 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Route Planning with Distributional Reinforcement Learning in a Stochastic Road Network Environment
Apr 19, 2023

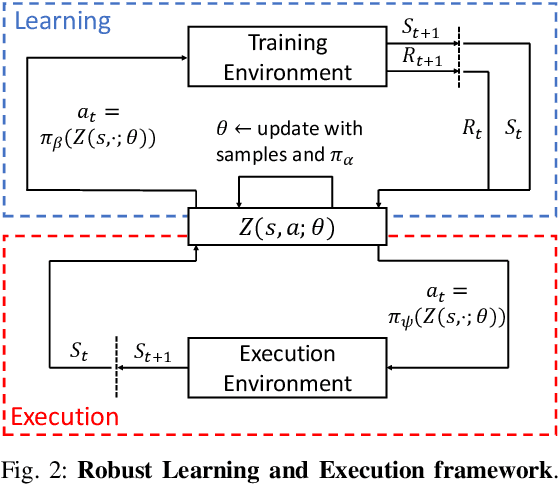
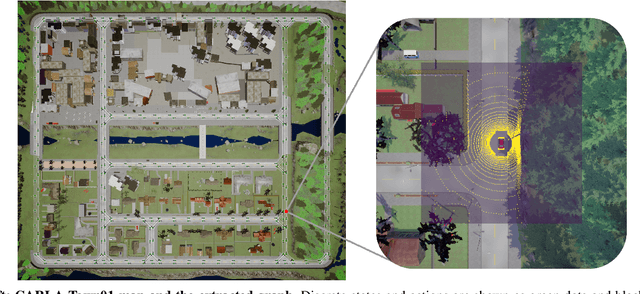

Route planning is essential to mobile robot navigation problems. In recent years, deep reinforcement learning (DRL) has been applied to learning optimal planning policies in stochastic environments without prior knowledge. However, existing works focus on learning policies that maximize the expected return, the performance of which can vary greatly when the level of stochasticity in the environment is high. In this work, we propose a distributional reinforcement learning based framework that learns return distributions which explicitly reflect environmental stochasticity. Policies based on the second-order stochastic dominance (SSD) relation can be used to make adjustable route decisions according to user preference on performance robustness. Our proposed method is evaluated in a simulated road network environment, and experimental results show that our method is able to plan the shortest routes that minimize stochasticity in travel time when robustness is preferred, while other state-of-the-art DRL methods are agnostic to environmental stochasticity.
Power Law Trends in Speedrunning and Machine Learning
Apr 19, 2023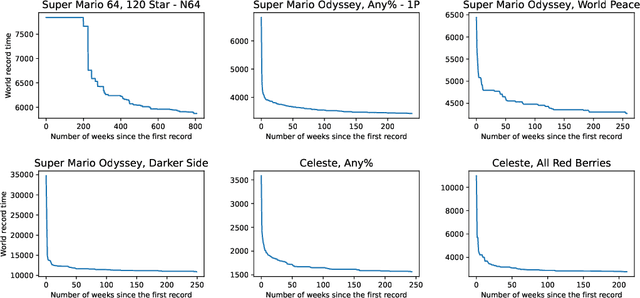
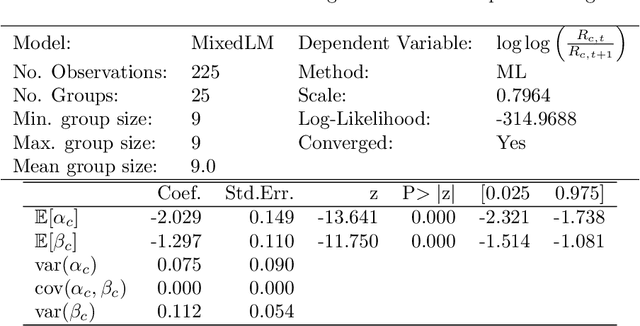
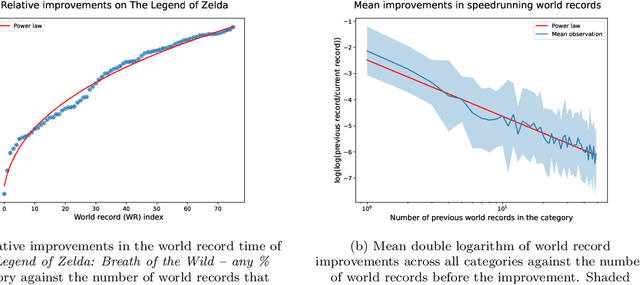

We find that improvements in speedrunning world records follow a power law pattern. Using this observation, we answer an outstanding question from previous work: How do we improve on the baseline of predicting no improvement when forecasting speedrunning world records out to some time horizon, such as one month? Using a random effects model, we improve on this baseline for relative mean square error made on predicting out-of-sample world record improvements as the comparison metric at a $p < 10^{-5}$ significance level. The same set-up improves \textit{even} on the ex-post best exponential moving average forecasts at a $p = 0.15$ significance level while having access to substantially fewer data points. We demonstrate the effectiveness of this approach by applying it to Machine Learning benchmarks and achieving forecasts that exceed a baseline. Finally, we interpret the resulting model to suggest that 1) ML benchmarks are far from saturation and 2) sudden large improvements in Machine Learning are unlikely but cannot be ruled out.
