 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
IFedRec: Item-Guided Federated Aggregation for Cold-Start
May 22, 2023
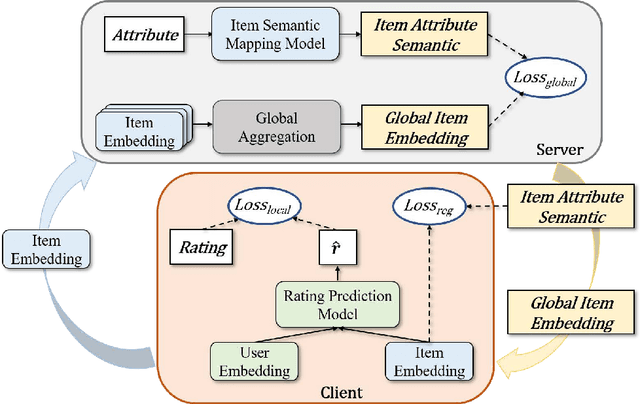

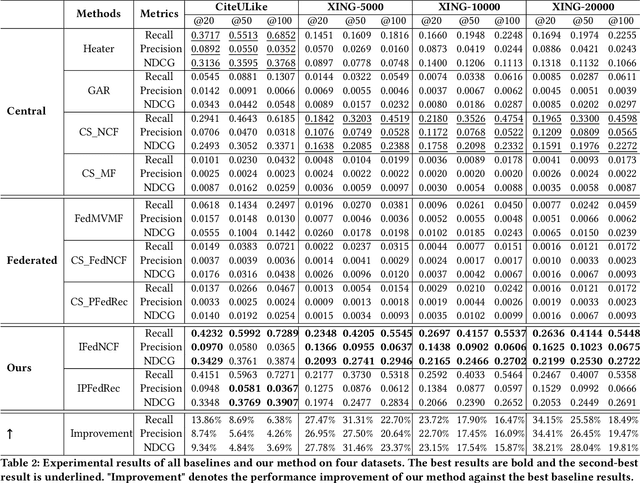
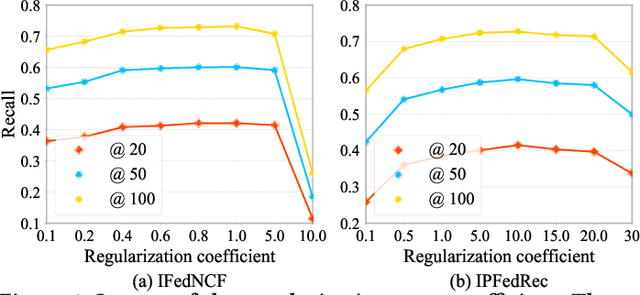
Federated recommendation system is a recently emerging architecture, which provides recommendation services without exposing users' private data. Existing methods are mainly designed to recommend items already existing in the system. In practical scenarios, the system continuously introduces new items and recommends them to users, i.e., cold-start recommendation. To recommend cold items, existing federated recommendation models require collecting new interactions from users and retraining the model, which is time-consuming and poses a privacy threat to users' sensitive information. This paper presents a novel Item-guided Federated aggregation for cold-start Recommendation (IFedRec) framework. The IFedRec exchanges the item embedding to learn the common item preference semantic and preserves other model parameters locally to capture user personalization. Besides, it deploys a meta attribute network on the server to learn the item feature semantic, and a semantic alignment mechanism is presented to align both kinds of item semantic. When the new items arrive, each client can make recommendations with item feature semantic learned from the meta attribute network by incorporating the locally personalized model without retraining. Experiments on four benchmark datasets demonstrate IFedRec's outstanding performance for cold-start recommendation. Besides, in-depth analysis verifies IFedRec's learning ability for cold items while protecting user's privacy.
