 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An AMR-based Link Prediction Approach for Document-level Event Argument Extraction
May 30, 2023
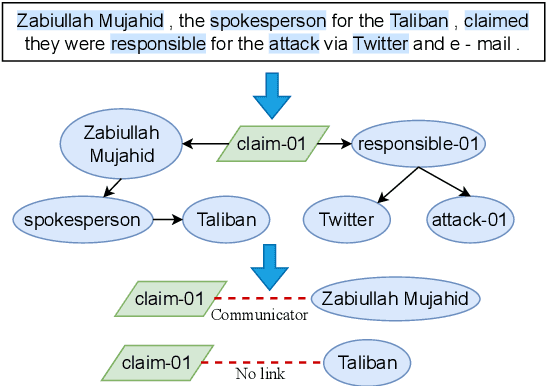

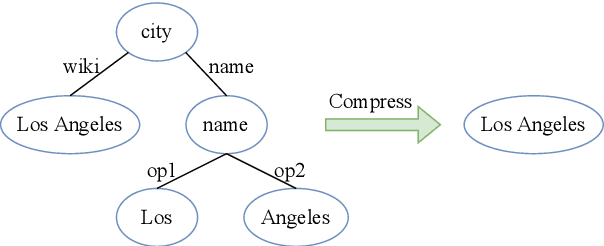
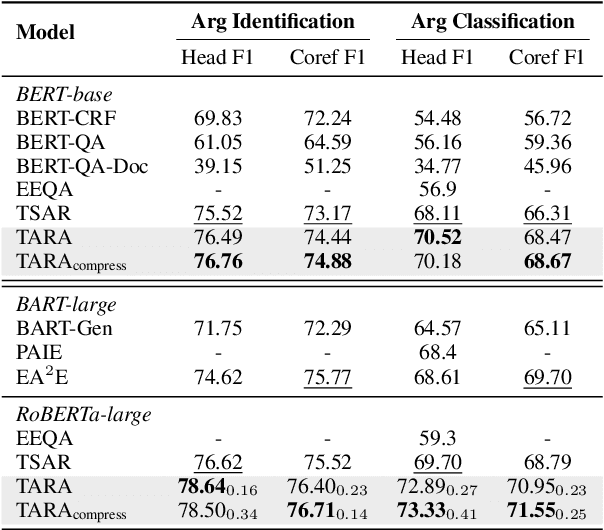
Recent works have introduced Abstract Meaning Representation (AMR) for Document-level Event Argument Extraction (Doc-level EAE), since AMR provides a useful interpretation of complex semantic structures and helps to capture long-distance dependency. However, in these works AMR is used only implicitly, for instance, as additional features or training signals. Motivated by the fact that all event structures can be inferred from AMR, this work reformulates EAE as a link prediction problem on AMR graphs. Since AMR is a generic structure and does not perfectly suit EAE, we propose a novel graph structure, Tailored AMR Graph (TAG), which compresses less informative subgraphs and edge types, integrates span information, and highlights surrounding events in the same document. With TAG, we further propose a novel method using graph neural networks as a link prediction model to find event arguments. Our extensive experiments on WikiEvents and RAMS show that this simpler approach outperforms the state-of-the-art models by 3.63pt and 2.33pt F1, respectively, and do so with reduced 56% inference time. The code is availabel at https://github.com/ayyyq/TARA.
