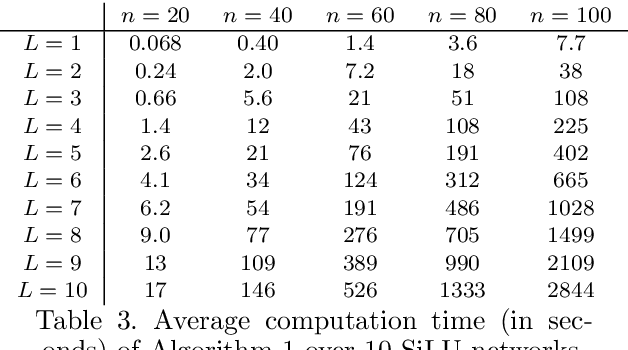
The literature on reachability analysis methods for neural networks currently only focuses on uncertainties on the network's inputs. In this paper, we introduce two new approaches for the reachability analysis of neural networks with additional uncertainties on their internal parameters (weight matrices and bias vectors of each layer), which may open the field of formal methods on neural networks to new topics, such as safe training or network repair. The first and main method that we propose relies on existing reachability analysis approach based on mixed monotonicity (initially introduced for dynamical systems). The second proposed approach extends the ESIP (Error-based Symbolic Interval Propagation) approach which was first implemented in the verification tool Neurify, and first mentioned in the publication of the tool VeriNet. Although the ESIP approach has been shown to often outperform the mixed-monotonicity reachability analysis in the classical case with uncertainties only on the network's inputs, we show in this paper through numerical simulations that the situation is greatly reversed (in terms of precision, computation time, memory usage, and broader applicability) when dealing with uncertainties on the weights and biases.
Metric Search for Rank List Compatibility Matching with Applications
Mar 14, 2023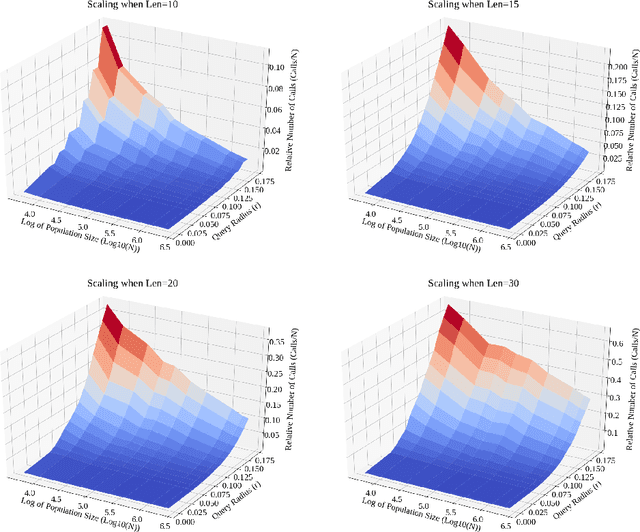
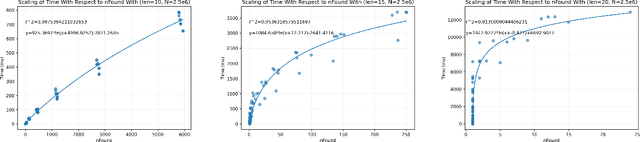
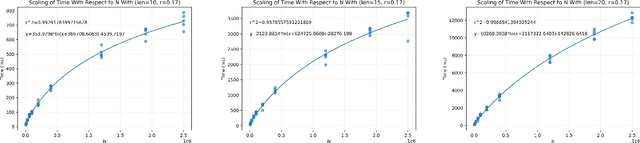
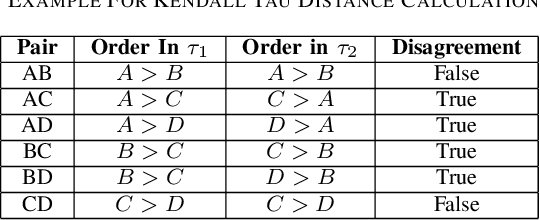
As online dating has become more popular in the past few years, an efficient and effective algorithm to match users is needed. In this project, we proposed a new dating matching algorithm that uses Kendall-Tau distance to measure the similarity between users based on their ranking for items in a list. (e.g., their favourite sports, music, etc.) To increase the performance of the search process, we applied a tree-based searching structure, Cascading Metric Tree (CMT), on this metric. The tree is built on ranked lists from all the users; when a query target and a radius are provided, our algorithm can return users within the radius of the target. We tested the scaling of this searching method on a synthetic dataset by varying list length, population size, and query radius. We observed that the algorithm is able to query the best matching people for the user in a practical time, given reasonable parameters. We also provided potential future improvements that can be made to this algorithm based on the limitations. Finally, we offered more use cases of this search structure on Kendall-Tau distance and new insight into real-world applications of distance search structures.
