 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Grouping Method for mmWave Massive MIMO System: Exploitation of Angular Multiplexing Gain
May 25, 2023
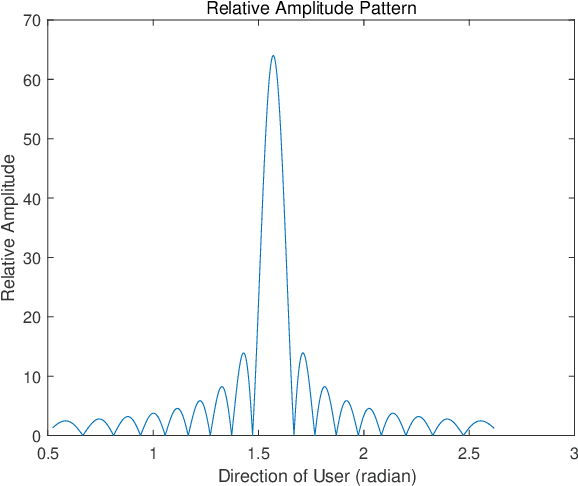
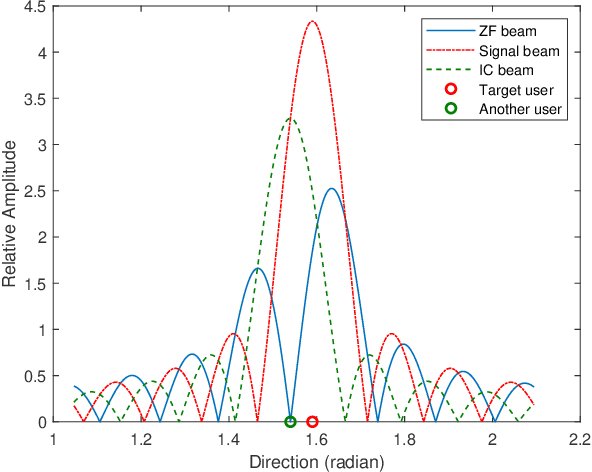
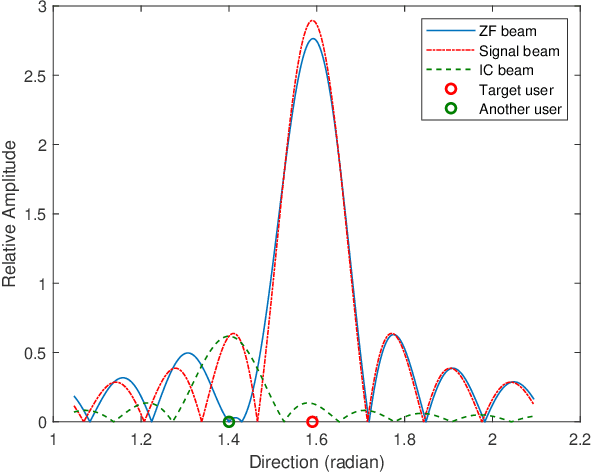
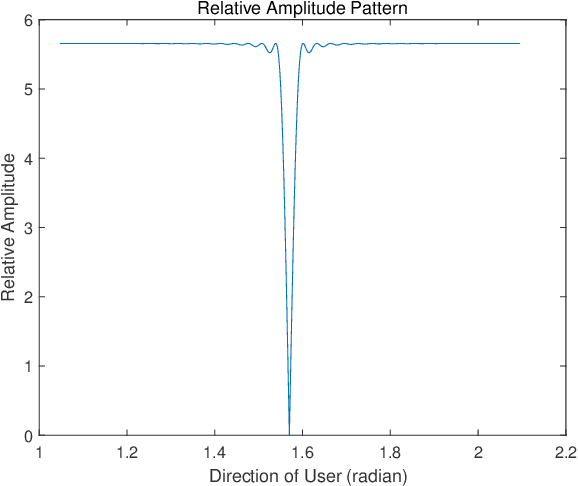
A future millimeter-wave (mmWave) massive multiple-input and multiple-output (MIMO) system may serve hundreds or thousands of users at the same time; thus, research on multiple access technology is particularly important.Moreover, due to the short-wavelength nature of a mmWave, large-scale arrays are easier to implement than microwaves, while their directivity and sparseness make the physical beamforming effect of precoding more prominent.In consideration of the mmWave angle division multiple access (ADMA) system based on precoding, this paper investigates the influence of the angle distribution on system performance, which is denoted as the angular multiplexing gain.Furthermore, inspired by the above research, we transform the ADMA user grouping problem to maximize the system sum-rate into the inter-user angular spacing equalization problem.Then, the form of the optimal solution for the approximate problem is derived, and the corresponding grouping algorithm is proposed.The simulation results demonstrate that the proposed algorithm performs better than the comparison methods.Finally, a complexity analysis also shows that the proposed algorithm has extremely low complexity.