Prompt-based Tuning of Transformer Models for Multi-Center Medical Image Segmentation
May 30, 2023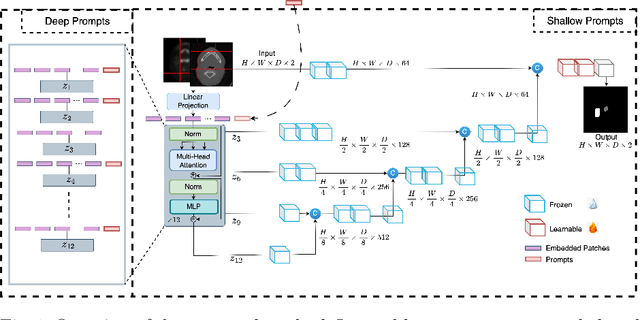

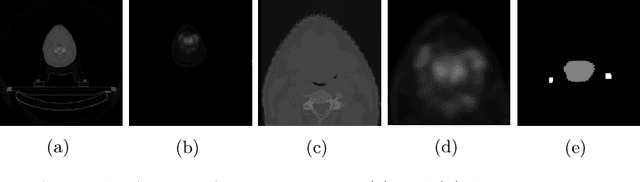
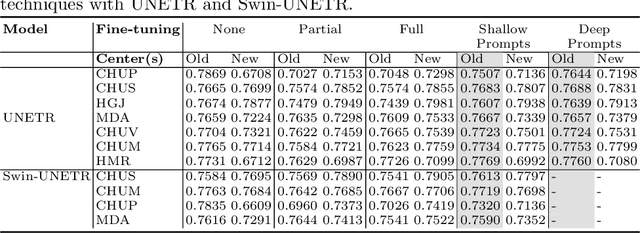
Medical image segmentation is a vital healthcare endeavor requiring precise and efficient models for appropriate diagnosis and treatment. Vision transformer-based segmentation models have shown great performance in accomplishing this task. However, to build a powerful backbone, the self-attention block of ViT requires large-scale pre-training data. The present method of modifying pre-trained models entails updating all or some of the backbone parameters. This paper proposes a novel fine-tuning strategy for adapting a pretrained transformer-based segmentation model on data from a new medical center. This method introduces a small number of learnable parameters, termed prompts, into the input space (less than 1\% of model parameters) while keeping the rest of the model parameters frozen. Extensive studies employing data from new unseen medical centers show that prompts-based fine-tuning of medical segmentation models provides excellent performance on the new center data with a negligible drop on the old centers. Additionally, our strategy delivers great accuracy with minimum re-training on new center data, significantly decreasing the computational and time costs of fine-tuning pre-trained models.
Prediction Error-based Classification for Class-Incremental Learning
May 30, 2023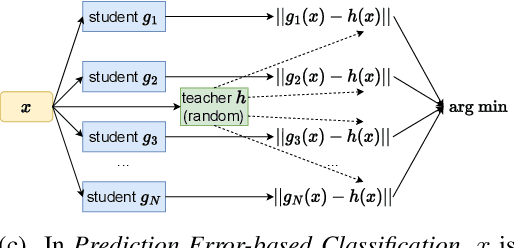
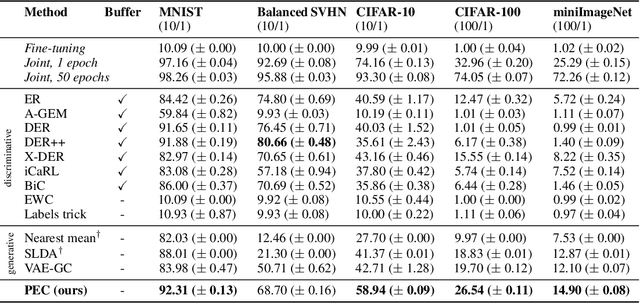
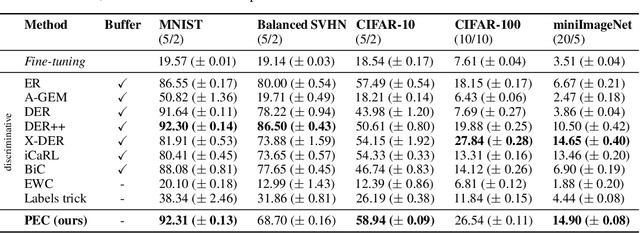
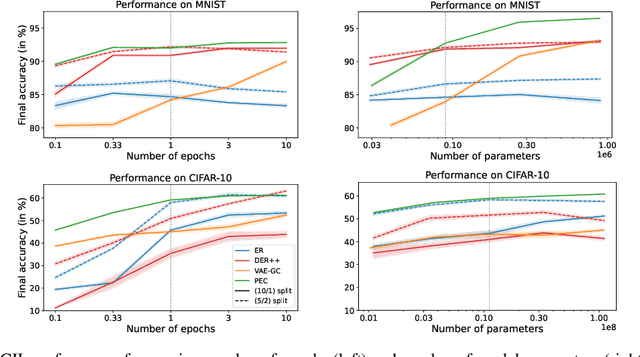
Class-incremental learning (CIL) is a particularly challenging variant of continual learning, where the goal is to learn to discriminate between all classes presented in an incremental fashion. Existing approaches often suffer from excessive forgetting and imbalance of the scores assigned to classes that have not been seen together during training. In this study, we introduce a novel approach, Prediction Error-based Classification (PEC), which differs from traditional discriminative and generative classification paradigms. PEC computes a class score by measuring the prediction error of a model trained to replicate the outputs of a frozen random neural network on data from that class. The method can be interpreted as approximating a classification rule based on Gaussian Process posterior variance. PEC offers several practical advantages, including sample efficiency, ease of tuning, and effectiveness even when data are presented one class at a time. Our empirical results show that PEC performs strongly in single-pass-through-data CIL, outperforming other rehearsal-free baselines in all cases and rehearsal-based methods with moderate replay buffer size in most cases across multiple benchmarks.
Competing for Shareable Arms in Multi-Player Multi-Armed Bandits
May 30, 2023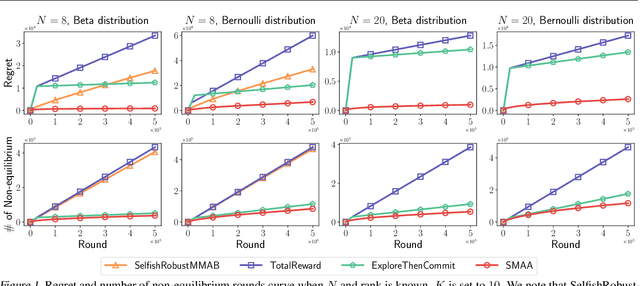
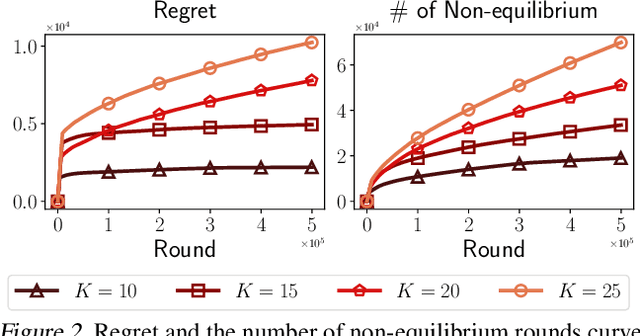
Competitions for shareable and limited resources have long been studied with strategic agents. In reality, agents often have to learn and maximize the rewards of the resources at the same time. To design an individualized competing policy, we model the competition between agents in a novel multi-player multi-armed bandit (MPMAB) setting where players are selfish and aim to maximize their own rewards. In addition, when several players pull the same arm, we assume that these players averagely share the arms' rewards by expectation. Under this setting, we first analyze the Nash equilibrium when arms' rewards are known. Subsequently, we propose a novel SelfishMPMAB with Averaging Allocation (SMAA) approach based on the equilibrium. We theoretically demonstrate that SMAA could achieve a good regret guarantee for each player when all players follow the algorithm. Additionally, we establish that no single selfish player can significantly increase their rewards through deviation, nor can they detrimentally affect other players' rewards without incurring substantial losses for themselves. We finally validate the effectiveness of the method in extensive synthetic experiments.
