 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generating Images with Multimodal Language Models
May 26, 2023
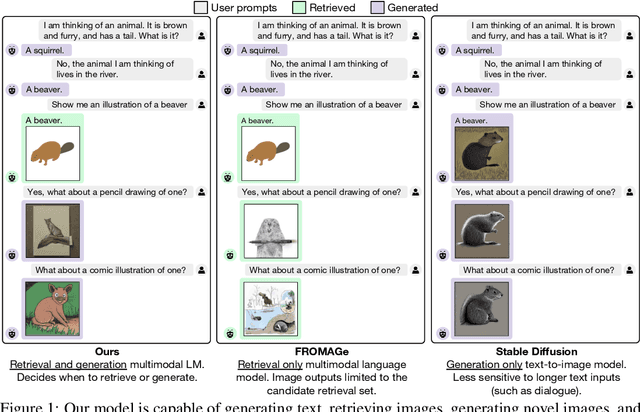
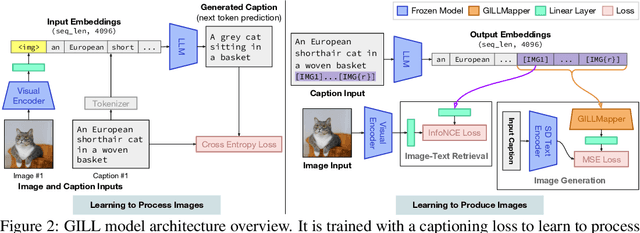

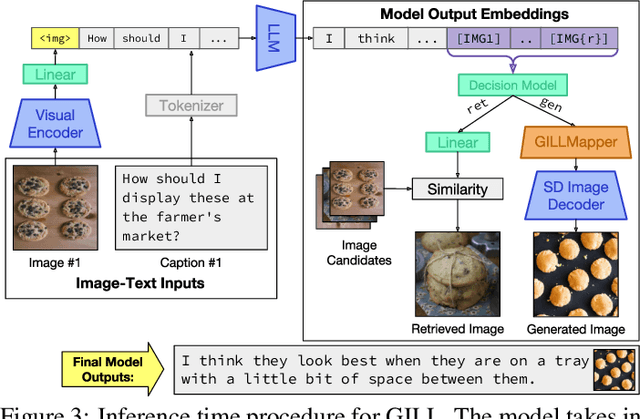
We propose a method to fuse frozen text-only large language models (LLMs) with pre-trained image encoder and decoder models, by mapping between their embedding spaces. Our model demonstrates a wide suite of multimodal capabilities: image retrieval, novel image generation, and multimodal dialogue. Ours is the first approach capable of conditioning on arbitrarily interleaved image and text inputs to generate coherent image (and text) outputs. To achieve strong performance on image generation, we propose an efficient mapping network to ground the LLM to an off-the-shelf text-to-image generation model. This mapping network translates hidden representations of text into the embedding space of the visual models, enabling us to leverage the strong text representations of the LLM for visual outputs. Our approach outperforms baseline generation models on tasks with longer and more complex language. In addition to novel image generation, our model is also capable of image retrieval from a prespecified dataset, and decides whether to retrieve or generate at inference time. This is done with a learnt decision module which conditions on the hidden representations of the LLM. Our model exhibits a wider range of capabilities compared to prior multimodal language models. It can process image-and-text inputs, and produce retrieved images, generated images, and generated text -- outperforming non-LLM based generation models across several text-to-image tasks that measure context dependence.