Big-Little Adaptive Neural Networks on Low-Power Near-Subthreshold Processors
Apr 19, 2023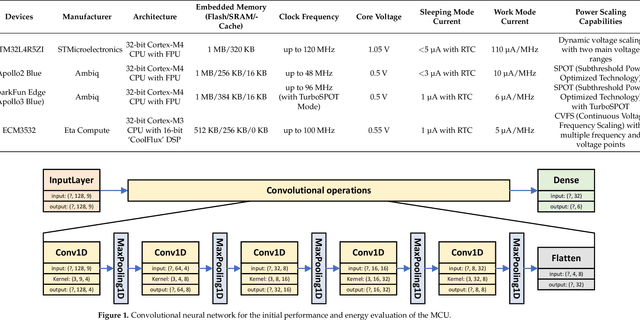
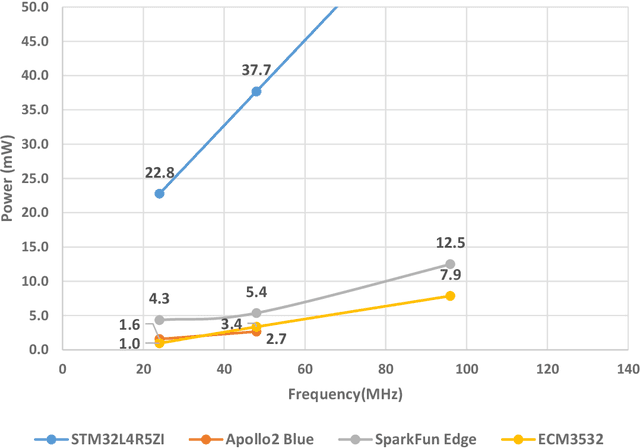
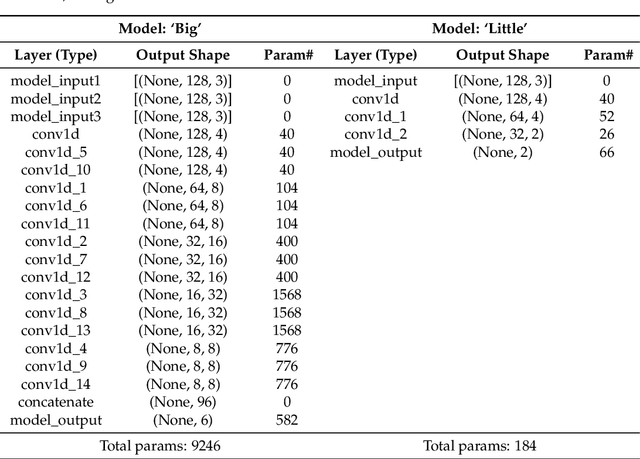
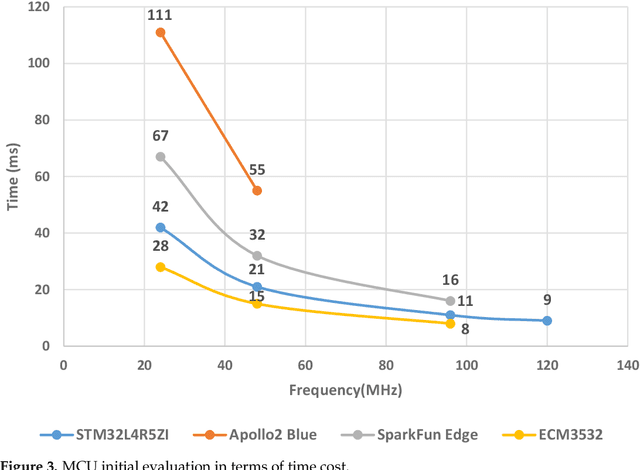
This paper investigates the energy savings that near-subthreshold processors can obtain in edge AI applications and proposes strategies to improve them while maintaining the accuracy of the application. The selected processors deploy adaptive voltage scaling techniques in which the frequency and voltage levels of the processor core are determined at the run-time. In these systems, embedded RAM and flash memory size is typically limited to less than 1 megabyte to save power. This limited memory imposes restrictions on the complexity of the neural networks model that can be mapped to these devices and the required trade-offs between accuracy and battery life. To address these issues, we propose and evaluate alternative 'big-little' neural network strategies to improve battery life while maintaining prediction accuracy. The strategies are applied to a human activity recognition application selected as a demonstrator that shows that compared to the original network, the best configurations obtain an energy reduction measured at 80% while maintaining the original level of inference accuracy.