High-Gain Disturbance Observer for Robust Trajectory Tracking of Quadrotors
May 30, 2023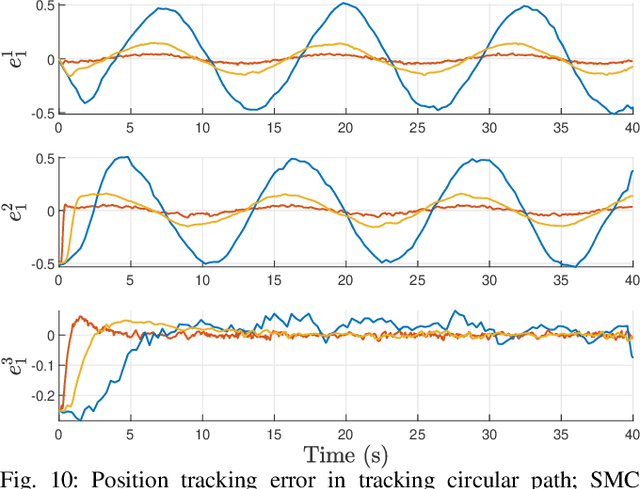
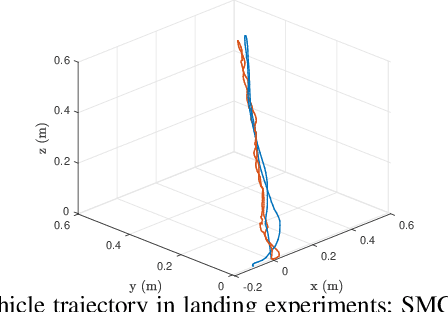
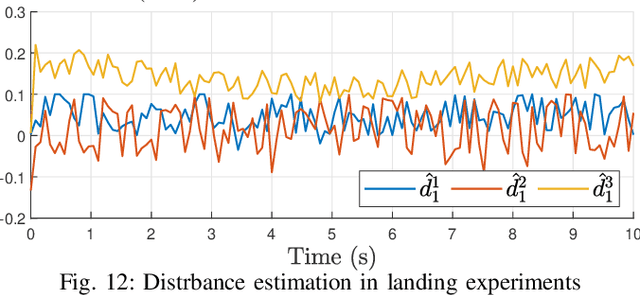
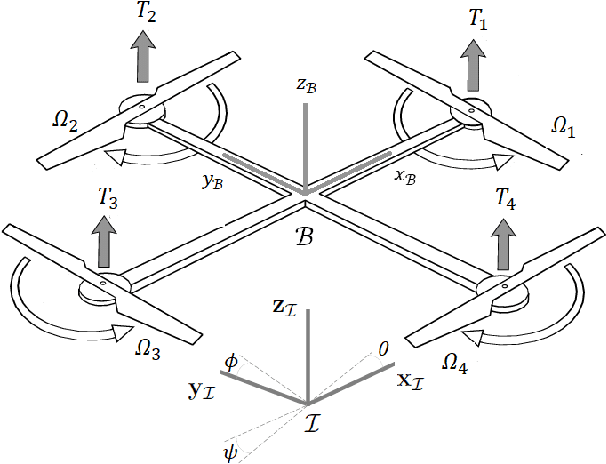
This paper presents a simple method to boost the robustness of quadrotors in trajectory tracking. The presented method features a high-gain disturbance observer (HGDO) that provides disturbance estimates in real-time. The estimates are then used in a trajectory control law to compensate for disturbance effects. We present theoretical convergence results showing that the proposed HGDO can quickly converge to an adjustable neighborhood of actual disturbance values. We will then integrate the disturbance estimates with a typical robust trajectory controller, namely sliding mode control (SMC), and present Lyapunov stability analysis to establish the boundedness of trajectory tracking errors. However, our stability analysis can be easily extended to other Lyapunov-based controllers to develop different HGDO-based controllers with formal stability guarantees. We evaluate the proposed HGDO-based control method using both simulation and laboratory experiments in various scenarios and in the presence of external disturbances. Our results indicate that the addition of HGDO to a quadrotor trajectory controller can significantly improve the accuracy and precision of trajectory tracking in the presence of external disturbances.
