 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fully On-board Low-Power Localization with Multizone Time-of-Flight Sensors on Nano-UAVs
Nov 25, 2022
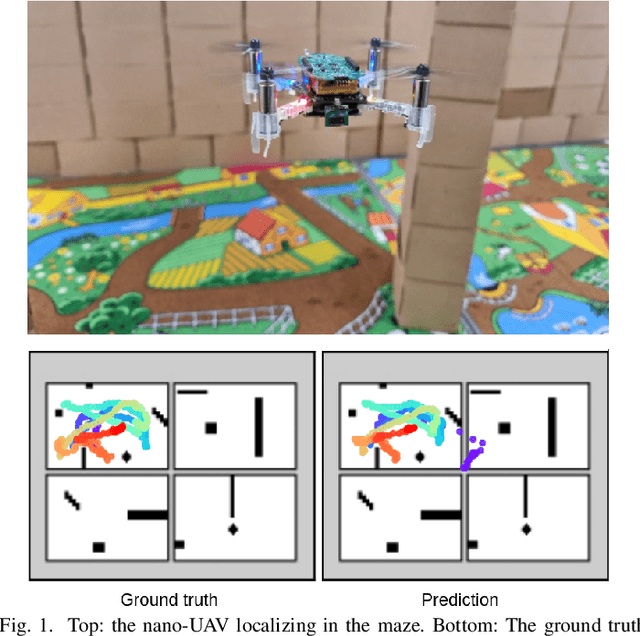
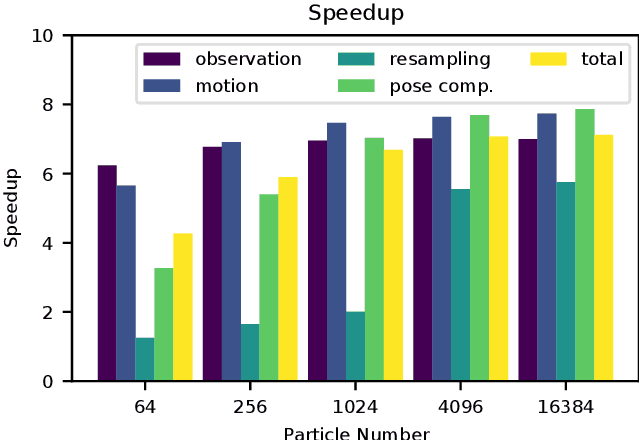
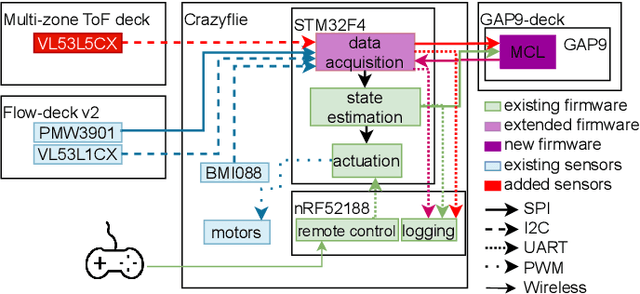
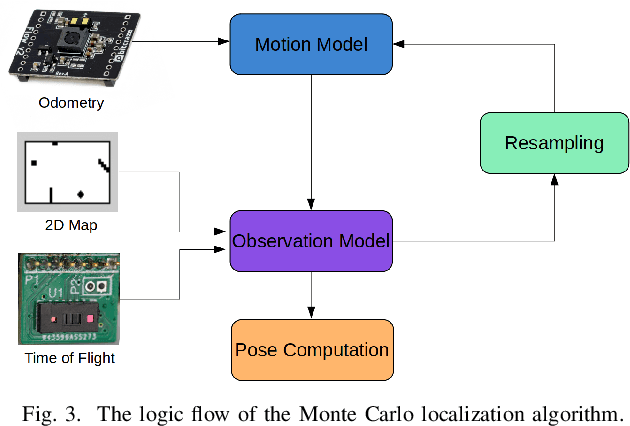
Nano-size unmanned aerial vehicles (UAVs) hold enormous potential to perform autonomous operations in complex environments, such as inspection, monitoring or data collection. Moreover, their small size allows safe operation close to humans and agile flight. An important part of autonomous flight is localization, which is a computationally intensive task especially on a nano-UAV that usually has strong constraints in sensing, processing and memory. This work presents a real-time localization approach with low element-count multizone range sensors for resource-constrained nano-UAVs. The proposed approach is based on a novel miniature 64-zone time-of-flight sensor from ST Microelectronics and a RISC-V-based parallel ultra low-power processor, to enable accurate and low latency Monte Carlo Localization on-board. Experimental evaluation using a nano-UAV open platform demonstrated that the proposed solution is capable of localizing on a 31.2m$\boldsymbol{^2}$ map with 0.15m accuracy and an above 95% success rate. The achieved accuracy is sufficient for localization in common indoor environments. We analyze tradeoffs in using full and half-precision floating point numbers as well as a quantized map and evaluate the accuracy and memory footprint across the design space. Experimental evaluation shows that parallelizing the execution for 8 RISC-V cores brings a 7x speedup and allows us to execute the algorithm on-board in real-time with a latency of 0.2-30ms (depending on the number of particles), while only increasing the overall drone power consumption by 3-7%. Finally, we provide an open-source implementation of our approach.