* 27 pages, 17 figures, https://github.com/DarkSZChao/Big-Little_NN_Strategies
Learning policies for resource allocation in business processes
Apr 19, 2023
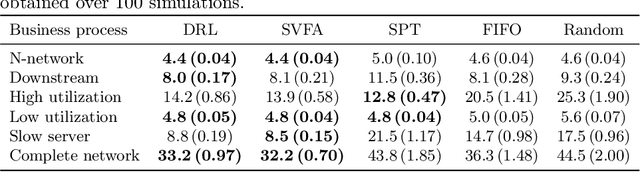
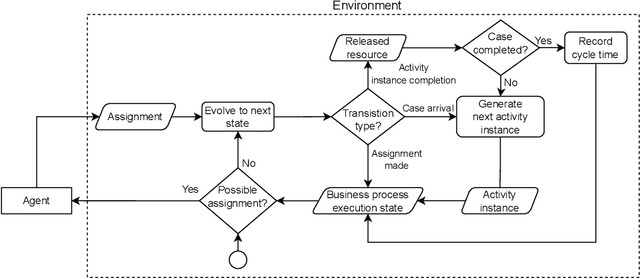
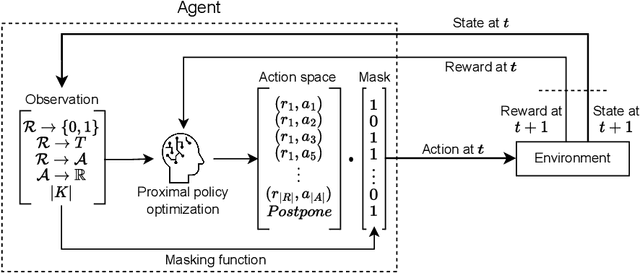
Resource allocation is the assignment of resources to activities that must be executed in a business process at a particular moment at run-time. While resource allocation is well-studied in other fields, such as manufacturing, there exist only a few methods in business process management. Existing methods are not suited for application in large business processes or focus on optimizing resource allocation for a single case rather than for all cases combined. To fill this gap, this paper proposes two learning-based methods for resource allocation in business processes: a deep reinforcement learning-based approach and a score-based value function approximation approach. The two methods are compared against existing heuristics in a set of scenarios that represent typical business process structures and on a complete network that represents a realistic business process. The results show that our learning-based methods outperform or are competitive with common heuristics in most scenarios and outperform heuristics in the complete network.