Understanding temporally weakly supervised training: A case study for keyword spotting
May 30, 2023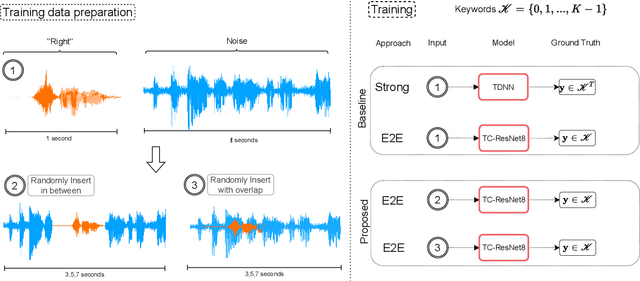

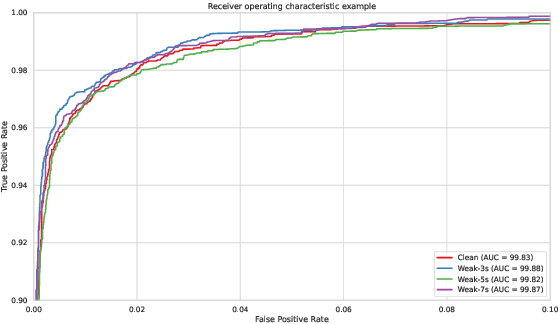
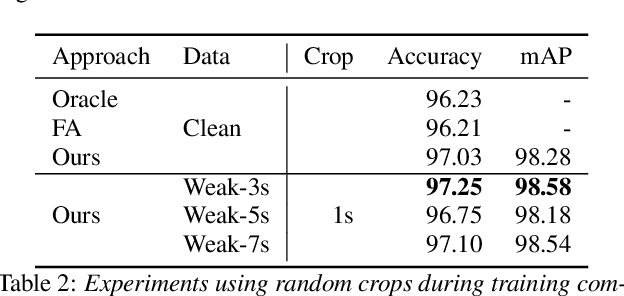
The currently most prominent algorithm to train keyword spotting (KWS) models with deep neural networks (DNNs) requires strong supervision i.e., precise knowledge of the spoken keyword location in time. Thus, most KWS approaches treat the presence of redundant data, such as noise, within their training set as an obstacle. A common training paradigm to deal with data redundancies is to use temporally weakly supervised learning, which only requires providing labels on a coarse scale. This study explores the limits of DNN training using temporally weak labeling with applications in KWS. We train a simple end-to-end classifier on the common Google Speech Commands dataset with increased difficulty by randomly appending and adding noise to the training dataset. Our results indicate that temporally weak labeling can achieve comparable results to strongly supervised baselines while having a less stringent labeling requirement. In the presence of noise, weakly supervised models are capable to localize and extract target keywords without explicit supervision, leading to a performance increase compared to strongly supervised approaches.
