 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time-Varying Optimization with Optimal Parametric Function
Oct 03, 2022
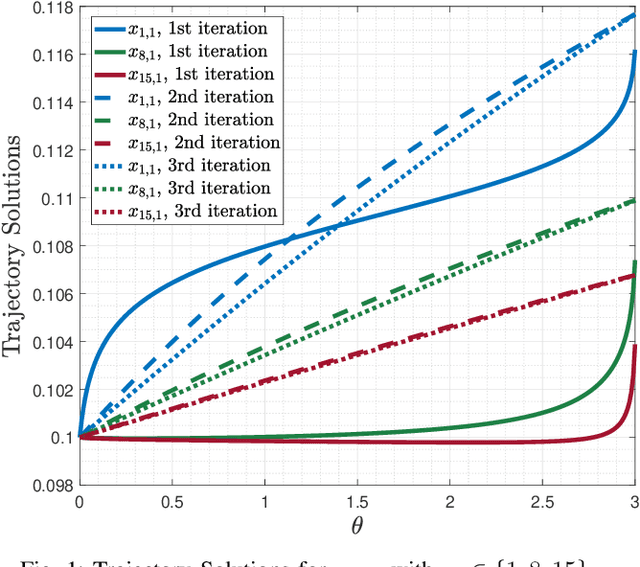
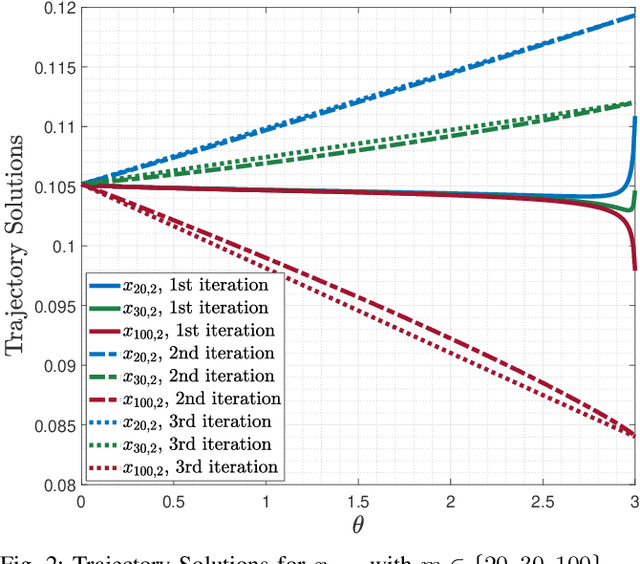
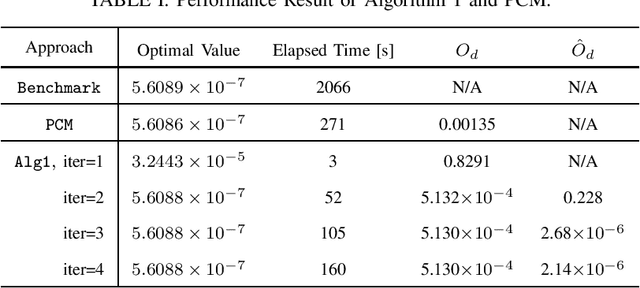
In this paper, we consider a class of nonlinear constrained optimization problems. We formulate this problem as a time-varying optimization using continuous-time parametric functions and derive a dynamical system for tracking the optimal solution. We then re-parameterize the dynamical system to express it as a linear combination of the parametric functions. Calculus of variations is applied to optimize the parametric functions, such that the optimality distance of the solution is minimized. Accordingly, an iterative dynamic algorithm is devised to find the solution with an efficient convergence rate. We benchmark the performance of the proposed algorithm with the prediction-correction method from the optimality and computational complexity point-of-views.
