 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Most Language Models can be Poets too: An AI Writing Assistant and Constrained Text Generation Studio
Jun 28, 2023

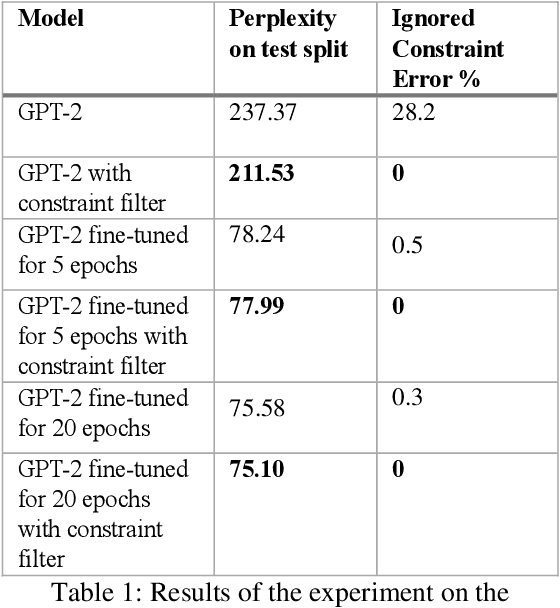
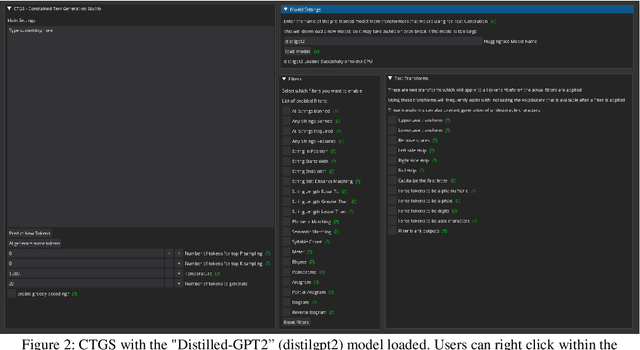
Despite rapid advancement in the field of Constrained Natural Language Generation, little time has been spent on exploring the potential of language models which have had their vocabularies lexically, semantically, and/or phonetically constrained. We find that most language models generate compelling text even under significant constraints. We present a simple and universally applicable technique for modifying the output of a language model by compositionally applying filter functions to the language models vocabulary before a unit of text is generated. This approach is plug-and-play and requires no modification to the model. To showcase the value of this technique, we present an easy to use AI writing assistant called Constrained Text Generation Studio (CTGS). CTGS allows users to generate or choose from text with any combination of a wide variety of constraints, such as banning a particular letter, forcing the generated words to have a certain number of syllables, and/or forcing the words to be partial anagrams of another word. We introduce a novel dataset of prose that omits the letter e. We show that our method results in strictly superior performance compared to fine-tuning alone on this dataset. We also present a Huggingface space web-app presenting this technique called Gadsby. The code is available to the public here: https://github.com/Hellisotherpeople/Constrained-Text-Generation-Studio
Deep Learning for Cancer Prognosis Prediction Using Portrait Photos by StyleGAN Embedding
Jun 28, 2023

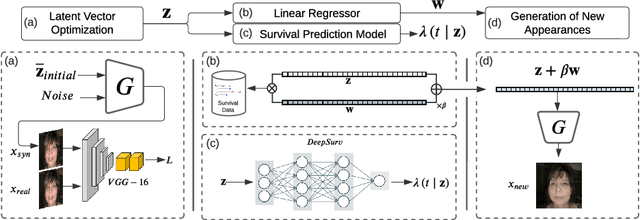

Survival prediction for cancer patients is critical for optimal treatment selection and patient management. Current patient survival prediction methods typically extract survival information from patients' clinical record data or biological and imaging data. In practice, experienced clinicians can have a preliminary assessment of patients' health status based on patients' observable physical appearances, which are mainly facial features. However, such assessment is highly subjective. In this work, the efficacy of objectively capturing and using prognostic information contained in conventional portrait photographs using deep learning for survival predication purposes is investigated for the first time. A pre-trained StyleGAN2 model is fine-tuned on a custom dataset of our cancer patients' photos to empower its generator with generative ability suitable for patients' photos. The StyleGAN2 is then used to embed the photographs to its highly expressive latent space. Utilizing the state-of-the-art survival analysis models and based on StyleGAN's latent space photo embeddings, this approach achieved a C-index of 0.677, which is notably higher than chance and evidencing the prognostic value embedded in simple 2D facial images. In addition, thanks to StyleGAN's interpretable latent space, our survival prediction model can be validated for relying on essential facial features, eliminating any biases from extraneous information like clothing or background. Moreover, a health attribute is obtained from regression coefficients, which has important potential value for patient care.