Origin Tracing and Detecting of LLMs
Apr 27, 2023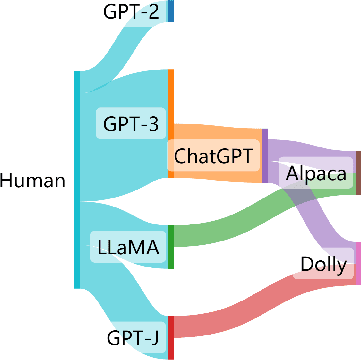

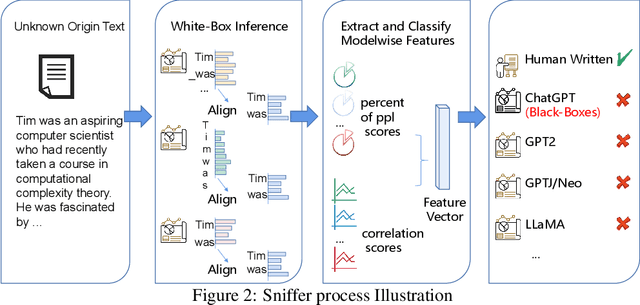
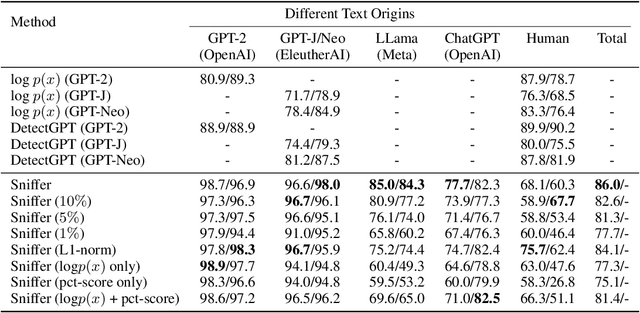
The extraordinary performance of large language models (LLMs) heightens the importance of detecting whether the context is generated by an AI system. More importantly, while more and more companies and institutions release their LLMs, the origin can be hard to trace. Since LLMs are heading towards the time of AGI, similar to the origin tracing in anthropology, it is of great importance to trace the origin of LLMs. In this paper, we first raise the concern of the origin tracing of LLMs and propose an effective method to trace and detect AI-generated contexts. We introduce a novel algorithm that leverages the contrastive features between LLMs and extracts model-wise features to trace the text origins. Our proposed method works under both white-box and black-box settings therefore can be widely generalized to detect various LLMs.(e.g. can be generalized to detect GPT-3 models without the GPT-3 models). Also, our proposed method requires only limited data compared with the supervised learning methods and can be extended to trace new-coming model origins. We construct extensive experiments to examine whether we can trace the origins of given texts. We provide valuable observations based on the experimental results, such as the difficulty level of AI origin tracing, and the AI origin similarities, and call for ethical concerns of LLM providers. We are releasing all codes and data as a toolkit and benchmark for future AI origin tracing and detecting studies. \footnote{We are releasing all available resource at \url{https://github.com/OpenLMLab/}.}
Shot Optimization in Quantum Machine Learning Architectures to Accelerate Training
Apr 27, 2023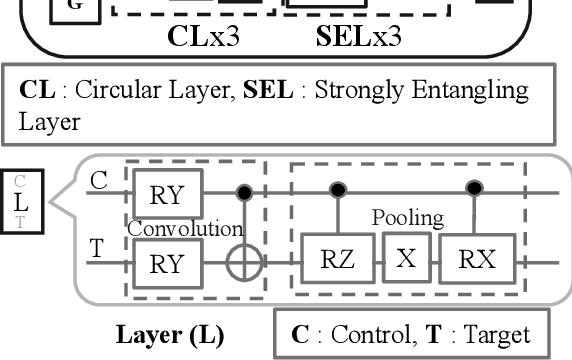
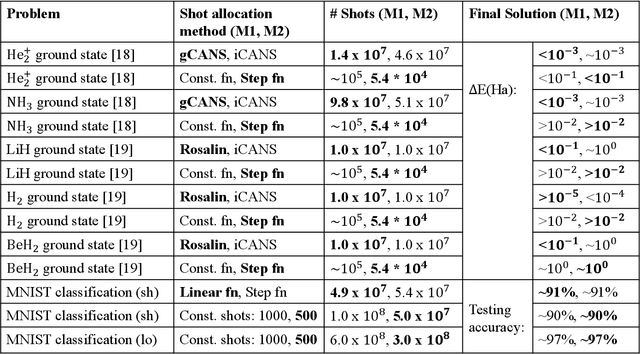
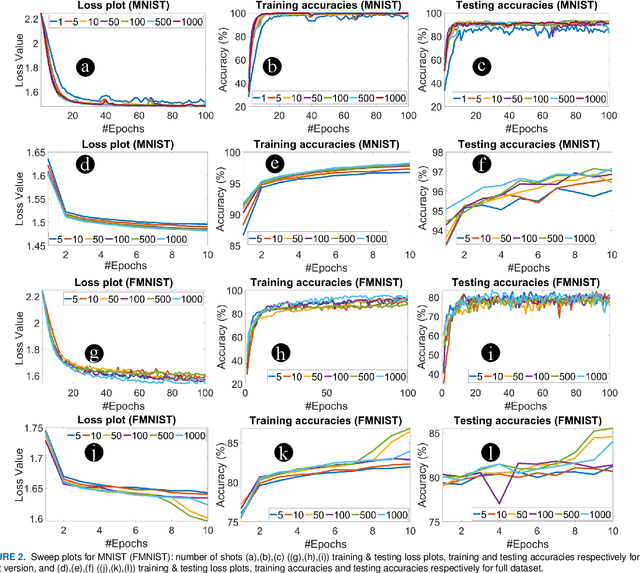
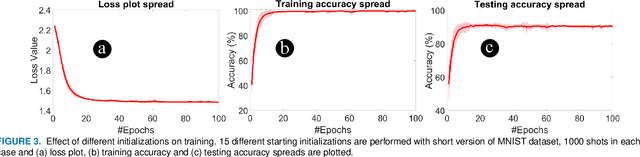
