 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Last-Iterate Convergent Policy Gradient Primal-Dual Methods for Constrained MDPs
Jun 20, 2023
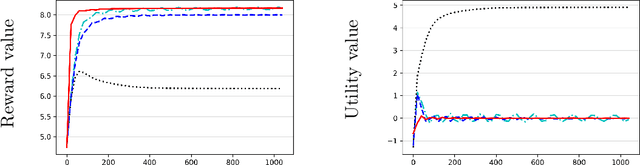
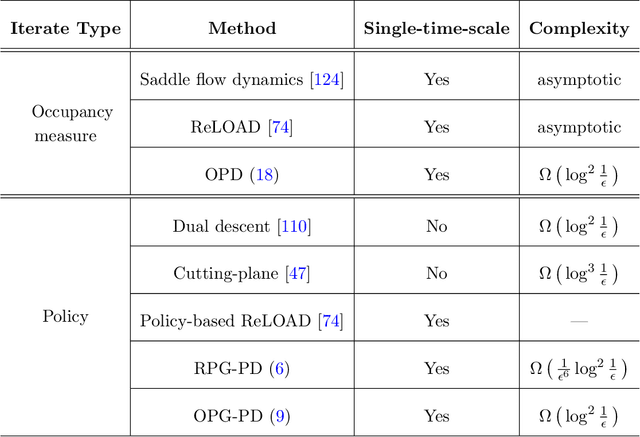
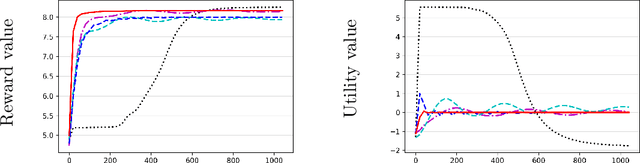
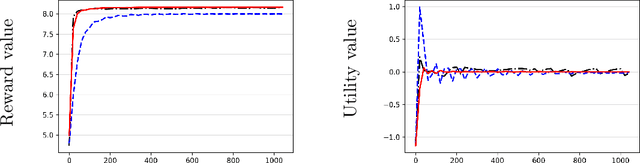
We study the problem of computing an optimal policy of an infinite-horizon discounted constrained Markov decision process (constrained MDP). Despite the popularity of Lagrangian-based policy search methods used in practice, the oscillation of policy iterates in these methods has not been fully understood, bringing out issues such as violation of constraints and sensitivity to hyper-parameters. To fill this gap, we employ the Lagrangian method to cast a constrained MDP into a constrained saddle-point problem in which max/min players correspond to primal/dual variables, respectively, and develop two single-time-scale policy-based primal-dual algorithms with non-asymptotic convergence of their policy iterates to an optimal constrained policy. Specifically, we first propose a regularized policy gradient primal-dual (RPG-PD) method that updates the policy using an entropy-regularized policy gradient, and the dual via a quadratic-regularized gradient ascent, simultaneously. We prove that the policy primal-dual iterates of RPG-PD converge to a regularized saddle point with a sublinear rate, while the policy iterates converge sublinearly to an optimal constrained policy. We further instantiate RPG-PD in large state or action spaces by including function approximation in policy parametrization, and establish similar sublinear last-iterate policy convergence. Second, we propose an optimistic policy gradient primal-dual (OPG-PD) method that employs the optimistic gradient method to update primal/dual variables, simultaneously. We prove that the policy primal-dual iterates of OPG-PD converge to a saddle point that contains an optimal constrained policy, with a linear rate. To the best of our knowledge, this work appears to be the first non-asymptotic policy last-iterate convergence result for single-time-scale algorithms in constrained MDPs.