Bandit Submodular Maximization for Multi-Robot Coordination in Unpredictable and Partially Observable Environments
May 26, 2023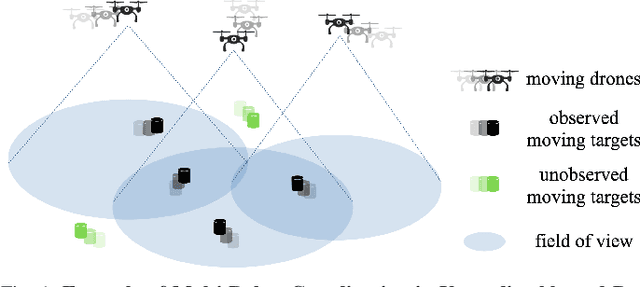
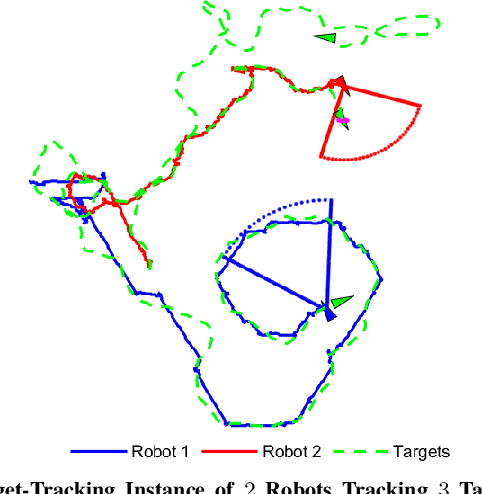
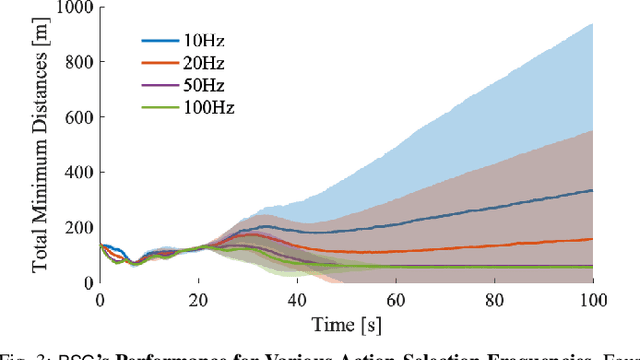
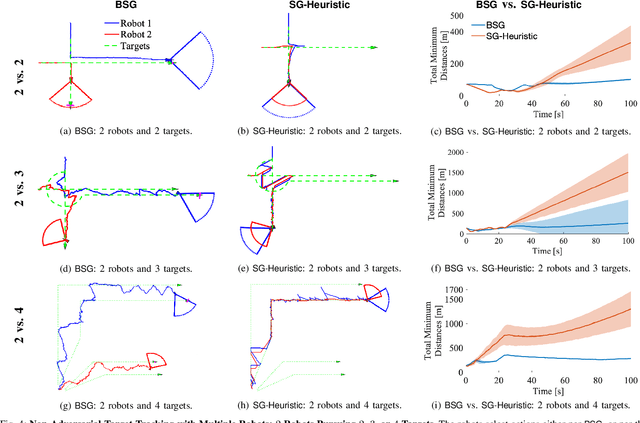
We study the problem of multi-agent coordination in unpredictable and partially observable environments, that is, environments whose future evolution is unknown a priori and that can only be partially observed. We are motivated by the future of autonomy that involves multiple robots coordinating actions in dynamic, unstructured, and partially observable environments to complete complex tasks such as target tracking, environmental mapping, and area monitoring. Such tasks are often modeled as submodular maximization coordination problems due to the information overlap among the robots. We introduce the first submodular coordination algorithm with bandit feedback and bounded tracking regret -- bandit feedback is the robots' ability to compute in hindsight only the effect of their chosen actions, instead of all the alternative actions that they could have chosen instead, due to the partial observability; and tracking regret is the algorithm's suboptimality with respect to the optimal time-varying actions that fully know the future a priori. The bound gracefully degrades with the environments' capacity to change adversarially, quantifying how often the robots should re-select actions to learn to coordinate as if they fully knew the future a priori. The algorithm generalizes the seminal Sequential Greedy algorithm by Fisher et al. to the bandit setting, by leveraging submodularity and algorithms for the problem of tracking the best action. We validate our algorithm in simulated scenarios of multi-target tracking.
CVB: A Video Dataset of Cattle Visual Behaviors
May 26, 2023

Existing image/video datasets for cattle behavior recognition are mostly small, lack well-defined labels, or are collected in unrealistic controlled environments. This limits the utility of machine learning (ML) models learned from them. Therefore, we introduce a new dataset, called Cattle Visual Behaviors (CVB), that consists of 502 video clips, each fifteen seconds long, captured in natural lighting conditions, and annotated with eleven visually perceptible behaviors of grazing cattle. We use the Computer Vision Annotation Tool (CVAT) to collect our annotations. To make the procedure more efficient, we perform an initial detection and tracking of cattle in the videos using appropriate pre-trained models. The results are corrected by domain experts along with cattle behavior labeling in CVAT. The pre-hoc detection and tracking step significantly reduces the manual annotation time and effort. Moreover, we convert CVB to the atomic visual action (AVA) format and train and evaluate the popular SlowFast action recognition model on it. The associated preliminary results confirm that we can localize the cattle and recognize their frequently occurring behaviors with confidence. By creating and sharing CVB, our aim is to develop improved models capable of recognizing all important behaviors accurately and to assist other researchers and practitioners in developing and evaluating new ML models for cattle behavior classification using video data.
