 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Self-Checker: Plug-and-Play Modules for Fact-Checking with Large Language Models
May 24, 2023
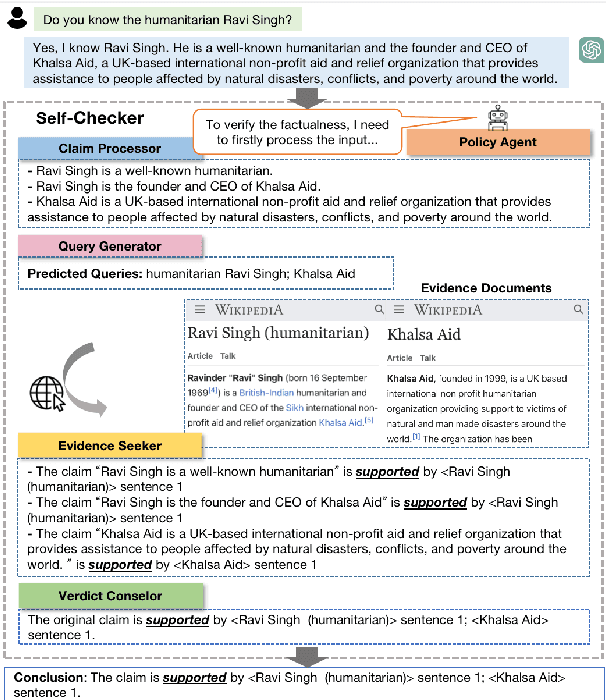

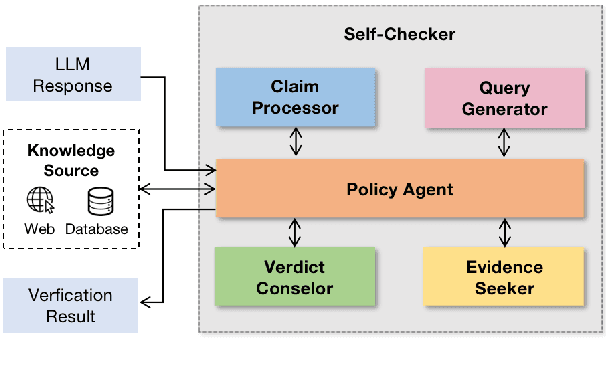
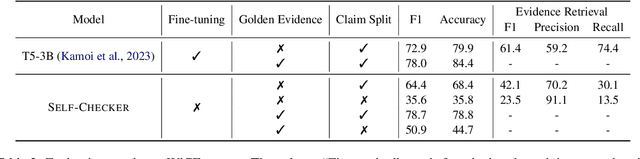
Fact-checking is an essential task in NLP that is commonly utilized for validating the factual accuracy of claims. Prior work has mainly focused on fine-tuning pre-trained languages models on specific datasets, which can be computationally intensive and time-consuming. With the rapid development of large language models (LLMs), such as ChatGPT and GPT-3, researchers are now exploring their in-context learning capabilities for a wide range of tasks. In this paper, we aim to assess the capacity of LLMs for fact-checking by introducing Self-Checker, a framework comprising a set of plug-and-play modules that facilitate fact-checking by purely prompting LLMs in an almost zero-shot setting. This framework provides a fast and efficient way to construct fact-checking systems in low-resource environments. Empirical results demonstrate the potential of Self-Checker in utilizing LLMs for fact-checking. However, there is still significant room for improvement compared to SOTA fine-tuned models, which suggests that LLM adoption could be a promising approach for future fact-checking research.