Vision-based UAV Detection in Complex Backgrounds and Rainy Conditions
May 25, 2023

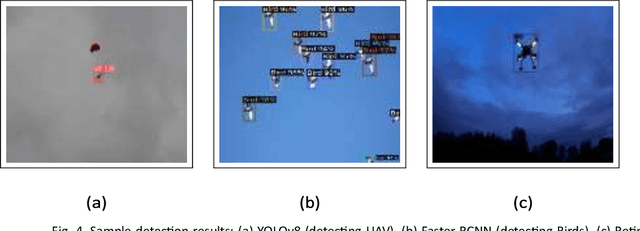

To detect UAVs in real-time, computer vision and deep learning approaches are developing areas of research. There have been concerns raised regarding the possible hazards and misuse of employing unmanned aerial vehicles (UAVs) in many applications. These include potential privacy violations, safety-related issues, and security threats. Vision-based detection systems often comprise a combination of hardware components such as cameras and software components. In this work, the performance of recent and popular vision-based object detection techniques is investigated for the task of UAV detection under challenging conditions such as complex backgrounds, varying UAV sizes, complex background scenarios, and low-to-heavy rainy conditions. To study the performance of selected methods under these conditions, two datasets were curated: one with a sky background and one with complex background. In this paper, one-stage detectors and two-stage detectors are studied and evaluated. The findings presented in the paper shall help provide insights concerning the performance of the selected models for the task of UAV detection under challenging conditions and pave the way to develop more robust UAV detection methods
Response Generation in Longitudinal Dialogues: Which Knowledge Representation Helps?
May 25, 2023

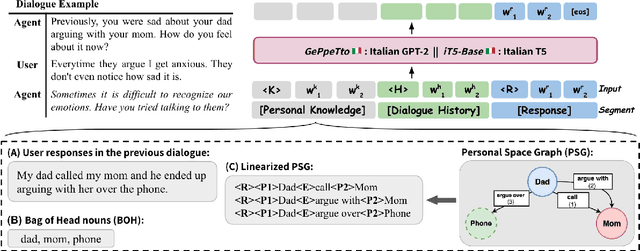
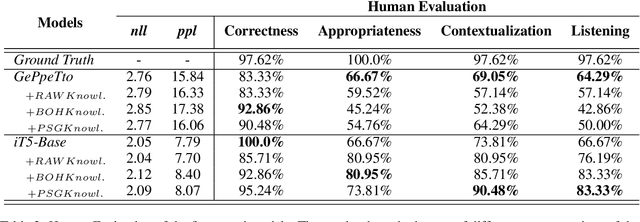
Longitudinal Dialogues (LD) are the most challenging type of conversation for human-machine dialogue systems. LDs include the recollections of events, personal thoughts, and emotions specific to each individual in a sparse sequence of dialogue sessions. Dialogue systems designed for LDs should uniquely interact with the users over multiple sessions and long periods of time (e.g. weeks), and engage them in personal dialogues to elaborate on their feelings, thoughts, and real-life events. In this paper, we study the task of response generation in LDs. We evaluate whether general-purpose Pre-trained Language Models (PLM) are appropriate for this purpose. We fine-tune two PLMs, GePpeTto (GPT-2) and iT5, using a dataset of LDs. We experiment with different representations of the personal knowledge extracted from LDs for grounded response generation, including the graph representation of the mentioned events and participants. We evaluate the performance of the models via automatic metrics and the contribution of the knowledge via the Integrated Gradients technique. We categorize the natural language generation errors via human evaluations of contextualization, appropriateness and engagement of the user.