A Novel Neural Network Approach for Predicting the Arrival Time of Buses for Smart On-Demand Public Transit
Mar 27, 2023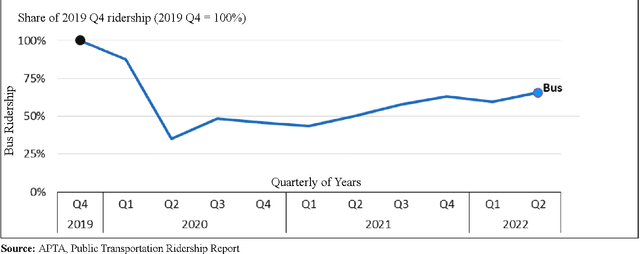
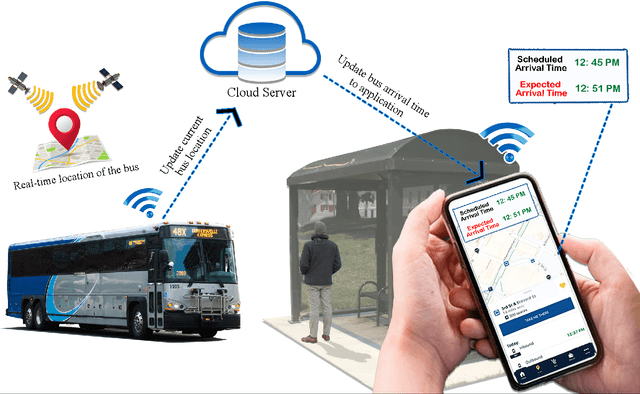
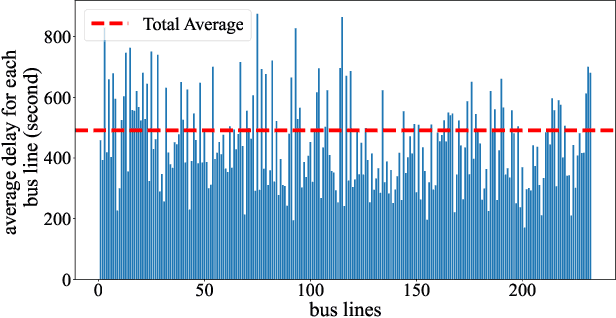
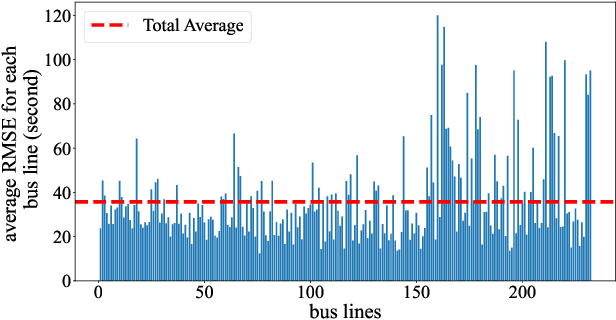
Among the major public transportation systems in cities, bus transit has its problems, including more accuracy and reliability when estimating the bus arrival time for riders. This can lead to delays and decreased ridership, especially in cities where public transportation is heavily relied upon. A common issue is that the arrival times of buses do not match the schedules, resulting in latency for fixed schedules. According to the study in this paper on New York City bus data, there is an average delay of around eight minutes or 491 seconds mismatch between the bus arrivals and the actual scheduled time. This research paper presents a novel AI-based data-driven approach for estimating the arrival times of buses at each transit point (station). Our approach is based on a fully connected neural network and can predict the arrival time collectively across all bus lines in large metropolitan areas. Our neural-net data-driven approach provides a new way to estimate the arrival time of the buses, which can lead to a more efficient and smarter way to bring the bus transit to the general public. Our evaluation of the network bus system with more than 200 bus lines, and 2 million data points, demonstrates less than 40 seconds of estimated error for arrival times. The inference time per each validation set data point is less than 0.006 ms.