Fast refacing of MR images with a generative neural network lowers re-identification risk and preserves volumetric consistency
May 26, 2023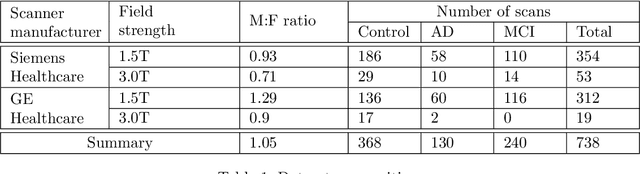
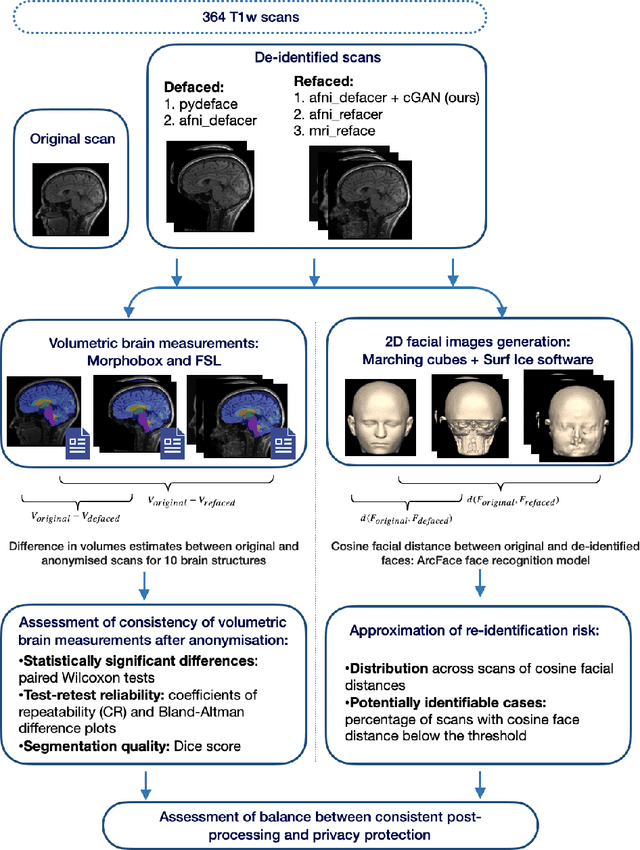
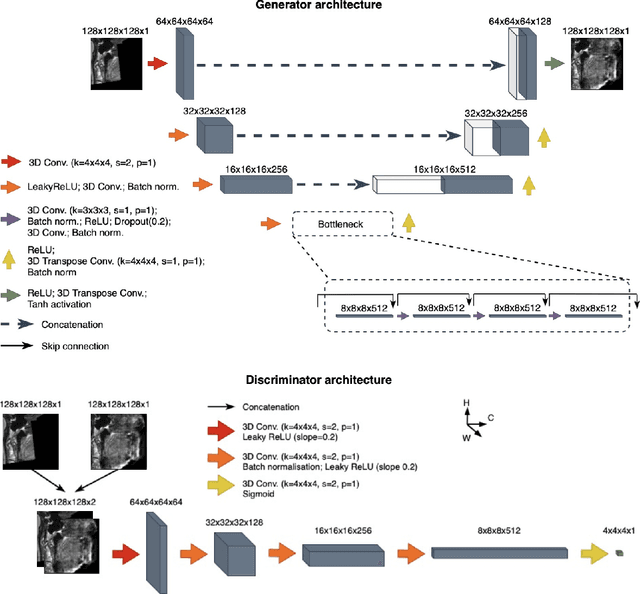

With the rise of open data, identifiability of individuals based on 3D renderings obtained from routine structural magnetic resonance imaging (MRI) scans of the head has become a growing privacy concern. To protect subject privacy, several algorithms have been developed to de-identify imaging data using blurring, defacing or refacing. Completely removing facial structures provides the best re-identification protection but can significantly impact post-processing steps, like brain morphometry. As an alternative, refacing methods that replace individual facial structures with generic templates have a lower effect on the geometry and intensity distribution of original scans, and are able to provide more consistent post-processing results by the price of higher re-identification risk and computational complexity. In the current study, we propose a novel method for anonymised face generation for defaced 3D T1-weighted scans based on a 3D conditional generative adversarial network. To evaluate the performance of the proposed de-identification tool, a comparative study was conducted between several existing defacing and refacing tools, with two different segmentation algorithms (FAST and Morphobox). The aim was to evaluate (i) impact on brain morphometry reproducibility, (ii) re-identification risk, (iii) balance between (i) and (ii), and (iv) the processing time. The proposed method takes 9 seconds for face generation and is suitable for recovering consistent post-processing results after defacing.