Learning Robust Statistics for Simulation-based Inference under Model Misspecification
May 25, 2023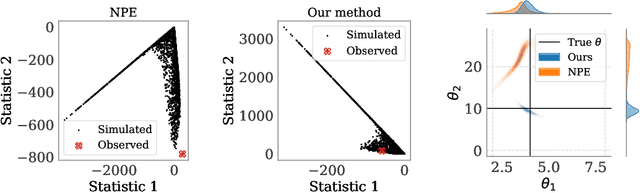
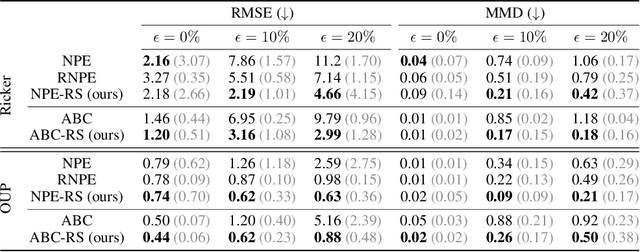
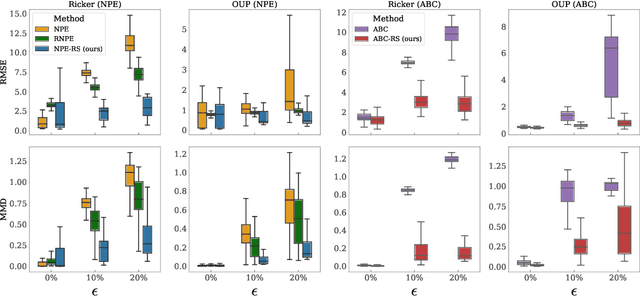
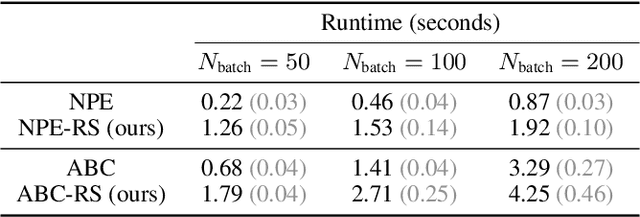
Simulation-based inference (SBI) methods such as approximate Bayesian computation (ABC), synthetic likelihood, and neural posterior estimation (NPE) rely on simulating statistics to infer parameters of intractable likelihood models. However, such methods are known to yield untrustworthy and misleading inference outcomes under model misspecification, thus hindering their widespread applicability. In this work, we propose the first general approach to handle model misspecification that works across different classes of SBI methods. Leveraging the fact that the choice of statistics determines the degree of misspecification in SBI, we introduce a regularized loss function that penalises those statistics that increase the mismatch between the data and the model. Taking NPE and ABC as use cases, we demonstrate the superior performance of our method on high-dimensional time-series models that are artificially misspecified. We also apply our method to real data from the field of radio propagation where the model is known to be misspecified. We show empirically that the method yields robust inference in misspecified scenarios, whilst still being accurate when the model is well-specified.
Revisiting Structured Variational Autoencoders
May 25, 2023Structured variational autoencoders (SVAEs) combine probabilistic graphical model priors on latent variables, deep neural networks to link latent variables to observed data, and structure-exploiting algorithms for approximate posterior inference. These models are particularly appealing for sequential data, where the prior can capture temporal dependencies. However, despite their conceptual elegance, SVAEs have proven difficult to implement, and more general approaches have been favored in practice. Here, we revisit SVAEs using modern machine learning tools and demonstrate their advantages over more general alternatives in terms of both accuracy and efficiency. First, we develop a modern implementation for hardware acceleration, parallelization, and automatic differentiation of the message passing algorithms at the core of the SVAE. Second, we show that by exploiting structure in the prior, the SVAE learns more accurate models and posterior distributions, which translate into improved performance on prediction tasks. Third, we show how the SVAE can naturally handle missing data, and we leverage this ability to develop a novel, self-supervised training approach. Altogether, these results show that the time is ripe to revisit structured variational autoencoders.
