 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Novel Low-Rank Tensor Method for Undersampling Artifact Removal in Respiratory Motion-Resolved Multi-Echo 3D Cones MRI
May 01, 2023
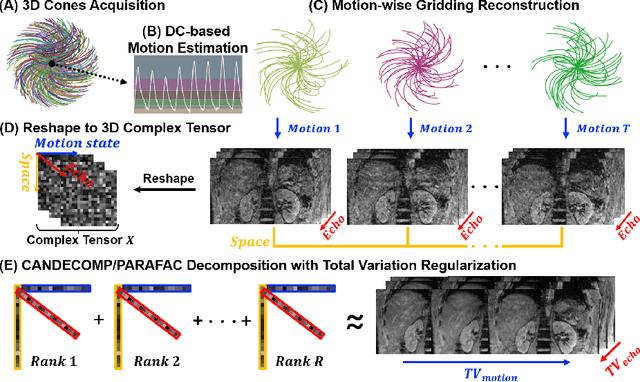
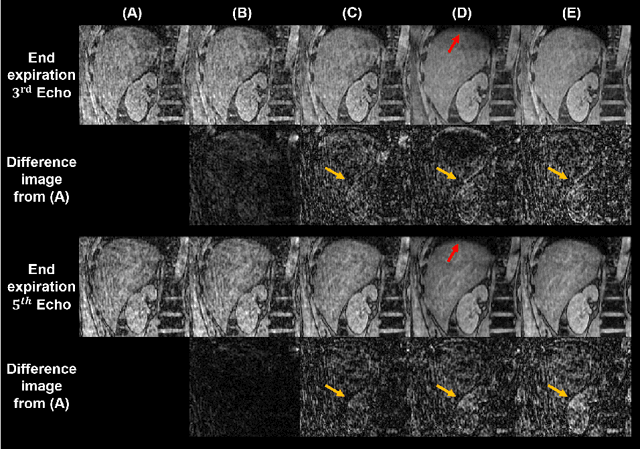
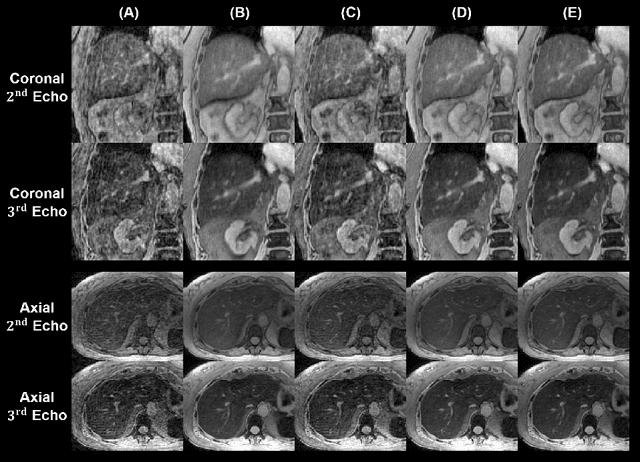
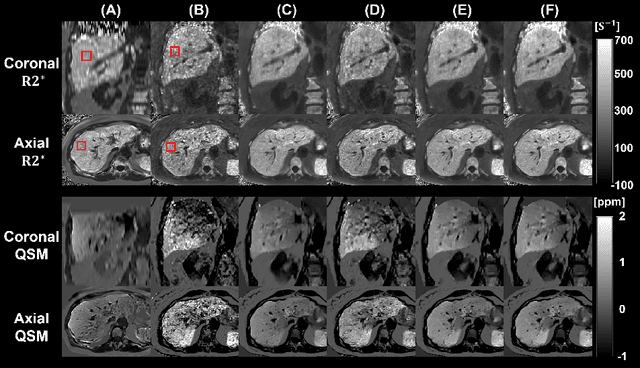
We propose a novel low-rank tensor method for respiratory motion-resolved multi-echo image reconstruction. The key idea is to construct a 3-way image tensor (space $\times$ echo $\times$ motion state) from the conventional gridding reconstruction of highly undersampled multi-echo k-space raw data, and exploit low-rank tensor structure to separate it from undersampling artifacts. Healthy volunteers and patients with iron overload were recruited and imaged on a 3T clinical MRI system for this study. Results show that our proposed method Successfully reduced severe undersampling artifacts in respiratory motion-state resolved complex source images, as well as subsequent R2* and quantitative susceptibility mapping (QSM). Compared to conventional respiratory motion-resolved compressed sensing (CS) image reconstruction, the proposed method had a reconstruction time at least three times faster, accounting for signal evolution along the echo dimension in the multi-echo data.