FlexNeRF: Photorealistic Free-viewpoint Rendering of Moving Humans from Sparse Views
Mar 25, 2023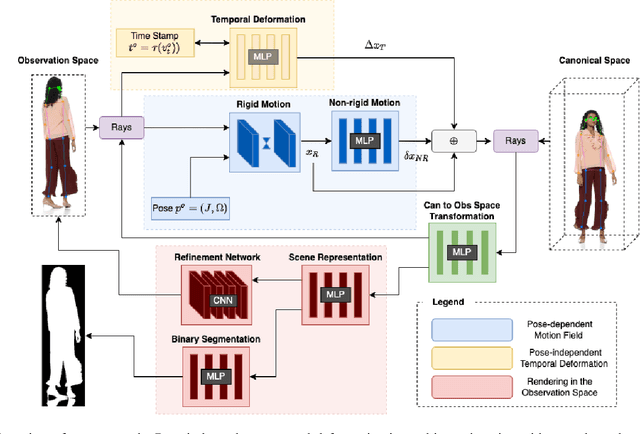
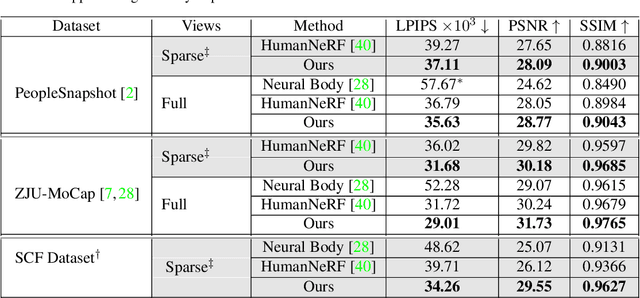

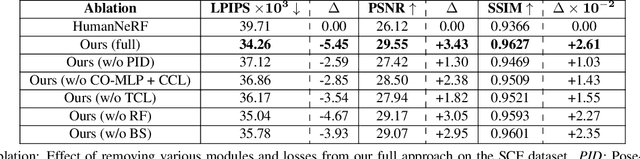
We present FlexNeRF, a method for photorealistic freeviewpoint rendering of humans in motion from monocular videos. Our approach works well with sparse views, which is a challenging scenario when the subject is exhibiting fast/complex motions. We propose a novel approach which jointly optimizes a canonical time and pose configuration, with a pose-dependent motion field and pose-independent temporal deformations complementing each other. Thanks to our novel temporal and cyclic consistency constraints along with additional losses on intermediate representation such as segmentation, our approach provides high quality outputs as the observed views become sparser. We empirically demonstrate that our method significantly outperforms the state-of-the-art on public benchmark datasets as well as a self-captured fashion dataset. The project page is available at: https://flex-nerf.github.io/
An ASR-free Fluency Scoring Approach with Self-Supervised Learning
Mar 13, 2023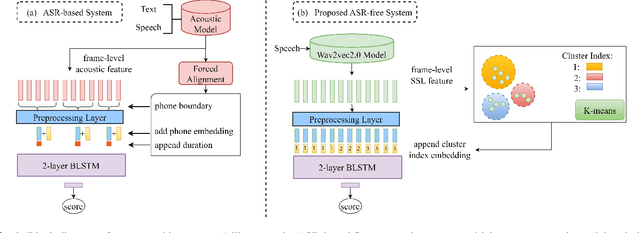
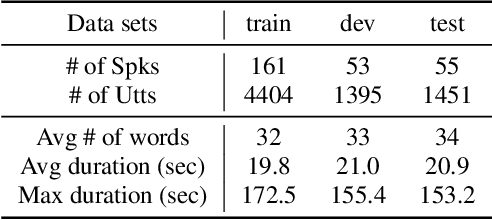
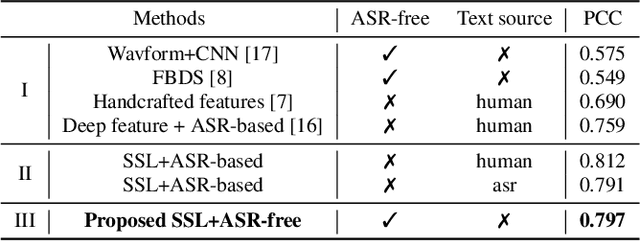
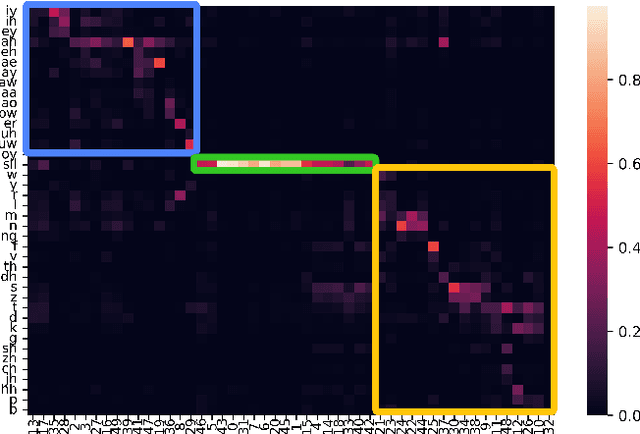
A typical fluency scoring system generally relies on an automatic speech recognition (ASR) system to obtain time stamps in input speech for either the subsequent calculation of fluency-related features or directly modeling speech fluency with an end-to-end approach. This paper describes a novel ASR-free approach for automatic fluency assessment using self-supervised learning (SSL). Specifically, wav2vec2.0 is used to extract