TiAda: A Time-scale Adaptive Algorithm for Nonconvex Minimax Optimization
Oct 31, 2022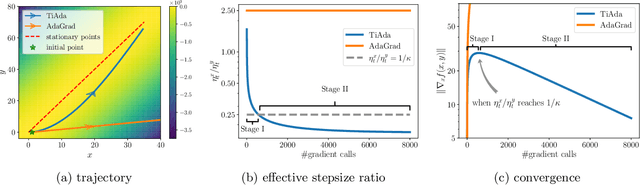

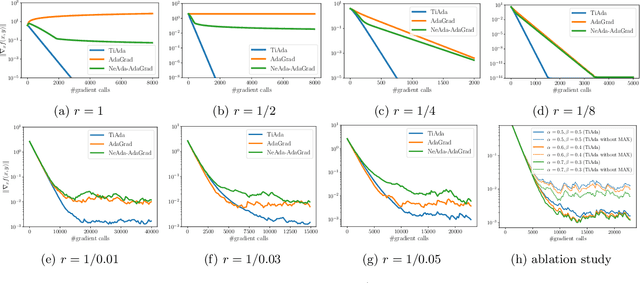
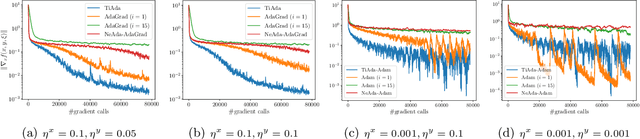
Adaptive gradient methods have shown their ability to adjust the stepsizes on the fly in a parameter-agnostic manner, and empirically achieve faster convergence for solving minimization problems. When it comes to nonconvex minimax optimization, however, current convergence analyses of gradient descent ascent (GDA) combined with adaptive stepsizes require careful tuning of hyper-parameters and the knowledge of problem-dependent parameters. Such a discrepancy arises from the primal-dual nature of minimax problems and the necessity of delicate time-scale separation between the primal and dual updates in attaining convergence. In this work, we propose a single-loop adaptive GDA algorithm called TiAda for nonconvex minimax optimization that automatically adapts to the time-scale separation. Our algorithm is fully parameter-agnostic and can achieve near-optimal complexities simultaneously in deterministic and stochastic settings of nonconvex-strongly-concave minimax problems. The effectiveness of the proposed method is further justified numerically for a number of machine learning applications.
Confidence Interval Construction for Multivariate time series using Long Short Term Memory Network
Nov 25, 2022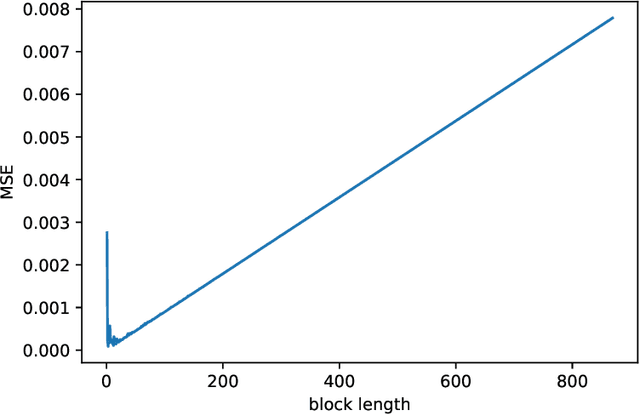

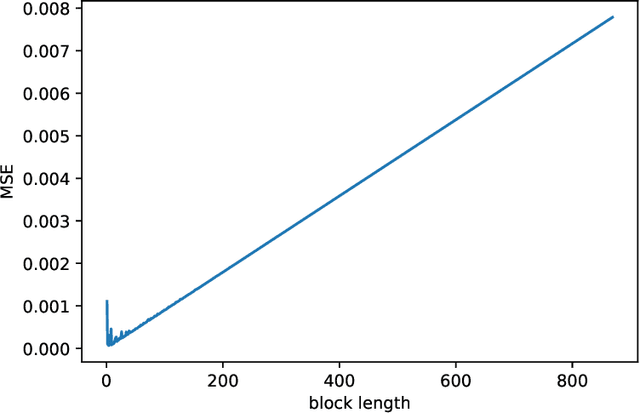
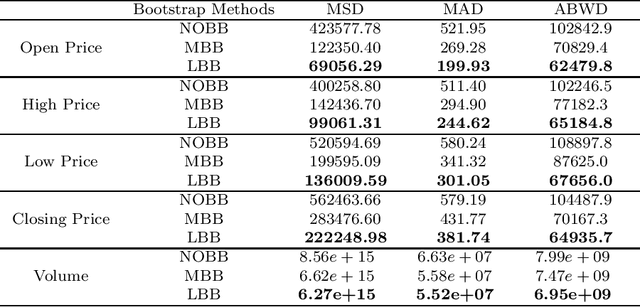
In this paper we propose a novel procedure to construct a confidence interval for multivariate time series predictions using long short term memory network. The construction uses a few novel block bootstrap techniques. We also propose an innovative block length selection procedure for each of these schemes. Two novel benchmarks help us to compare the construction of this confidence intervals by different bootstrap techniques. We illustrate the whole construction through S\&P $500$ and Dow Jones Index datasets.