A FPGA-based architecture for real-time cluster finding in the LHCb silicon pixel detector
Feb 08, 2023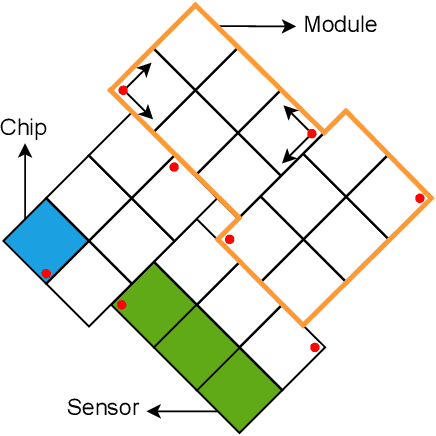
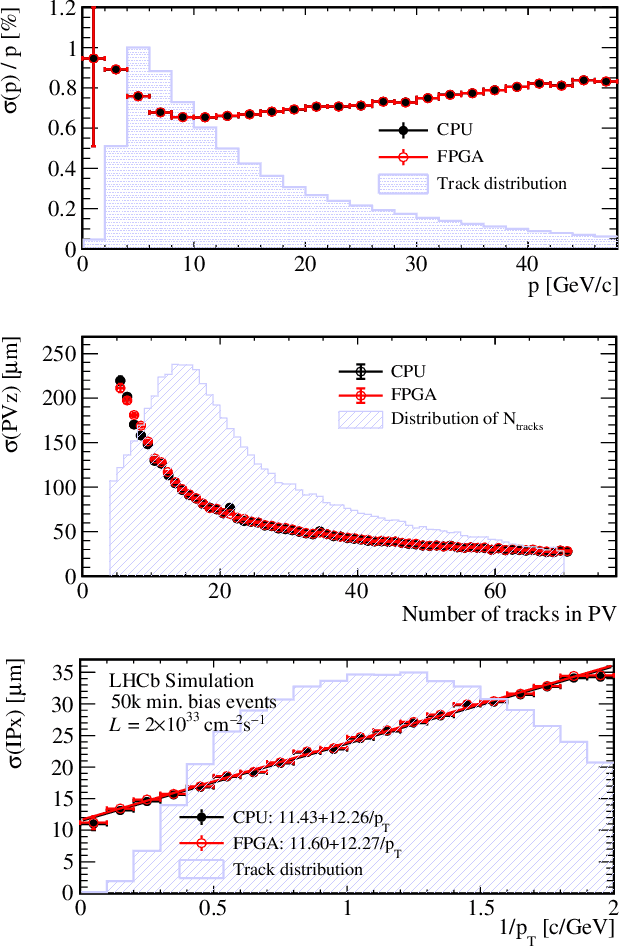
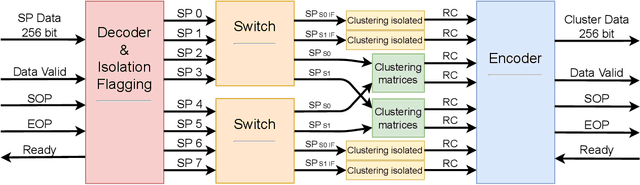

This article describes a custom VHDL firmware implementation of a two-dimensional cluster-finder architecture for reconstructing hit positions in the new vertex pixel detector (VELO) that is part of the LHCb Upgrade. This firmware has been deployed to the existing FPGA cards that perform the readout of the VELO, as a further enhancement of the DAQ system, and will run in real time during physics data taking, reconstructing VELO hits coordinates on-the-fly at the LHC collision rate. This pre-processing allows the first level of the software trigger to accept a 11% higher rate of events, as the ready-made hits coordinates accelerate the track reconstruction and consumes significantly less electrical power. It additionally allows the raw pixel data to be dropped at the readout level, thus saving approximately 14% of the DAQ bandwidth. Detailed simulation studies have shown that the use of this real-time cluster finding does not introduce any appreciable degradation in the tracking performance in comparison to a full-fledged software implementation. This work is part of a wider effort aimed at boosting the real-time processing capability of HEP experiments by delegating intensive tasks to dedicated computing accelerators deployed at the earliest stages of the data acquisition chain.