FuXi: A cascade machine learning forecasting system for 15-day global weather forecast
Jun 27, 2023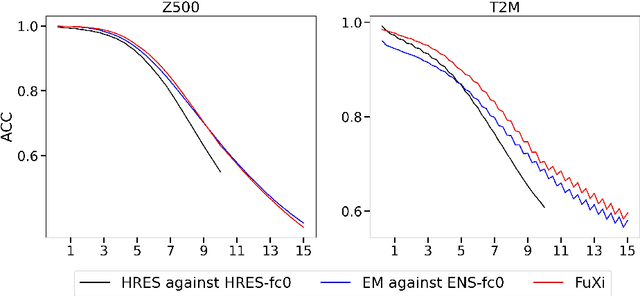
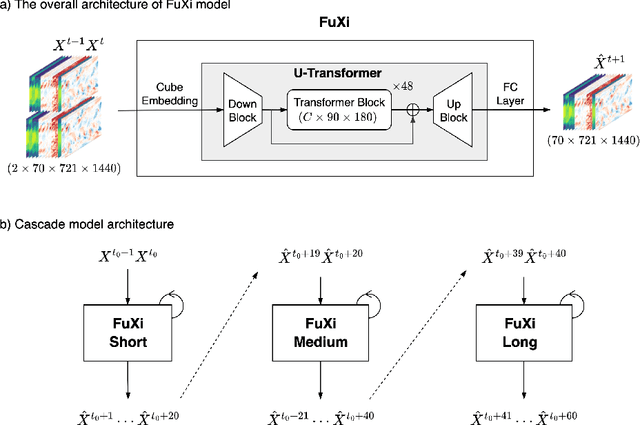
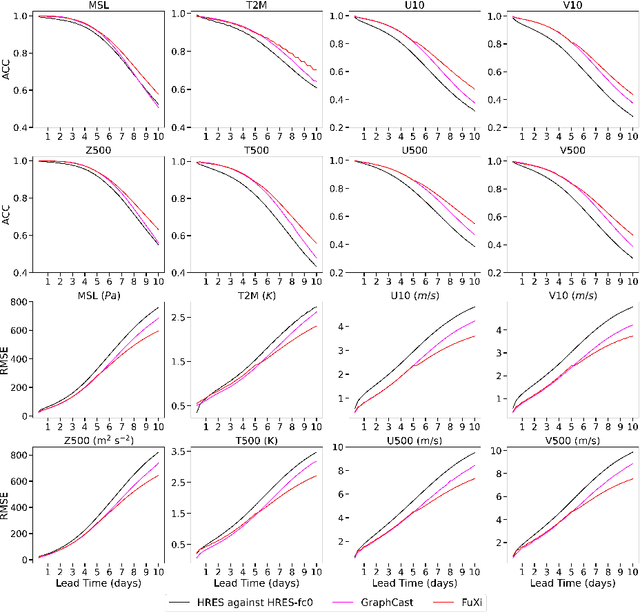
Over the past few years, due to the rapid development of machine learning (ML) models for weather forecasting, state-of-the-art ML models have shown superior performance compared to the European Centre for Medium-Range Weather Forecasts (ECMWF)'s high-resolution forecast (HRES) in 10-day forecasts at a spatial resolution of 0.25 degree. However, the challenge remains to perform comparably to the ECMWF ensemble mean (EM) in 15-day forecasts. Previous studies have demonstrated the importance of mitigating the accumulation of forecast errors for effective long-term forecasts. Despite numerous efforts to reduce accumulation errors, including autoregressive multi-time step loss, using a single model is found to be insufficient to achieve optimal performance in both short and long lead times. Therefore, we present FuXi, a cascaded ML weather forecasting system that provides 15-day global forecasts with a temporal resolution of 6 hours and a spatial resolution of 0.25 degree. FuXi is developed using 39 years of the ECMWF ERA5 reanalysis dataset. The performance evaluation, based on latitude-weighted root mean square error (RMSE) and anomaly correlation coefficient (ACC), demonstrates that FuXi has comparable forecast performance to ECMWF EM in 15-day forecasts, making FuXi the first ML-based weather forecasting system to accomplish this achievement.