Real-time Sampling-based Model Predictive Control based on Reverse Kullback-Leibler Divergence and Its Adaptive Acceleration
Dec 08, 2022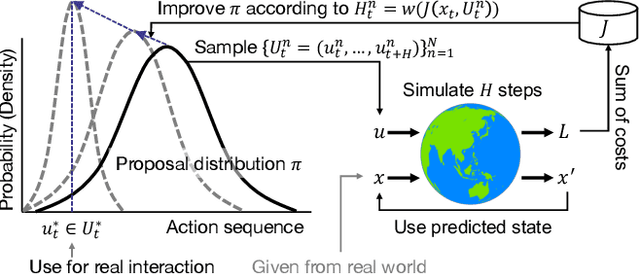
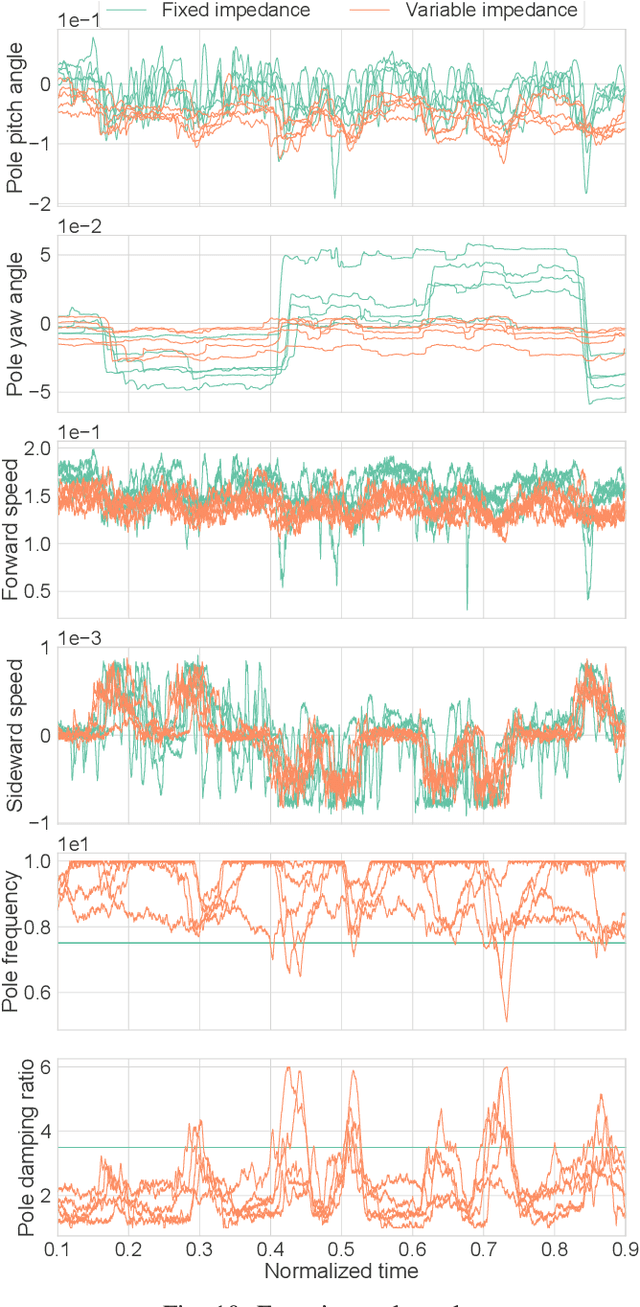
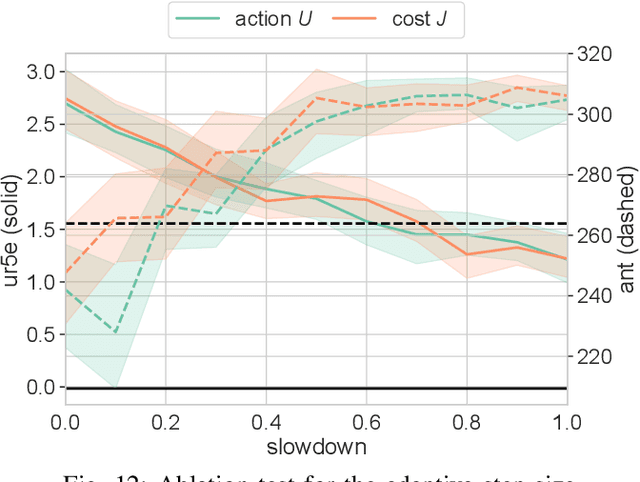
Sampling-based model predictive control (MPC) can be applied to versatile robotic systems. However, the real-time control with it is a big challenge due to its unstable updates and poor convergence. This paper tackles this challenge with a novel derivation from reverse Kullback-Leibler divergence, which has a mode-seeking behavior and is likely to find one of the sub-optimal solutions early. With this derivation, a weighted maximum likelihood estimation with positive/negative weights is obtained, solving by mirror descent (MD) algorithm. While the negative weights eliminate unnecessary actions, that requires to develop a practical implementation that avoids the interference with positive/negative updates based on rejection sampling. In addition, although the convergence of MD can be accelerated with Nesterov's acceleration method, it is modified for the proposed MPC with a heuristic of a step size adaptive to the noise estimated in update amounts. In the real-time simulations, the proposed method can solve more tasks statistically than the conventional method and accomplish more complex tasks only with a CPU due to the improved acceleration. In addition, its applicability is also demonstrated in a variable impedance control of a force-driven mobile robot. https://youtu.be/D8bFMzct1XM