Moral Machine or Tyranny of the Majority?
May 27, 2023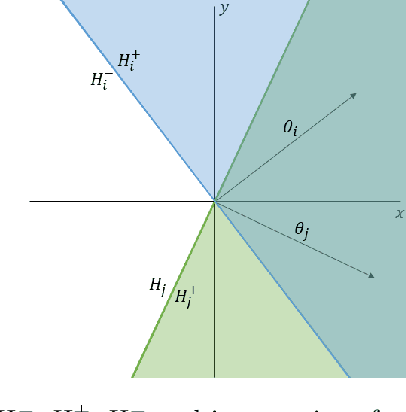
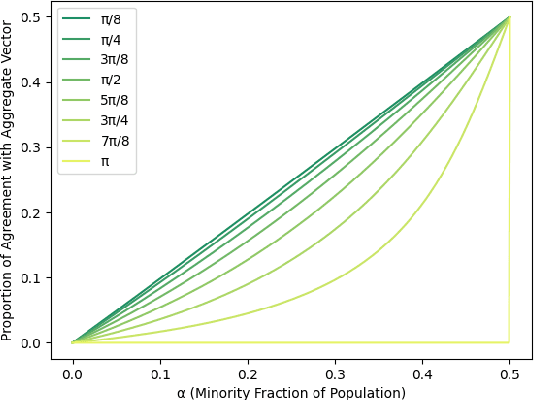
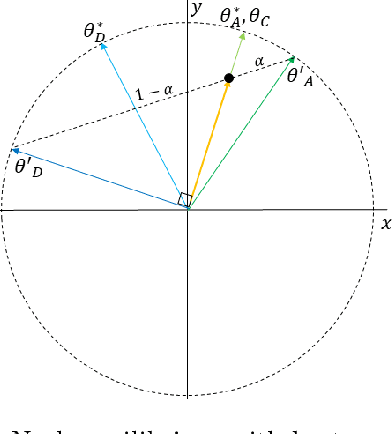
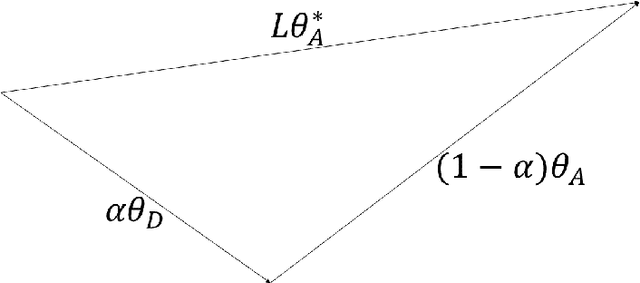
With Artificial Intelligence systems increasingly applied in consequential domains, researchers have begun to ask how these systems ought to act in ethically charged situations where even humans lack consensus. In the Moral Machine project, researchers crowdsourced answers to "Trolley Problems" concerning autonomous vehicles. Subsequently, Noothigattu et al. (2018) proposed inferring linear functions that approximate each individual's preferences and aggregating these linear models by averaging parameters across the population. In this paper, we examine this averaging mechanism, focusing on fairness concerns in the presence of strategic effects. We investigate a simple setting where the population consists of two groups, with the minority constituting an {\alpha} < 0.5 share of the population. To simplify the analysis, we consider the extreme case in which within-group preferences are homogeneous. Focusing on the fraction of contested cases where the minority group prevails, we make the following observations: (a) even when all parties report their preferences truthfully, the fraction of disputes where the minority prevails is less than proportionate in {\alpha}; (b) the degree of sub-proportionality grows more severe as the level of disagreement between the groups increases; (c) when parties report preferences strategically, pure strategy equilibria do not always exist; and (d) whenever a pure strategy equilibrium exists, the majority group prevails 100% of the time. These findings raise concerns about stability and fairness of preference vector averaging as a mechanism for aggregating diverging voices. Finally, we discuss alternatives, including randomized dictatorship and median-based mechanisms.
