 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
S-Graphs+: Real-time Localization and Mapping leveraging Hierarchical Representations
Dec 22, 2022
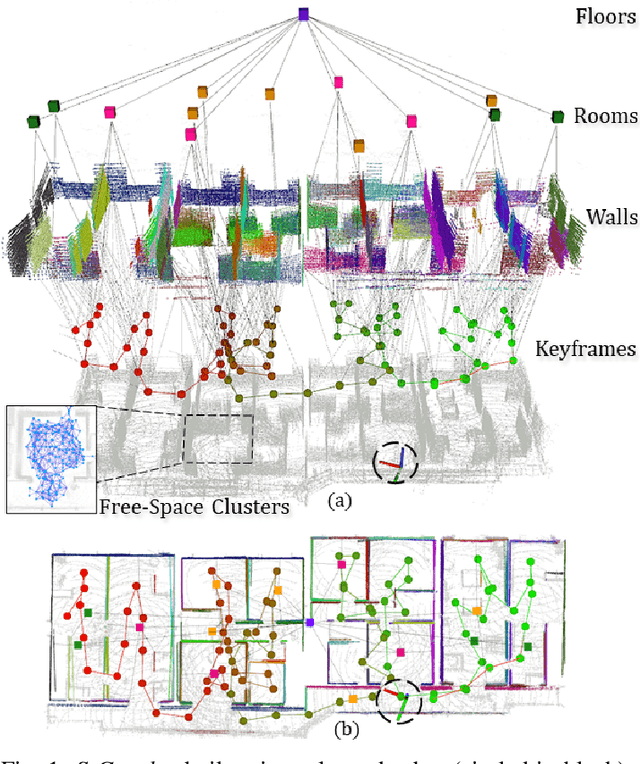
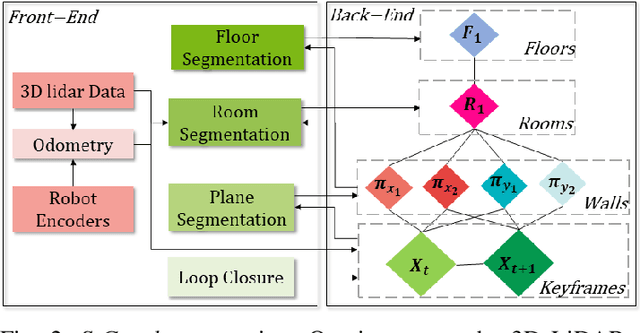
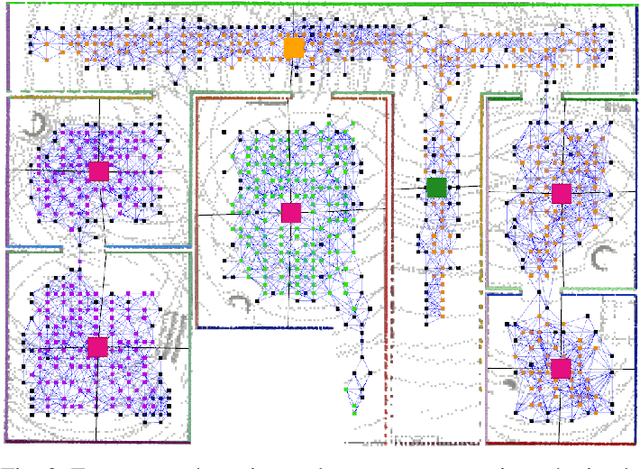
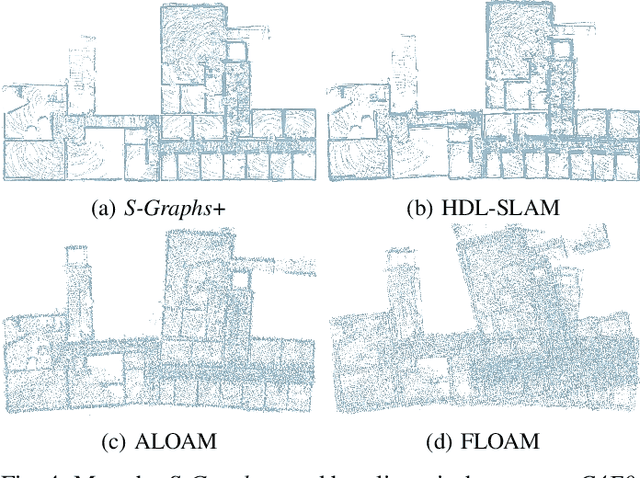
In this paper, we present an evolved version of the Situational Graphs, which jointly models in a single optimizable factor graph, a SLAM graph, as a set of robot keyframes, containing its associated measurements and robot poses, and a 3D scene graph, as a high-level representation of the environment that encodes its different geometric elements with semantic attributes and the relational information between those elements. Our proposed S-Graphs+ is a novel four-layered factor graph that includes: (1) a keyframes layer with robot pose estimates, (2) a walls layer representing wall surfaces, (3) a rooms layer encompassing sets of wall planes, and (4) a floors layer gathering the rooms within a given floor level. The above graph is optimized in real-time to obtain a robust and accurate estimate of the robot's pose and its map, simultaneously constructing and leveraging the high-level information of the environment. To extract such high-level information, we present novel room and floor segmentation algorithms utilizing the mapped wall planes and free-space clusters. We tested S-Graphs+ on multiple datasets including, simulations of distinct indoor environments, on real datasets captured over several construction sites and office environments, and on a real public dataset of indoor office environments. S-Graphs+ outperforms relevant baselines in the majority of the datasets while extending the robot situational awareness by a four-layered scene model. Moreover, we make the algorithm available as a docker file.