In this paper, we propose shot optimization method for QML models at the expense of minimal impact on model performance. We use classification task as a test case for MNIST and FMNIST datasets using a hybrid quantum-classical QML model. First, we sweep the number of shots for short and full versions of the dataset. We observe that training the full version provides 5-6% higher testing accuracy than short version of dataset with up to 10X higher number of shots for training. Therefore, one can reduce the dataset size to accelerate the training time. Next, we propose adaptive shot allocation on short version dataset to optimize the number of shots over training epochs and evaluate the impact on classification accuracy. We use a (a) linear function where the number of shots reduce linearly with epochs, and (b) step function where the number of shots reduce in step with epochs. We note around 0.01 increase in loss and around 4% (1%) reduction in testing accuracy for reduction in shots by up to 100X (10X) for linear (step) shot function compared to conventional constant shot function for MNIST dataset, and 0.05 increase in loss and around 5-7% (5-7%) reduction in testing accuracy with similar reduction in shots using linear (step) shot function on FMNIST dataset. For comparison, we also use the proposed shot optimization methods to perform ground state energy estimation of different molecules and observe that step function gives the best and most stable ground state energy prediction at 1000X less number of shots.
Quadric Representations for LiDAR Odometry, Mapping and Localization
Apr 27, 2023
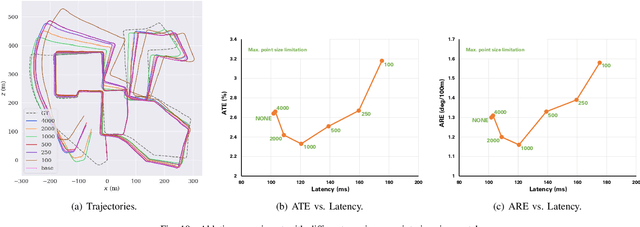
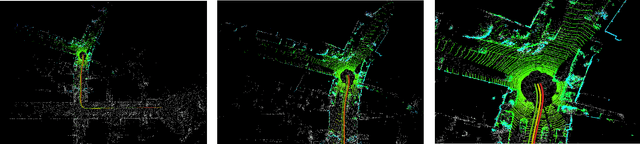
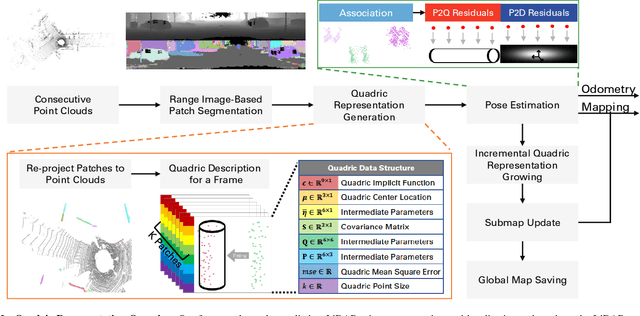
Current LiDAR odometry, mapping and localization methods leverage point-wise representations of 3D scenes and achieve high accuracy in autonomous driving tasks. However, the space-inefficiency of methods that use point-wise representations limits their development and usage in practical applications. In particular, scan-submap matching and global map representation methods are restricted by the inefficiency of nearest neighbor searching (NNS) for large-volume point clouds. To improve space-time efficiency, we propose a novel method of describing scenes using quadric surfaces, which are far more compact representations of 3D objects than conventional point clouds. In contrast to point cloud-based methods, our quadric representation-based method decomposes a 3D scene into a collection of sparse quadric patches, which improves storage efficiency and avoids the slow point-wise NNS process. Our method first segments a given point cloud into patches