Reinforcement Learning With Reward Machines in Stochastic Games
May 27, 2023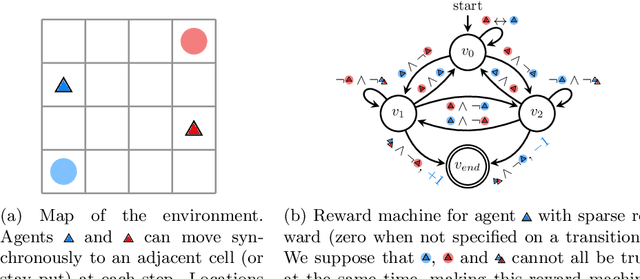
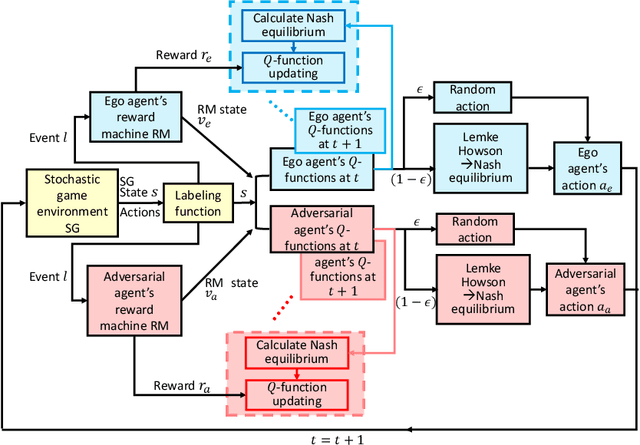
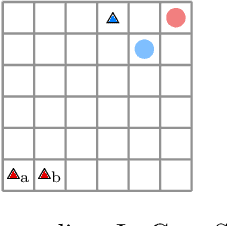
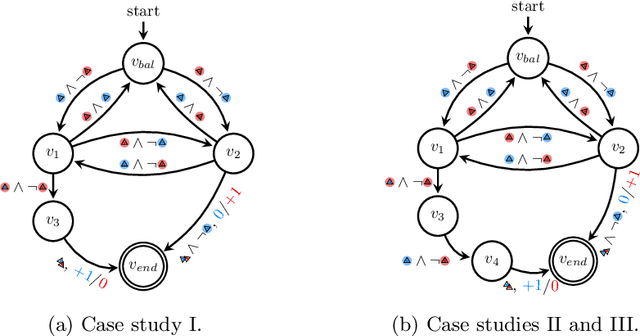
We investigate multi-agent reinforcement learning for stochastic games with complex tasks, where the reward functions are non-Markovian. We utilize reward machines to incorporate high-level knowledge of complex tasks. We develop an algorithm called Q-learning with reward machines for stochastic games (QRM-SG), to learn the best-response strategy at Nash equilibrium for each agent. In QRM-SG, we define the Q-function at a Nash equilibrium in augmented state space. The augmented state space integrates the state of the stochastic game and the state of reward machines. Each agent learns the Q-functions of all agents in the system. We prove that Q-functions learned in QRM-SG converge to the Q-functions at a Nash equilibrium if the stage game at each time step during learning has a global optimum point or a saddle point, and the agents update Q-functions based on the best-response strategy at this point. We use the Lemke-Howson method to derive the best-response strategy given current Q-functions. The three case studies show that QRM-SG can learn the best-response strategies effectively. QRM-SG learns the best-response strategies after around 7500 episodes in Case Study I, 1000 episodes in Case Study II, and 1500 episodes in Case Study III, while baseline methods such as Nash Q-learning and MADDPG fail to converge to the Nash equilibrium in all three case studies.