Multi-lingual and Multi-cultural Figurative Language Understanding
May 25, 2023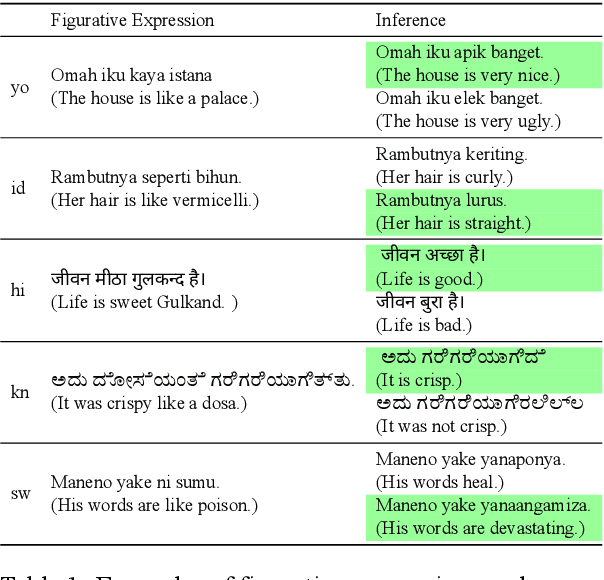
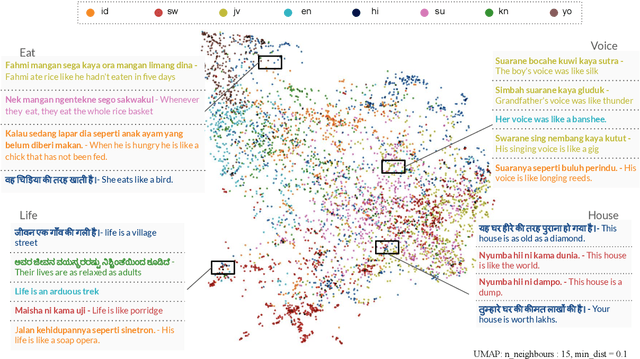

Figurative language permeates human communication, but at the same time is relatively understudied in NLP. Datasets have been created in English to accelerate progress towards measuring and improving figurative language processing in language models (LMs). However, the use of figurative language is an expression of our cultural and societal experiences, making it difficult for these phrases to be universally applicable. In this work, we create a figurative language inference dataset, \datasetname, for seven diverse languages associated with a variety of cultures: Hindi, Indonesian, Javanese, Kannada, Sundanese, Swahili and Yoruba. Our dataset reveals that each language relies on cultural and regional concepts for figurative expressions, with the highest overlap between languages originating from the same region. We assess multilingual LMs' abilities to interpret figurative language in zero-shot and few-shot settings. All languages exhibit a significant deficiency compared to English, with variations in performance reflecting the availability of pre-training and fine-tuning data, emphasizing the need for LMs to be exposed to a broader range of linguistic and cultural variation during training.