Enhancing Short-Term Wind Speed Forecasting using Graph Attention and Frequency-Enhanced Mechanisms
May 22, 2023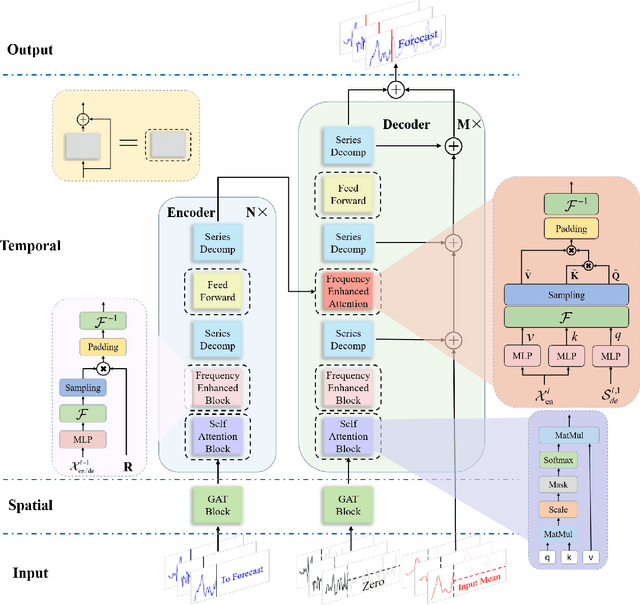
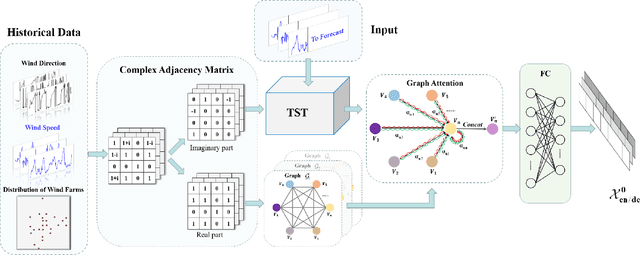
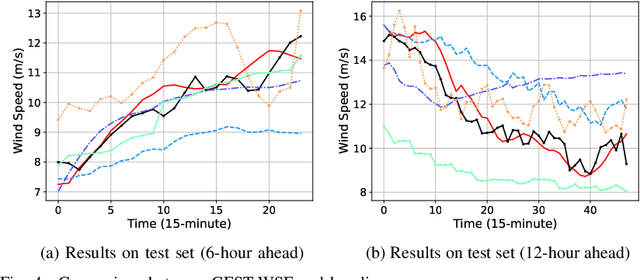
The safe and stable operation of power systems is greatly challenged by the high variability and randomness of wind power in large-scale wind-power-integrated grids. Wind power forecasting is an effective solution to tackle this issue, with wind speed forecasting being an essential aspect. In this paper, a Graph-attentive Frequency-enhanced Spatial-Temporal Wind Speed Forecasting model based on graph attention and frequency-enhanced mechanisms, i.e., GFST-WSF, is proposed to improve the accuracy of short-term wind speed forecasting. The GFST-WSF comprises a Transformer architecture for temporal feature extraction and a Graph Attention Network (GAT) for spatial feature extraction. The GAT is specifically designed to capture the complex spatial dependencies among wind speed stations to effectively aggregate information from neighboring nodes in the graph, thus enhancing the spatial representation of the data. To model the time lag in wind speed correlation between adjacent wind farms caused by geographical factors, a dynamic complex adjacency matrix is formulated and utilized by the GAT. Benefiting from the effective spatio-temporal feature extraction and the deep architecture of the Transformer, the GFST-WSF outperforms other baselines in wind speed forecasting for the 6-24 hours ahead forecast horizon in case studies.
Towards Benchmarking and Assessing Visual Naturalness of Physical World Adversarial Attacks