Multiple description video coding for real-time applications using HEVC
Mar 10, 2023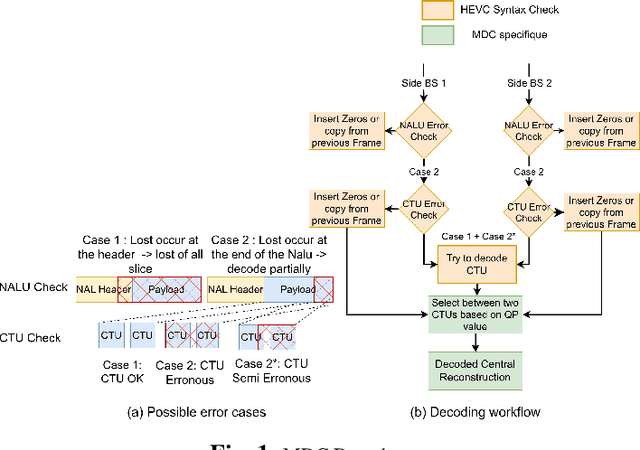
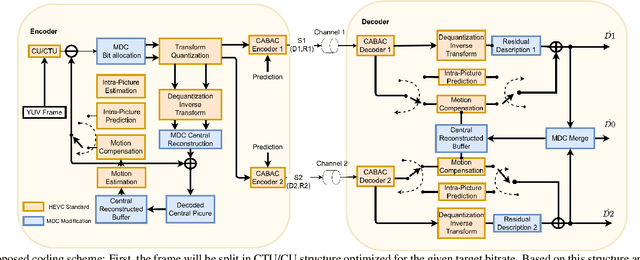
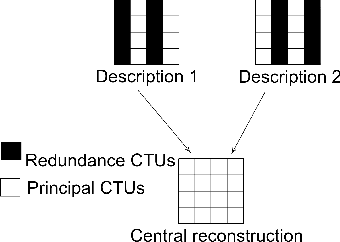
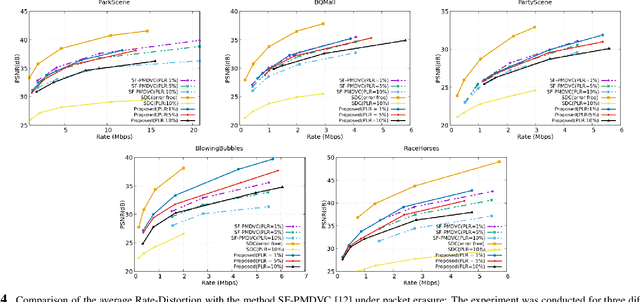
Remote control vehicles require the transmission of large amounts of data, and video is one of the most important sources for the driver. To ensure reliable video transmission, the encoded video stream is transmitted simultaneously over multiple channels. However, this solution incurs a high transmission cost due to the wireless channel's unreliable and random bit loss characteristics. To address this issue, it is necessary to use more efficient video encoding methods that can make the video stream robust to noise. In this paper, we propose a low-complexity, low-latency 2-channel Multiple Description Coding (MDC) solution with an adaptive Instantaneous Decoder Refresh (IDR) frame period, which is compatible with the HEVC standard. This method shows better resistance to high packet loss rates with lower complexity.