Which Features are Learnt by Contrastive Learning? On the Role of Simplicity Bias in Class Collapse and Feature Suppression
May 25, 2023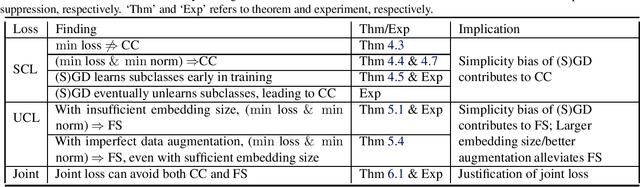
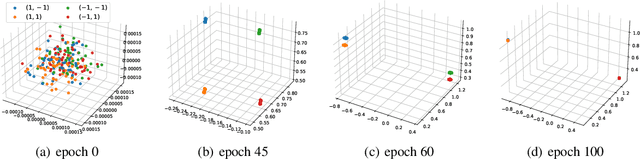
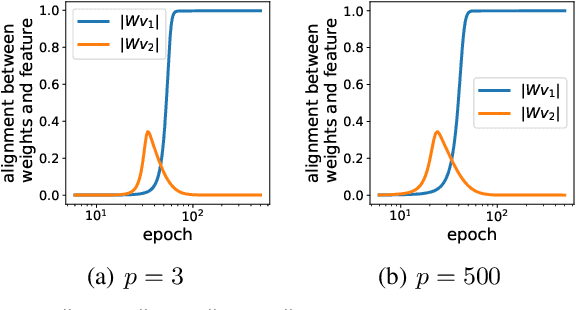
Contrastive learning (CL) has emerged as a powerful technique for representation learning, with or without label supervision. However, supervised CL is prone to collapsing representations of subclasses within a class by not capturing all their features, and unsupervised CL may suppress harder class-relevant features by focusing on learning easy class-irrelevant features; both significantly compromise representation quality. Yet, there is no theoretical understanding of \textit{class collapse} or \textit{feature suppression} at \textit{test} time. We provide the first unified theoretically rigorous framework to determine \textit{which} features are learnt by CL. Our analysis indicate that, perhaps surprisingly, bias of (stochastic) gradient descent towards finding simpler solutions is a key factor in collapsing subclass representations and suppressing harder class-relevant features. Moreover, we present increasing embedding dimensionality and improving the quality of data augmentations as two theoretically motivated solutions to {feature suppression}. We also provide the first theoretical explanation for why employing supervised and unsupervised CL together yields higher-quality representations, even when using commonly-used stochastic gradient methods.
Distilling Script Knowledge from Large Language Models for Constrained Language Planning
May 22, 2023
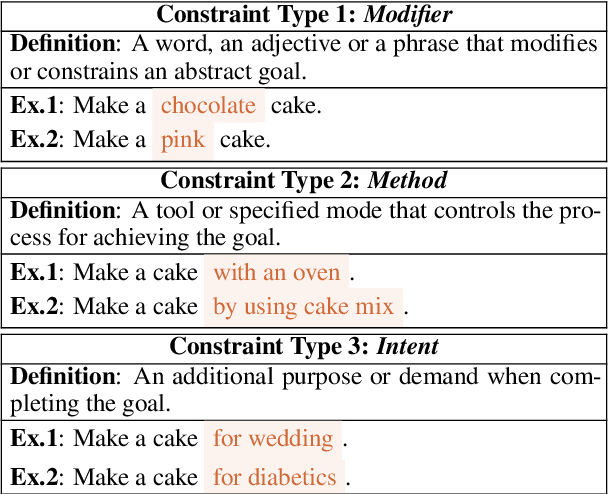
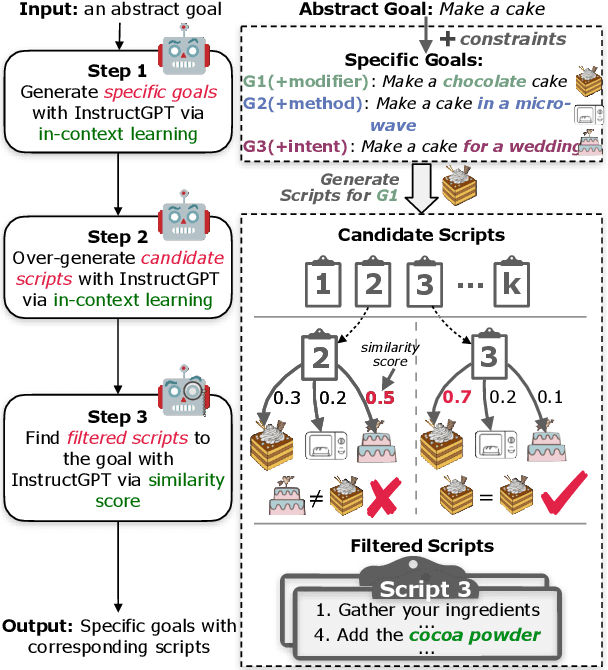

In everyday life, humans often plan their actions by following step-by-step instructions in the form of goal-oriented scripts. Previous work has exploited language models (LMs) to plan for abstract goals of stereotypical activities (e.g., "make a cake"), but leaves more specific goals with multi-facet constraints understudied (e.g., "make a cake for diabetics"). In this paper, we define the task of constrained language planning for the first time. We propose an overgenerate-then-filter approach to improve large language models (LLMs) on this task, and use it to distill a novel constrained language planning dataset, CoScript, which consists of 55,000 scripts. Empirical results demonstrate that our method significantly improves the constrained language planning ability of LLMs, especially on constraint faithfulness. Furthermore, CoScript is demonstrated to be quite effective in endowing smaller LMs with constrained language planning ability.