FBA-Net: Foreground and Background Aware Contrastive Learning for Semi-Supervised Atrium Segmentation
Jun 27, 2023Medical image segmentation of gadolinium enhancement magnetic resonance imaging (GE MRI) is an important task in clinical applications. However, manual annotation is time-consuming and requires specialized expertise. Semi-supervised segmentation methods that leverage both labeled and unlabeled data have shown promise, with contrastive learning emerging as a particularly effective approach. In this paper, we propose a contrastive learning strategy of foreground and background representations for semi-supervised 3D medical image segmentation (FBA-Net). Specifically, we leverage the contrastive loss to learn representations of both the foreground and background regions in the images. By training the network to distinguish between foreground-background pairs, we aim to learn a representation that can effectively capture the anatomical structures of interest. Experiments on three medical segmentation datasets demonstrate state-of-the-art performance. Notably, our method achieves a Dice score of 91.31% with only 20% labeled data, which is remarkably close to the 91.62% score of the fully supervised method that uses 100% labeled data on the left atrium dataset. Our framework has the potential to advance the field of semi-supervised 3D medical image segmentation and enable more efficient and accurate analysis of medical images with a limited amount of annotated labels.
FLuRKA: Fast fused Low-Rank & Kernel Attention
Jun 27, 2023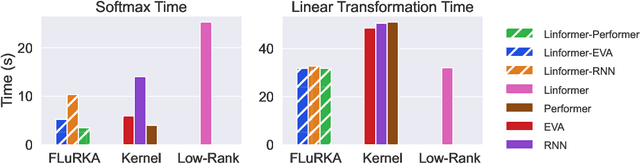
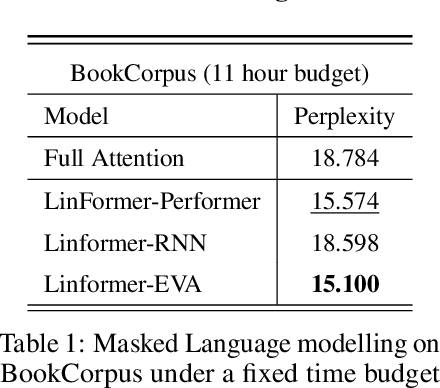
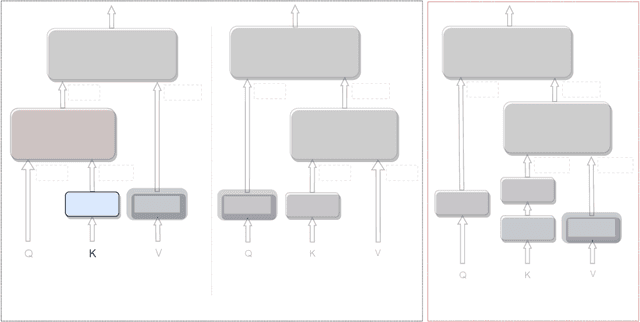
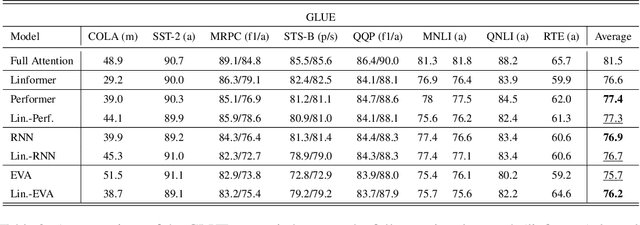