POPNASv3: a Pareto-Optimal Neural Architecture Search Solution for Image and Time Series Classification
Dec 13, 2022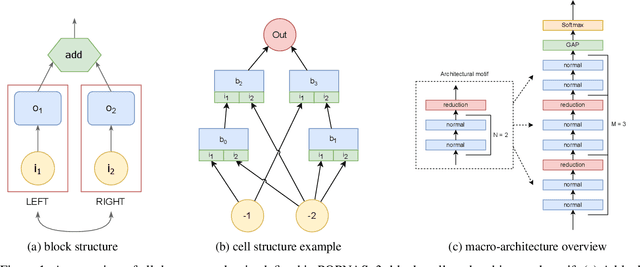

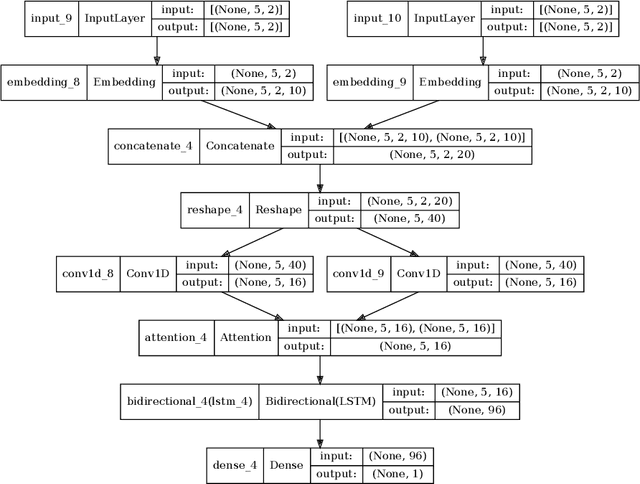

The automated machine learning (AutoML) field has become increasingly relevant in recent years. These algorithms can develop models without the need for expert knowledge, facilitating the application of machine learning techniques in the industry. Neural Architecture Search (NAS) exploits deep learning techniques to autonomously produce neural network architectures whose results rival the state-of-the-art models hand-crafted by AI experts. However, this approach requires significant computational resources and hardware investments, making it less appealing for real-usage applications. This article presents the third version of Pareto-Optimal Progressive Neural Architecture Search (POPNASv3), a new sequential model-based optimization NAS algorithm targeting different hardware environments and multiple classification tasks. Our method is able to find competitive architectures within large search spaces, while keeping a flexible structure and data processing pipeline to adapt to different tasks. The algorithm employs Pareto optimality to reduce the number of architectures sampled during the search, drastically improving the time efficiency without loss in accuracy. The experiments performed on images and time series classification datasets provide evidence that POPNASv3 can explore a large set of assorted operators and converge to optimal architectures suited for the type of data provided under different scenarios.