May 22, 2023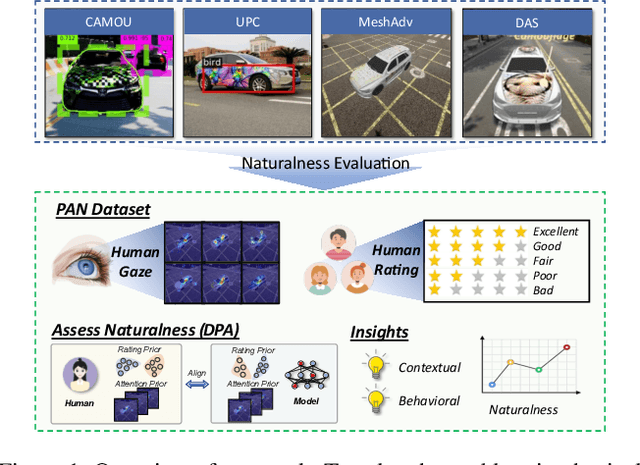
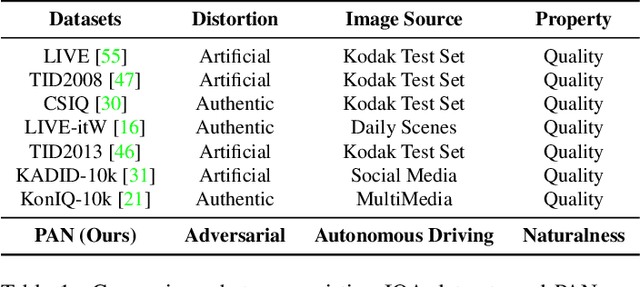
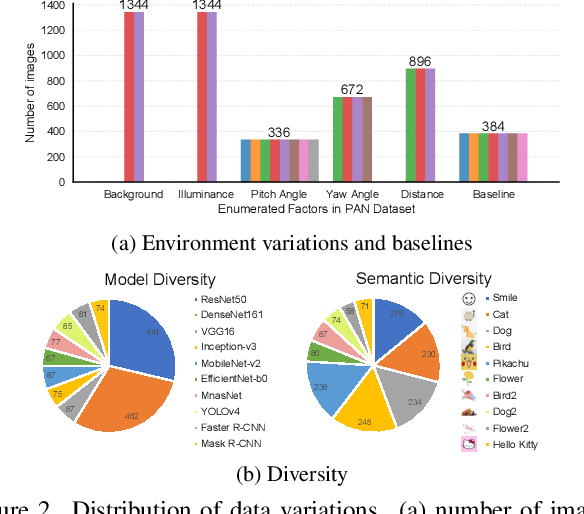
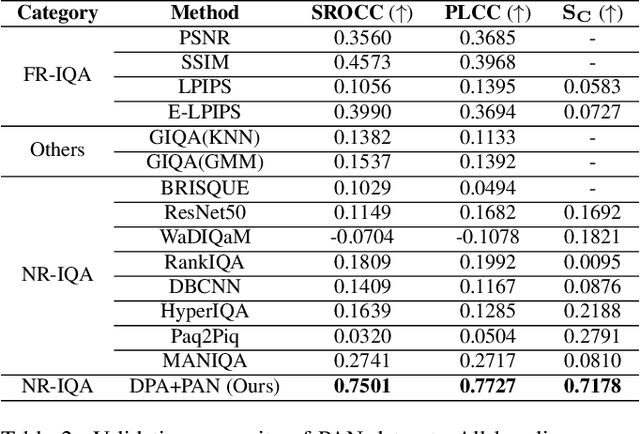
Physical world adversarial attack is a highly practical and threatening attack, which fools real world deep learning systems by generating conspicuous and maliciously crafted real world artifacts. In physical world attacks, evaluating naturalness is highly emphasized since human can easily detect and remove unnatural attacks. However, current studies evaluate naturalness in a case-by-case fashion, which suffers from errors, bias and inconsistencies. In this paper, we take the first step to benchmark and assess visual naturalness of physical world attacks, taking autonomous driving scenario as the first attempt. First, to benchmark attack naturalness, we contribute the first Physical Attack Naturalness (PAN) dataset with human rating and gaze. PAN verifies several insights for the first time: naturalness is (disparately) affected by contextual features (i.e., environmental and semantic variations) and correlates with behavioral feature (i.e., gaze signal). Second, to automatically assess attack naturalness that aligns with human ratings, we further introduce Dual Prior Alignment (DPA) network, which aims to embed human knowledge into model reasoning process. Specifically, DPA imitates human reasoning in naturalness assessment by rating prior alignment and mimics human gaze behavior by attentive prior alignment. We hope our work fosters researches to improve and automatically assess naturalness of physical world attacks. Our code and dataset can be found at https://github.com/zhangsn-19/PAN.