Hawkes Process Based on Controlled Differential Equations
May 18, 2023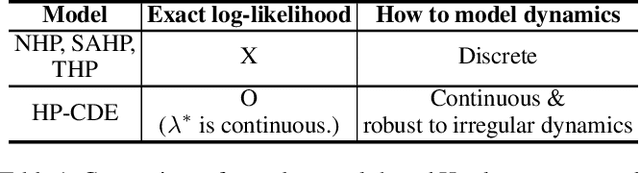
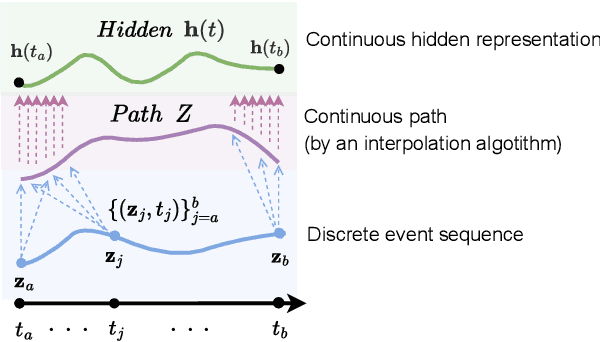
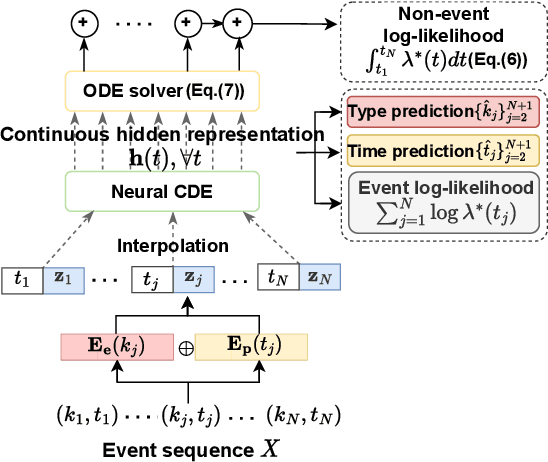
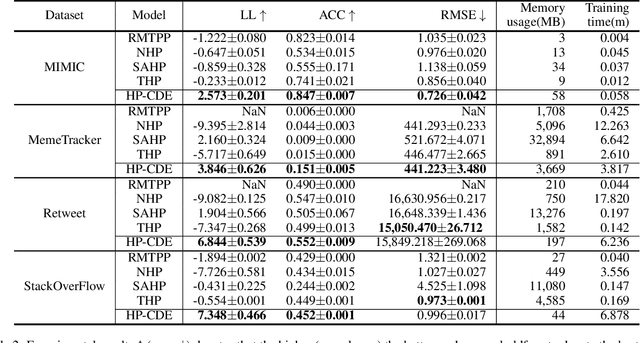
Hawkes processes are a popular framework to model the occurrence of sequential events, i.e., occurrence dynamics, in several fields such as social diffusion. In real-world scenarios, the inter-arrival time among events is irregular. However, existing neural network-based Hawkes process models not only i) fail to capture such complicated irregular dynamics, but also ii) resort to heuristics to calculate the log-likelihood of events since they are mostly based on neural networks designed for regular discrete inputs. To this end, we present the concept of Hawkes process based on controlled differential equations (HP-CDE), by adopting the neural controlled differential equation (neural CDE) technology which is an analogue to continuous RNNs. Since HP-CDE continuously reads data, i) irregular time-series datasets can be properly treated preserving their uneven temporal spaces, and ii) the log-likelihood can be exactly computed. Moreover, as both Hawkes processes and neural CDEs are first developed to model complicated human behavioral dynamics, neural CDE-based Hawkes processes are successful in modeling such occurrence dynamics. In our experiments with 4 real-world datasets, our method outperforms existing methods by non-trivial margins.