frame-level speech features, followed by K-means clustering to assign a pseudo label (cluster index) to each frame. A BLSTM-based model is trained to predict an utterance-level fluency score from frame-level SSL features and the corresponding cluster indexes. Neither speech transcription nor time stamp information is required in the proposed system. It is ASR-free and can potentially avoid the ASR errors effect in practice. Experimental results carried out on non-native English databases show that the proposed approach significantly improves the performance in the "open response" scenario as compared to previous methods and matches the recently reported performance in the "read aloud" scenario.
Probabilistic Uncertainty-Aware Risk Spot Detector for Naturalistic Driving
Mar 13, 2023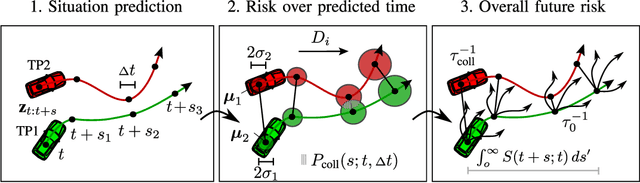
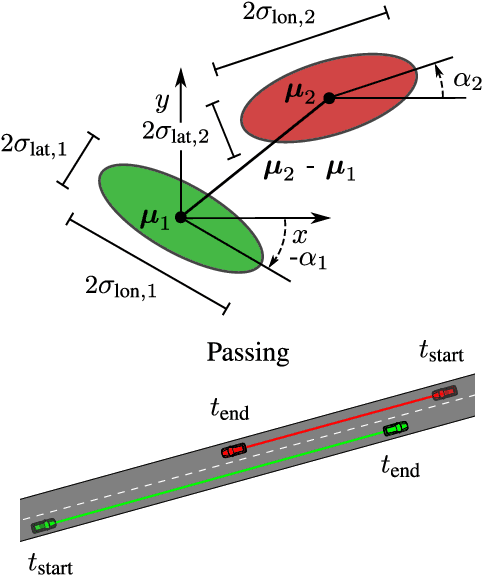
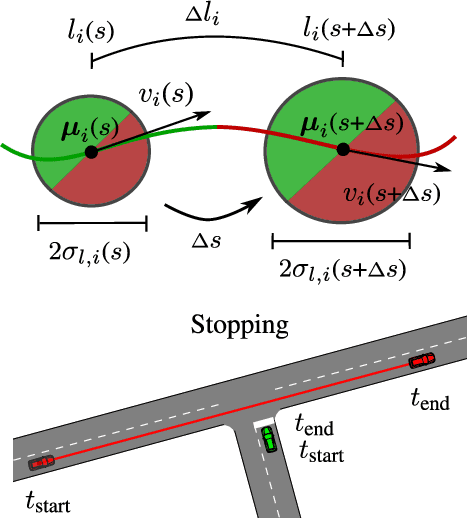
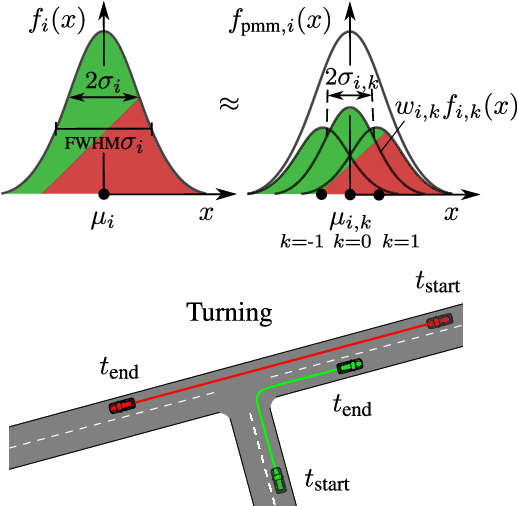
Risk assessment is a central element for the development and validation of Autonomous Vehicles (AV). It comprises a combination of occurrence probability and severity of future critical events. Time Headway (TH) as well as Time-To-Contact (TTC) are commonly used risk metrics and have qualitative relations to occurrence probability. However, they lack theoretical derivations and additionally they are designed to only cover special types of traffic scenarios (e.g. following between single car pairs). In this paper, we present a probabilistic situation risk model based on survival analysis considerations and extend it to naturally incorporate sensory, temporal and behavioral uncertainties as they arise in real-world scenarios. The resulting Risk Spot Detector (RSD) is applied and tested on naturalistic driving data of