AV-SepFormer: Cross-Attention SepFormer for Audio-Visual Target Speaker Extraction
Jun 25, 2023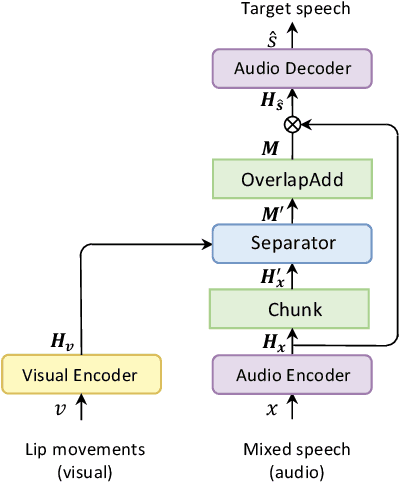

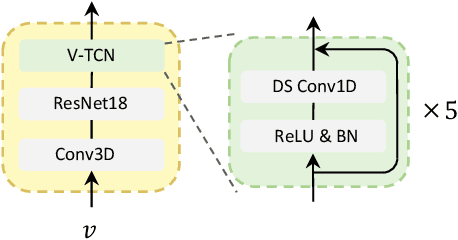

Visual information can serve as an effective cue for target speaker extraction (TSE) and is vital to improving extraction performance. In this paper, we propose AV-SepFormer, a SepFormer-based attention dual-scale model that utilizes cross- and self-attention to fuse and model features from audio and visual. AV-SepFormer splits the audio feature into a number of chunks, equivalent to the length of the visual feature. Then self- and cross-attention are employed to model and fuse the multi-modal features. Furthermore, we use a novel 2D positional encoding, that introduces the positional information between and within chunks and provides significant gains over the traditional positional encoding. Our model has two key advantages: the time granularity of audio chunked feature is synchronized to the visual feature, which alleviates the harm caused by the inconsistency of audio and video sampling rate; by combining self- and cross-attention, feature fusion and speech extraction processes are unified within an attention paradigm. The experimental results show that AV-SepFormer significantly outperforms other existing methods.
A Framework for dynamically meeting performance objectives on a service mesh
Jun 25, 2023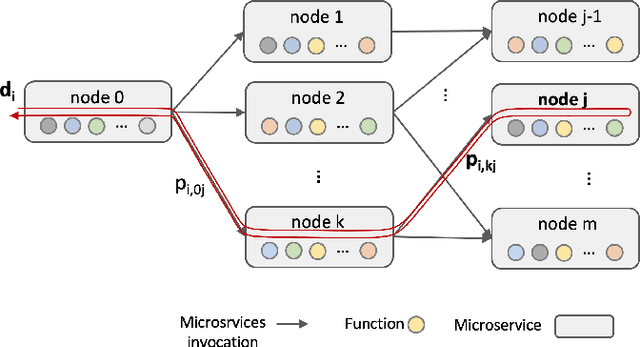
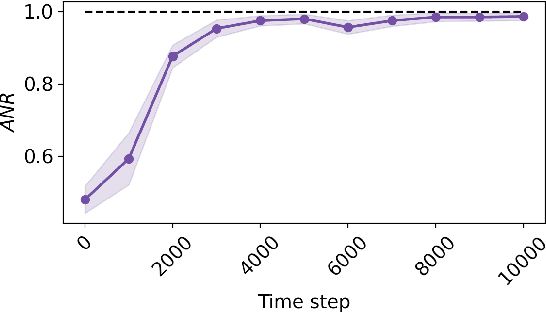
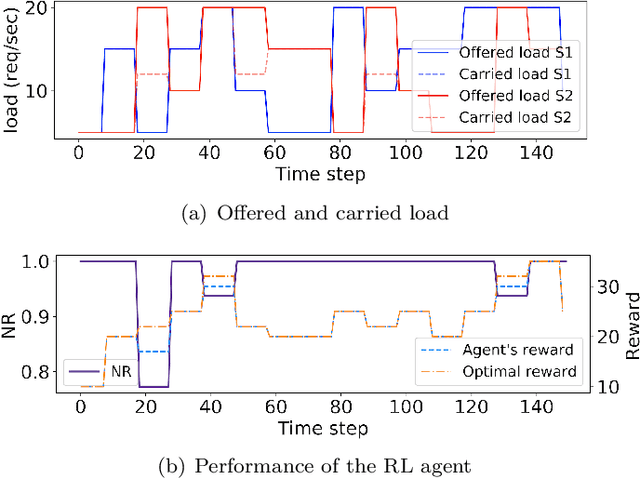
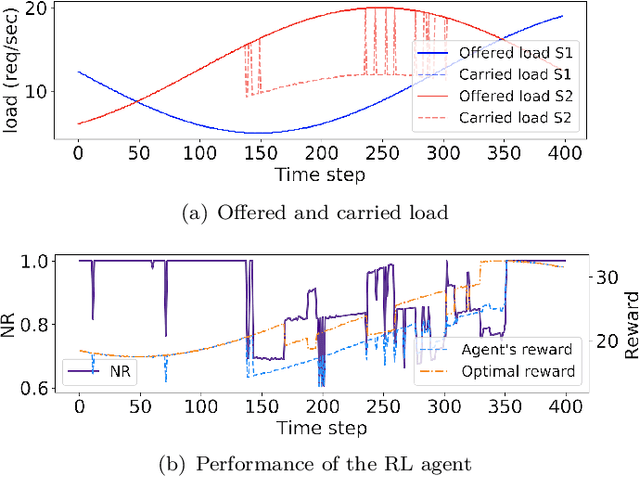
We present a framework for achieving end-to-end management objectives for multiple services that concurrently execute on a service mesh. We apply reinforcement learning (RL) techniques to train an agent that periodically performs control actions to reallocate resources. We develop and evaluate the framework using a laboratory testbed where we run information and computing services on a service mesh, supported by the Istio and Kubernetes platforms. We investigate different management objectives that include end-to-end delay bounds on service requests, throughput objectives, cost-related objectives, and service