Comparing Humans and Models on a Similar Scale: Towards Cognitive Gender Bias Evaluation in Coreference Resolution
May 24, 2023
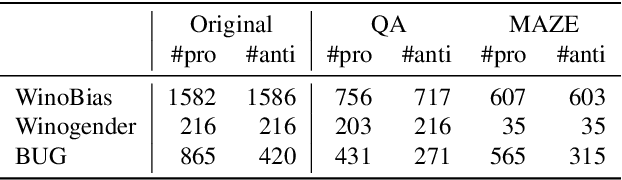
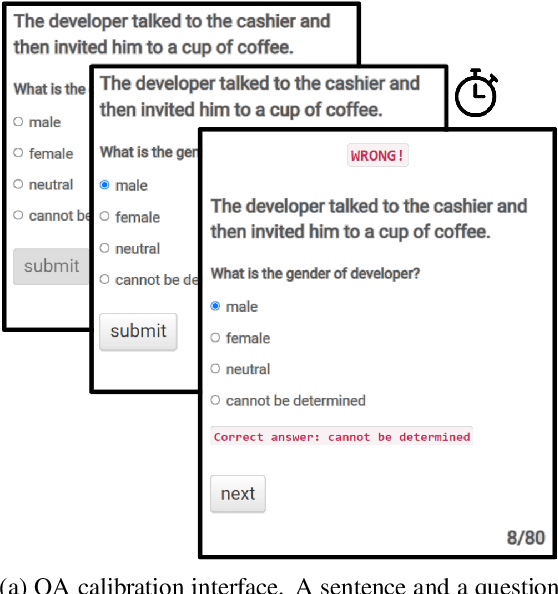
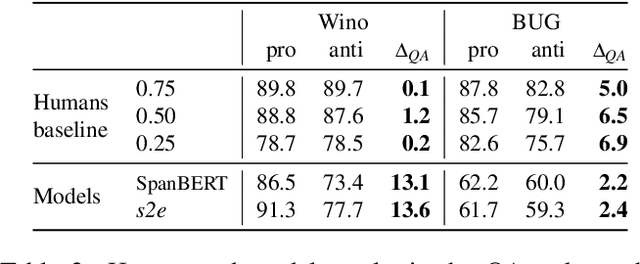
Spurious correlations were found to be an important factor explaining model performance in various NLP tasks (e.g., gender or racial artifacts), often considered to be ''shortcuts'' to the actual task. However, humans tend to similarly make quick (and sometimes wrong) predictions based on societal and cognitive presuppositions. In this work we address the question: can we quantify the extent to which model biases reflect human behaviour? Answering this question will help shed light on model performance and provide meaningful comparisons against humans. We approach this question through the lens of the dual-process theory for human decision-making. This theory differentiates between an automatic unconscious (and sometimes biased) ''fast system'' and a ''slow system'', which when triggered may revisit earlier automatic reactions. We make several observations from two crowdsourcing experiments of gender bias in coreference resolution, using self-paced reading to study the ''fast'' system, and question answering to study the ''slow'' system under a constrained time setting. On real-world data humans make $\sim$3\% more gender-biased decisions compared to models, while on synthetic data models are $\sim$12\% more biased.
Feature-aligned N-BEATS with Sinkhorn divergence
May 24, 2023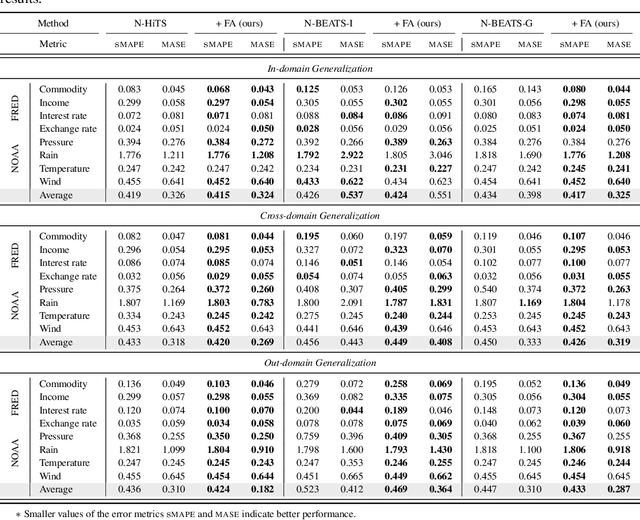
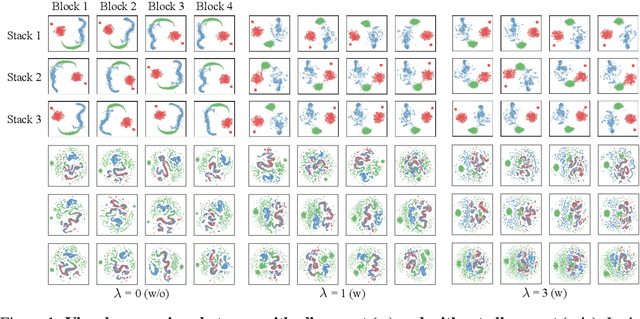
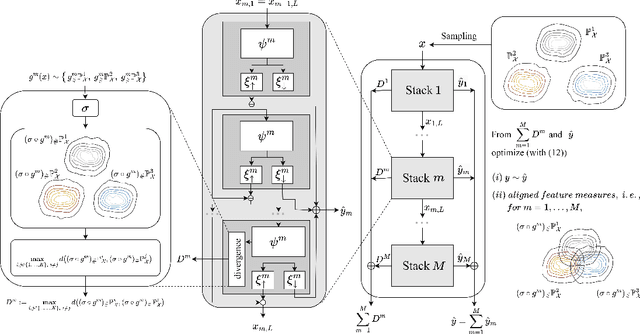

In this study, we propose Feature-aligned N-BEATS as a domain generalization model for univariate time series forecasting problems. The proposed model is an extension of the doubly residual stacking architecture of N-BEATS (Oreshkin et al. [34]) into a representation learning framework. The model is a new structure that involves marginal feature probability measures (i.e., pushforward measures of multiple source domains) induced by the intricate