READMem: Robust Embedding Association for a Diverse Memory in Unconstrained Video Object Segmentation
May 22, 2023
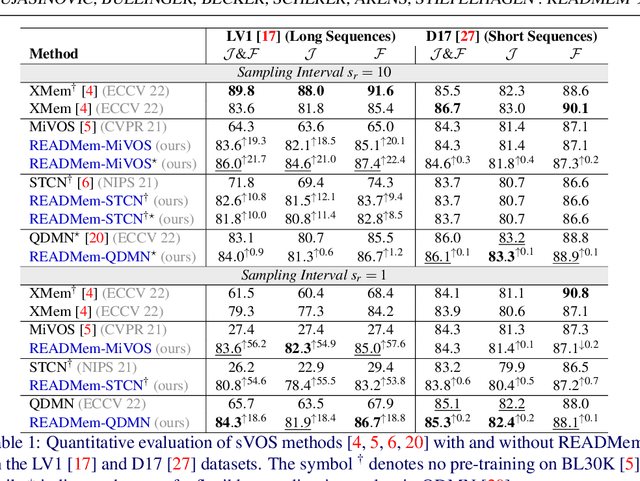
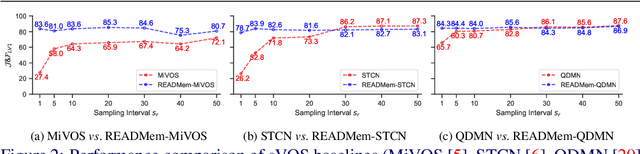

We present READMem (Robust Embedding Association for a Diverse Memory), a modular framework for semi-automatic video object segmentation (sVOS) methods designed to handle unconstrained videos. Contemporary sVOS works typically aggregate video frames in an ever-expanding memory, demanding high hardware resources for long-term applications. To mitigate memory requirements and prevent near object duplicates (caused by information of adjacent frames), previous methods introduce a hyper-parameter that controls the frequency of frames eligible to be stored. This parameter has to be adjusted according to concrete video properties (such as rapidity of appearance changes and video length) and does not generalize well. Instead, we integrate the embedding of a new frame into the memory only if it increases the diversity of the memory content. Furthermore, we propose a robust association of the embeddings stored in the memory with query embeddings during the update process. Our approach avoids the accumulation of redundant data, allowing us in return, to restrict the memory size and prevent extreme memory demands in long videos. We extend popular sVOS baselines with READMem, which previously showed limited performance on long videos. Our approach achieves competitive results on the Long-time Video dataset (LV1) while not hindering performance on short sequences. Our code is publicly available.
Bio-inspired spike-based Hippocampus and Posterior Parietal Cortex models for robot navigation and environment pseudo-mapping
May 22, 2023
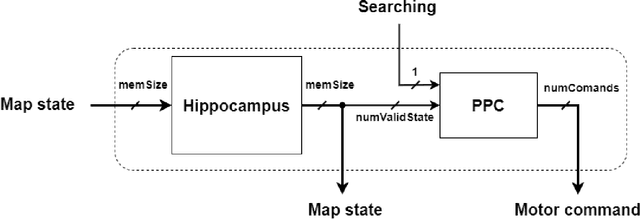
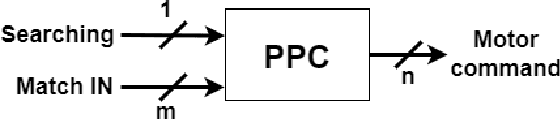
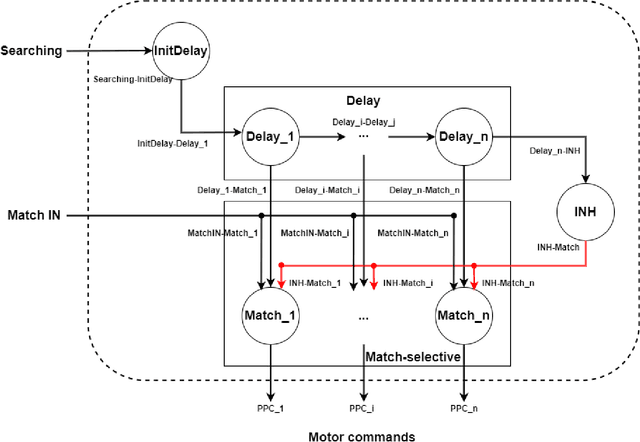
The brain has a great capacity for computation and efficient resolution of complex problems, far surpassing modern computers. Neuromorphic engineering seeks to mimic the basic principles of the brain to develop systems capable of achieving such capabilities. In the neuromorphic field, navigation systems are of great interest due to their potential applicability to robotics, although these systems are still a challenge to be solved. This work proposes a spike-based robotic navigation and environment pseudomapping system formed by a bio-inspired hippocampal memory model connected to a Posterior Parietal Cortex model. The hippocampus is in charge of maintaining a representation of an environment state map, and the PPC is in charge of local decision-making. This system was implemented on the SpiNNaker hardware platform using Spiking Neural Networks. A set of real-time experiments was applied to demonstrate the correct functioning of the system in virtual and physical environments on a robotic platform. The system is able to navigate through the environment to reach a goal position starting from an initial position, avoiding obstacles and mapping the environment. To the best of the authors knowledge, this is the first implementation of an environment pseudo-mapping system with dynamic learning based on a bio-inspired hippocampal memory.