differentiation. We compute the control policies on a simulator rather than on the testbed, which speeds up the training time by orders of magnitude for the scenarios we study. Our proposed framework is novel in that it advocates a top-down approach whereby the management objectives are defined first and then mapped onto the available control actions. It allows us to execute several types of control actions simultaneously. By first learning the system model and the operating region from testbed traces, we can train the agent for different management objectives in parallel.
SpATr: MoCap 3D Human Action Recognition based on Spiral Auto-encoder and Transformer Network
Jun 30, 2023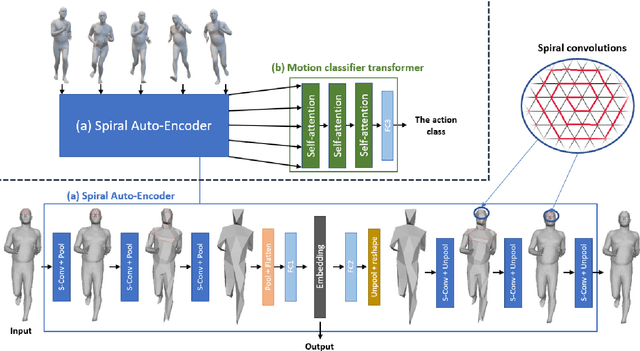
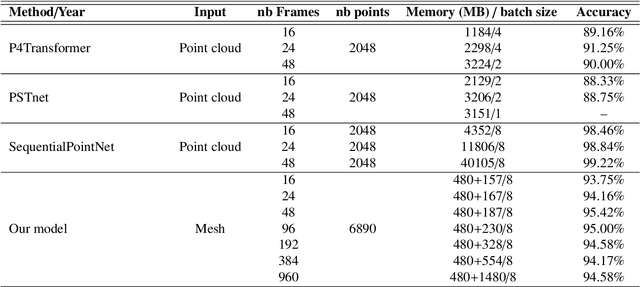
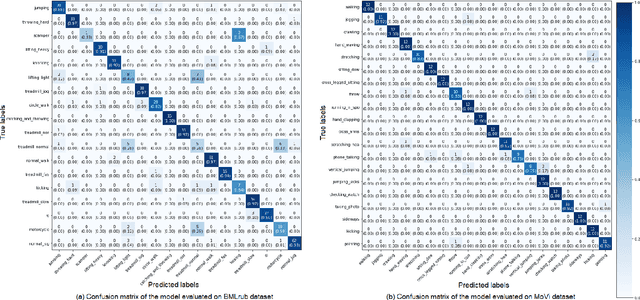
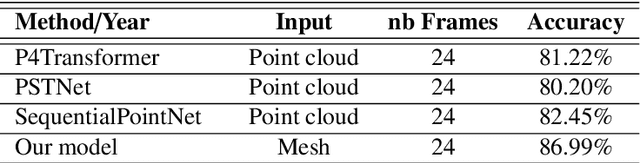
Recent advancements in technology have expanded the possibilities of human action recognition by leveraging 3D data, which offers a richer representation of actions through the inclusion of depth information, enabling more accurate analysis of spatial and temporal characteristics. However, 3D human action recognition is a challenging task due to the irregularity and Disarrangement of the data points in action sequences. In this context, we present our novel model for human action recognition from fixed topology mesh sequences based on Spiral Auto-encoder and Transformer Network, namely SpATr. The proposed method first disentangles space and time in the mesh sequences. Then, an auto-encoder is utilized to extract spatial geometrical features, and tiny transformer is used to capture the temporal evolution of the sequence. Previous methods either use 2D depth images, sample skeletons points or they require a huge amount of memory leading to the ability to process short sequences only. In this work, we show competitive recognition rate and high memory efficiency by building our auto-encoder based on spiral convolutions, which are light weight convolution directly applied to mesh data with fixed topologies, and by modeling temporal evolution using a attention, that can handle large sequences. The proposed method is evaluated on on two 3D human action datasets: MoVi and BMLrub from the Archive of Motion Capture As Surface Shapes (AMASS). The results analysis shows the effectiveness of our method in 3D human action recognition while maintaining high memory efficiency. The code will soon be made publicly available.
