 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHashtag Re-Appropriation for Audience Control on Recommendation-Driven Social Media Xiaohongshu (rednote)
Jan 30, 2025



Algorithms have played a central role in personalized recommendations on social media. However, they also present significant obstacles for content creators trying to predict and manage their audience reach. This issue is particularly challenging for marginalized groups seeking to maintain safe spaces. Our study explores how women on Xiaohongshu (rednote), a recommendation-driven social platform, proactively re-appropriate hashtags (e.g., #Baby Supplemental Food) by using them in posts unrelated to their literal meaning. The hashtags were strategically chosen from topics that would be uninteresting to the male audience they wanted to block. Through a mixed-methods approach, we analyzed the practice of hashtag re-appropriation based on 5,800 collected posts and interviewed 24 active users from diverse backgrounds to uncover users' motivations and reactions towards the re-appropriation. This practice highlights how users can reclaim agency over content distribution on recommendation-driven platforms, offering insights into self-governance within algorithmic-centered power structures.
CoCoLoFa: A Dataset of News Comments with Common Logical Fallacies Written by LLM-Assisted Crowds
Oct 04, 2024



Detecting logical fallacies in texts can help users spot argument flaws, but automating this detection is not easy. Manually annotating fallacies in large-scale, real-world text data to create datasets for developing and validating detection models is costly. This paper introduces CoCoLoFa, the largest known logical fallacy dataset, containing 7,706 comments for 648 news articles, with each comment labeled for fallacy presence and type. We recruited 143 crowd workers to write comments embodying specific fallacy types (e.g., slippery slope) in response to news articles. Recognizing the complexity of this writing task, we built an LLM-powered assistant into the workers' interface to aid in drafting and refining their comments. Experts rated the writing quality and labeling validity of CoCoLoFa as high and reliable. BERT-based models fine-tuned using CoCoLoFa achieved the highest fallacy detection (F1=0.86) and classification (F1=0.87) performance on its test set, outperforming the state-of-the-art LLMs. Our work shows that combining crowdsourcing and LLMs enables us to more effectively construct datasets for complex linguistic phenomena that crowd workers find challenging to produce on their own.
CoCo Matrix: Taxonomy of Cognitive Contributions in Co-writing with Intelligent Agents
May 21, 2024


In recent years, there has been a growing interest in employing intelligent agents in writing. Previous work emphasizes the evaluation of the quality of end product-whether it was coherent and polished, overlooking the journey that led to the product, which is an invaluable dimension of the creative process. To understand how to recognize human efforts in co-writing with intelligent writing systems, we adapt Flower and Hayes' cognitive process theory of writing and propose CoCo Matrix, a two-dimensional taxonomy of entropy and information gain, to depict the new human-agent co-writing model. We define four quadrants and situate thirty-four published systems within the taxonomy. Our research found that low entropy and high information gain systems are under-explored, yet offer promising future directions in writing tasks that benefit from the agent's divergent planning and the human's focused translation. CoCo Matrix, not only categorizes different writing systems but also deepens our understanding of the cognitive processes in human-agent co-writing. By analyzing minimal changes in the writing process, CoCo Matrix serves as a proxy for the writer's mental model, allowing writers to reflect on their contributions. This reflection is facilitated through the measured metrics of information gain and entropy, which provide insights irrespective of the writing system used.
Annotation Imputation to Individualize Predictions: Initial Studies on Distribution Dynamics and Model Predictions
May 24, 2023



Annotating data via crowdsourcing is time-consuming and expensive. Owing to these costs, dataset creators often have each annotator label only a small subset of the data. This leads to sparse datasets with examples that are marked by few annotators; if an annotator is not selected to label an example, their opinion regarding it is lost. This is especially concerning for subjective NLP datasets where there is no correct label: people may have different valid opinions. Thus, we propose using imputation methods to restore the opinions of all annotators for all examples, creating a dataset that does not leave out any annotator's view. We then train and prompt models with data from the imputed dataset (rather than the original sparse dataset) to make predictions about majority and individual annotations. Unfortunately, the imputed data provided by our baseline methods does not improve predictions. However, through our analysis of it, we develop a strong understanding of how different imputation methods impact the original data in order to inform future imputation techniques. We make all of our code and data publicly available.
Everyone's Voice Matters: Quantifying Annotation Disagreement Using Demographic Information
Jan 12, 2023



