 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Weak LLMs Speak with Confidence, Preference Alignment Gets Stronger
Mar 05, 2026Preference alignment is an essential step in adapting large language models (LLMs) to human values, but existing approaches typically depend on costly human annotations or large-scale API-based models. We explore whether a weak LLM can instead act as an effective annotator. We surprisingly find that selecting only a subset of a weak LLM's highly confident samples leads to substantially better performance than using full human annotations. Building on this insight, we propose Confidence-Weighted Preference Optimization (CW-PO), a general framework that re-weights training samples by a weak LLM's confidence and can be applied across different preference optimization objectives. Notably, the model aligned by CW-PO with just 20% of human annotations outperforms the model trained with 100% of annotations under standard DPO. These results suggest that weak LLMs, when paired with confidence weighting, can dramatically reduce the cost of preference alignment while even outperforming methods trained on fully human-labeled data.
Adaptive Problem Generation via Symbolic Representations
Feb 22, 2026We present a method for generating training data for reinforcement learning with verifiable rewards to improve small open-weights language models on mathematical tasks. Existing data generation approaches rely on open-loop pipelines and fixed modifications that do not adapt to the model's capabilities. Furthermore, they typically operate directly on word problems, limiting control over problem structure. To address this, we perform modifications in a symbolic problem space, representing each problem as a set of symbolic variables and constraints (e.g., via algebraic frameworks such as SymPy or SMT formulations). This representation enables precise control over problem structure, automatic generation of ground-truth solutions, and decouples mathematical reasoning from linguistic realization. We also show that this results in more diverse generations. To adapt the problem difficulty to the model, we introduce a closed-loop framework that learns modification strategies through prompt optimization in symbolic space. Experimental results demonstrate that both adaptive problem generation and symbolic representation modifications contribute to improving the model's math solving ability.
An Analysis of Model Robustness across Concurrent Distribution Shifts
Jan 08, 2025



Machine learning models, meticulously optimized for source data, often fail to predict target data when faced with distribution shifts (DSs). Previous benchmarking studies, though extensive, have mainly focused on simple DSs. Recognizing that DSs often occur in more complex forms in real-world scenarios, we broadened our study to include multiple concurrent shifts, such as unseen domain shifts combined with spurious correlations. We evaluated 26 algorithms that range from simple heuristic augmentations to zero-shot inference using foundation models, across 168 source-target pairs from eight datasets. Our analysis of over 100K models reveals that (i) concurrent DSs typically worsen performance compared to a single shift, with certain exceptions, (ii) if a model improves generalization for one distribution shift, it tends to be effective for others, and (iii) heuristic data augmentations achieve the best overall performance on both synthetic and real-world datasets.
Feature-aligned N-BEATS with Sinkhorn divergence
May 24, 2023



In this study, we propose Feature-aligned N-BEATS as a domain generalization model for univariate time series forecasting problems. The proposed model is an extension of the doubly residual stacking architecture of N-BEATS (Oreshkin et al. [34]) into a representation learning framework. The model is a new structure that involves marginal feature probability measures (i.e., pushforward measures of multiple source domains) induced by the intricate composition of residual operators of N-BEATS in each stack and aligns them stack-wise via an entropic regularized Wasserstein distance referred to as the Sinkhorn divergence (Genevay et al. [14]). The loss function consists of a typical forecasting loss for multiple source domains and an alignment loss calculated with the Sinkhorn divergence, which allows the model to learn invariant features stack-wise across multiple source data sequences while retaining N-BEATS's interpretable design. We conduct a comprehensive experimental evaluation of the proposed approach and the results demonstrate the model's forecasting and generalization capabilities in comparison with methods based on the original N-BEATS.
MARA-Net: Single Image Deraining Network with Multi-level connections and Adaptive Regional Attentions
Oct 04, 2020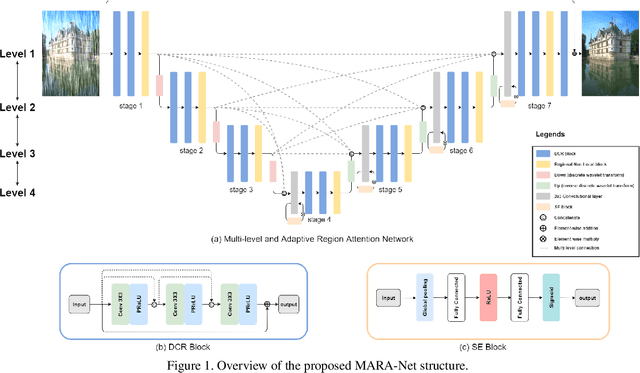
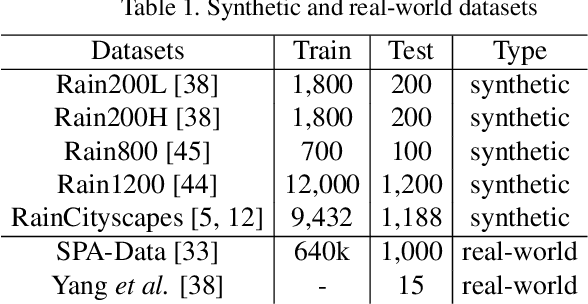
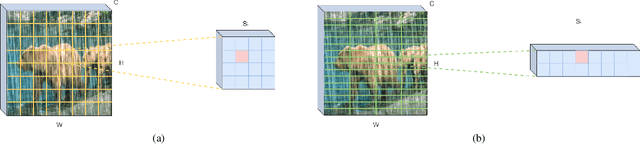
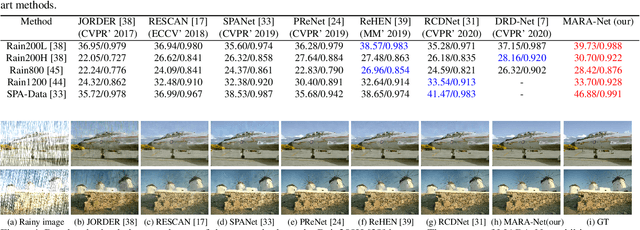
Removing rain streaks from single images is an important problem in various computer vision tasks because rain streaks can degrade outdoor images and reduce their visibility. While recent convolutional neural network-based deraining models have succeeded in capturing rain streaks effectively, difficulties in recovering the details in rain-free images still remain. In this paper, we present a multi-level connection and adaptive regional attention network (MARA-Net) to properly restore the original background textures in rainy images. The first main idea is a multi-level connection design that repeatedly connects multi-level features of the encoder network to the decoder network. Multi-level connections encourage the decoding process to use the feature information of all levels. Channel attention is considered in multi-level connections to learn which level of features is important in the decoding process of the current level. The second main idea is a wide regional non-local block (WRNL). As rain streaks primarily exhibit a vertical distribution, we divide the grid of the image into horizontally-wide patches and apply a non-local operation to each region to explore the rich rain-free background information. Experimental results on both synthetic and real-world rainy datasets demonstrate that the proposed model significantly outperforms existing state-of-the-art models. Furthermore, the results of the joint deraining and segmentation experiment prove that our model contributes effectively to other vision tasks.