composition of residual operators of N-BEATS in each stack and aligns them stack-wise via an entropic regularized Wasserstein distance referred to as the Sinkhorn divergence (Genevay et al. [14]). The loss function consists of a typical forecasting loss for multiple source domains and an alignment loss calculated with the Sinkhorn divergence, which allows the model to learn invariant features stack-wise across multiple source data sequences while retaining N-BEATS's interpretable design. We conduct a comprehensive experimental evaluation of the proposed approach and the results demonstrate the model's forecasting and generalization capabilities in comparison with methods based on the original N-BEATS.
Modeling Appropriate Language in Argumentation
May 24, 2023
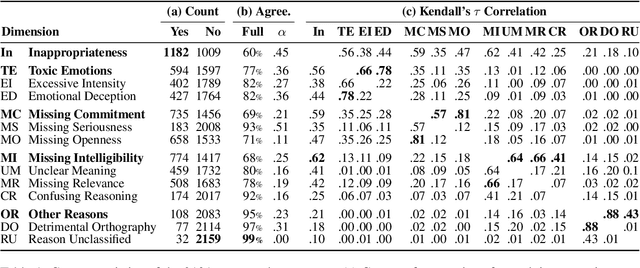
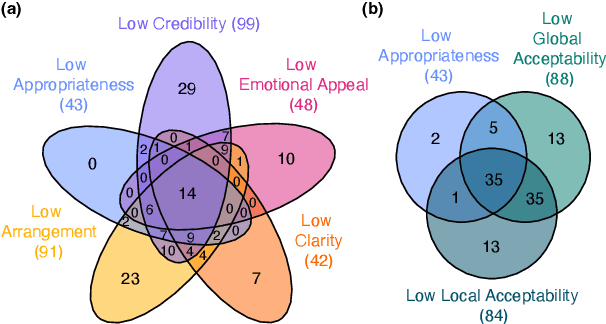
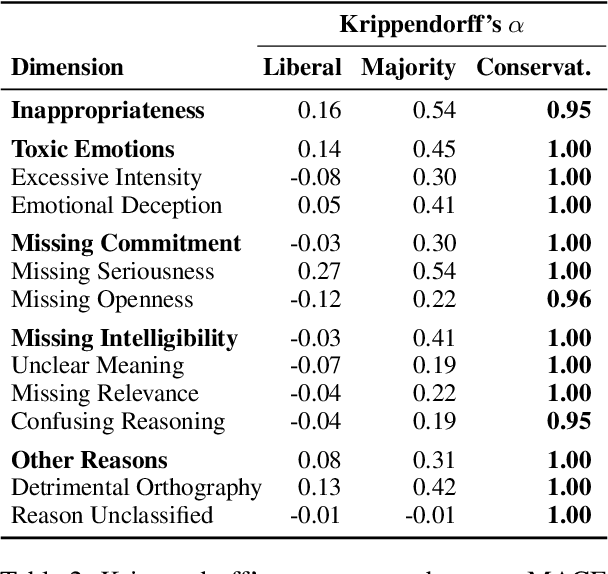
Online discussion moderators must make ad-hoc decisions about whether the contributions of discussion participants are appropriate or should be removed to maintain civility. Existing research on offensive language and the resulting tools cover only one aspect among many involved in such decisions. The question of what is considered appropriate in a controversial discussion has not yet been systematically addressed. In this paper, we operationalize appropriate language in argumentation for the first time. In particular, we model appropriateness through the absence of flaws, grounded in research on argument quality assessment, especially in aspects from rhetoric. From these, we derive a new taxonomy of 14 dimensions that determine inappropriate language in online discussions. Building on three argument quality corpora, we then create a corpus of 2191 arguments annotated for the 14 dimensions. Empirical analyses support that the taxonomy covers the concept of appropriateness comprehensively, showing several plausible correlations with argument quality dimensions. Moreover, results of baseline approaches to assessing appropriateness suggest that all dimensions can be modeled computationally on the corpus.