Learning Transition Operators From Sparse Space-Time Samples
Dec 01, 2022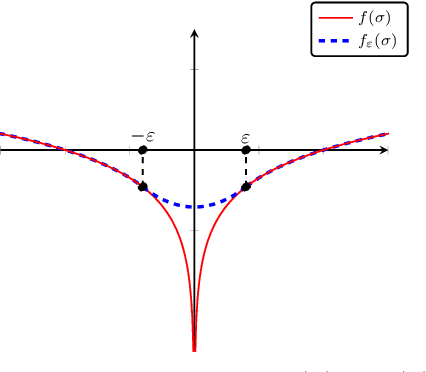
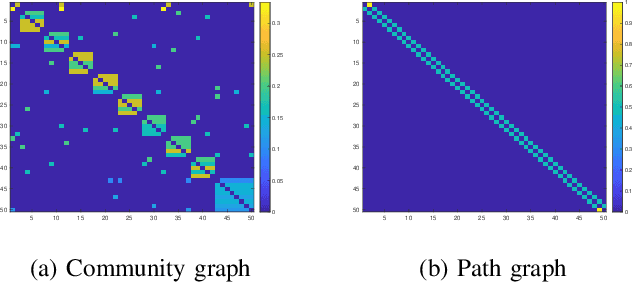
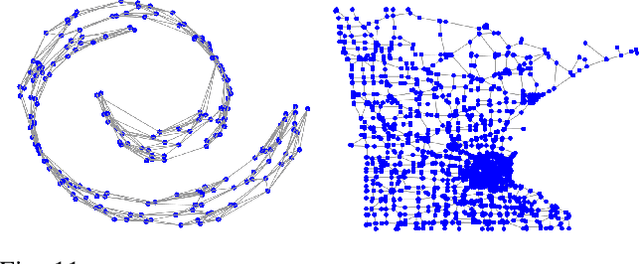
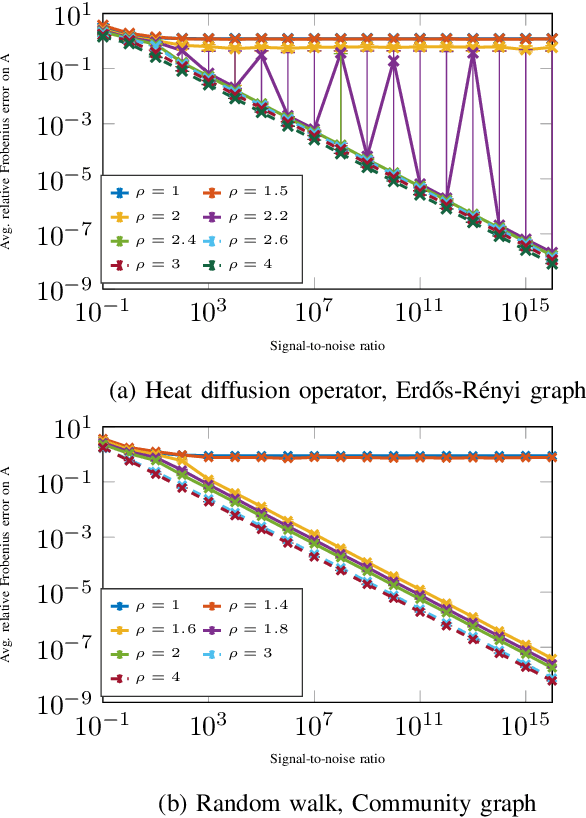
We consider the nonlinear inverse problem of learning a transition operator $\mathbf{A}$ from partial observations at different times, in particular from sparse observations of entries of its powers $\mathbf{A},\mathbf{A}^2,\cdots,\mathbf{A}^{T}$. This Spatio-Temporal Transition Operator Recovery problem is motivated by the recent interest in learning time-varying graph signals that are driven by graph operators depending on the underlying graph topology. We address the nonlinearity of the problem by embedding it into a higher-dimensional space of suitable block-Hankel matrices, where it becomes a low-rank matrix completion problem, even if $\mathbf{A}$ is of full rank. For both a uniform and an adaptive random space-time sampling model, we quantify the recoverability of the transition operator via suitable measures of incoherence of these block-Hankel embedding matrices. For graph transition operators these measures of incoherence depend on the interplay between the dynamics and the graph topology. We develop a suitable non-convex iterative reweighted least squares (IRLS) algorithm, establish its quadratic local convergence, and show that, in optimal scenarios, no more than $\mathcal{O}(rn \log(nT))$ space-time samples are sufficient to ensure accurate recovery of a rank-$r$ operator $\mathbf{A}$ of size $n \times n$. This establishes that spatial samples can be substituted by a comparable number of space-time samples. We provide an efficient implementation of the proposed IRLS algorithm with space complexity of order $O(r n T)$ and per-iteration time complexity linear in $n$. Numerical experiments for transition operators based on several graph models confirm that the theoretical findings accurately track empirical phase transitions, and illustrate the applicability and scalability of the proposed algorithm.