Many efficient approximate self-attention techniques have become prevalent since the inception of the transformer architecture. Two popular classes of these techniques are low-rank and kernel methods. Each of these methods has its own strengths. We observe these strengths synergistically complement each other and exploit these synergies to fuse low-rank and kernel methods, producing a new class of transformers: FLuRKA (Fast Low-Rank and Kernel Attention). FLuRKA provide sizable performance gains over these approximate techniques and are of high quality. We theoretically and empirically evaluate both the runtime performance and quality of FLuRKA. Our runtime analysis posits a variety of parameter configurations where FLuRKA exhibit speedups and our accuracy analysis bounds the error of FLuRKA with respect to full-attention. We instantiate three FLuRKA variants which experience empirical speedups of up to 3.3x and 1.7x over low-rank and kernel methods respectively. This translates to speedups of up to 30x over models with full-attention. With respect to model quality, FLuRKA can match the accuracy of low-rank and kernel methods on GLUE after pre-training on wiki-text 103. When pre-training on a fixed time budget, FLuRKA yield better perplexity scores than models with full-attention.
Methodology for Jointly Assessing Myocardial Infarct Extent and Regional Contraction in 3-D CMRI
Jun 27, 2023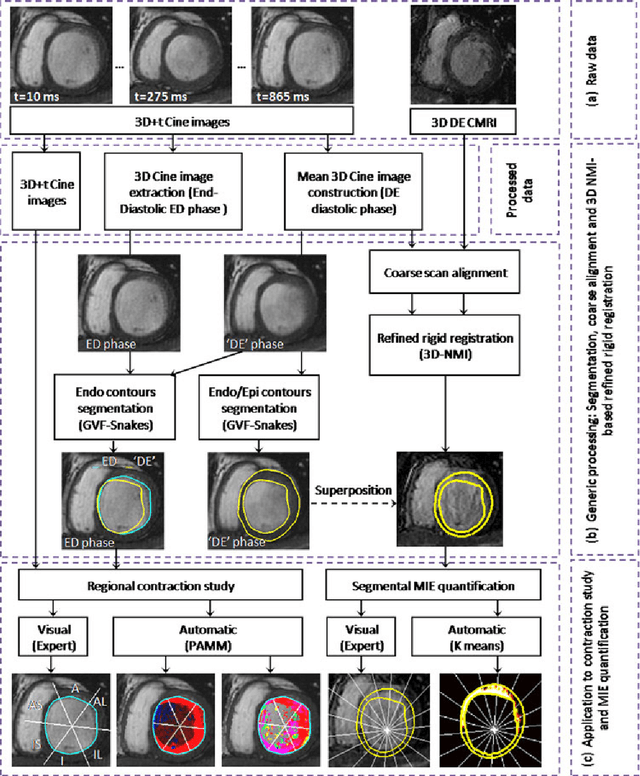
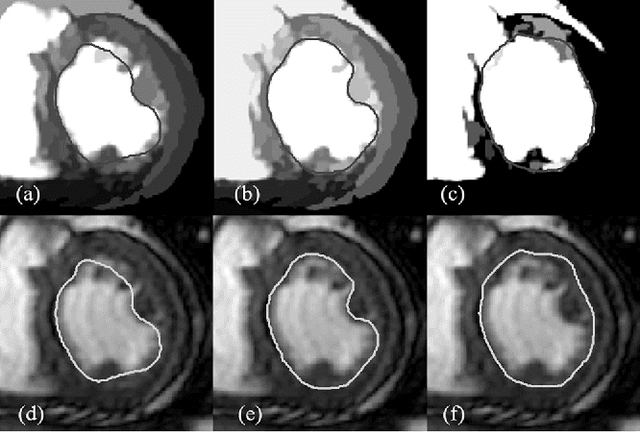
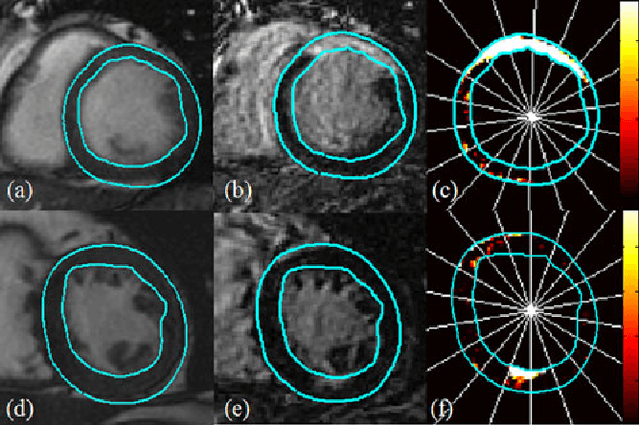
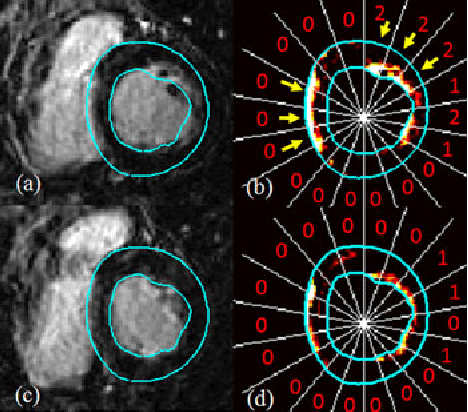