Sequential Learning from Noisy Data: Data-Assimilation Meets Echo-State Network
Apr 01, 2023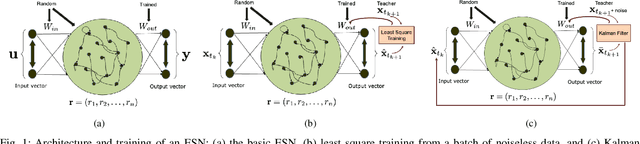
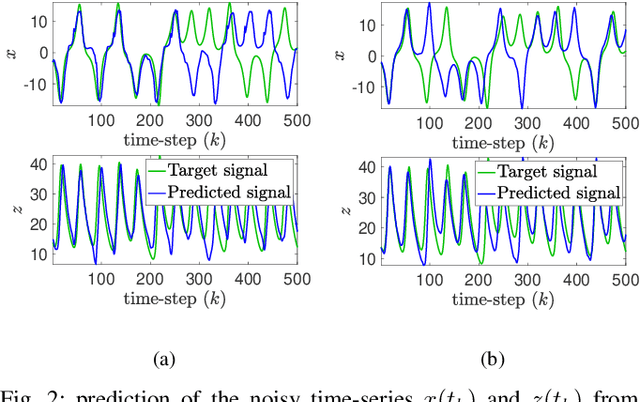
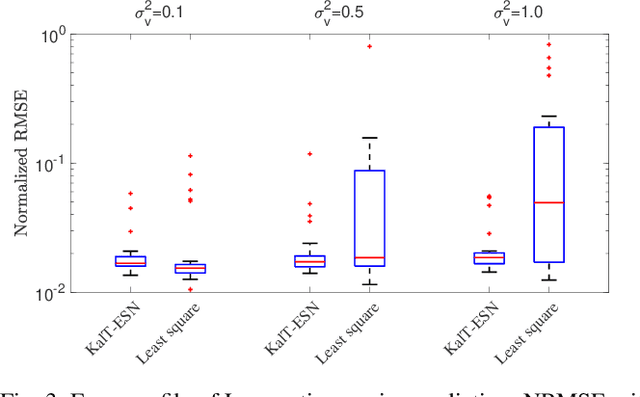
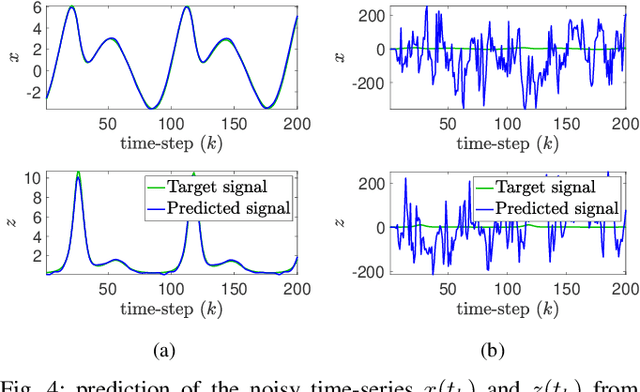
This paper explores the problem of training a recurrent neural network from noisy data. While neural network based dynamic predictors perform well with noise-free training data, prediction with noisy inputs during training phase poses a significant challenge. Here a sequential training algorithm is developed for an echo-state network (ESN) by incorporating noisy observations using an ensemble Kalman filter. The resultant Kalman-trained echo-state network (KalT-ESN) outperforms the traditionally trained ESN with least square algorithm while still being computationally cheap. The proposed method is demonstrated on noisy observations from three systems: two synthetic datasets from chaotic dynamical systems and a set of real-time traffic data.