An ensemble of convolution-based methods for fault detection using vibration signals
May 05, 2023
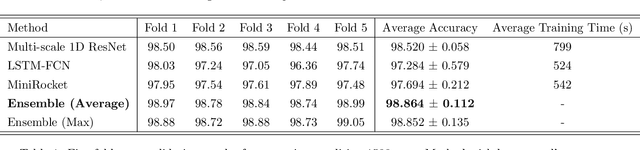
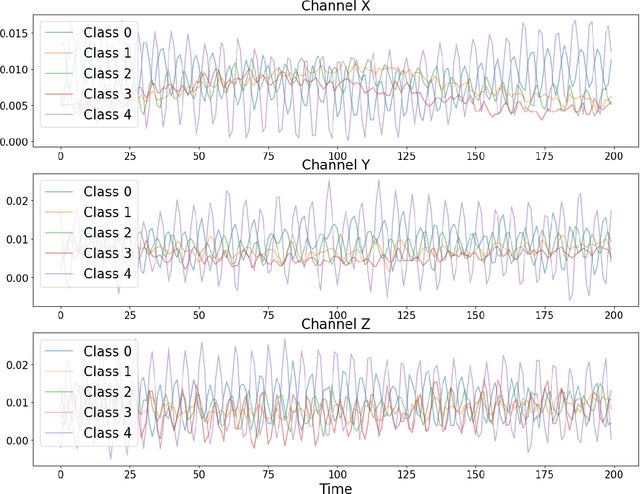
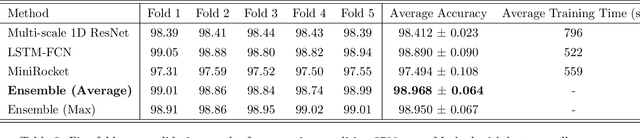
This paper focuses on solving a fault detection problem using multivariate time series of vibration signals collected from planetary gearboxes in a test rig. Various traditional machine learning and deep learning methods have been proposed for multivariate time-series classification, including distance-based, functional data-oriented, feature-driven, and convolution kernel-based methods. Recent studies have shown using convolution kernel-based methods like ROCKET, and 1D convolutional neural networks with ResNet and FCN, have robust performance for multivariate time-series data classification. We propose an ensemble of three convolution kernel-based methods and show its efficacy on this fault detection problem by outperforming other approaches and achieving an accuracy of more than 98.8\%.
Fast Anticipatory Motion Planning for Close-Proximity Human-Robot Interaction
May 19, 2023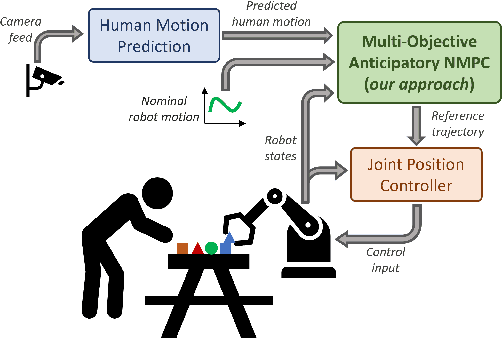
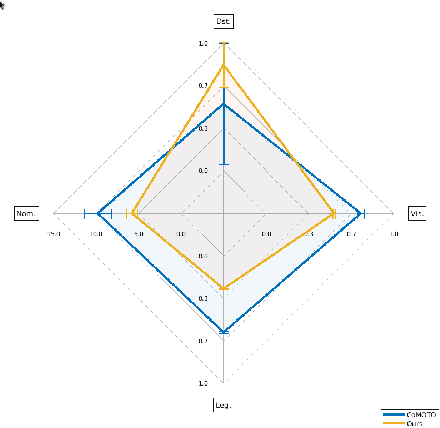
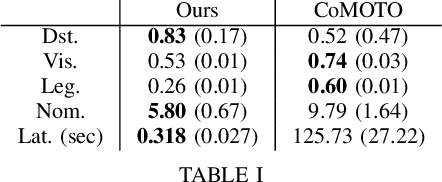
Effective close-proximity human-robot interaction (CP-HRI) requires robots to be able to both efficiently perform tasks as well as adapt to human behavior and preferences. However, this ability is mediated by many, sometimes competing, aspects of interaction. We propose a real-time motion-planning framework for robotic manipulators that can simultaneously optimize a set of both task- and human-centric cost functions. To this end, we formulate a Nonlinear Model-Predictive Control (NMPC) problem with kino-dynamic constraints and efficiently solve it by leveraging recent advances in nonlinear trajectory optimization. We employ stochastic predictions of the human partner's trajectories in order to adapt the robot's nominal behavior in anticipation of its human partner. Our framework explicitly models and allows balancing of different task- and human-centric cost functions. While previous approaches to trajectory optimization for CP-HRI take anywhere from several seconds to a full minute to compute a trajectory, our approach is capable of computing one in 318 ms on average, enabling real-time implementation. We illustrate the effectiveness of our framework by simultaneously optimizing for separation distance, end-effector visibility, legibility, smoothness, and deviation from nominal behavior. We also demonstrate that our approach performs comparably to prior work in terms of the chosen cost functions, while significantly improving computational efficiency.