Enhancing Next Active Object-based Egocentric Action Anticipation with Guided Attention
May 22, 2023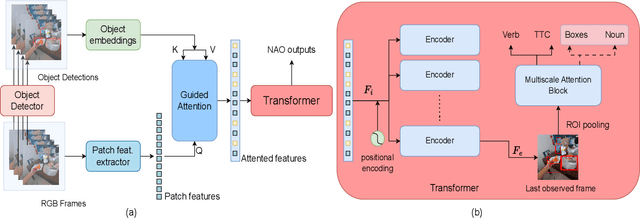
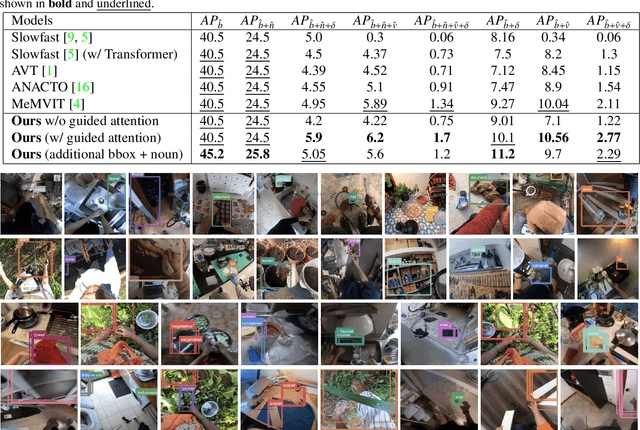
Short-term action anticipation (STA) in first-person videos is a challenging task that involves understanding the next active object interactions and predicting future actions. Existing action anticipation methods have primarily focused on utilizing features extracted from video clips, but often overlooked the importance of objects and their interactions. To this end, we propose a novel approach that applies a guided attention mechanism between the objects, and the spatiotemporal features extracted from video clips, enhancing the motion and contextual information, and further decoding the object-centric and motion-centric information to address the problem of STA in egocentric videos. Our method, GANO (Guided Attention for Next active Objects) is a multi-modal, end-to-end, single transformer-based network. The experimental results performed on the largest egocentric dataset demonstrate that GANO outperforms the existing state-of-the-art methods for the prediction of the next active object label, its bounding box location, the corresponding future action, and the time to contact the object. The ablation study shows the positive contribution of the guided attention mechanism compared to other fusion methods. Moreover, it is possible to improve the next active object location and class label prediction results of GANO by just appending the learnable object tokens with the region of interest embeddings.
An Investigation into the Effects of Pre-training Data Distributions for Pathology Report Classification
May 27, 2023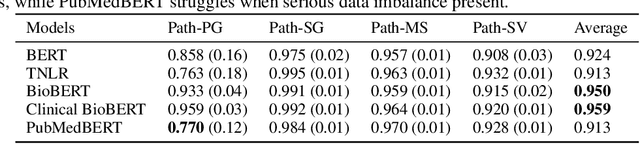
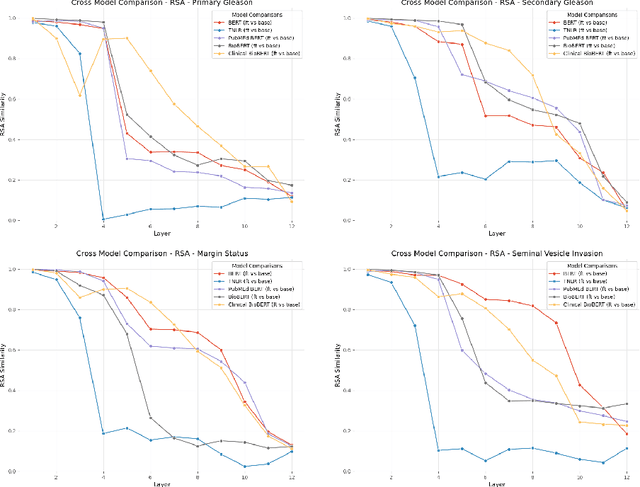
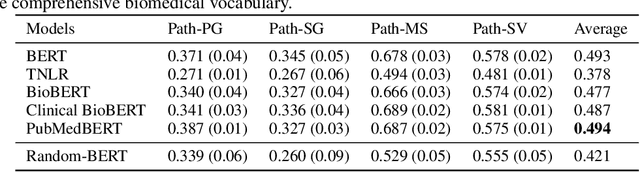
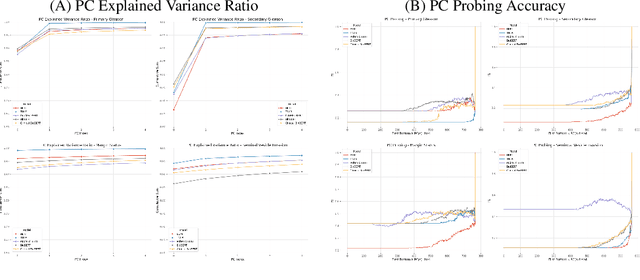
Pre-trained transformer models have demonstrated success across many natural language processing (NLP) tasks. In applying these models to the clinical domain, a prevailing assumption is that pre-training language models from scratch on large-scale biomedical data results in substantial improvements. We test this assumption with 4 pathology classification tasks on a corpus of 2907 prostate cancer