Harnessing LLMs in Curricular Design: Using GPT-4 to Support Authoring of Learning Objectives
Jun 30, 2023

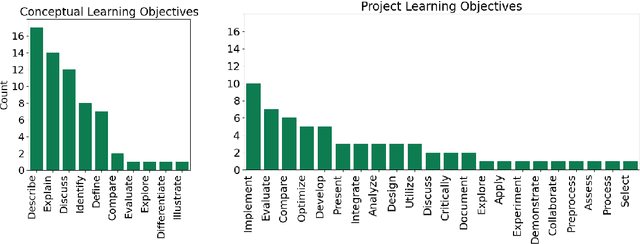
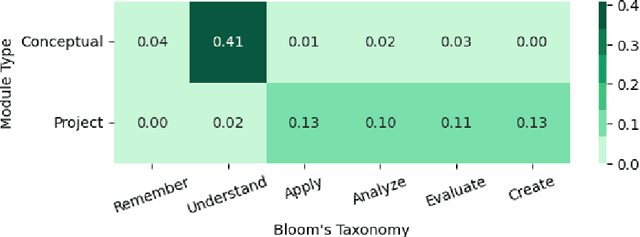
We evaluated the capability of a generative pre-trained transformer (GPT-4) to automatically generate high-quality learning objectives (LOs) in the context of a practically oriented university course on Artificial Intelligence. Discussions of opportunities (e.g., content generation, explanation) and risks (e.g., cheating) of this emerging technology in education have intensified, but to date there has not been a study of the models' capabilities in supporting the course design and authoring of LOs. LOs articulate the knowledge and skills learners are intended to acquire by engaging with a course. To be effective, LOs must focus on what students are intended to achieve, focus on specific cognitive processes, and be measurable. Thus, authoring high-quality LOs is a challenging and time consuming (i.e., expensive) effort. We evaluated 127 LOs that were automatically generated based on a carefully crafted prompt (detailed guidelines on high-quality LOs authoring) submitted to GPT-4 for conceptual modules and projects of an AI Practitioner course. We analyzed the generated LOs if they follow certain best practices such as beginning with action verbs from Bloom's taxonomy in regards to the level of sophistication intended. Our analysis showed that the generated LOs are sensible, properly expressed (e.g., starting with an action verb), and that they largely operate at the appropriate level of Bloom's taxonomy, respecting the different nature of the conceptual modules (lower levels) and projects (higher levels). Our results can be leveraged by instructors and curricular designers wishing to take advantage of the state-of-the-art generative models to support their curricular and course design efforts.