Test like you Train in Implicit Deep Learning
May 24, 2023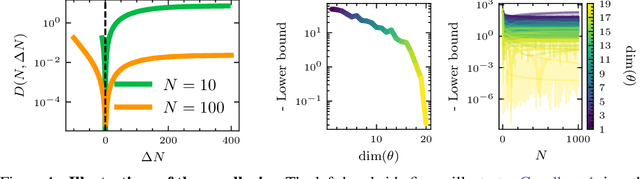
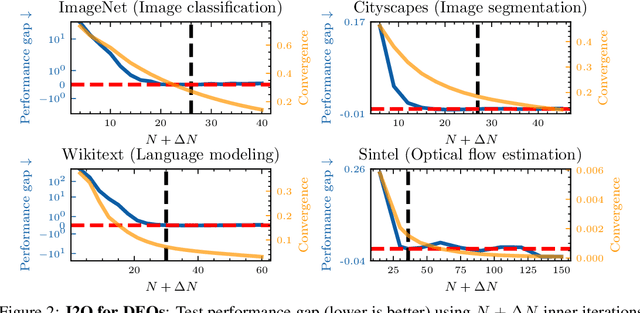
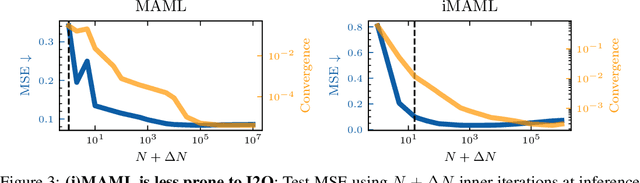
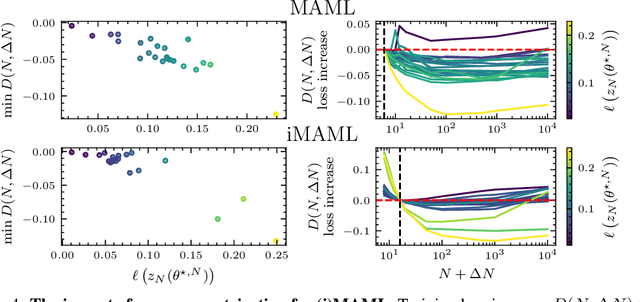
Implicit deep learning has recently gained popularity with applications ranging from meta-learning to Deep Equilibrium Networks (DEQs). In its general formulation, it relies on expressing some components of deep learning pipelines implicitly, typically via a root equation called the inner problem. In practice, the solution of the inner problem is approximated during training with an iterative procedure, usually with a fixed number of inner iterations. During inference, the inner problem needs to be solved with new data. A popular belief is that increasing the number of inner iterations compared to the one used during training yields better performance. In this paper, we question such an assumption and provide a detailed theoretical analysis in a simple setting. We demonstrate that overparametrization plays a key role: increasing the number of iterations at test time cannot improve performance for overparametrized networks. We validate our theory on an array of implicit deep-learning problems. DEQs, which are typically overparametrized, do not benefit from increasing the number of iterations at inference while meta-learning, which is typically not overparametrized, benefits from it.