a multi-lane boulevard with several intersections, enabling the visualization of road criticality maps. Compared to TH and TTC, our approach is more selective and specific in predicting risk. RSD concentrates on driving sections of high vehicle density where large accelerations and decelerations or approaches with high velocity occur.
Learning-based Robust Speaker Counting and Separation with the Aid of Spatial Coherence
Mar 13, 2023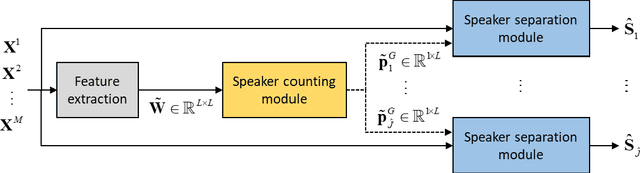
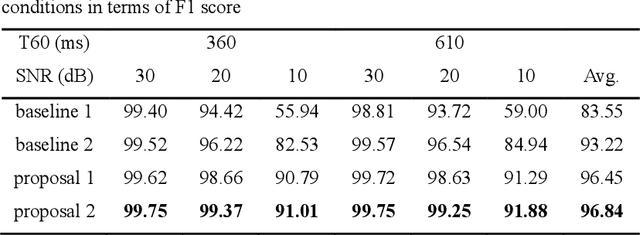
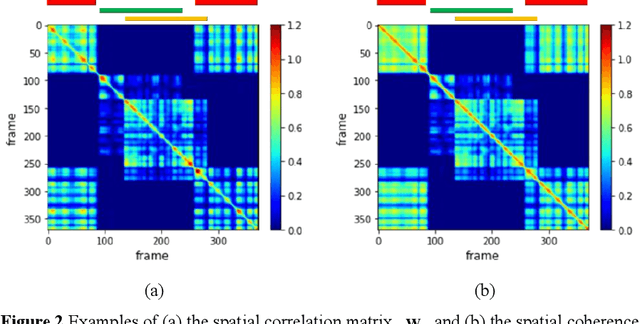
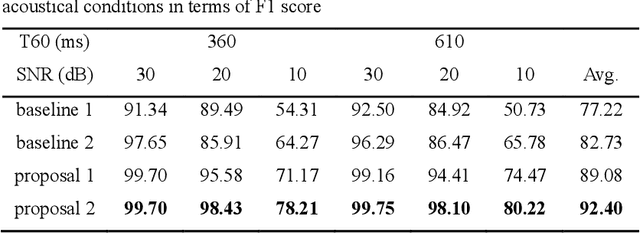
A two-stage approach is proposed for speaker counting and speech separation in noisy and reverberant environments. A spatial coherence matrix (SCM) is computed using whitened relative transfer functions (wRTFs) across time frames. The global activity functions of each speaker are estimated on the basis of a simplex constructed using the eigenvectors of the SCM, while the local coherence functions are computed from the coherence between the wRTFs of a time-frequency bin and the global activity function-weighted RTF of the target speaker. In speaker counting, we use the eigenvalues of the SCM and the maximum similarity of the interframe global activity distributions between two speakers as the input features to the speaker counting network (SCnet). In speaker separation, a global and local activity-driven network (GLADnet) is utilized to estimate a speaker mask, which is particularly useful for highly overlapping speech signals. Experimental results obtained from the real meeting recordings demonstrated the superior speaker counting and speaker separation performance achieved by the proposed learning-based system without prior knowledge of the array configurations.