Few-shot Geometry-Aware Keypoint Localization
Mar 30, 2023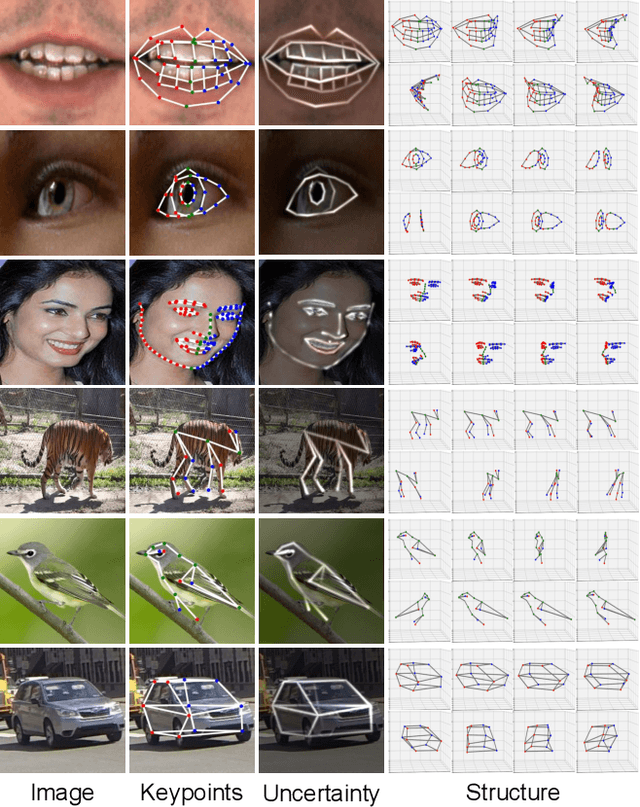
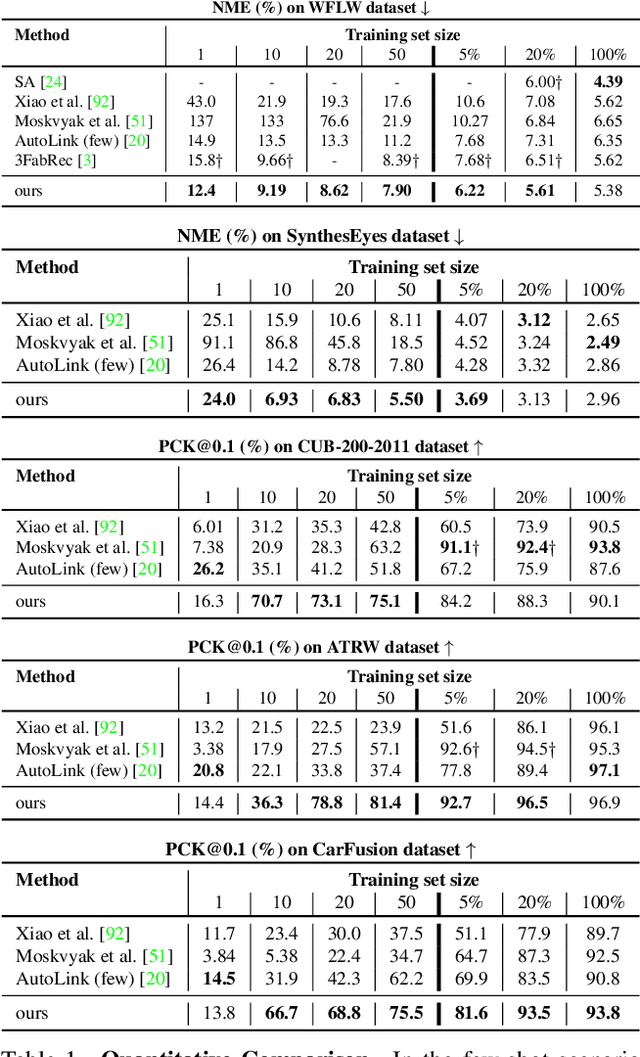
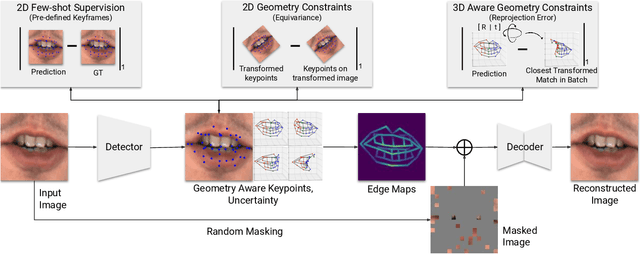
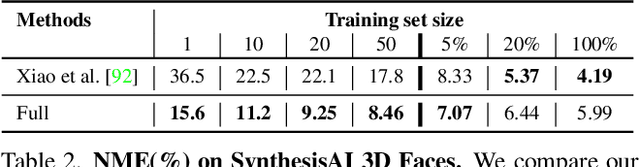
Supervised keypoint localization methods rely on large manually labeled image datasets, where objects can deform, articulate, or occlude. However, creating such large keypoint labels is time-consuming and costly, and is often error-prone due to inconsistent labeling. Thus, we desire an approach that can learn keypoint localization with fewer yet consistently annotated images. To this end, we present a novel formulation that learns to localize semantically consistent keypoint definitions, even for occluded regions, for varying object categories. We use a few user-labeled 2D images as input examples, which are extended via self-supervision using a larger unlabeled dataset. Unlike unsupervised methods, the few-shot images act as semantic shape constraints for object localization. Furthermore, we introduce 3D geometry-aware constraints to uplift keypoints, achieving more accurate 2D localization. Our general-purpose formulation paves the way for semantically conditioned generative modeling and attains competitive or state-of-the-art accuracy on several datasets, including human faces, eyes, animals, cars, and never-before-seen mouth interior (teeth) localization tasks, not attempted by the previous few-shot methods. Project page: https://xingzhehe.github.io/FewShot3DKP/}{https://xingzhehe.github.io/FewShot3DKP/