Annotation Imputation to Individualize Predictions: Initial Studies on Distribution Dynamics and Model Predictions
May 24, 2023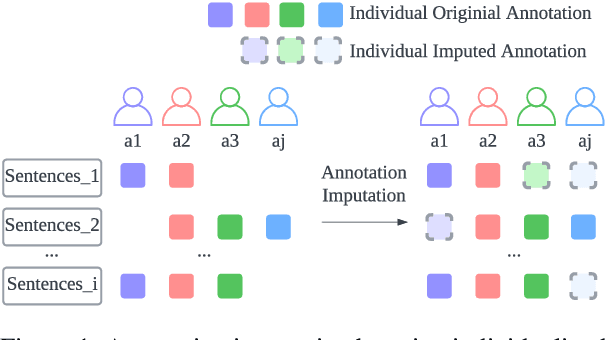

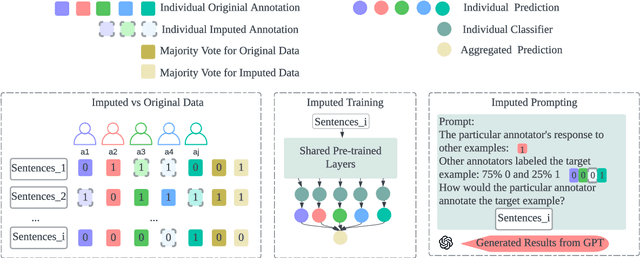
Annotating data via crowdsourcing is time-consuming and expensive. Owing to these costs, dataset creators often have each annotator label only a small subset of the data. This leads to sparse datasets with examples that are marked by few annotators; if an annotator is not selected to label an example, their opinion regarding it is lost. This is especially concerning for subjective NLP datasets where there is no correct label: people may have different valid opinions. Thus, we propose using imputation methods to restore the opinions of all annotators for all examples, creating a dataset that does not leave out any annotator's view. We then train and prompt models with data from the imputed dataset (rather than the original sparse dataset) to make predictions about majority and individual annotations. Unfortunately, the imputed data provided by our baseline methods does not improve predictions. However, through our analysis of it, we develop a strong understanding of how different imputation methods impact the original data in order to inform future imputation techniques. We make all of our code and data publicly available.
GrACE: Generation using Associated Code Edits
May 24, 2023
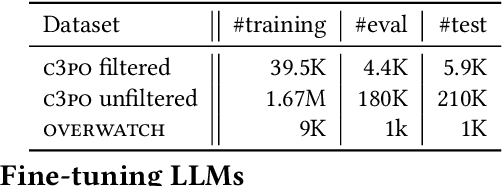


Developers expend a significant amount of time in editing code for a variety of reasons such as bug fixing or adding new features. Designing effective methods to predict code edits has been an active yet challenging area of research due to the diversity of code edits and the difficulty of capturing the developer intent. In this work, we address these challenges by endowing pre-trained large language models (LLMs) of code with the knowledge of prior, relevant edits. The generative capability of the LLMs helps address the diversity in code changes and conditioning code generation on prior edits helps capture the latent developer intent. We evaluate two well-known LLMs, Codex and CodeT5, in zero-shot and fine-tuning settings respectively. In our experiments with two datasets, the knowledge of prior edits boosts the performance of the LLMs significantly and enables them to generate 29% and 54% more correctly edited code in top-1 suggestions relative to the current state-of-the-art symbolic and neural approaches, respectively.