Rethinking Adversarial Policies: A Generalized Attack Formulation and Provable Defense in Multi-Agent RL
May 27, 2023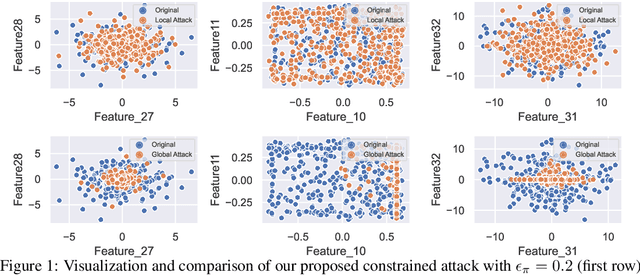
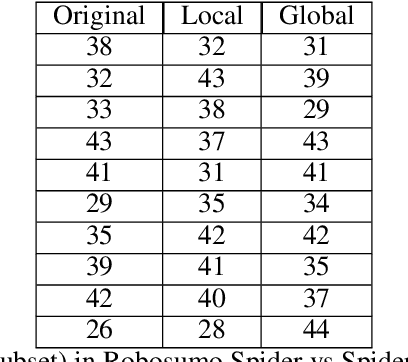
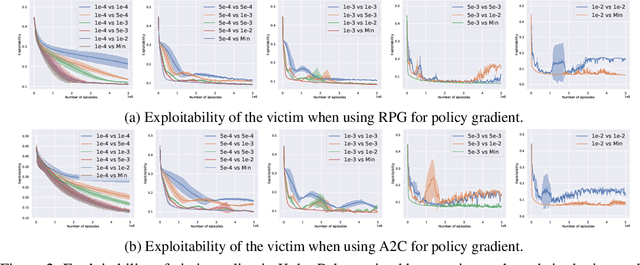
Most existing works consider direct perturbations of victim's state/action or the underlying transition dynamics to show vulnerability of reinforcement learning agents under adversarial attacks. However, such direct manipulation may not always be feasible in practice. In this paper, we consider another common and realistic attack setup: in a multi-agent RL setting with well-trained agents, during deployment time, the victim agent $\nu$ is exploited by an attacker who controls another agent $\alpha$ to act adversarially against the victim using an \textit{adversarial policy}. Prior attack models under such setup do not consider that the attacker can confront resistance and thus can only take partial control of the agent $\alpha$, as well as introducing perceivable ``abnormal'' behaviors that are easily detectable. A provable defense against these adversarial policies is also lacking. To resolve these issues, we introduce a more general attack formulation that models to what extent the adversary is able to control the agent to produce the adversarial policy. Based on such a generalized attack framework, the attacker can also regulate the state distribution shift caused by the attack through an attack budget, and thus produce stealthy adversarial policies that can exploit the victim agent. Furthermore, we provide the first provably robust defenses with convergence guarantee to the most robust victim policy via adversarial training with timescale separation, in sharp contrast to adversarial training in supervised learning which may only provide {\it empirical} defenses.
An Investigation of Evaluation Metrics for Automated Medical Note Generation
May 27, 2023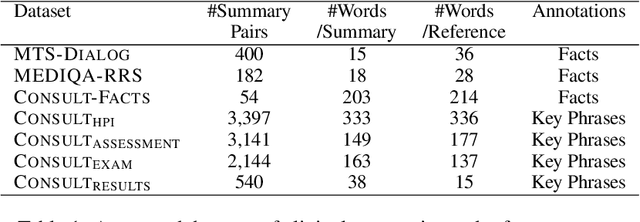
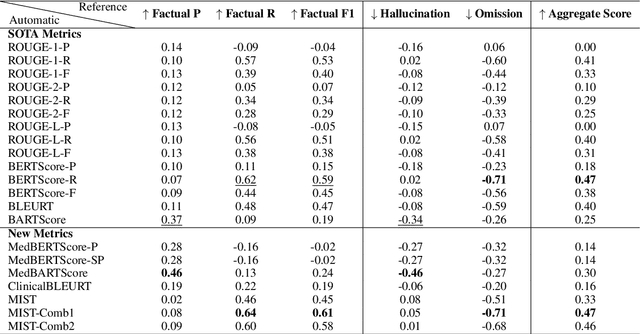
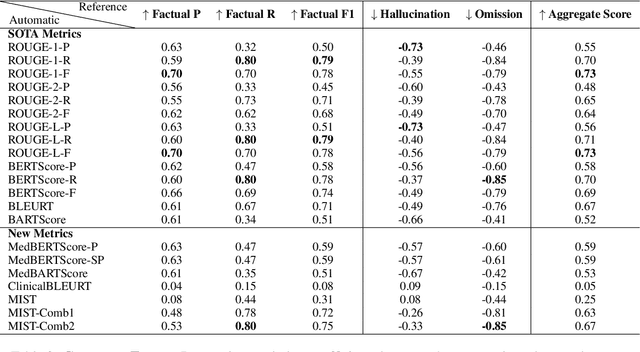
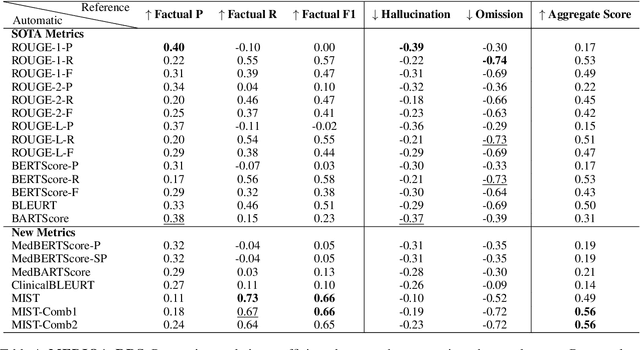
Recent studies on automatic note generation have shown that doctors can save significant amounts of time when using automatic clinical note generation (Knoll et al., 2022). Summarization models have been used for this task to generate clinical notes as summaries of doctor-patient conversations (Krishna et al., 2021; Cai et al., 2022). However, assessing which model would best serve clinicians in their daily practice is still a challenging task due to the large set of possible correct summaries, and the potential limitations of automatic evaluation metrics. In this paper, we study evaluation methods and metrics for the automatic generation of clinical notes