User-defined Event Sampling and Uncertainty Quantification in Diffusion Models for Physical Dynamical Systems
Jun 13, 2023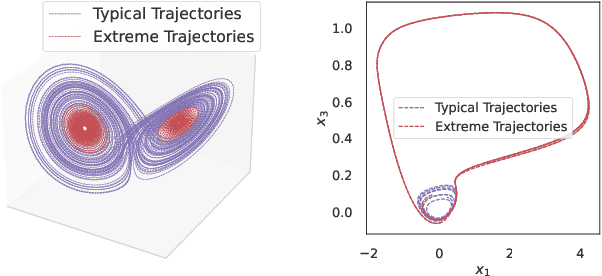
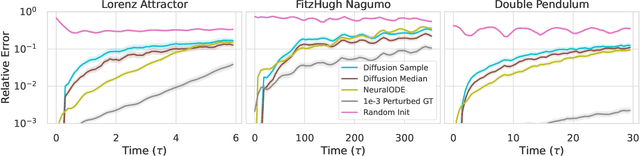
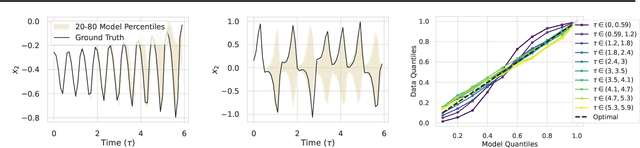
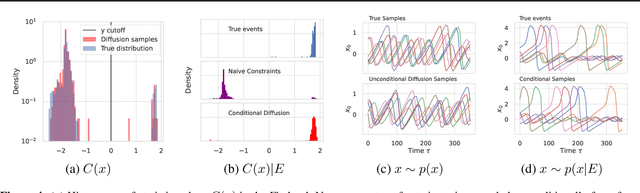
Diffusion models are a class of probabilistic generative models that have been widely used as a prior for image processing tasks like text conditional generation and inpainting. We demonstrate that these models can be adapted to make predictions and provide uncertainty quantification for chaotic dynamical systems. In these applications, diffusion models can implicitly represent knowledge about outliers and extreme events; however, querying that knowledge through conditional sampling or measuring probabilities is surprisingly difficult. Existing methods for conditional sampling at inference time seek mainly to enforce the constraints, which is insufficient to match the statistics of the distribution or compute the probability of the chosen events. To achieve these ends, optimally one would use the conditional score function, but its computation is typically intractable. In this work, we develop a probabilistic approximation scheme for the conditional score function which provably converges to the true distribution as the noise level decreases. With this scheme we are able to sample conditionally on nonlinear userdefined events at inference time, and matches data statistics even when sampling from the tails of the distribution.
Lingua Manga: A Generic Large Language Model Centric System for Data Curation
Jun 20, 2023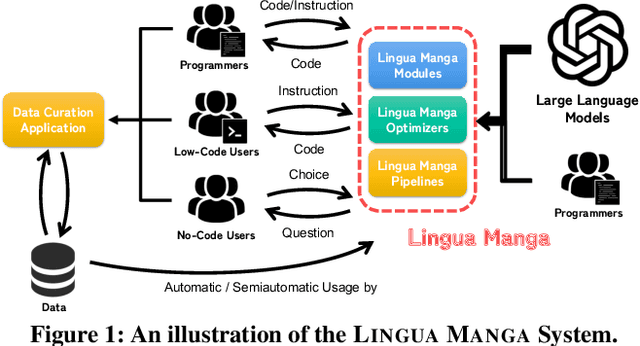
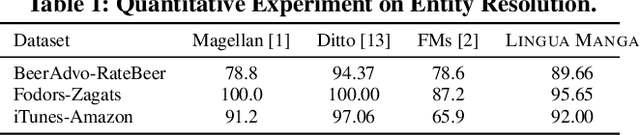
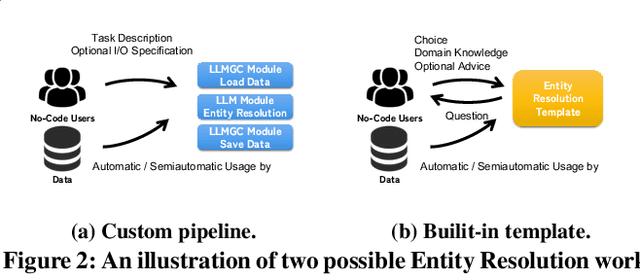