Training on Thin Air: Improve Image Classification with Generated Data
May 24, 2023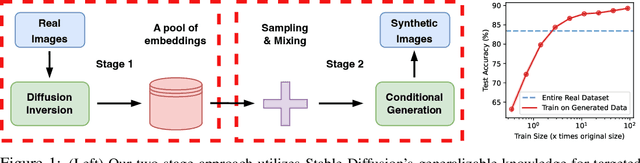
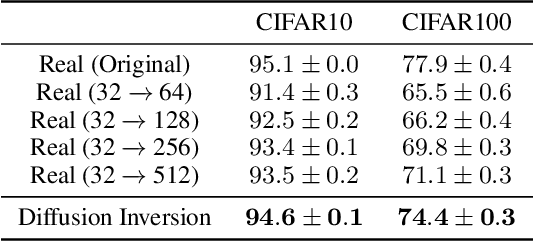
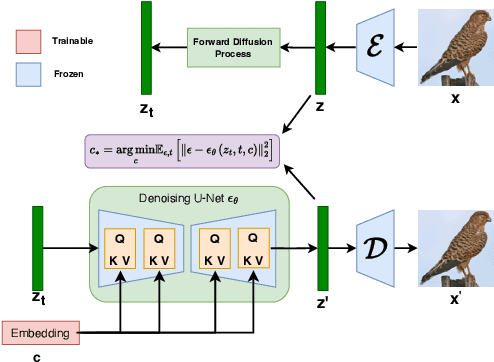

Acquiring high-quality data for training discriminative models is a crucial yet challenging aspect of building effective predictive systems. In this paper, we present Diffusion Inversion, a simple yet effective method that leverages the pre-trained generative model, Stable Diffusion, to generate diverse, high-quality training data for image classification. Our approach captures the original data distribution and ensures data coverage by inverting images to the latent space of Stable Diffusion, and generates diverse novel training images by conditioning the generative model on noisy versions of these vectors. We identify three key components that allow our generated images to successfully supplant the original dataset, leading to a 2-3x enhancement in sample complexity and a 6.5x decrease in sampling time. Moreover, our approach consistently outperforms generic prompt-based steering methods and KNN retrieval baseline across a wide range of datasets. Additionally, we demonstrate the compatibility of our approach with widely-used data augmentation techniques, as well as the reliability of the generated data in supporting various neural architectures and enhancing few-shot learning.
Training Energy-Based Normalizing Flow with Score-Matching Objectives
May 24, 2023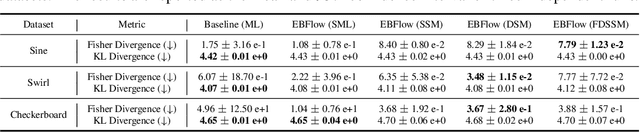
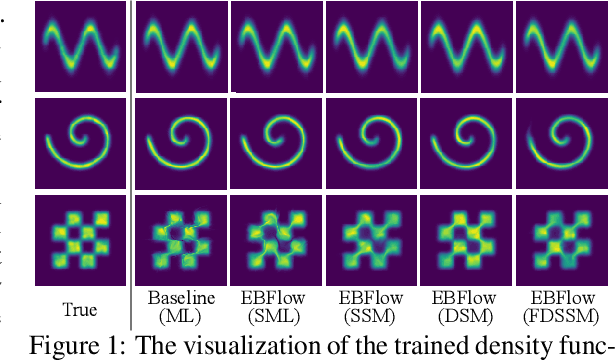
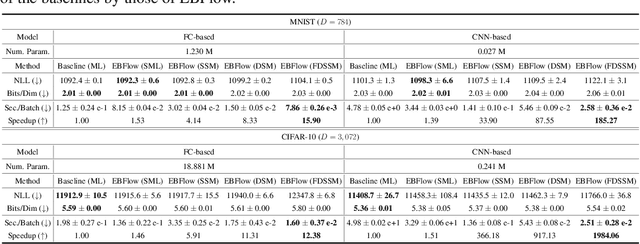
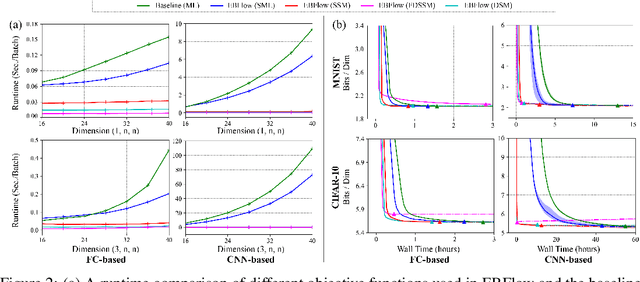
In this paper, we establish a connection between the parameterization of flow-based and energy-based generative models, and present a new flow-based modeling approach called energy-based normalizing flow (EBFlow). We demonstrate that by optimizing EBFlow with score-matching objectives, the computation of Jacobian determinants for linear transformations can be entirely bypassed. This feature enables the use of arbitrary linear layers in the construction of flow-based models without increasing the computational time complexity of each training iteration from $\mathcal{O}(D^2L)$ to $\mathcal{O}(D^3L)$ for an $L$-layered model that accepts $D$-dimensional inputs. This makes the training of EBFlow more efficient than the commonly-adopted maximum likelihood training method. In addition to the reduction in runtime, we enhance the training stability and empirical performance of EBFlow through a number of techniques developed based on our analysis on the score-matching methods. The experimental results demonstrate that our approach achieves a significant speedup compared to maximum likelihood estimation, while outperforming prior efficient training techniques with a noticeable margin in terms of negative log-likelihood (NLL).