Superhuman Artificial Intelligence Can Improve Human Decision Making by Increasing Novelty
Mar 13, 2023How will superhuman artificial intelligence (AI) affect human decision making? And what will be the mechanisms behind this effect? We address these questions in a domain where AI already exceeds human performance, analyzing more than 5.8 million move decisions made by professional Go players over the past 71 years (1950-2021). To address the first question, we use a superhuman AI program to estimate the quality of human decisions across time, generating 58 billion counterfactual game patterns and comparing the win rates of actual human decisions with those of counterfactual AI decisions. We find that humans began to make significantly better decisions following the advent of superhuman AI. We then examine human players' strategies across time and find that novel decisions (i.e., previously unobserved moves) occurred more frequently and became associated with higher decision quality after the advent of superhuman AI. Our findings suggest that the development of superhuman AI programs may have prompted human players to break away from traditional strategies and induced them to explore novel moves, which in turn may have improved their decision-making.
* An edited version of this paper is published online at PNAS: https://www.pnas.org/doi/10.1073/pnas.2214840120
Indoor Positioning using Wi-Fi and Machine Learning for Industry 5.0
Mar 26, 2023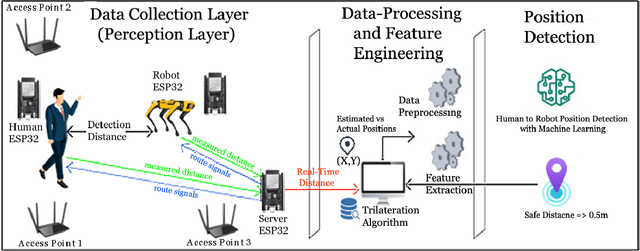
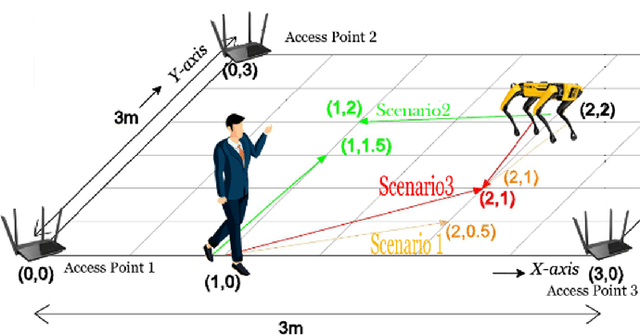
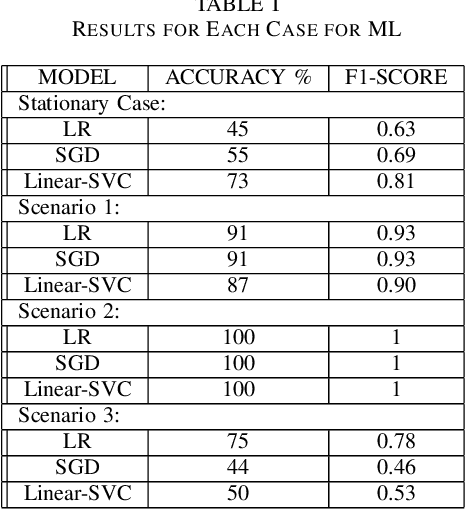
Humans and robots working together in an environment to enhance human performance is the aim of Industry 5.0. Although significant progress in outdoor positioning has been seen, indoor positioning remains a challenge. In this paper, we introduce a new research concept by exploiting the potential of indoor positioning for Industry 5.0. We use Wi-Fi Received Signal Strength Indicator (RSSI) with trilateration using cheap and easily available ESP32 Arduino boards for positioning as well as sending effective route signals to a human and a robot working in a simulated-indoor factory environment in real-time. We utilized machine learning models to detect safe closeness between two co-workers (a human subject and a robot). Experimental data and analysis show an average deviation of less than 1m from the actual distance while the targets are mobile or stationary.