Automated extraction of quantitative parameters from Cardiac Magnetic Resonance Images (CMRI) is crucial for the management of patients with myocardial infarct. This work proposes a post-processing procedure to jointly analyze Cine and Delayed-Enhanced (DE) acquisitions in order to provide an automatic quantification of myocardial contraction and enhancement parameters and a study of their relationship. For that purpose, the following processes are performed: 1) DE/Cine temporal synchronization and 3D scan alignment, 2) 3D DE/Cine rigid registration in a region about the heart, 3) segmentation of the myocardium on Cine MRI and superimposition of the epicardial and endocardial contours on the DE images, 4) quantification of the Myocardial Infarct Extent (MIE), 5) study of the regional contractile function using a new index, the Amplitude to Time Ratio (ATR). The whole procedure was applied to 10 patients with clinically proven myocardial infarction. The comparison between the MIE and the visually assessed regional function scores demonstrated that the MIE is highly related to the severity of the wall motion abnormality. In addition, it was shown that the newly developed regional myocardial contraction parameter (ATR) decreases significantly in delayed enhanced regions. This largely automated approach enables a combined study of regional MIE and left ventricular function.
Efficiently Using Polar Codes in 5G Base Stations to Enhance Rural Connectivity
Jun 27, 2023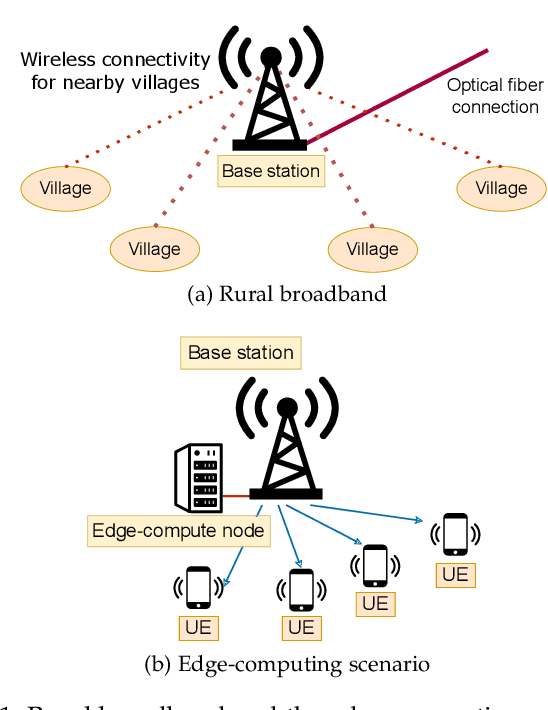
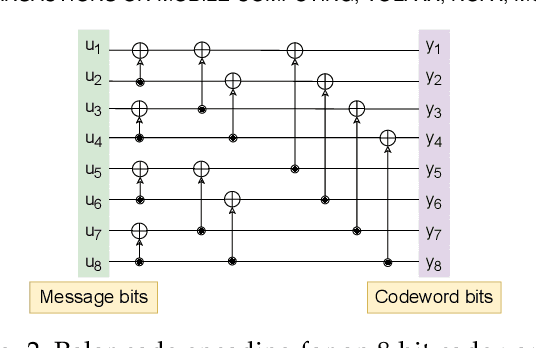
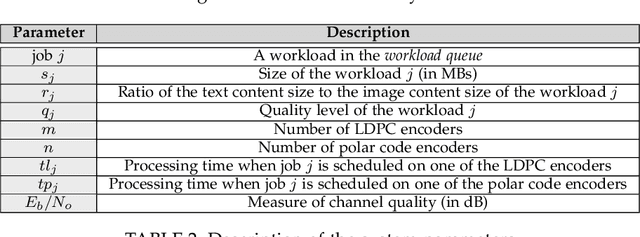
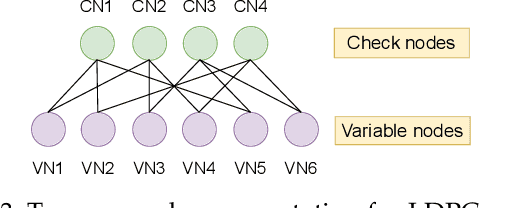
5G connectivity has become essential to integrate rural communities into the broader digital economy and support critical applications like remote education and remote surgery. A major hindrance to expanding rural broadband coverage, especially in developing countries, is the high cost of installing 5G base stations. Hence, there is a need to reduce the cost