AMS-DRL: Learning Multi-Pursuit Evasion for Safe Targeted Navigation of Drones
Apr 07, 2023
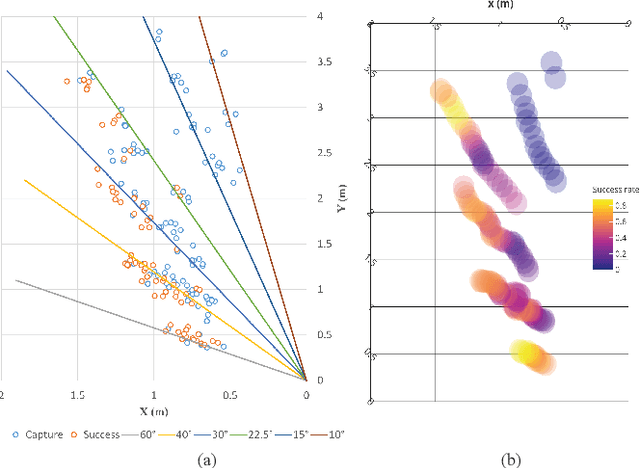
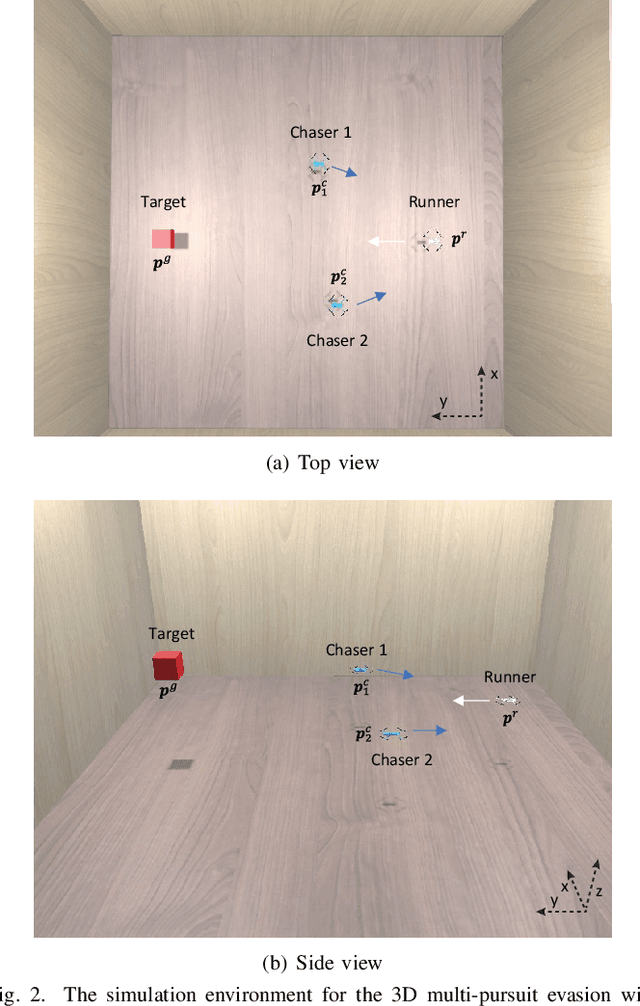
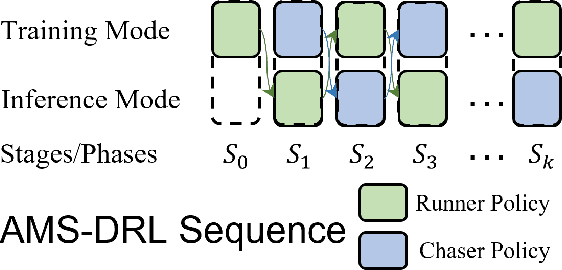
Safe navigation of drones in the presence of adversarial physical attacks from multiple pursuers is a challenging task. This paper proposes a novel approach, asynchronous multi-stage deep reinforcement learning (AMS-DRL), to train an adversarial neural network that can learn from the actions of multiple pursuers and adapt quickly to their behavior, enabling the drone to avoid attacks and reach its target. Our approach guarantees convergence by ensuring Nash Equilibrium among agents from the game-theory analysis. We evaluate our method in extensive simulations and show that it outperforms baselines with higher navigation success rates. We also analyze how parameters such as the relative maximum speed affect navigation performance. Furthermore, we have conducted physical experiments and validated the effectiveness of the trained policies in real-time flights. A success rate heatmap is introduced to elucidate how spatial geometry influences navigation outcomes. Project website: https://github.com/NTU-UAVG/AMS-DRL-for-Pursuit-Evasion.