Log-Linear-Time Gaussian Processes Using Binary Tree Kernels
Oct 04, 2022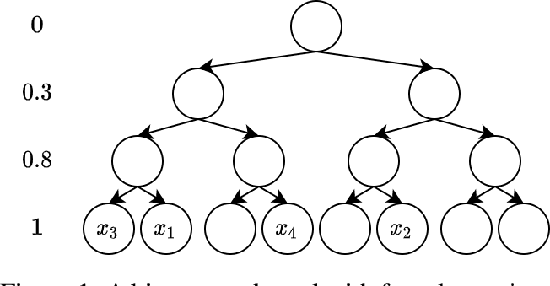
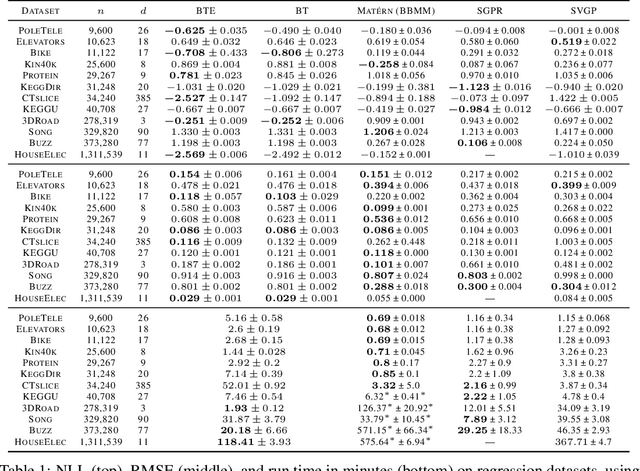
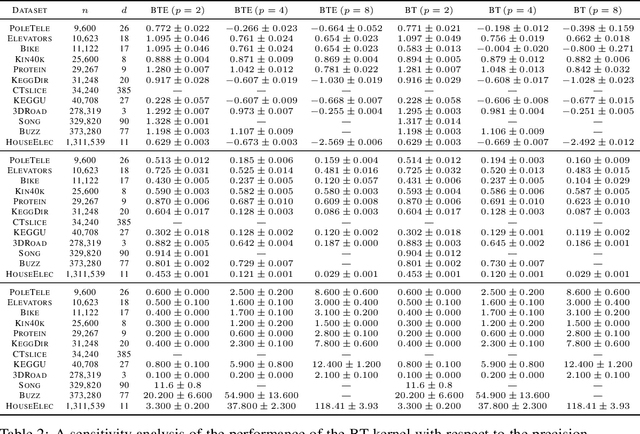
Gaussian processes (GPs) produce good probabilistic models of functions, but most GP kernels require $O((n+m)n^2)$ time, where $n$ is the number of data points and $m$ the number of predictive locations. We present a new kernel that allows for Gaussian process regression in $O((n+m)\log(n+m))$ time. Our "binary tree" kernel places all data points on the leaves of a binary tree, with the kernel depending only on the depth of the deepest common ancestor. We can store the resulting kernel matrix in $O(n)$ space in $O(n \log n)$ time, as a sum of sparse rank-one matrices, and approximately invert the kernel matrix in $O(n)$ time. Sparse GP methods also offer linear run time, but they predict less well than higher dimensional kernels. On a classic suite of regression tasks, we compare our kernel against Mat\'ern, sparse, and sparse variational kernels. The binary tree GP assigns the highest likelihood to the test data on a plurality of datasets, usually achieves lower mean squared error than the sparse methods, and often ties or beats the Mat\'ern GP. On large datasets, the binary tree GP is fastest, and much faster than a Mat\'ern GP.