of a 5G base station without degrading its performance. Our work proposes a novel approach to efficiently utilize the polar code encoders in a 5G base station. The idea is to use the idle time of the polar encoders during downlink transmission for error correction in the 5G data plane. Polar codes have conventionally been used in the 5G control plane, while LDPC codes are used in the data plane. We perform detailed characterization experiments to show the advantages of using polar codes in the data plane as well. Further, to intelligently distribute the user data packets among the available compute nodes, we propose a set of novel resource allocation algorithms and compare their performance with other algorithms in the literature. Using our proposed optimization techniques, we achieve a 17% reduction in the cost of a 5G base station. Simultaneously, we are able to improve the performance by 24% compared to a conventional base station.
FedET: A Communication-Efficient Federated Class-Incremental Learning Framework Based on Enhanced Transformer
Jun 27, 2023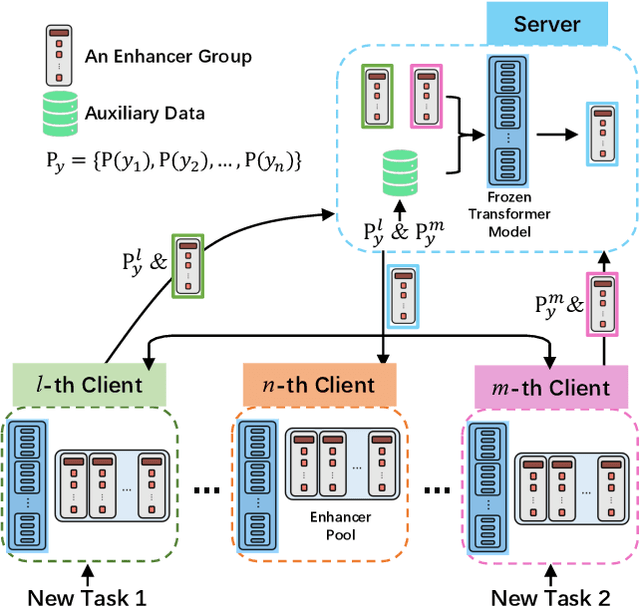
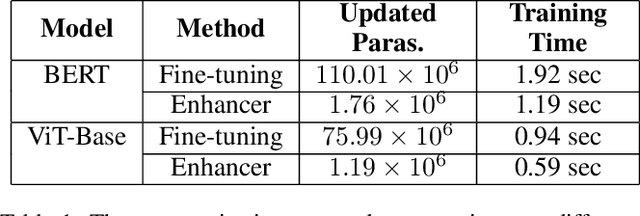

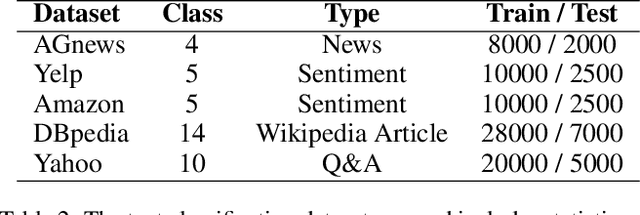
Federated Learning (FL) has been widely concerned for it enables decentralized learning while ensuring data privacy. However, most existing methods unrealistically assume that the classes encountered by local clients are fixed over time. After learning new classes, this assumption will make the model's catastrophic forgetting of old classes significantly severe. Moreover, due to the limitation of communication cost, it is challenging to use large-scale models in FL, which will affect the prediction accuracy. To address these challenges, we propose a novel framework, Federated