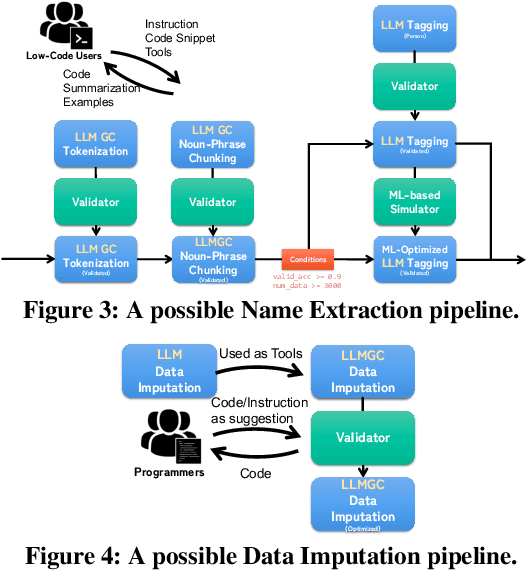
Data curation is a wide-ranging area which contains many critical but time-consuming data processing tasks. However, the diversity of such tasks makes it challenging to develop a general-purpose data curation system. To address this issue, we present Lingua Manga, a user-friendly and versatile system that utilizes pre-trained large language models. Lingua Manga offers automatic optimization for achieving high performance and label efficiency while facilitating flexible and rapid development. Through three example applications with distinct objectives and users of varying levels of technical proficiency, we demonstrate that Lingua Manga can effectively assist both skilled programmers and low-code or even no-code users in addressing data curation challenges.
A Protocol for Continual Explanation of SHAP
Jun 20, 2023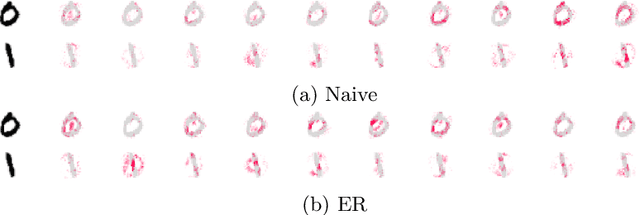
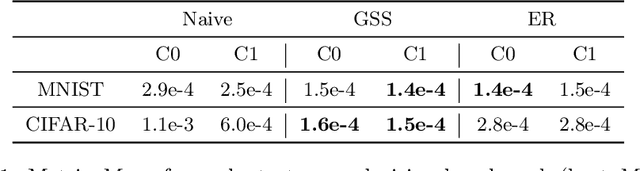
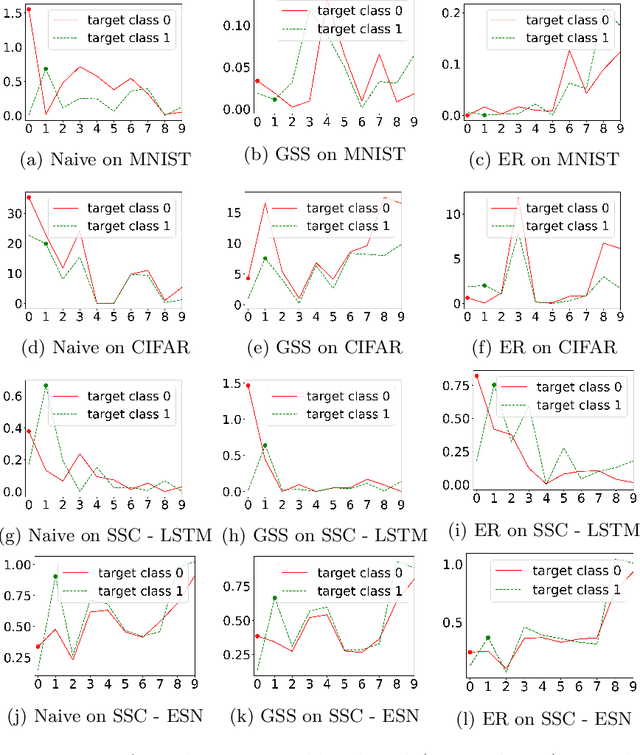
Continual Learning trains models on a stream of data, with the aim of learning new information without forgetting previous knowledge. Given the dynamic nature of such environments, explaining the predictions of these models can be challenging. We study the behavior of SHAP values explanations in Continual Learning and propose an evaluation protocol to robustly assess the change of explanations in Class-Incremental scenarios. We observed that, while Replay strategies enforce the stability of SHAP values in feedforward/convolutional models, they are not able to do the same with fully-trained recurrent models. We show that alternative recurrent approaches, like randomized recurrent models, are more effective in keeping the explanations stable over time.