Energy-based Models are Zero-Shot Planners for Compositional Scene Rearrangement
May 06, 2023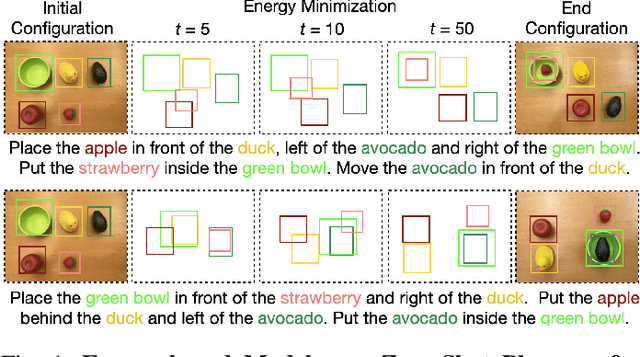
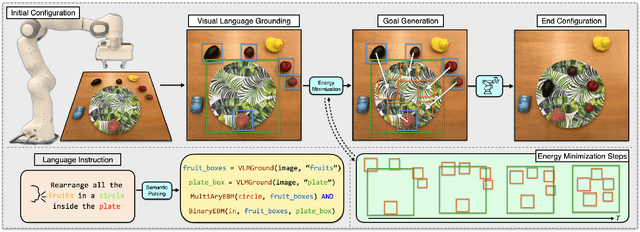


Language is compositional; an instruction can express multiple relation constraints to hold among objects in a scene that a robot is tasked to rearrange. Our focus in this work is an instructable scene-rearranging framework that generalizes to longer instructions and to spatial concept compositions never seen at training time. We propose to represent language-instructed spatial concepts with energy functions over relative object arrangements. A language parser maps instructions to corresponding energy functions and an open-vocabulary visual-language model grounds their arguments to relevant objects in the scene. We generate goal scene configurations by gradient descent on the sum of energy functions, one per language predicate in the instruction. Local vision-based policies then re-locate objects to the inferred goal locations. We test our model on established instruction-guided manipulation benchmarks, as well as benchmarks of compositional instructions we introduce. We show our model can execute highly compositional instructions zero-shot in simulation and in the real world. It outperforms language-to-action reactive policies and Large Language Model planners by a large margin, especially for long instructions that involve compositions of multiple spatial concepts. Simulation and real-world robot execution videos, as well as our code and datasets are publicly available on our website: https://ebmplanner.github.io.