* CVPR 2023
Event-based Agile Object Catching with a Quadrupedal Robot
Mar 30, 2023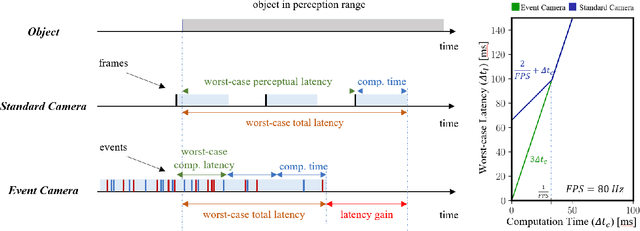
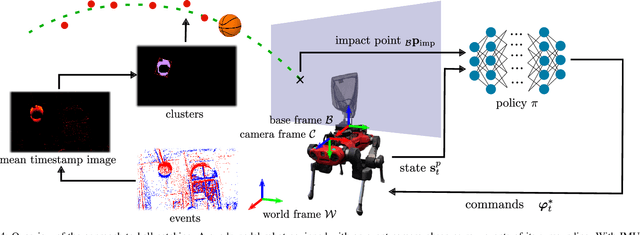


Quadrupedal robots are conquering various indoor and outdoor applications due to their ability to navigate challenging uneven terrains. Exteroceptive information greatly enhances this capability since perceiving their surroundings allows them to adapt their controller and thus achieve higher levels of robustness. However, sensors such as LiDARs and RGB cameras do not provide sufficient information to quickly and precisely react in a highly dynamic environment since they suffer from a bandwidth-latency tradeoff. They require significant bandwidth at high frame rates while featuring significant perceptual latency at lower frame rates, thereby limiting their versatility on resource-constrained platforms. In this work, we tackle this problem by equipping our quadruped with an event camera, which does not suffer from this tradeoff due to its asynchronous and sparse operation. In leveraging the low latency of the events, we push the limits of quadruped agility and demonstrate high-speed ball catching for the first time. We show that our quadruped equipped with an event camera can catch objects with speeds up to 15 m/s from 4 meters, with a success rate of 83%. Using a VGA event camera, our method runs at 100 Hz on an NVIDIA Jetson Orin.