In NLP annotation, it is common to have multiple annotators label the text and then obtain the ground truth labels based on the agreement of major annotators. However, annotators are individuals with different backgrounds, and minors' opinions should not be simply ignored. As annotation tasks become subjective and topics are controversial in modern NLP tasks, we need NLP systems that can represent people's diverse voices on subjective matters and predict the level of diversity. This paper examines whether the text of the task and annotators' demographic background information can be used to estimate the level of disagreement among annotators. Particularly, we extract disagreement labels from the annotators' voting histories in the five subjective datasets, and then fine-tune language models to predict annotators' disagreement. Our results show that knowing annotators' demographic information, like gender, ethnicity, and education level, helps predict disagreements. In order to distinguish the disagreement from the inherent controversy from text content and the disagreement in the annotators' different perspectives, we simulate everyone's voices with different combinations of annotators' artificial demographics and examine its variance of the finetuned disagreement predictor. Our paper aims to improve the annotation process for more efficient and inclusive NLP systems through a novel disagreement prediction mechanism. Our code and dataset are publicly available.
A Conversational Agent System for Dietary Supplements Use
Apr 04, 2021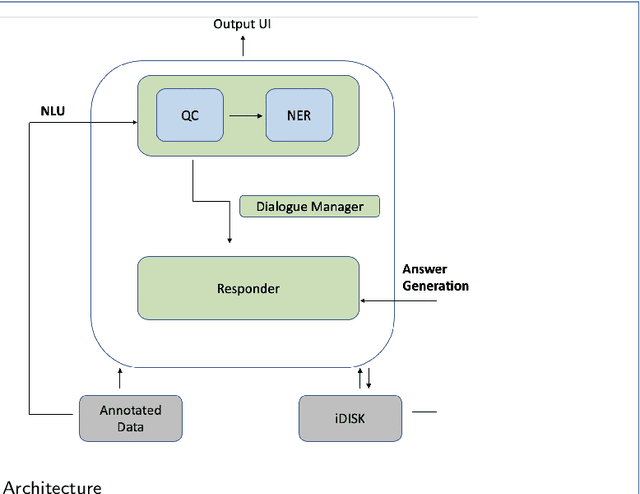