Efficient information recovery from Pauli noise via classical shadow
May 06, 2023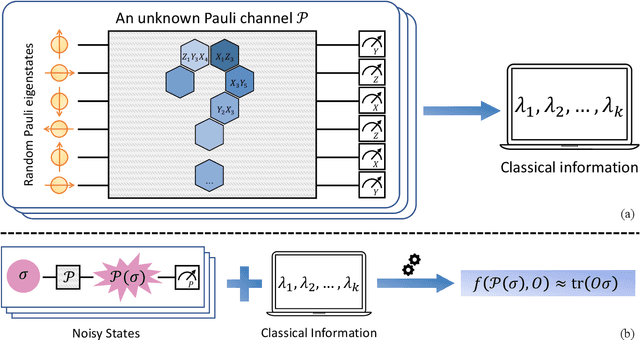
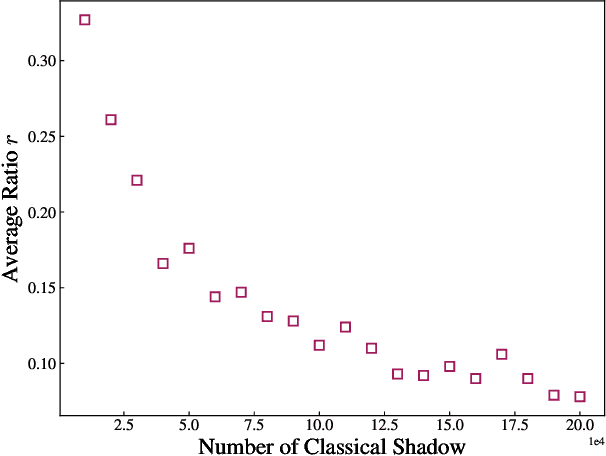
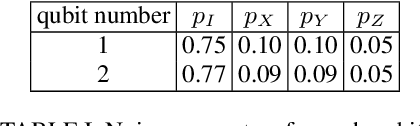
The rapid advancement of quantum computing has led to an extensive demand for effective techniques to extract classical information from quantum systems, particularly in fields like quantum machine learning and quantum chemistry. However, quantum systems are inherently susceptible to noises, which adversely corrupt the information encoded in quantum systems. In this work, we introduce an efficient algorithm that can recover information from quantum states under Pauli noise. The core idea is to learn the necessary information of the unknown Pauli channel by post-processing the classical shadows of the channel. For a local and bounded-degree observable, only partial knowledge of the channel is required rather than its complete classical description to recover the ideal information, resulting in a polynomial-time algorithm. This contrasts with conventional methods such as probabilistic error cancellation, which requires the full information of the channel and exhibits exponential scaling with the number of qubits. We also prove that this scalable method is optimal on the sample complexity and generalise the algorithm to the weight contracting channel. Furthermore, we demonstrate the validity of the algorithm on the 1D anisotropic Heisenberg-type model via numerical simulations. As a notable application, our method can be severed as a sample-efficient error mitigation scheme for Clifford circuits.
Prak: An automatic phonetic alignment tool for Czech
Apr 17, 2023
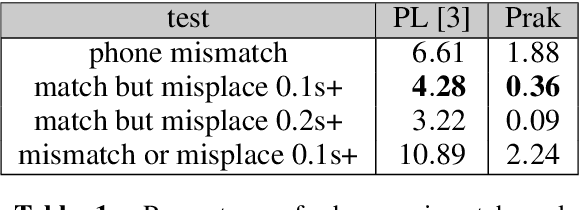

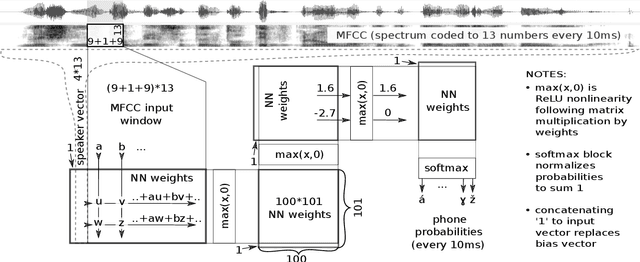
Labeling speech down to the identity and time boundaries of phones is a labor-intensive part of phonetic research. To simplify this work, we created a free open-source tool generating phone sequences from Czech text and time-aligning them with audio. Low architecture complexity makes the design approachable for students of phonetics. Acoustic model ReLU NN with 56k weights was trained using PyTorch on small CommonVoice data. Alignment and variant selection decoder is implemented in Python with matrix library. A Czech pronunciation generator is composed of simple rule-based blocks capturing the logic of the language where possible, allowing modification of transcription approach details. Compared to tools used until now, data preparation efficiency improved, the tool is usable on Mac, Linux and Windows in Praat GUI or command line, achieves mostly correct pronunciation variant choice including glottal stop detection, algorithmically captures most of Czech assimilation logic and is both didactic and practical.