Ring-Rotor: A Novel Retractable Ring-shaped Quadrotor with Aerial Grasping and Transportation Capability
Apr 07, 2023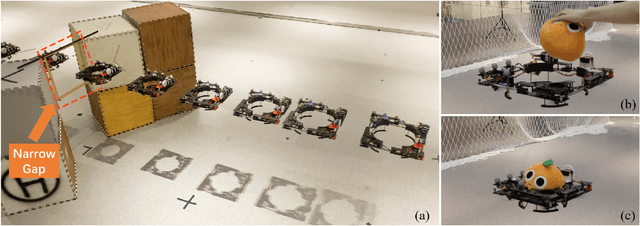



This letter presents a novel and retractable ring-shaped quadrotor called Ring-Rotor that can adjust the vehicle's length and width simultaneously. Unlike other morphing quadrotors with high platform complexity and poor controllability, Ring-Rotor uses only one servo motor for morphing but reduces the largest dimension of the vehicle by approximately 31.4\%. It can guarantee passibility while flying through small spaces in its compact form and energy saving in its standard form. Meanwhile, the vehicle breaks the cross configuration of general quadrotors with four arms connected to the central body and innovates a ring-shaped mechanical structure with spare central space. Based on this, an ingenious whole-body aerial grasping and transportation scheme is designed to carry various shapes of objects without the external manipulator mechanism. Moreover, we exploit a nonlinear model predictive control (NMPC) strategy that uses a time-variant physical parameter model to adapt to the quadrotor morphology. Above mentioned applications are performed in real-world experiments to demonstrate the system's high versatility.
A Learnheuristic Approach to A Constrained Multi-Objective Portfolio Optimisation Problem
Apr 13, 2023Multi-objective portfolio optimisation is a critical problem researched across various fields of study as it achieves the objective of maximising the expected return while minimising the risk of a given portfolio at the same time. However, many studies fail to include realistic constraints in the model, which limits practical trading strategies. This study introduces realistic constraints, such as transaction and holding costs, into an optimisation model. Due to the non-convex nature of this problem, metaheuristic algorithms, such as NSGA-II, R-NSGA-II, NSGA-III and U-NSGA-III, will play a vital role in solving the problem. Furthermore, a learnheuristic approach is taken as surrogate models enhance the metaheuristics employed. These algorithms are then compared to the baseline metaheuristic algorithms, which solve a constrained, multi-objective optimisation problem without using learnheuristics. The results of this study show that, despite taking significantly longer to run to completion, the learnheuristic algorithms outperform the baseline algorithms in terms of hypervolume and rate of convergence. Furthermore, the backtesting results indicate that utilising learnheuristics to generate weights for asset allocation leads to a lower risk percentage, higher expected return and higher Sharpe ratio than backtesting without using learnheuristics. This leads us to conclude that using learnheuristics to solve a constrained, multi-objective portfolio optimisation problem produces superior and preferable results than solving the problem without using learnheuristics.