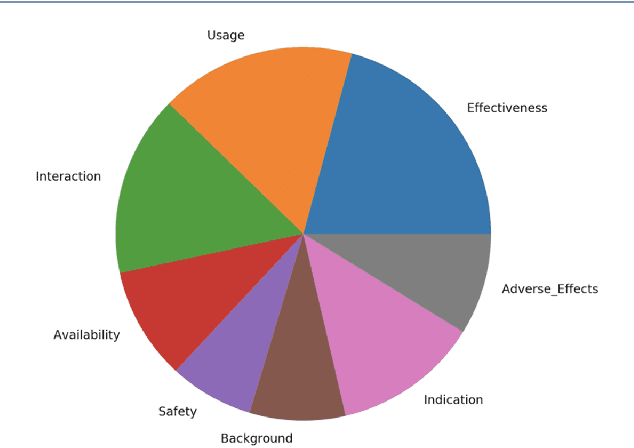
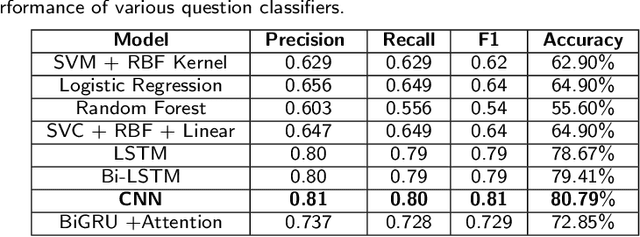
Dietary supplements (DS) have been widely used by consumers, but the information around the effectiveness and safety of DS is disparate or incomplete, making barriers to consumers to find information effectively. Conversational agent systems have been applied to the healthcare domain but there is no such a system to answer consumers regarding DS use, although widespread use of the dietary supplement. In this study, we develop the first conversational agent system for DS use.
Social determinants of health in the era of artificial intelligence with electronic health records: A systematic review
Jan 22, 2021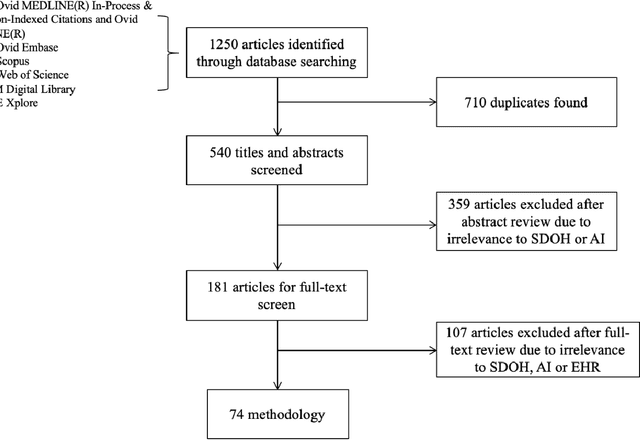
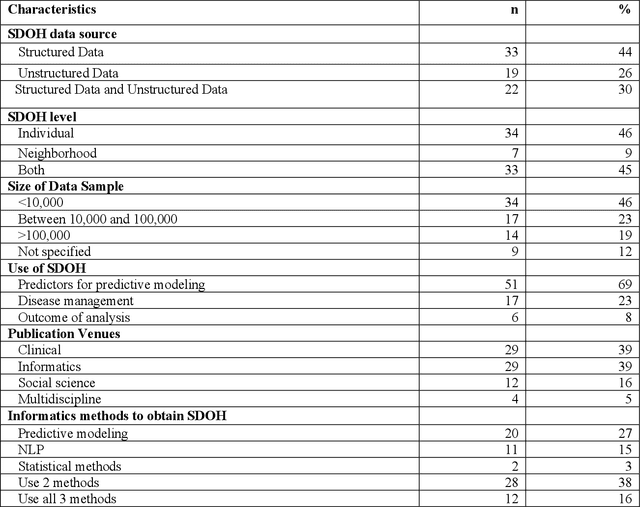
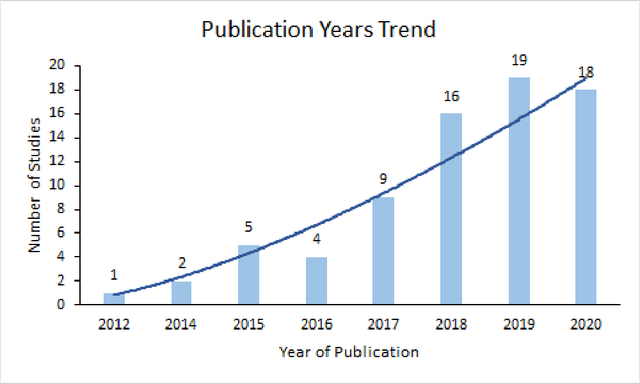
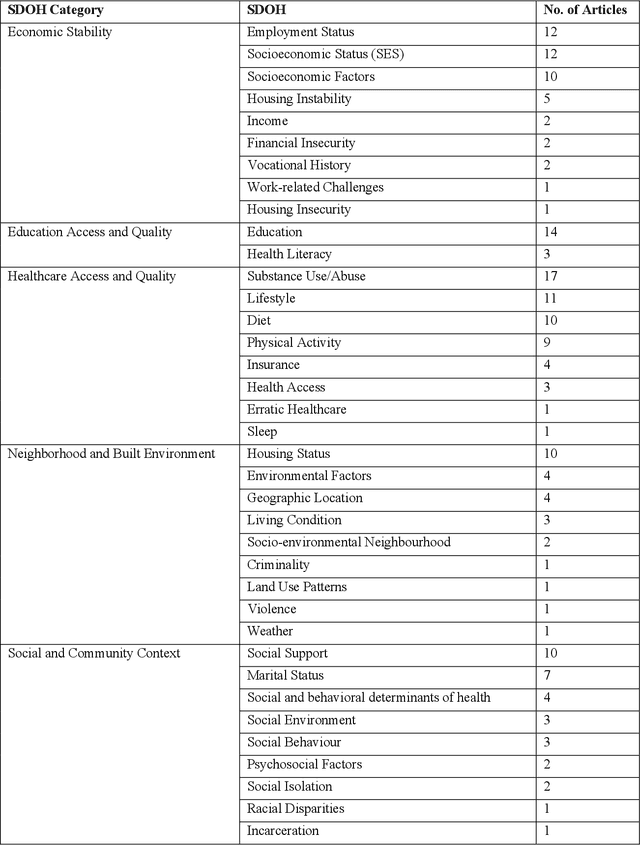
There is growing evidence showing the significant role of social determinant of health (SDOH) on a wide variety of health outcomes. In the era of artificial intelligence (AI), electronic health records (EHRs) have been widely used to conduct observational studies. However, how to make the best of SDOH information from EHRs is yet to be studied. In this paper, we systematically reviewed recently published papers and provided a methodology review of AI methods using the SDOH information in EHR data. A total of 1250 articles were retrieved from the literature between 2010 and 2020, and 74 papers were included in this review after abstract and full-text screening. We summarized these papers in terms of general characteristics (including publication years, venues, countries etc.), SDOH types, disease areas, study outcomes, AI methods to extract SDOH from EHRs and AI methods using SDOH for healthcare outcomes. Finally, we conclude this paper with discussion on the current trends, challenges, and future directions on using SDOH from EHRs.