and fits each of them to a quadric implicit function. Each function is then coupled with other geometric descriptors of the patch, such as its center position and covariance matrix. Collectively, these patch representations fully describe a 3D scene, which can be used in place of the original point cloud and employed in LiDAR odometry, mapping and localization algorithms. We further design a novel incremental growing method for quadric representations, which eliminates the need to repeatedly re-fit quadric surfaces from the original point cloud. Extensive odometry, mapping and localization experiments on large-volume point clouds in the KITTI and UrbanLoco datasets demonstrate that our method maintains low latency and memory utility while achieving competitive, and even superior, accuracy.
A mean-field games laboratory for generative modeling
Apr 27, 2023In this paper, we demonstrate the versatility of mean-field games (MFGs) as a mathematical framework for explaining, enhancing, and designing generative models. There is a pervasive sense in the generative modeling community that the various flow and diffusion-based generative models have some foundational common structure and interrelationships. We establish connections between MFGs and major classes of flow and diffusion-based generative models including continuous-time normalizing flows, score-based models, and Wasserstein gradient flows. We derive these three classes of generative models through different choices of particle dynamics and cost functions. Furthermore, we study the mathematical structure and properties of each generative model by studying their associated MFG's optimality condition, which is a set of coupled nonlinear partial differential equations (PDEs). The theory of MFGs, therefore, enables the study of generative models through the theory of nonlinear PDEs. Through this perspective, we investigate the well-posedness and structure of normalizing flows, unravel the mathematical structure of score-based generative modeling, and derive a mean-field game formulation of the Wasserstein gradient flow. From an algorithmic perspective, the optimality conditions of MFGs also allow us to introduce HJB regularizers for enhanced training a broader class of generative models. We present this framework as an MFG laboratory which serves as a platform for revealing new avenues of experimentation and invention of generative models. This laboratory will give rise to a multitude of well-posed generative modeling formulations, providing a consistent theoretical framework upon which numerical and algorithmic tools may be developed.