Gated Stereo: Joint Depth Estimation from Gated and Wide-Baseline Active Stereo Cues
May 22, 2023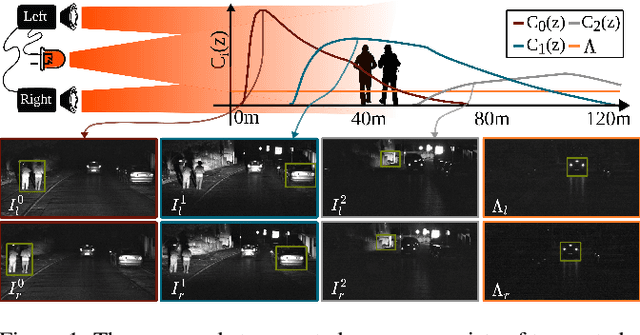
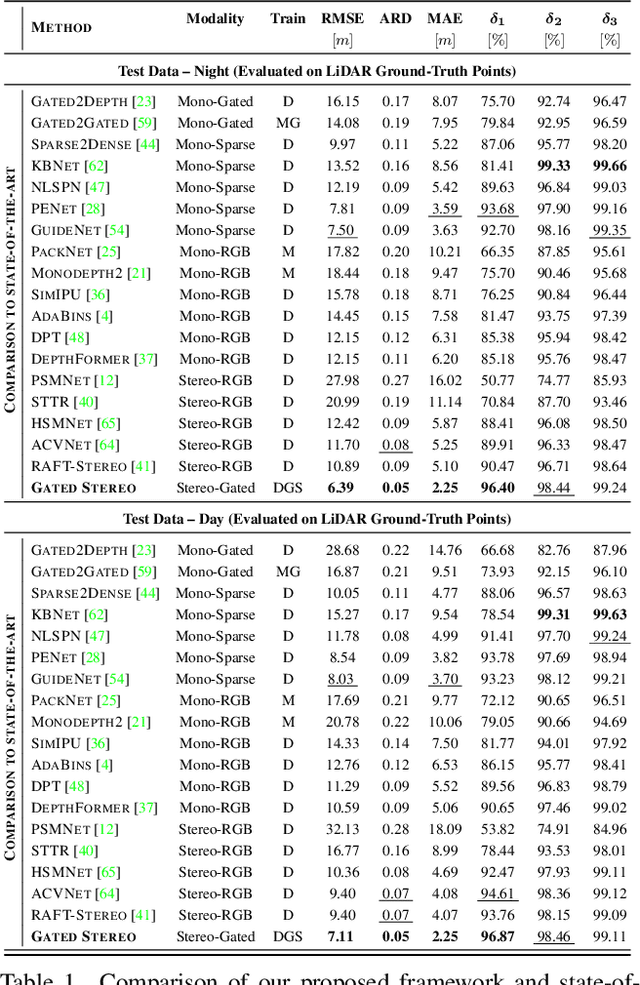
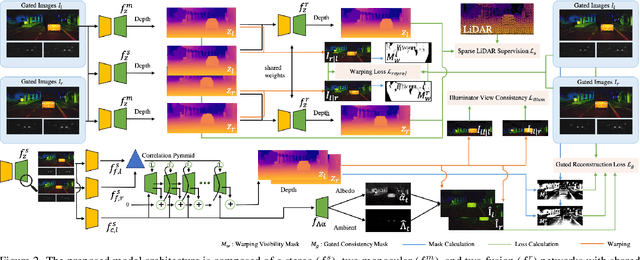
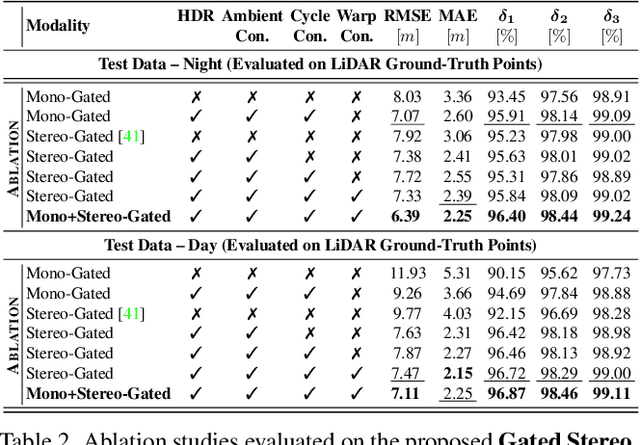
We propose Gated Stereo, a high-resolution and long-range depth estimation technique that operates on active gated stereo images. Using active and high dynamic range passive captures, Gated Stereo exploits multi-view cues alongside time-of-flight intensity cues from active gating. To this end, we propose a depth estimation method with a monocular and stereo depth prediction branch which are combined in a final fusion stage. Each block is supervised through a combination of supervised and gated self-supervision losses. To facilitate training and validation, we acquire a long-range synchronized gated stereo dataset for automotive scenarios. We find that the method achieves an improvement of more than 50 % MAE compared to the next best RGB stereo method, and 74 % MAE to existing monocular gated methods for distances up to 160 m. Our code,models and datasets are available here.