Using Models Based on Cognitive Theory to Predict Human Behavior in Traffic: A Case Study
May 24, 2023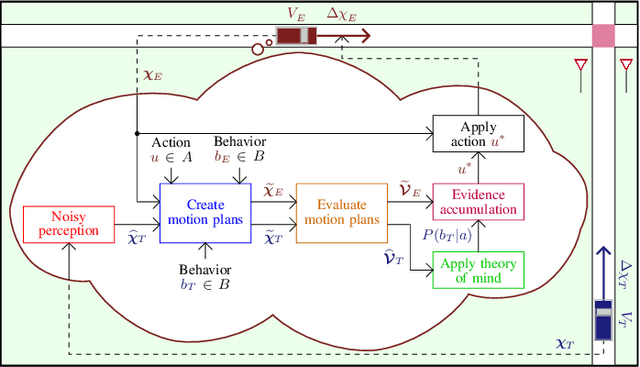
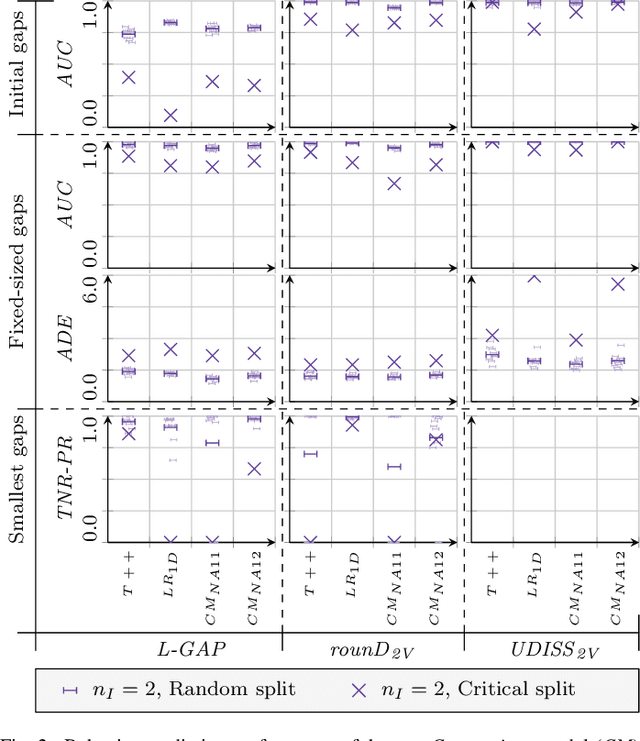

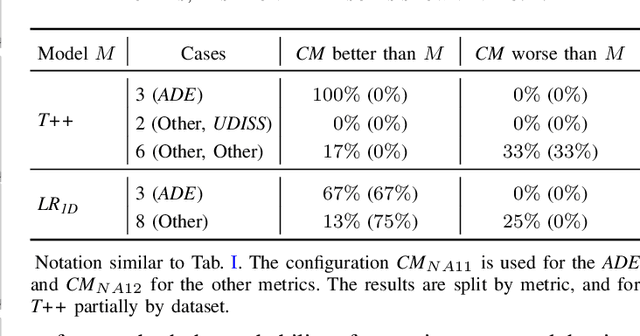
The development of automated vehicles has the potential to revolutionize transportation, but they are currently unable to ensure a safe and time-efficient driving style. Reliable models predicting human behavior are essential for overcoming this issue. While data-driven models are commonly used to this end, they can be vulnerable in safety-critical edge cases. This has led to an interest in models incorporating cognitive theory, but as such models are commonly developed for explanatory purposes, this approach's effectiveness in behavior prediction has remained largely untested so far. In this article, we investigate the usefulness of the \emph{Commotions} model -- a novel cognitively plausible model incorporating the latest theories of human perception, decision-making, and motor control -- for predicting human behavior in gap acceptance scenarios, which entail many important traffic interactions such as lane changes and intersections. We show that this model can compete with or even outperform well-established data-driven prediction models across several naturalistic datasets. These results demonstrate the promise of incorporating cognitive theory in behavior prediction models for automated vehicles.