CoreDiff: Contextual Error-Modulated Generalized Diffusion Model for Low-Dose CT Denoising and Generalization
Apr 04, 2023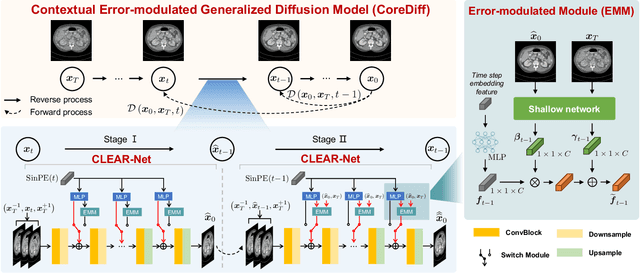
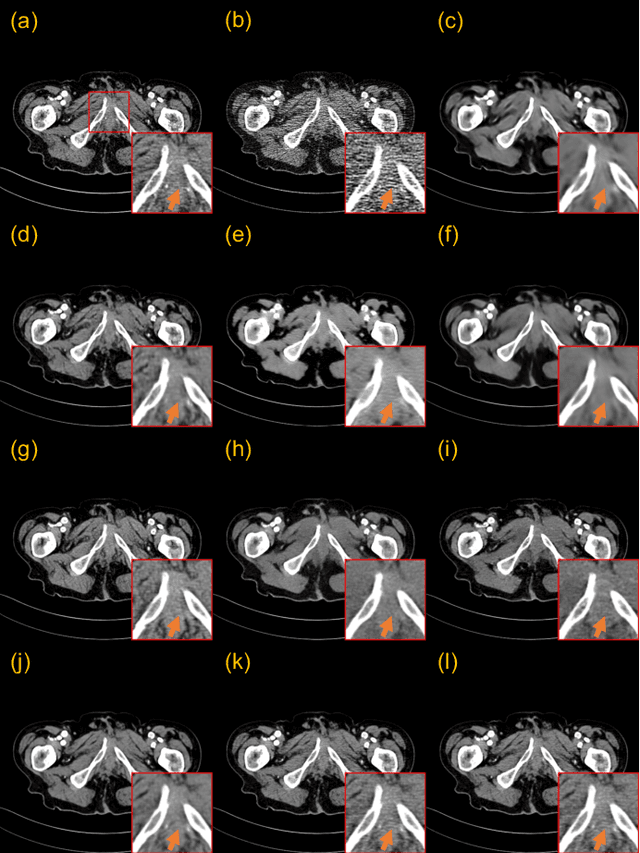
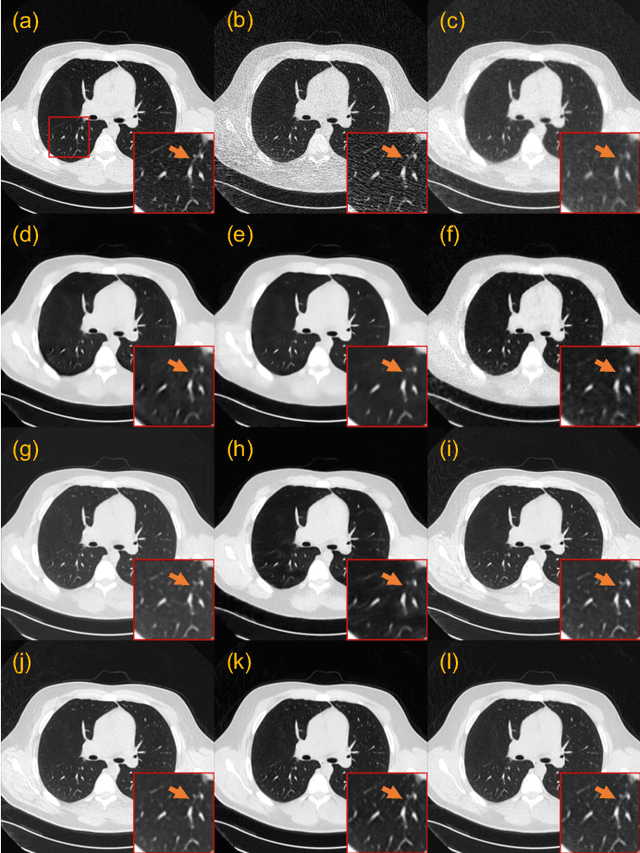

Low-dose computed tomography (CT) images suffer from noise and artifacts due to photon starvation and electronic noise. Recently, some works have attempted to use diffusion models to address the over-smoothness and training instability encountered by previous deep-learning-based denoising models. However, diffusion models suffer from long inference times due to the large number of sampling steps involved. Very recently, cold diffusion model generalizes classical diffusion models and has greater flexibility. Inspired by the cold diffusion, this paper presents a novel COntextual eRror-modulated gEneralized Diffusion model for low-dose CT (LDCT) denoising, termed CoreDiff. First, CoreDiff utilizes LDCT images to displace the random Gaussian noise and employs a novel mean-preserving degradation operator to mimic the physical process of CT degradation, significantly reducing sampling steps thanks to the informative LDCT images as the starting point of the sampling process. Second, to alleviate the error accumulation problem caused by the imperfect restoration operator in the sampling process, we propose a novel ContextuaL Error-modulAted Restoration Network (CLEAR-Net), which can leverage contextual information to constrain the sampling process from structural distortion and modulate time step embedding features for better alignment with the input at the next time step. Third, to rapidly generalize to a new, unseen dose level with as few resources as possible, we devise a one-shot learning framework to make CoreDiff generalize faster and better using only a single LDCT image (un)paired with NDCT. Extensive experimental results on two datasets demonstrate that our CoreDiff outperforms competing methods in denoising and generalization performance, with a clinically acceptable inference time.