Probably Approximately Correct Federated Learning
Apr 13, 2023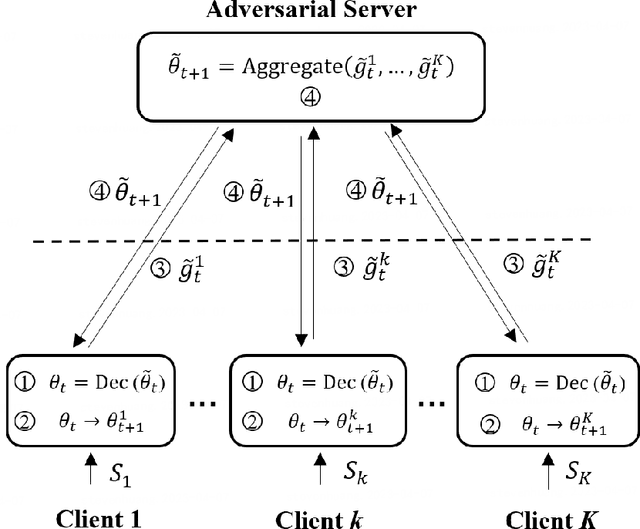

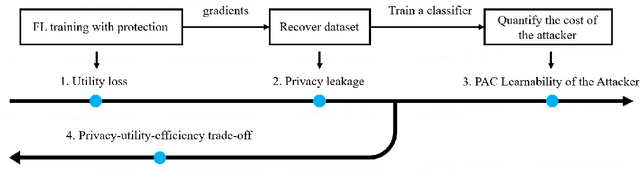
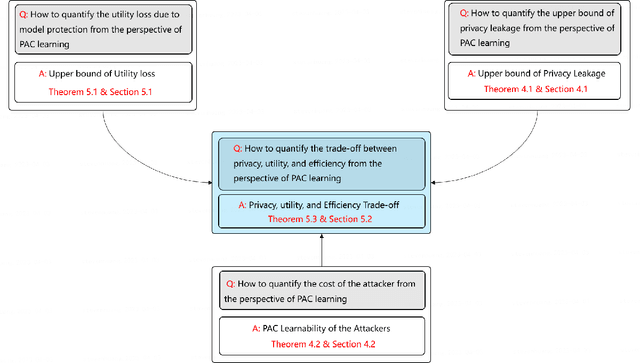
Federated learning (FL) is a new distributed learning paradigm, with privacy, utility, and efficiency as its primary pillars. Existing research indicates that it is unlikely to simultaneously attain infinitesimal privacy leakage, utility loss, and efficiency. Therefore, how to find an optimal trade-off solution is the key consideration when designing the FL algorithm. One common way is to cast the trade-off problem as a multi-objective optimization problem, i.e., the goal is to minimize the utility loss and efficiency reduction while constraining the privacy leakage not exceeding a predefined value. However, existing multi-objective optimization frameworks are very time-consuming, and do not guarantee the existence of the Pareto frontier, this motivates us to seek a solution to transform the multi-objective problem into a single-objective problem because it is more efficient and easier to be solved. To this end, we propose FedPAC, a unified framework that leverages PAC learning to quantify multiple objectives in terms of sample complexity, such quantification allows us to constrain the solution space of multiple objectives to a shared dimension, so that it can be solved with the help of a single-objective optimization algorithm. Specifically, we provide the results and detailed analyses of how to quantify the utility loss, privacy leakage, privacy-utility-efficiency trade-off, as well as the cost of the attacker from the PAC learning perspective.