pathology reports. We evaluate 5 transformer pre-trained models that are the same size but differ in pre-training corpora. Specifically, we analyze 3 categories of models: 1)General-domain: BERT and Turing Natural Language Representation (TNLR) models, which use general corpora for pre-training, 2)Mixed-domain: BioBERT which is obtained from BERT by including PubMed abstracts in pre-training and Clinical BioBERT which additionally includes MIMIC-III clinical notes and 3)Domain-specific: PubMedBERT which is pre-trained from scratch on PubMed abstracts. We find the mixed-domain and domain-specific models exhibit faster feature disambiguation during fine-tuning. However, the domain-specific model, PubMedBERT, can overfit to minority classes when presented with class imbalance, a common scenario in pathology report data. At the same time, the mixed-domain models are more resistant to overfitting. Our findings indicate that the use of general natural language and domain-specific corpora in pre-training serve complementary purposes for pathology report classification. The first enables resistance to overfitting when fine-tuning on an imbalanced dataset while the second allows for more accurate modelling of the fine-tuning domain. An expert evaluation is also conducted to reveal common outlier modes of each model. Our results could inform better fine-tuning practices in the clinical domain, to possibly leverage the benefits of mixed-domain models for imbalanced downstream datasets.
Fully Automatic Gym Exercises Recording: An IoT Solution
May 27, 2023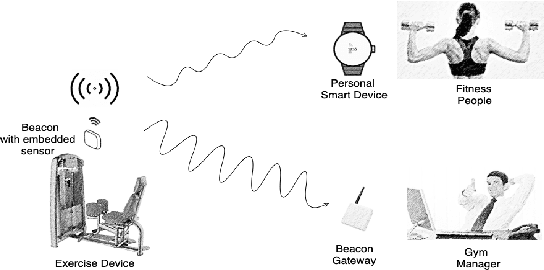
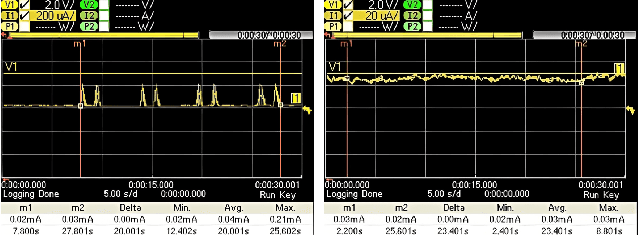
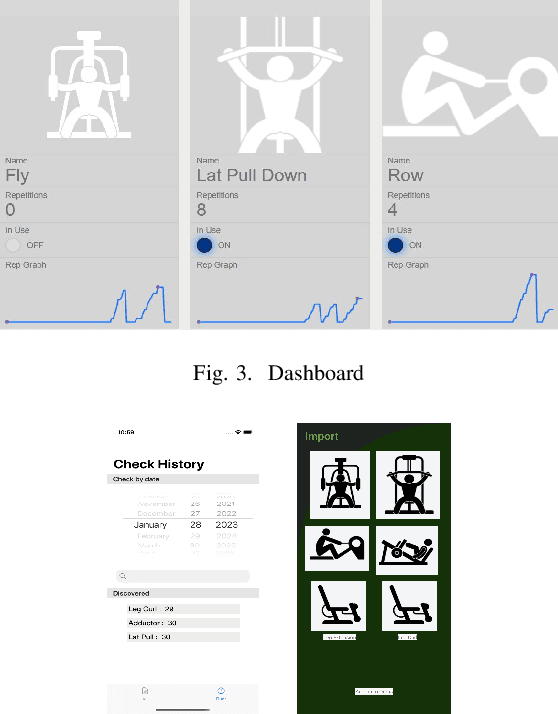
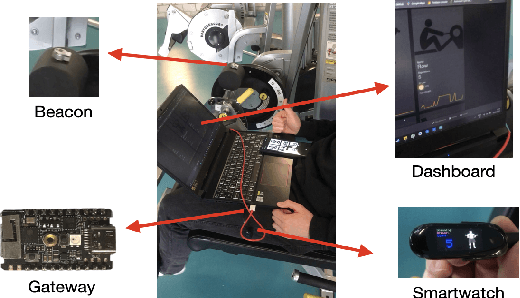
In recent years, working out in the gym has gotten increasingly more data-focused and many gym enthusiasts are recording their exercises to have a better overview of their historical gym activities and to make a better exercise plan for the future. As a side effect, this recording process has led to a lot of time spent painstakingly operating these apps by plugging in used types of equipment and repetitions. This project aims to automate this process using an Internet of Things (IoT) approach. Specifically, beacons with embedded ultra-low-power