Robust Multi-Agent Pickup and Delivery with Delays
Mar 30, 2023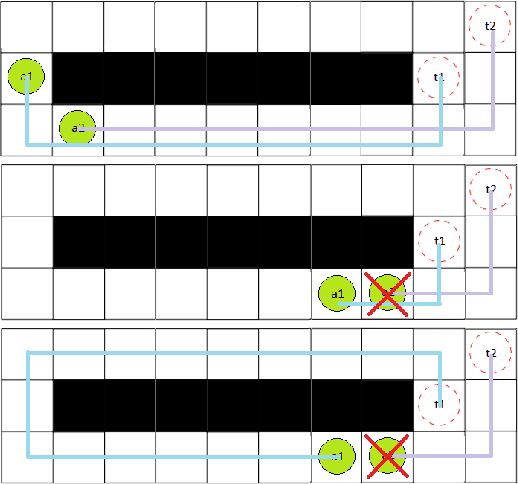
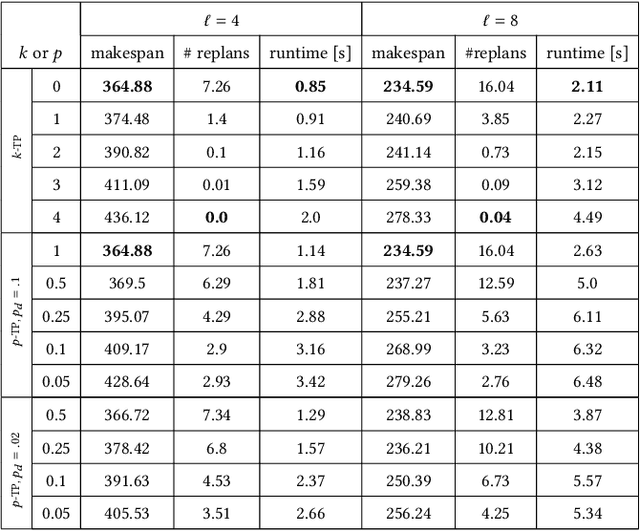
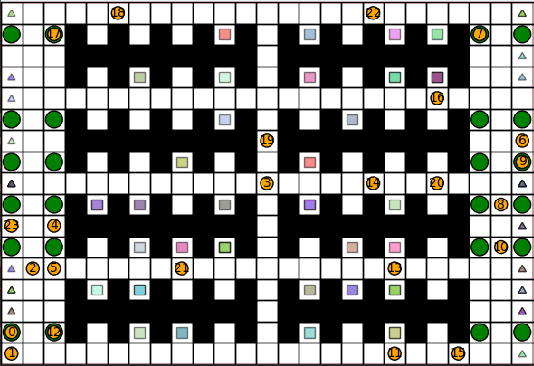
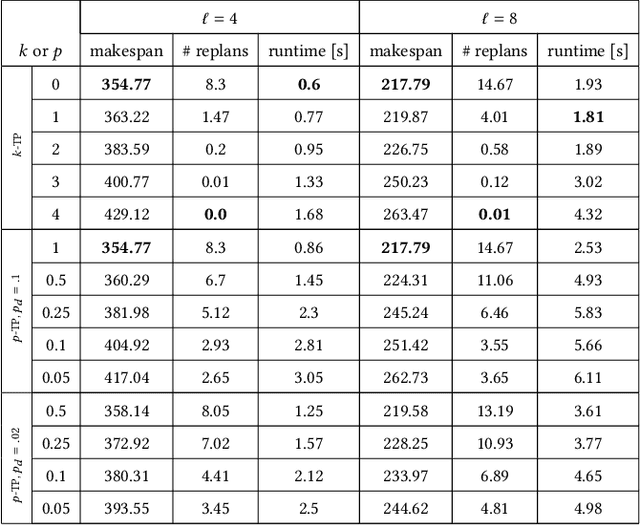
Multi-Agent Pickup and Delivery (MAPD) is the problem of computing collision-free paths for a group of agents such that they can safely reach delivery locations from pickup ones. These locations are provided at runtime, making MAPD a combination between classical Multi-Agent Path Finding (MAPF) and online task assignment. Current algorithms for MAPD do not consider many of the practical issues encountered in real applications: real agents often do not follow the planned paths perfectly, and may be subject to delays and failures. In this paper, we study the problem of MAPD with delays, and we present two solution approaches that provide robustness guarantees by planning paths that limit the effects of imperfect execution. In particular, we introduce two algorithms, k-TP and p-TP, both based on a decentralized algorithm typically used to solve MAPD, Token Passing (TP), which offer deterministic and probabilistic guarantees, respectively. Experimentally, we compare our algorithms against a version of TP enriched with online replanning. k-TP and p-TP provide robust solutions, significantly reducing the number of replans caused by delays, with little or no increase in solution cost and running time.