from medical conversations. In particular, we propose new task-specific metrics and we compare them to SOTA evaluation metrics in text summarization and generation, including: (i) knowledge-graph embedding-based metrics, (ii) customized model-based metrics, (iii) domain-adapted/fine-tuned metrics, and (iv) ensemble metrics. To study the correlation between the automatic metrics and manual judgments, we evaluate automatic notes/summaries by comparing the system and reference facts and computing the factual correctness, and the hallucination and omission rates for critical medical facts. This study relied on seven datasets manually annotated by domain experts. Our experiments show that automatic evaluation metrics can have substantially different behaviors on different types of clinical notes datasets. However, the results highlight one stable subset of metrics as the most correlated with human judgments with a relevant aggregation of different evaluation criteria.
DotHash: Estimating Set Similarity Metrics for Link Prediction and Document Deduplication
May 27, 2023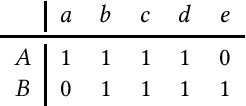
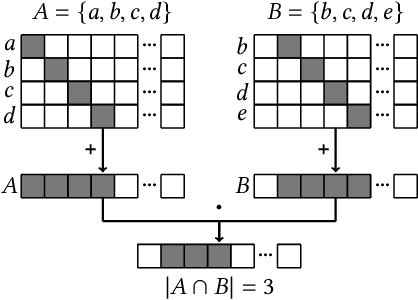
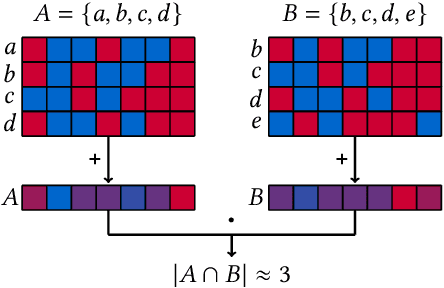
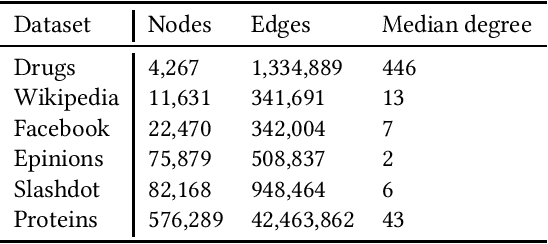
Metrics for set similarity are a core aspect of several data mining tasks. To remove duplicate results in a Web search, for example, a common approach looks at the Jaccard index between all pairs of pages. In social network analysis, a much-celebrated metric is the Adamic-Adar index, widely used to compare node neighborhood sets in the important problem of predicting links. However, with the increasing amount of data to be processed, calculating the exact similarity between all pairs can be intractable. The challenge of working at this scale has motivated research into efficient estimators for set similarity metrics. The two most popular estimators, MinHash and SimHash, are indeed used in applications such as document deduplication and recommender systems where large volumes of data need to be processed. Given the importance of these tasks, the demand for advancing estimators is evident. We propose DotHash, an unbiased estimator for the intersection size of two sets. DotHash can be used to estimate the Jaccard index and, to the best of our knowledge, is the first method that can also estimate the Adamic-Adar index and a family of related metrics. We formally define this family of metrics, provide theoretical bounds on the probability of estimate errors, and analyze its empirical performance. Our experimental results indicate that DotHash is more accurate than the other estimators in link prediction and detecting duplicate documents with the same complexity and similar comparison time.