inertial measurement units (IMUs) are attached to the types of equipment to recognize the usage and transmit the information to gym-goers and managers. We have created a small ecosystem composed of beacons, a gateway, smartwatches, android/iPhone applications, a firebase cloud server, and a dashboard, all communicating over a mixture of Bluetooth and Wifi to distribute collected data from machines to users and gym managers in a compact and meaningful way. The system we have implemented is a working prototype of a bigger end goal and is supposed to initialize progress toward a smarter, more efficient, and still privacy-respect gym environment in the future. A small-scale real-life test shows 94.6\% accuracy in user gym session recording, which can reach up to 100\% easily with a more suitable assembling of the beacons. This promising result shows the potential of a fully automatic exercise recording system, which enables comprehensive monitoring and analysis of the exercise sessions and frees the user from manual recording. The estimated battery life of the beacon is 400 days with a 210 mAh coin battery. We also discussed the shortcoming of the current demonstration system and the future work for a reliable and ready-to-deploy automatic gym workout recording system.
XRoute Environment: A Novel Reinforcement Learning Environment for Routing
May 23, 2023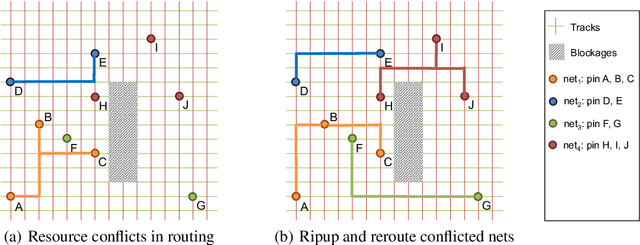
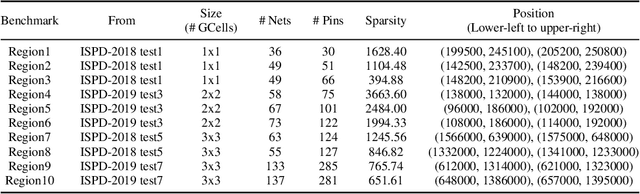
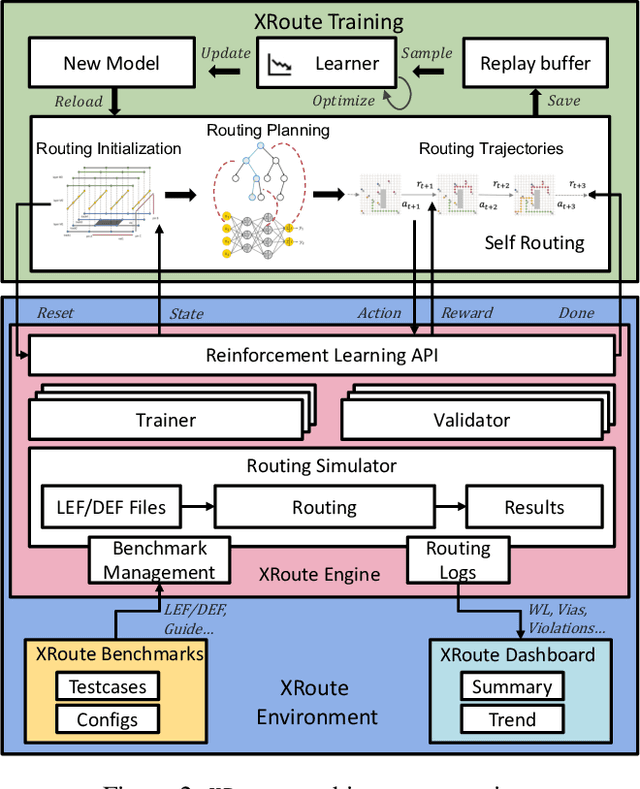
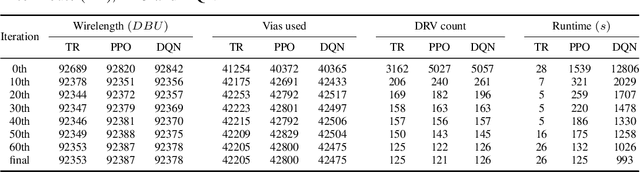
Routing is a crucial and time-consuming stage in modern design automation flow for advanced technology nodes. Great progress in the field of reinforcement learning makes it possible to use those approaches to improve the routing quality and efficiency. However, the scale of the routing problems solved by reinforcement learning-based methods in recent studies is too small for these methods to be used in commercial EDA tools. We introduce the XRoute Environment, a new reinforcement learning environment where agents are trained to select and route nets in an advanced, end-to-end routing framework. Novel algorithms and ideas can be quickly tested in a safe and reproducible manner in it. The resulting environment is challenging, easy to