Enhanced Transformer (FedET), which simultaneously achieves high accuracy and low communication cost. Specifically, FedET uses Enhancer, a tiny module, to absorb and communicate new knowledge, and applies pre-trained Transformers combined with different Enhancers to ensure high precision on various tasks. To address local forgetting caused by new classes of new tasks and global forgetting brought by non-i.i.d (non-independent and identically distributed) class imbalance across different local clients, we proposed an Enhancer distillation method to modify the imbalance between old and new knowledge and repair the non-i.i.d. problem. Experimental results demonstrate that FedET's average accuracy on representative benchmark datasets is 14.1% higher than the state-of-the-art method, while FedET saves 90% of the communication cost compared to the previous method.
Audio Tagging on an Embedded Hardware Platform
Jun 15, 2023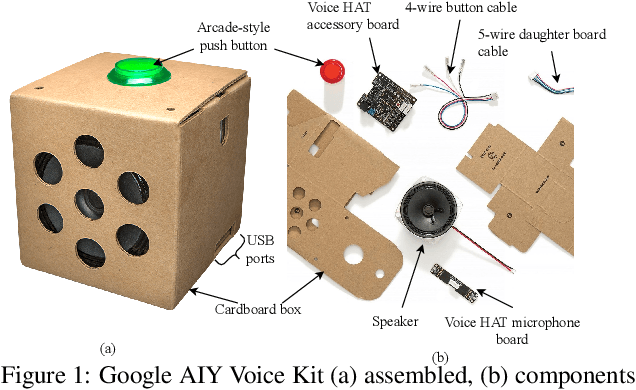
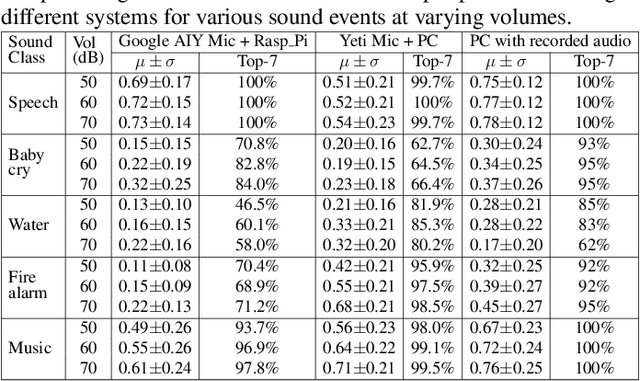

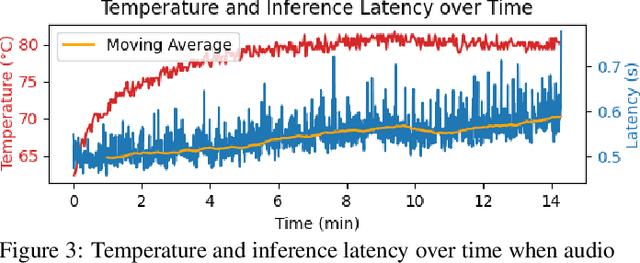
Convolutional neural networks (CNNs) have exhibited state-of-the-art performance in various audio classification tasks. However, their real-time deployment remains a challenge on resource-constrained devices like embedded systems. In this paper, we analyze how the performance of large-scale pretrained audio neural networks designed for audio pattern recognition changes when deployed on a hardware such as Raspberry Pi. We empirically study the role of CPU temperature, microphone quality and audio signal volume on performance. Our experiments reveal that the continuous CPU usage results in an increased temperature that can trigger an automated slowdown mechanism in the Raspberry Pi, impacting inference