Lifting uniform learners via distributional decomposition
Mar 30, 2023

We show how any PAC learning algorithm that works under the uniform distribution can be transformed, in a blackbox fashion, into one that works under an arbitrary and unknown distribution $\mathcal{D}$. The efficiency of our transformation scales with the inherent complexity of $\mathcal{D}$, running in $\mathrm{poly}(n, (md)^d)$ time for distributions over $\{\pm 1\}^n$ whose pmfs are computed by depth-$d$ decision trees, where $m$ is the sample complexity of the original algorithm. For monotone distributions our transformation uses only samples from $\mathcal{D}$, and for general ones it uses subcube conditioning samples. A key technical ingredient is an algorithm which, given the aforementioned access to $\mathcal{D}$, produces an optimal decision tree decomposition of $\mathcal{D}$: an approximation of $\mathcal{D}$ as a mixture of uniform distributions over disjoint subcubes. With this decomposition in hand, we run the uniform-distribution learner on each subcube and combine the hypotheses using the decision tree. This algorithmic decomposition lemma also yields new algorithms for learning decision tree distributions with runtimes that exponentially improve on the prior state of the art -- results of independent interest in distribution learning.
MDAESF: Cine MRI Reconstruction Based on Motion-Guided Deformable Alignment and Efficient Spatiotemporal Self-Attention Fusion
Mar 09, 2023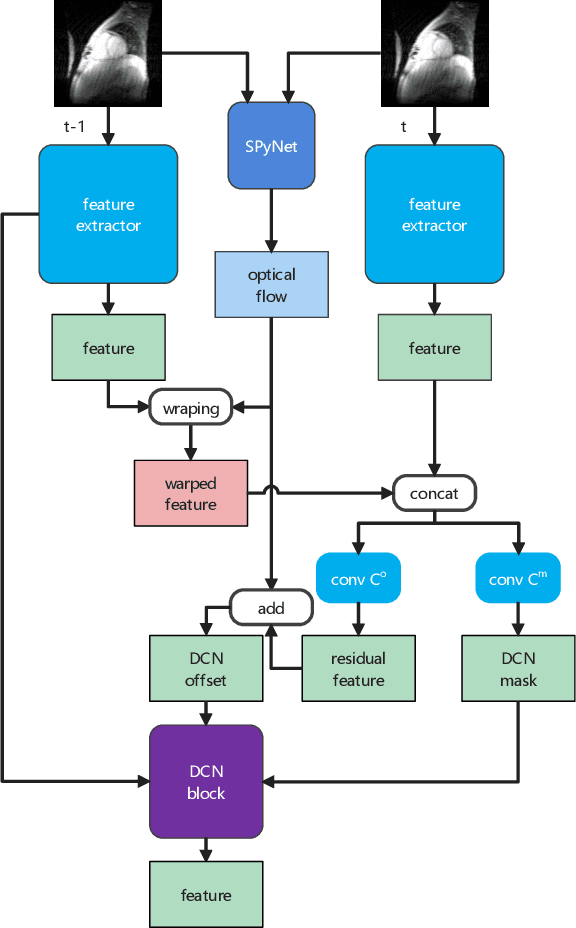

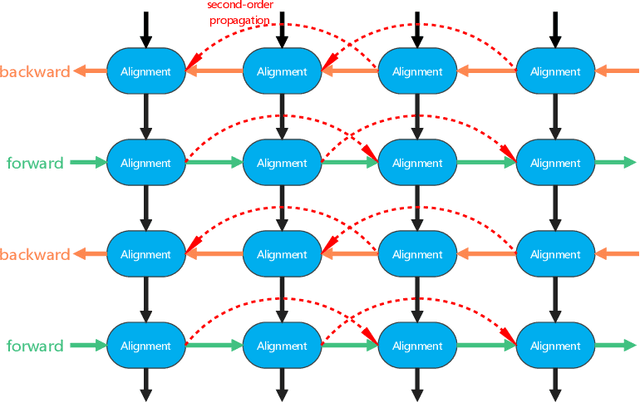

Cine MRI can jointly obtain the continuous influence of the anatomical structure and physiological and pathological mechanisms of organs in the two dimensions of time domain and space domain. Compared with ordinary two-dimensional static MRI images, the information in the time dimension of cine MRI contains many important information. But the information in the temporal dimension is not well utilized in past methods. To make full use of spatiotemporal information and reduce the influence of artifacts, this paper proposes a cine MRI reconstruction model based on second-order bidirectional propagation, motion-guided deformable alignment, and efficient spatiotemporal self-attention fusion. Compared to other advanced methods, our proposed method achieved better image reconstruction quality in terms of peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) metrics as well as visual effects. The source code will be made available on https://github.com/GtLinyer/MDAESF.