use, customize and add additional scenarios, and it is available under a permissive open-source license. In addition, it provides support for distributed deployment and multi-instance experiments. We propose two tasks for learning and build a full-chip test bed with routing benchmarks of various region sizes. We also pre-define several static routing regions with different pin density and number of nets for easier learning and testing. For net ordering task, we report baseline results for two widely used reinforcement learning algorithms (PPO and DQN) and one searching-based algorithm (TritonRoute). The XRoute Environment will be available at https://github.com/xplanlab/xroute_env.
WikiChat: A Few-Shot LLM-Based Chatbot Grounded with Wikipedia
May 23, 2023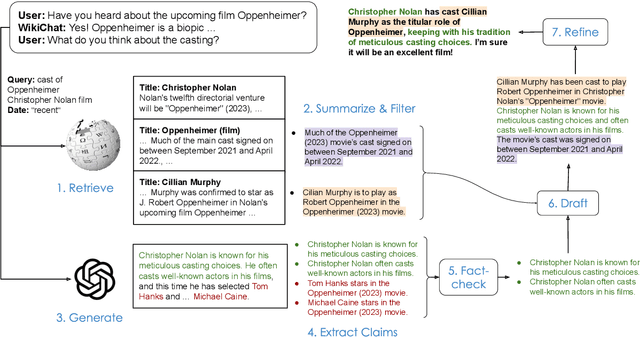
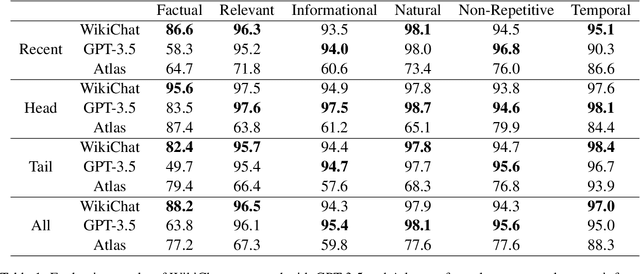


Despite recent advances in Large Language Models (LLMs), users still cannot trust the information provided in their responses. LLMs cannot speak accurately about events that occurred after their training, which are often topics of great interest to users, and, as we show in this paper, they are highly prone to hallucination when talking about less popular (tail) topics. This paper presents WikiChat, a few-shot LLM-based chatbot that is grounded with live information from Wikipedia. Through many iterations of experimentation, we have crafte a pipeline based on information retrieval that (1) uses LLMs to suggest interesting and relevant facts that are individually verified against Wikipedia, (2) retrieves additional up-to-date information, and (3) composes coherent and engaging time-aware responses. We propose a novel hybrid human-and-LLM evaluation methodology to analyze the factuality and conversationality of LLM-based chatbots. We focus on evaluating important but previously neglected issues such as conversing about recent and tail topics. We evaluate WikiChat against strong fine-tuned and LLM-based baselines across a diverse set of conversation topics. We find that WikiChat outperforms all baselines in terms of the factual accuracy of its claims, by up to 12.1%, 28.3% and 32.7% on head, recent and tail topics, while matching GPT-3.5 in terms of providing natural, relevant, non-repetitive and informational responses.