latency. The quality of a microphone, specifically with affordable devices like the Google AIY Voice Kit, and audio signal volume, all affect the system performance. In the course of our investigation, we encounter substantial complications linked to library compatibility and the unique processor architecture requirements of the Raspberry Pi, making the process less straightforward compared to conventional computers (PCs). Our observations, while presenting challenges, pave the way for future researchers to develop more compact machine learning models, design heat-dissipative hardware, and select appropriate microphones when AI models are deployed for real-time applications on edge devices. All related assets and an interactive demo can be found on GitHub
Autoencoding for the 'Good Dictionary' of eigen pairs of the Koopman Operator
Jun 08, 2023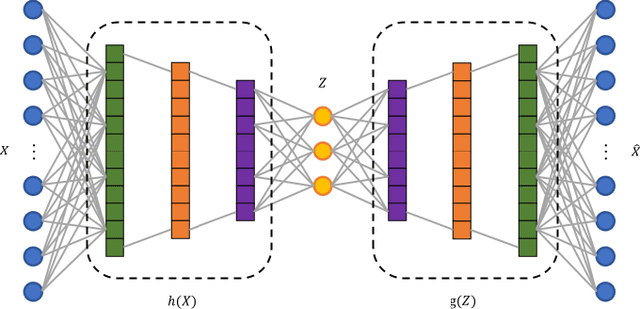
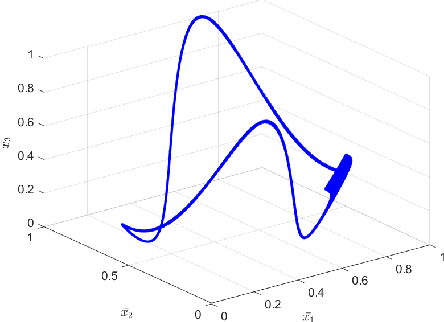
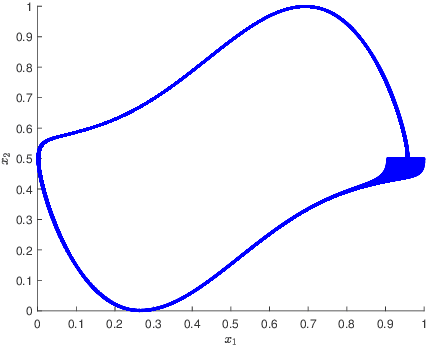
Reduced order modelling relies on representing complex dynamical systems using simplified modes, which can be achieved through Koopman operator analysis. However, computing Koopman eigen pairs for high-dimensional observable data can be inefficient. This paper proposes using deep autoencoders, a type of deep learning technique, to perform non-linear geometric transformations on raw data before computing Koopman eigen vectors. The encoded data produced by the deep autoencoder is diffeomorphic to a manifold of the dynamical system, and has a significantly lower dimension than the raw data. To handle high-dimensional time series data, Takens's time delay embedding is presented as a pre-processing technique. The paper concludes by presenting examples of these techniques in action.