 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers Can Achieve Length Generalization But Not Robustly
Feb 14, 2024



Length generalization, defined as the ability to extrapolate from shorter training sequences to longer test ones, is a significant challenge for language models. This issue persists even with large-scale Transformers handling relatively straightforward tasks. In this paper, we test the Transformer's ability of length generalization using the task of addition of two integers. We show that the success of length generalization is intricately linked to the data format and the type of position encoding. Using the right combination of data format and position encodings, we show for the first time that standard Transformers can extrapolate to a sequence length that is 2.5x the input length. Nevertheless, unlike in-distribution generalization, length generalization remains fragile, significantly influenced by factors like random weight initialization and training data order, leading to large variances across different random seeds.
DistillSpec: Improving Speculative Decoding via Knowledge Distillation
Oct 12, 2023



Speculative decoding (SD) accelerates large language model inference by employing a faster draft model for generating multiple tokens, which are then verified in parallel by the larger target model, resulting in the text generated according to the target model distribution. However, identifying a compact draft model that is well-aligned with the target model is challenging. To tackle this issue, we propose DistillSpec that uses knowledge distillation to better align the draft model with the target model, before applying SD. DistillSpec makes two key design choices, which we demonstrate via systematic study to be crucial to improving the draft and target alignment: utilizing on-policy data generation from the draft model, and tailoring the divergence function to the task and decoding strategy. Notably, DistillSpec yields impressive 10 - 45% speedups over standard SD on a range of standard benchmarks, using both greedy and non-greedy sampling. Furthermore, we combine DistillSpec with lossy SD to achieve fine-grained control over the latency vs. task performance trade-off. Finally, in practical scenarios with models of varying sizes, first using distillation to boost the performance of the target model and then applying DistillSpec to train a well-aligned draft model can reduce decoding latency by 6-10x with minimal performance drop, compared to standard decoding without distillation.
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Sep 25, 2023



Recent advances in Language Model (LM) agents and tool use, exemplified by applications like ChatGPT Plugins, enable a rich set of capabilities but also amplify potential risks - such as leaking private data or causing financial losses. Identifying these risks is labor-intensive, necessitating implementing the tools, manually setting up the environment for each test scenario, and finding risky cases. As tools and agents become more complex, the high cost of testing these agents will make it increasingly difficult to find high-stakes, long-tailed risks. To address these challenges, we introduce ToolEmu: a framework that uses an LM to emulate tool execution and enables the testing of LM agents against a diverse range of tools and scenarios, without manual instantiation. Alongside the emulator, we develop an LM-based automatic safety evaluator that examines agent failures and quantifies associated risks. We test both the tool emulator and evaluator through human evaluation and find that 68.8% of failures identified with ToolEmu would be valid real-world agent failures. Using our curated initial benchmark consisting of 36 high-stakes tools and 144 test cases, we provide a quantitative risk analysis of current LM agents and identify numerous failures with potentially severe outcomes. Notably, even the safest LM agent exhibits such failures 23.9% of the time according to our evaluator, underscoring the need to develop safer LM agents for real-world deployment.
Training on Thin Air: Improve Image Classification with Generated Data
May 24, 2023



Acquiring high-quality data for training discriminative models is a crucial yet challenging aspect of building effective predictive systems. In this paper, we present Diffusion Inversion, a simple yet effective method that leverages the pre-trained generative model, Stable Diffusion, to generate diverse, high-quality training data for image classification. Our approach captures the original data distribution and ensures data coverage by inverting images to the latent space of Stable Diffusion, and generates diverse novel training images by conditioning the generative model on noisy versions of these vectors. We identify three key components that allow our generated images to successfully supplant the original dataset, leading to a 2-3x enhancement in sample complexity and a 6.5x decrease in sampling time. Moreover, our approach consistently outperforms generic prompt-based steering methods and KNN retrieval baseline across a wide range of datasets. Additionally, we demonstrate the compatibility of our approach with widely-used data augmentation techniques, as well as the reliability of the generated data in supporting various neural architectures and enhancing few-shot learning.
Large Language Models Are Human-Level Prompt Engineers
Nov 03, 2022



By conditioning on natural language instructions, large language models (LLMs) have displayed impressive capabilities as general-purpose computers. However, task performance depends significantly on the quality of the prompt used to steer the model, and most effective prompts have been handcrafted by humans. Inspired by classical program synthesis and the human approach to prompt engineering, we propose Automatic Prompt Engineer (APE) for automatic instruction generation and selection. In our method, we treat the instruction as the "program," optimized by searching over a pool of instruction candidates proposed by an LLM in order to maximize a chosen score function. To evaluate the quality of the selected instruction, we evaluate the zero-shot performance of another LLM following the selected instruction. Experiments on 24 NLP tasks show that our automatically generated instructions outperform the prior LLM baseline by a large margin and achieve better or comparable performance to the instructions generated by human annotators on 19/24 tasks. We conduct extensive qualitative and quantitative analyses to explore the performance of APE. We show that APE-engineered prompts can be applied to steer models toward truthfulness and/or informativeness, as well as to improve few-shot learning performance by simply prepending them to standard in-context learning prompts. Please check out our webpage at https://sites.google.com/view/automatic-prompt-engineer.
Dataset Distillation using Neural Feature Regression
Jun 01, 2022
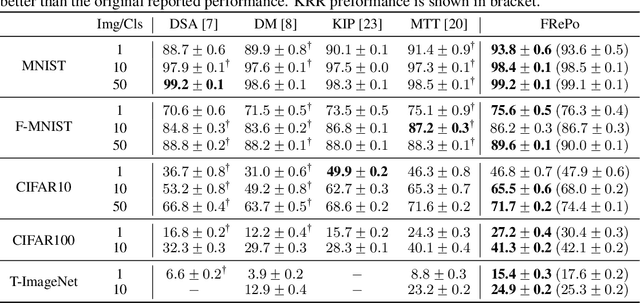
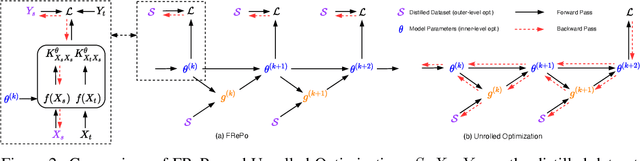

Dataset distillation aims to learn a small synthetic dataset that preserves most of the information from the original dataset. Dataset distillation can be formulated as a bi-level meta-learning problem where the outer loop optimizes the meta-dataset and the inner loop trains a model on the distilled data. Meta-gradient computation is one of the key challenges in this formulation, as differentiating through the inner loop learning procedure introduces significant computation and memory costs. In this paper, we address these challenges using neural Feature Regression with Pooling (FRePo), achieving the state-of-the-art performance with an order of magnitude less memory requirement and two orders of magnitude faster training than previous methods. The proposed algorithm is analogous to truncated backpropagation through time with a pool of models to alleviate various types of overfitting in dataset distillation. FRePo significantly outperforms the previous methods on CIFAR100, Tiny ImageNet, and ImageNet-1K. Furthermore, we show that high-quality distilled data can greatly improve various downstream applications, such as continual learning and membership inference defense.