TAEC: Unsupervised Action Segmentation with Temporal-Aware Embedding and Clustering
Mar 09, 2023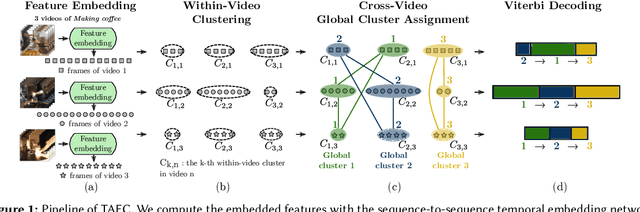
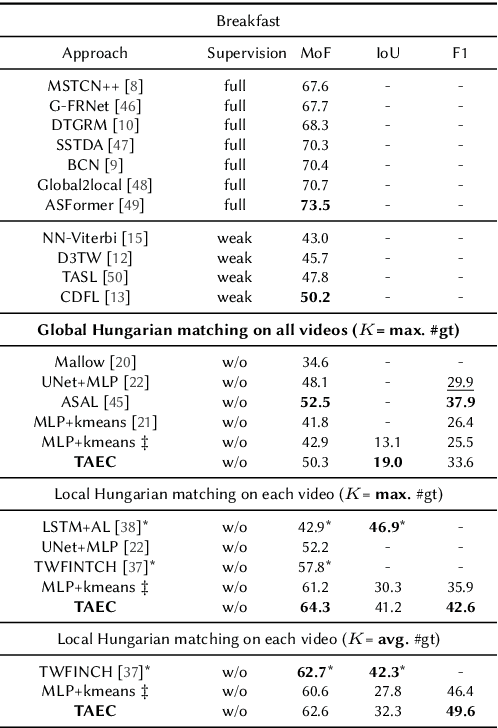
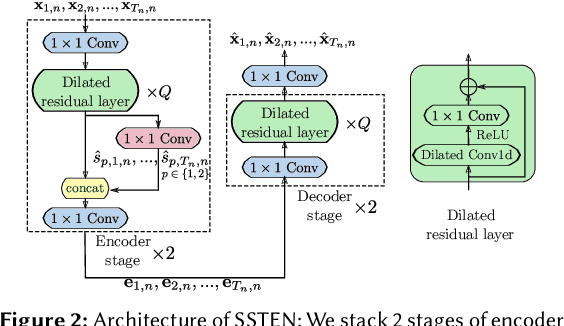
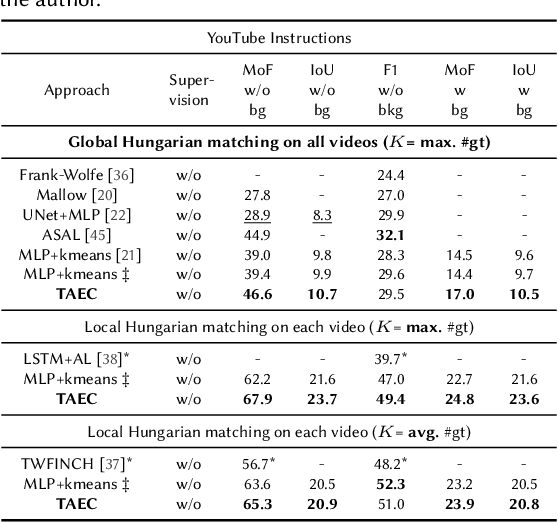
Temporal action segmentation in untrimmed videos has gained increased attention recently. However, annotating action classes and frame-wise boundaries is extremely time consuming and cost intensive, especially on large-scale datasets. To address this issue, we propose an unsupervised approach for learning action classes from untrimmed video sequences. In particular, we propose a temporal embedding network that combines relative time prediction, feature reconstruction, and sequence-to-sequence learning, to preserve the spatial layout and sequential nature of the video features. A two-step clustering pipeline on these embedded feature representations then allows us to enforce temporal consistency within, as well as across videos. Based on the identified clusters, we decode the video into coherent temporal segments that correspond to semantically meaningful action classes. Our evaluation on three challenging datasets shows the impact of each component and, furthermore, demonstrates our state-of-the-art unsupervised action segmentation results.