BEDLAM: A Synthetic Dataset of Bodies Exhibiting Detailed Lifelike Animated Motion
Jun 29, 2023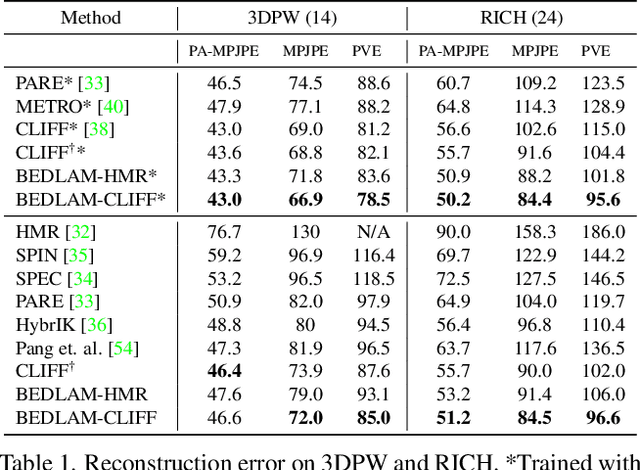

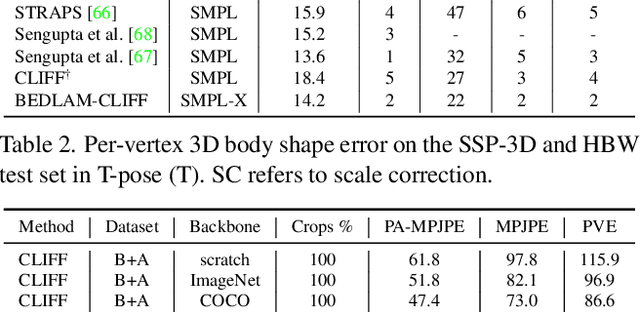

We show, for the first time, that neural networks trained only on synthetic data achieve state-of-the-art accuracy on the problem of 3D human pose and shape (HPS) estimation from real images. Previous synthetic datasets have been small, unrealistic, or lacked realistic clothing. Achieving sufficient realism is non-trivial and we show how to do this for full bodies in motion. Specifically, our BEDLAM dataset contains monocular RGB videos with ground-truth 3D bodies in SMPL-X format. It includes a diversity of body shapes, motions, skin tones, hair, and clothing. The clothing is realistically simulated on the moving bodies using commercial clothing physics simulation. We render varying numbers of people in realistic scenes with varied lighting and camera motions. We then train various HPS regressors using BEDLAM and achieve state-of-the-art accuracy on real-image benchmarks despite training with synthetic data. We use BEDLAM to gain insights into what model design choices are important for accuracy. With good synthetic training data, we find that a basic method like HMR approaches the accuracy of the current SOTA method (CLIFF). BEDLAM is useful for a variety of tasks and all images, ground truth bodies, 3D clothing, support code, and more are available for research purposes. Additionally, we provide detailed information about our synthetic data generation pipeline, enabling others to generate their own datasets. See the project page: https://bedlam.is.tue.mpg.de/.