Computation with Sequences in the Brain
Jun 06, 2023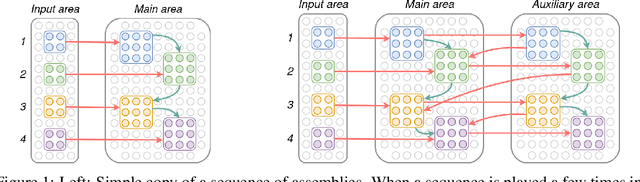
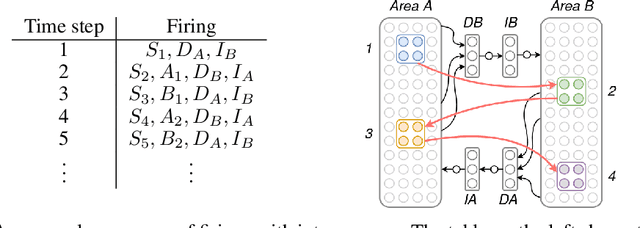
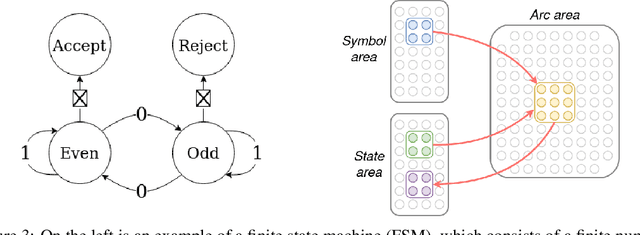
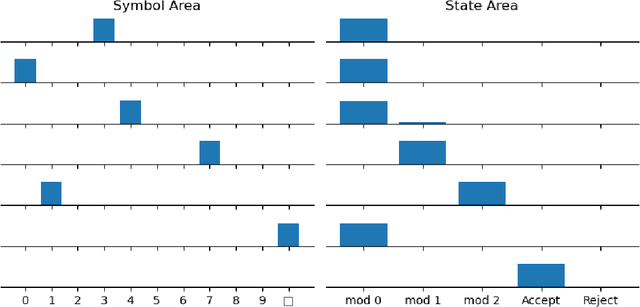
Even as machine learning exceeds human-level performance on many applications, the generality, robustness, and rapidity of the brain's learning capabilities remain unmatched. How cognition arises from neural activity is a central open question in neuroscience, inextricable from the study of intelligence itself. A simple formal model of neural activity was proposed in Papadimitriou [2020] and has been subsequently shown, through both mathematical proofs and simulations, to be capable of implementing certain simple cognitive operations via the creation and manipulation of assemblies of neurons. However, many intelligent behaviors rely on the ability to recognize, store, and manipulate temporal sequences of stimuli (planning, language, navigation, to list a few). Here we show that, in the same model, time can be captured naturally as precedence through synaptic weights and plasticity, and, as a result, a range of computations on sequences of assemblies can be carried out. In particular, repeated presentation of a sequence of stimuli leads to the memorization of the sequence through corresponding neural assemblies: upon future presentation of any stimulus in the sequence, the corresponding assembly and its subsequent ones will be activated, one after the other, until the end of the sequence. Finally, we show that any finite state machine can be learned in a similar way, through the presentation of appropriate patterns of sequences. Through an extension of this mechanism, the model can be shown to be capable of universal computation. We support our analysis with a number of experiments to probe the limits of learning in this model in key ways. Taken together, these results provide a concrete hypothesis for the basis of the brain's remarkable abilities to compute and learn, with sequences playing a vital role.