Knowledge Distillation from 3D to Bird's-Eye-View for LiDAR Semantic Segmentation
Apr 22, 2023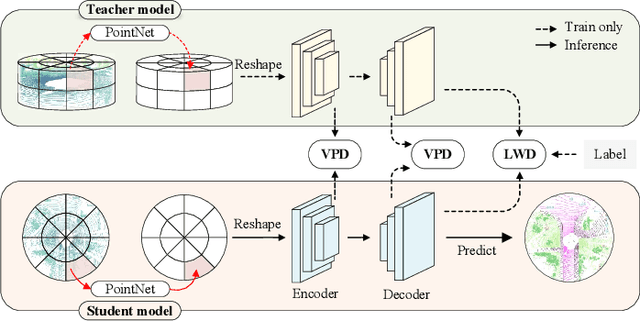
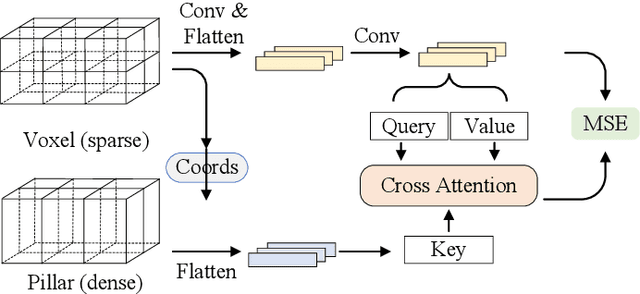
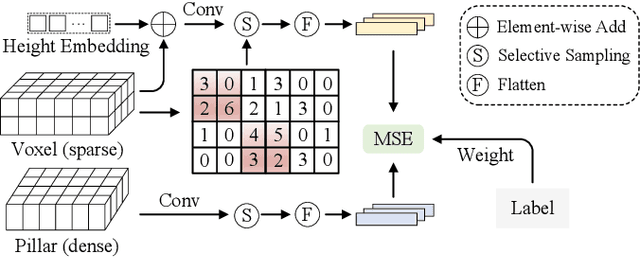
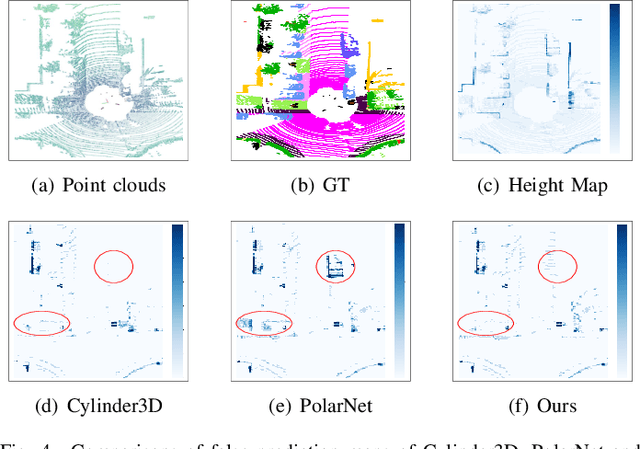
LiDAR point cloud segmentation is one of the most fundamental tasks for autonomous driving scene understanding. However, it is difficult for existing models to achieve both high inference speed and accuracy simultaneously. For example, voxel-based methods perform well in accuracy, while Bird's-Eye-View (BEV)-based methods can achieve real-time inference. To overcome this issue, we develop an effective 3D-to-BEV knowledge distillation method that transfers rich knowledge from 3D voxel-based models to BEV-based models. Our framework mainly consists of two modules: the voxel-to-pillar distillation module and the label-weight distillation module. Voxel-to-pillar distillation distills sparse 3D features to BEV features for middle layers to make the BEV-based model aware of more structural and geometric information. Label-weight distillation helps the model pay more attention to regions with more height information. Finally, we conduct experiments on the SemanticKITTI dataset and Paris-Lille-3D. The results on SemanticKITTI show more than 5% improvement on the test set, especially for classes such as motorcycle and person, with more than 15% improvement. The code can be accessed at https://github.com/fengjiang5/Knowledge-Distillation-from-Cylinder3D-to-PolarNet.