A study on a Q-Learning algorithm application to a manufacturing assembly problem
Apr 17, 2023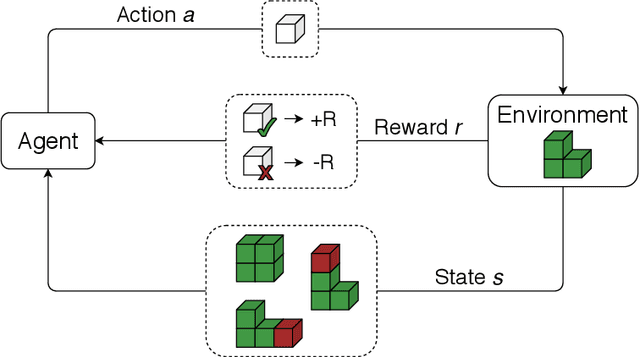


The development of machine learning algorithms has been gathering relevance to address the increasing modelling complexity of manufacturing decision-making problems. Reinforcement learning is a methodology with great potential due to the reduced need for previous training data, i.e., the system learns along time with actual operation. This study focuses on the implementation of a reinforcement learning algorithm in an assembly problem of a given object, aiming to identify the effectiveness of the proposed approach in the optimisation of the assembly process time. A model-free Q-Learning algorithm is applied, considering the learning of a matrix of Q-values (Q-table) from the successive interactions with the environment to suggest an assembly sequence solution. This implementation explores three scenarios with increasing complexity so that the impact of the Q-Learning\textsc's parameters and rewards is assessed to improve the reinforcement learning agent performance. The optimisation approach achieved very promising results by learning the optimal assembly sequence 98.3% of the times.
Generative Disco: Text-to-Video Generation for Music Visualization
Apr 17, 2023



Visuals are a core part of our experience of music, owing to the way they can amplify the emotions and messages conveyed through the music. However, creating music visualization is a complex, time-consuming, and resource-intensive process. We introduce Generative Disco, a generative AI system that helps generate music visualizations with large language models and text-to-image models. Users select intervals of music to visualize and then parameterize that visualization by defining start and end prompts. These prompts are warped between and generated according to the beat of the music for audioreactive video. We introduce design patterns for improving generated videos: "transitions", which express shifts in color, time, subject, or style, and "holds", which encourage visual emphasis and consistency. A study with professionals showed that the system was enjoyable, easy to explore, and highly expressive. We conclude on use cases of Generative Disco for professionals and how AI-generated content is changing the landscape of creative work.
A polynomial time iterative algorithm for matching Gaussian matrices with non-vanishing correlation
Dec 28, 2022Motivated by the problem of matching vertices in two correlated Erd\H{o}s-R\'enyi graphs, we study the problem of matching two correlated Gaussian Wigner matrices. We propose an iterative matching algorithm, which succeeds in polynomial time as long as the correlation between the two Gaussian matrices does not vanish. Our result is the first polynomial time algorithm that solves a graph matching type of problem when the correlation is an arbitrarily small constant.