Generalizable Deep Learning Method for Suppressing Unseen and Multiple MRI Artifacts Using Meta-learning
Apr 13, 2023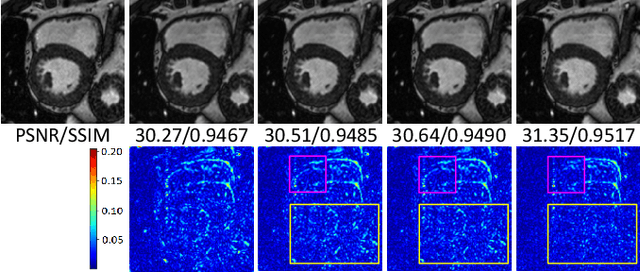
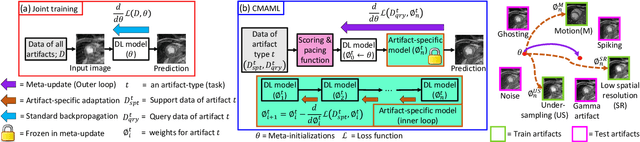
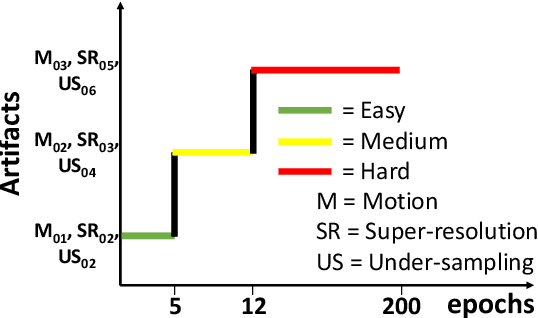
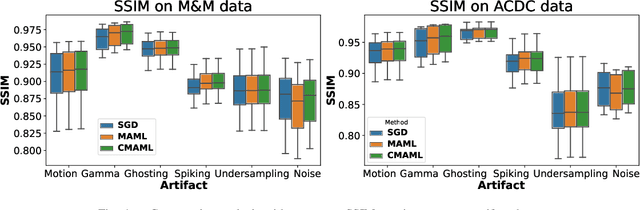
Magnetic Resonance (MR) images suffer from various types of artifacts due to motion, spatial resolution, and under-sampling. Conventional deep learning methods deal with removing a specific type of artifact, leading to separately trained models for each artifact type that lack the shared knowledge generalizable across artifacts. Moreover, training a model for each type and amount of artifact is a tedious process that consumes more training time and storage of models. On the other hand, the shared knowledge learned by jointly training the model on multiple artifacts might be inadequate to generalize under deviations in the types and amounts of artifacts. Model-agnostic meta-learning (MAML), a nested bi-level optimization framework is a promising technique to learn common knowledge across artifacts in the outer level of optimization, and artifact-specific restoration in the inner level. We propose curriculum-MAML (CMAML), a learning process that integrates MAML with curriculum learning to impart the knowledge of variable artifact complexity to adaptively learn restoration of multiple artifacts during training. Comparative studies against Stochastic Gradient Descent and MAML, using two cardiac datasets reveal that CMAML exhibits (i) better generalization with improved PSNR for 83% of unseen types and amounts of artifacts and improved SSIM in all cases, and (ii) better artifact suppression in 4 out of 5 cases of composite artifacts (scans with multiple artifacts).
Solving Regularized Exp, Cosh and Sinh Regression Problems
Mar 28, 2023In modern machine learning, attention computation is a fundamental task for training large language models such as Transformer, GPT-4 and ChatGPT. In this work, we study exponential regression problem which is inspired by the softmax/exp unit in the attention mechanism in large language models. The standard exponential regression is non-convex. We study the regularization version of exponential regression problem which is a convex problem. We use approximate newton method to solve in input sparsity time. Formally, in this problem, one is given matrix $A \in \mathbb{R}^{n \times d}$, $b \in \mathbb{R}^n$, $w \in \mathbb{R}^n$ and any of functions $\exp, \cosh$ and $\sinh$ denoted as $f$. The goal is to find the optimal $x$ that minimize $ 0.5 \| f(Ax) - b \|_2^2 + 0.5 \| \mathrm{diag}(w) A x \|_2^2$. The straightforward method is to use the naive Newton's method. Let $\mathrm{nnz}(A)$ denote the number of non-zeros entries in matrix $A$. Let $\omega$ denote the exponent of matrix multiplication. Currently, $\omega \approx 2.373$. Let $\epsilon$ denote the accuracy error. In this paper, we make use of the input sparsity and purpose an algorithm that use $\log ( \|x_0 - x^*\|_2 / \epsilon)$ iterations and $\widetilde{O}(\mathrm{nnz}(A) + d^{\omega} )$ per iteration time to solve the problem.