An Abstract Specification of VoxML as an Annotation Language
May 22, 2023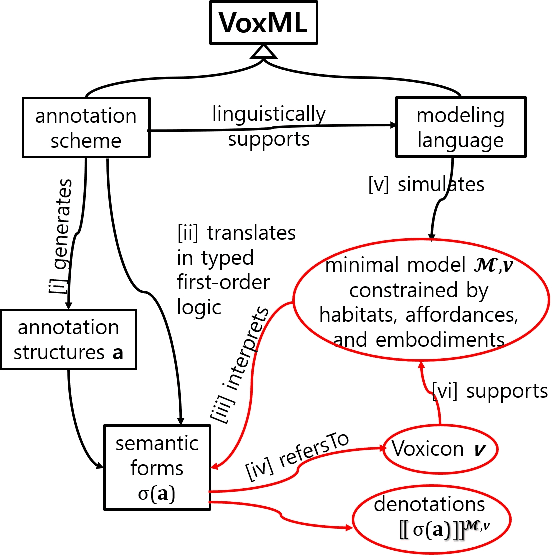
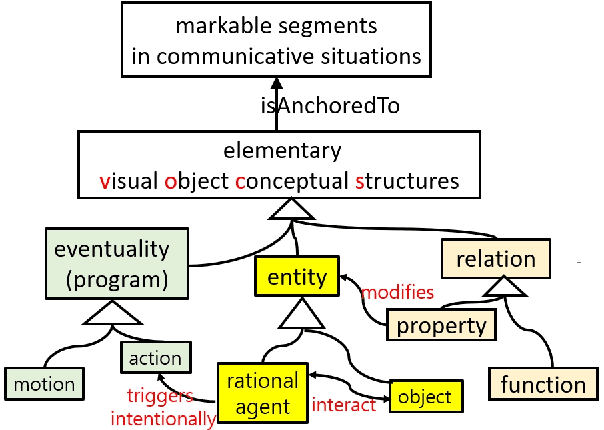

VoxML is a modeling language used to map natural language expressions into real-time visualizations using commonsense semantic knowledge of objects and events. Its utility has been demonstrated in embodied simulation environments and in agent-object interactions in situated multimodal human-agent collaboration and communication. It introduces the notion of object affordance (both Gibsonian and Telic) from HRI and robotics, as well as the concept of habitat (an object's context of use) for interactions between a rational agent and an object. This paper aims to specify VoxML as an annotation language in general abstract terms. It then shows how it works on annotating linguistic data that express visually perceptible human-object interactions. The annotation structures thus generated will be interpreted against the enriched minimal model created by VoxML as a modeling language while supporting the modeling purposes of VoxML linguistically.