Hardware Software Co-Design Based Reconfigurable Radar Signal Processing Accelerator for Joint Radar-Communication System
Mar 03, 2023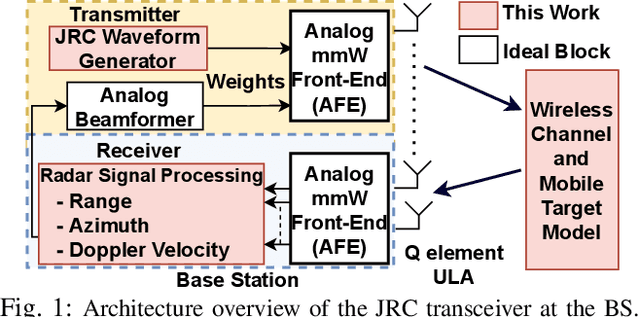
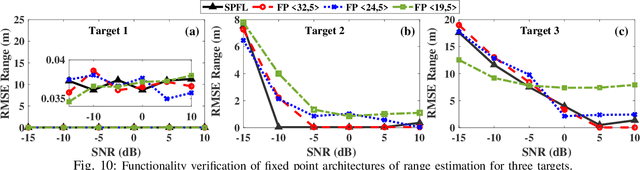
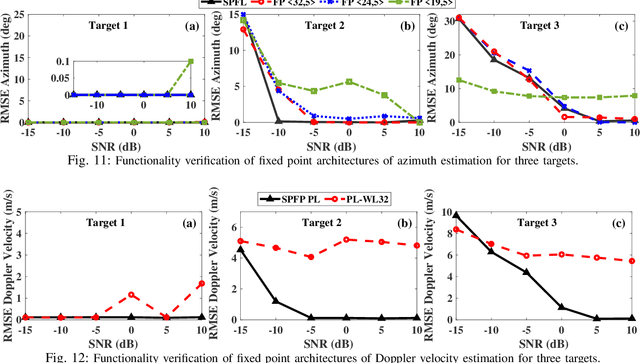
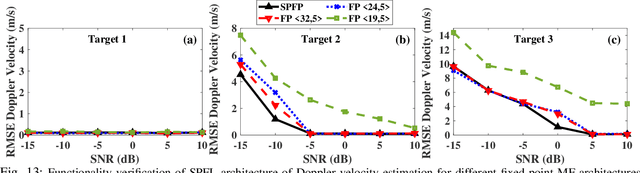
Millimeter wave (mmW) codesigned 802.11ad-based joint radar communication (JRC) systems have been identified as a potential solution for realizing high bandwidth connected vehicles for next-generation intelligent transportation systems. The radar functionality within the JRC enables accurate detection and localization of mobile targets, which can significantly speed up the selection of the optimal high-directional narrow beam required for mmW communications between the base station and mobile target. To bring JRC to reality, a radar signal processing (RSP) accelerator, co-located with the wireless communication physical layer (PHY), on edge platforms is desired. In this work, we discuss the three-dimensional digital hardware RSP framework for 802.11ad-based JRC to detect the range, azimuth, and Doppler velocity of multiple targets. We present a novel efficient reconfigurable architecture for RSP on multi-processor system-on-chip (MPSoC) via hardware-software co-design, word-length optimization, and serial-parallel configurations. We demonstrate the functional correctness of the proposed fixed-point architecture and significant savings in resource utilization (~40-70), execution time (1.5x improvement), and power consumption (50%) over floating-point architecture. The acceleration on hardware offers a 120-factor improvement in execution time over the benchmark Quad-core processor. The proposed architecture enables on-the-fly reconfigurability to support different azimuth precision and Doppler velocity resolution, offering a real-time trade-off between functional accuracy and detection time. We demonstrate end-to-end RSP on MPSoC with a user-friendly graphical user interface (GUI).