Online Learning of Wheel Odometry Correction for Mobile Robots with Attention-based Neural Network
Mar 21, 2023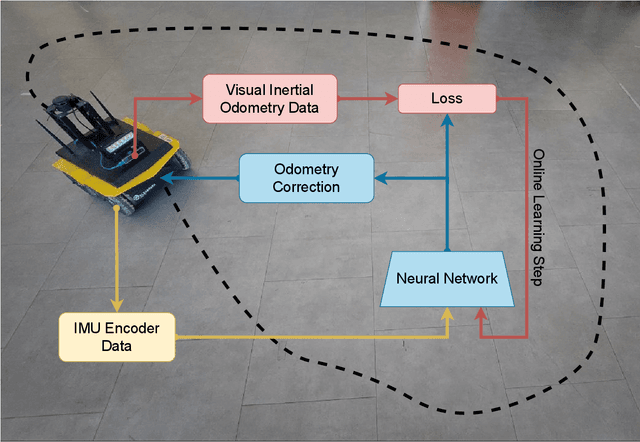
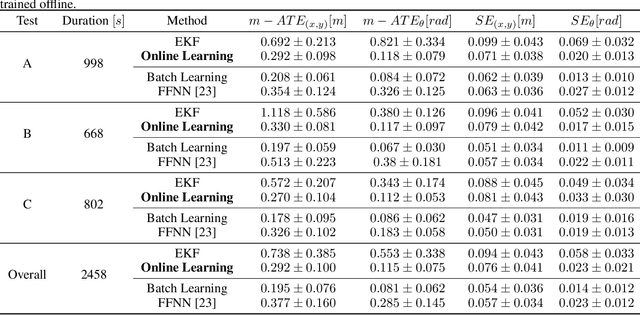
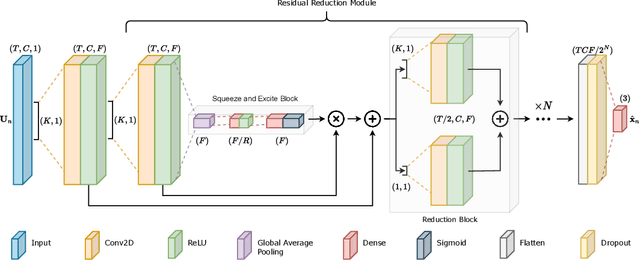
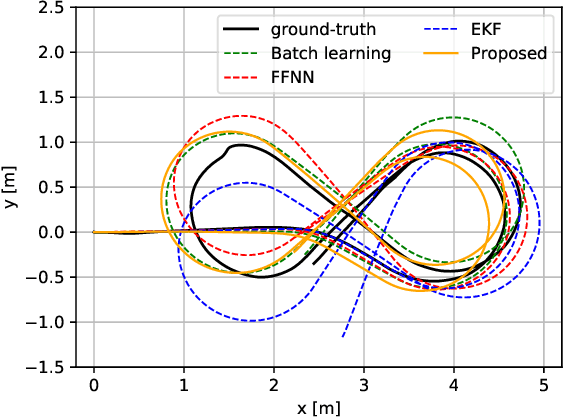
Modern robotic platforms need a reliable localization system to operate daily beside humans. Simple pose estimation algorithms based on filtered wheel and inertial odometry often fail in the presence of abrupt kinematic changes and wheel slips. Moreover, despite the recent success of visual odometry, service and assistive robotic tasks often present challenging environmental conditions where visual-based solutions fail due to poor lighting or repetitive feature patterns. In this work, we propose an innovative online learning approach for wheel odometry correction, paving the way for a robust multi-source localization system. An efficient attention-based neural network architecture has been studied to combine precise performances with real-time inference. The proposed solution shows remarkable results compared to a standard neural network and filter-based odometry correction algorithms. Nonetheless, the online learning paradigm avoids the time-consuming data collection procedure and can be adopted on a generic robotic platform on-the-fly.