Towards AI-controlled FES-restoration of movements: Learning cycling stimulation pattern with reinforcement learning
Mar 17, 2023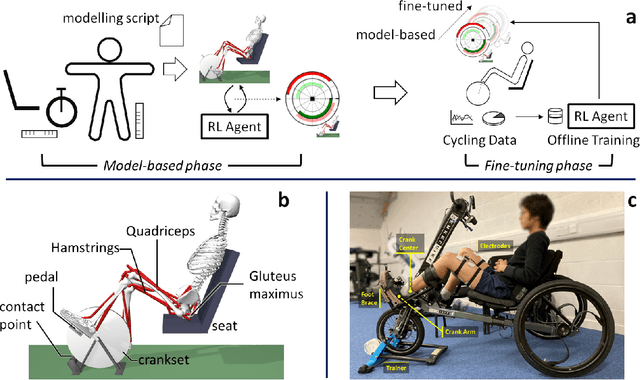
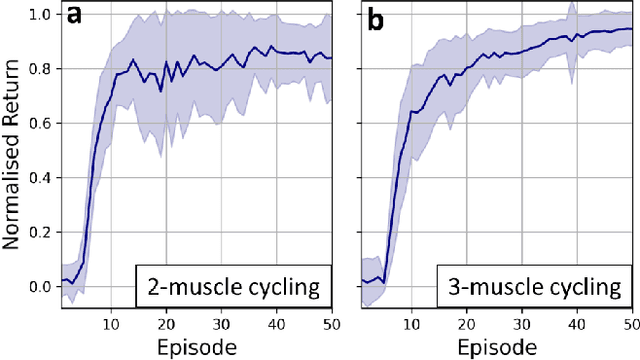
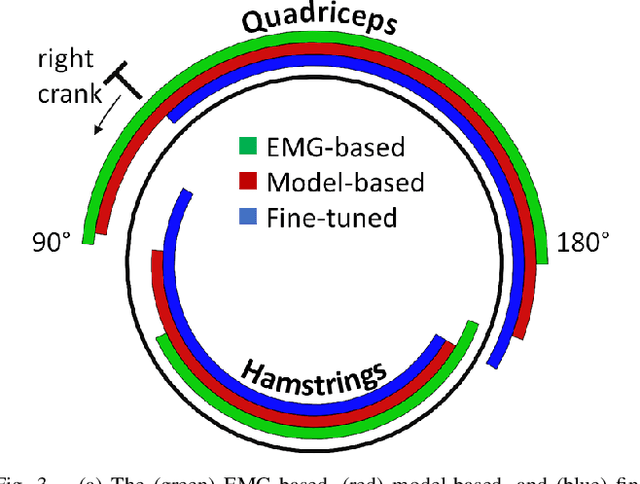
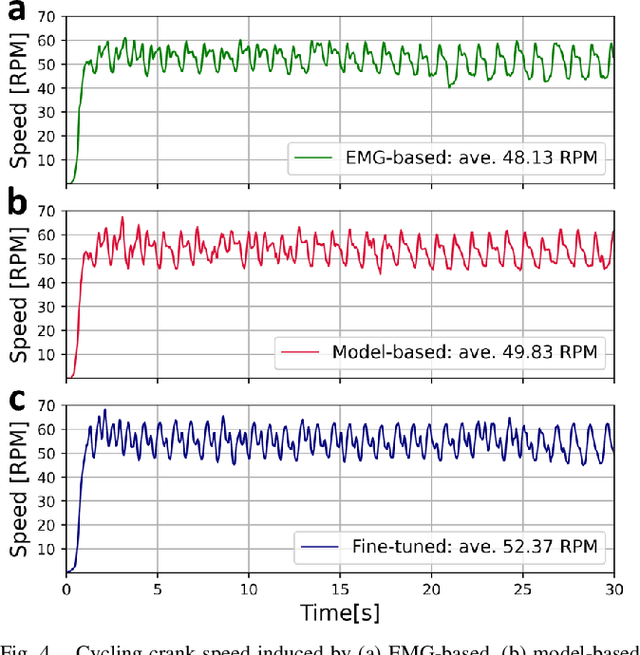
Functional electrical stimulation (FES) has been increasingly integrated with other rehabilitation devices, including robots. FES cycling is one of the common FES applications in rehabilitation, which is performed by stimulating leg muscles in a certain pattern. The appropriate pattern varies across individuals and requires manual tuning which can be time-consuming and challenging for the individual user. Here, we present an AI-based method for finding the patterns, which requires no extra hardware or sensors. Our method has two phases, starting with finding model-based patterns using reinforcement learning and detailed musculoskeletal models. The models, built using open-source software, can be customised through our automated script and can be therefore used by non-technical individuals without extra cost. Next, our method fine-tunes the pattern using real cycling data. We test our both in simulation and experimentally on a stationary tricycle. In the simulation test, our method can robustly deliver model-based patterns for different cycling configurations. The experimental evaluation shows that our method can find a model-based pattern that induces higher cycling speed than an EMG-based pattern. By using just 100 seconds of cycling data, our method can deliver a fine-tuned pattern that gives better cycling performance. Beyond FES cycling, this work is a showcase, displaying the feasibility and potential of human-in-the-loop AI in real-world rehabilitation.