Accelerating Wireless Federated Learning via Nesterov's Momentum and Distributed Principle Component Analysis
Mar 31, 2023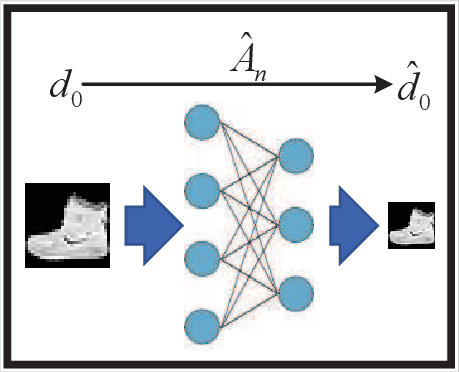
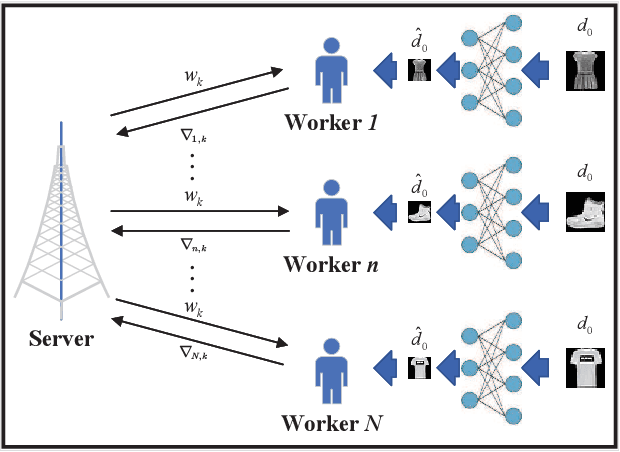
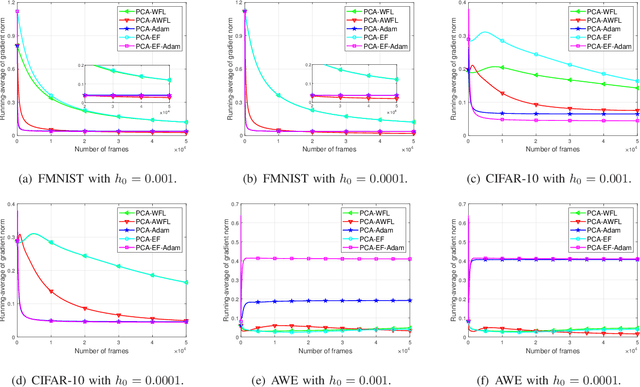
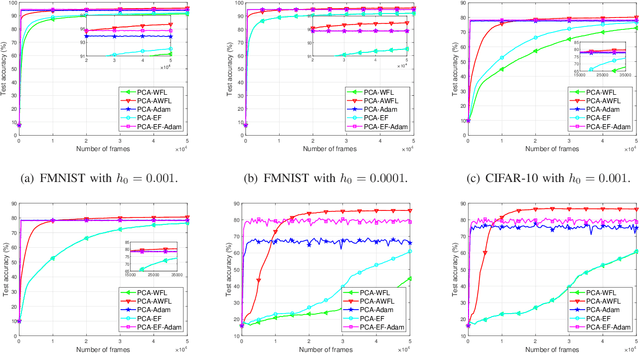
A wireless federated learning system is investigated by allowing a server and workers to exchange uncoded information via orthogonal wireless channels. Since the workers frequently upload local gradients to the server via bandwidth-limited channels, the uplink transmission from the workers to the server becomes a communication bottleneck. Therefore, a one-shot distributed principle component analysis (PCA) is leveraged to reduce the dimension of uploaded gradients such that the communication bottleneck is relieved. A PCA-based wireless federated learning (PCA-WFL) algorithm and its accelerated version (i.e., PCA-AWFL) are proposed based on the low-dimensional gradients and the Nesterov's momentum. For the non-convex loss functions, a finite-time analysis is performed to quantify the impacts of system hyper-parameters on the convergence of the PCA-WFL and PCA-AWFL algorithms. The PCA-AWFL algorithm is theoretically certified to converge faster than the PCA-WFL algorithm. Besides, the convergence rates of PCA-WFL and PCA-AWFL algorithms quantitatively reveal the linear speedup with respect to the number of workers over the vanilla gradient descent algorithm. Numerical results are used to demonstrate the improved convergence rates of the proposed PCA-WFL and PCA-AWFL algorithms over the benchmarks.