Bi-Mapper: Holistic BEV Semantic Mapping for Autonomous Driving
May 07, 2023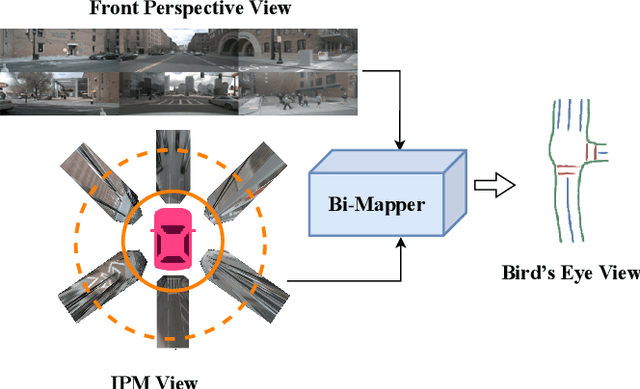
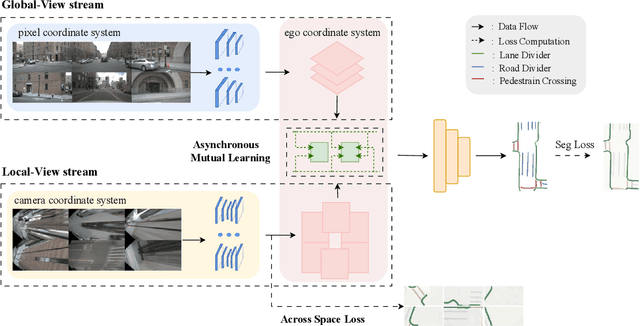
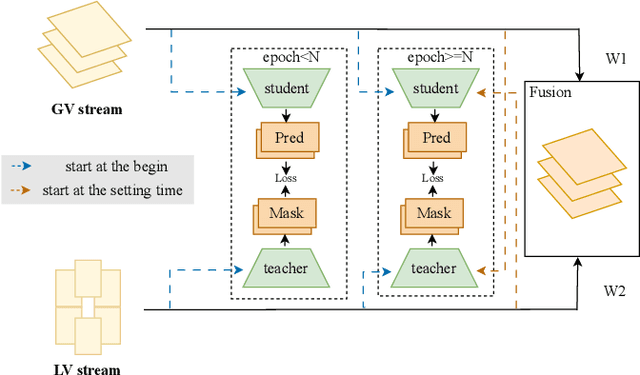
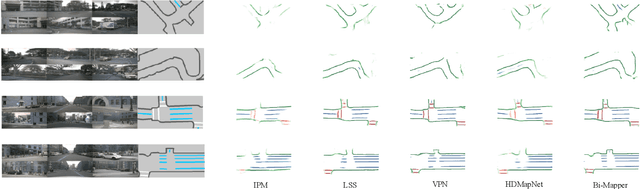
A semantic map of the road scene, covering fundamental road elements, is an essential ingredient in autonomous driving systems. It provides important perception foundations for positioning and planning when rendered in the Bird's-Eye-View (BEV). Currently, the prior knowledge of hypothetical depth can guide the learning of translating front perspective views into BEV directly with the help of calibration parameters. However, it suffers from geometric distortions in the representation of distant objects. In addition, another stream of methods without prior knowledge can learn the transformation between front perspective views and BEV implicitly with a global view. Considering that the fusion of different learning methods may bring surprising beneficial effects, we propose a Bi-Mapper framework for top-down road-scene semantic understanding, which incorporates a global view and local prior knowledge. To enhance reliable interaction between them, an asynchronous mutual learning strategy is proposed. At the same time, an Across-Space Loss (ASL) is designed to mitigate the negative impact of geometric distortions. Extensive results on nuScenes and Cam2BEV datasets verify the consistent effectiveness of each module in the proposed Bi-Mapper framework. Compared with exiting road mapping networks, the proposed Bi-Mapper achieves 5.0 higher IoU on the nuScenes dataset. Moreover, we verify the generalization performance of Bi-Mapper in a real-world driving scenario. Code will be available at https://github.com/lynn-yu/Bi-Mapper.