 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving Speech Translation Accuracy and Time Efficiency with Fine-tuned wav2vec 2.0-based Speech Segmentation
Apr 25, 2023
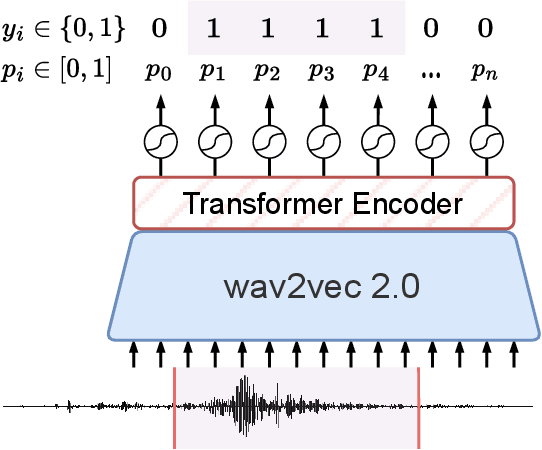
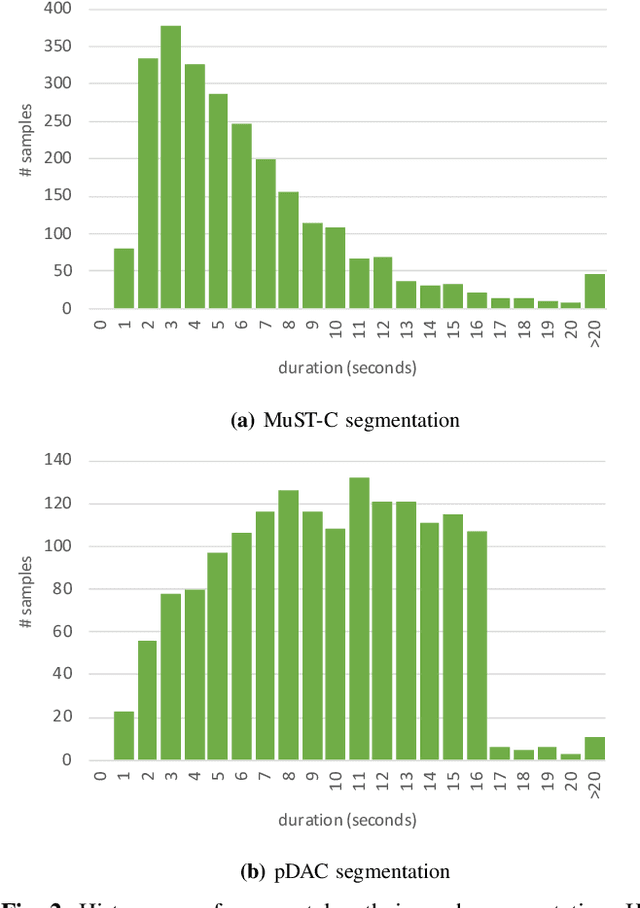
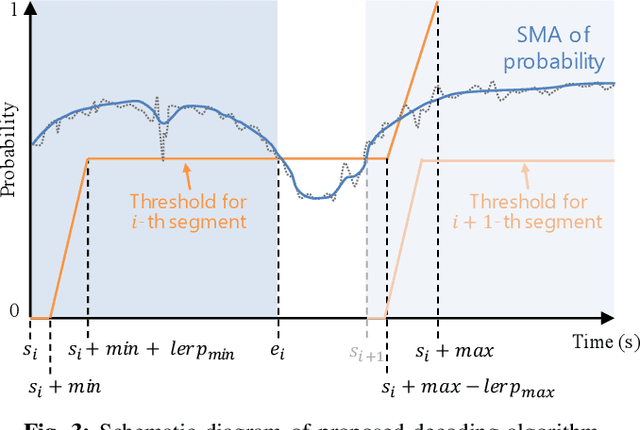
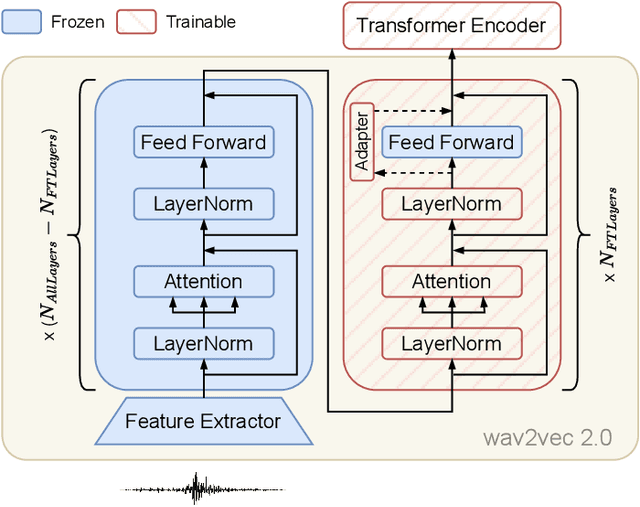
Speech translation (ST) automatically converts utterances in a source language into text in another language. Splitting continuous speech into shorter segments, known as speech segmentation, plays an important role in ST. Recent segmentation methods trained to mimic the segmentation of ST corpora have surpassed traditional approaches. Tsiamas et al. proposed a segmentation frame classifier (SFC) based on a pre-trained speech encoder called wav2vec 2.0. Their method, named SHAS, retains 95-98% of the BLEU score for ST corpus segmentation. However, the segments generated by SHAS are very different from ST corpus segmentation and tend to be longer with multiple combined utterances. This is due to SHAS's reliance on length heuristics, i.e., it splits speech into segments of easily translatable length without fully considering the potential for ST improvement by splitting them into even shorter segments. Longer segments often degrade translation quality and ST's time efficiency. In this study, we extended SHAS to improve ST translation accuracy and efficiency by splitting speech into shorter segments that correspond to sentences. We introduced a simple segmentation algorithm using the moving average of SFC predictions without relying on length heuristics and explored wav2vec 2.0 fine-tuning for improved speech segmentation prediction. Our experimental results reveal that our speech segmentation method significantly improved the quality and the time efficiency of speech translation compared to SHAS.
Transport, Variational Inference and Diffusions: with Applications to Annealed Flows and Schrödinger Bridges
Jul 03, 2023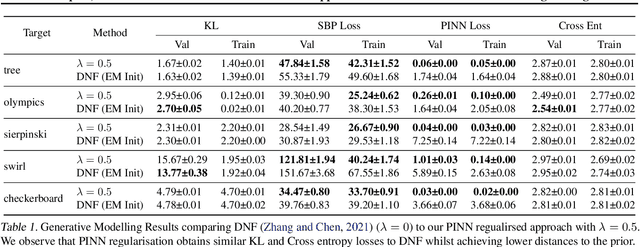

This paper explores the connections between optimal transport and variational inference, with a focus on forward and reverse time stochastic differential equations and Girsanov transformations.We present a principled and systematic framework for sampling and generative modelling centred around divergences on path space. Our work culminates in the development of a novel score-based annealed flow technique (with connections to Jarzynski and Crooks identities from statistical physics) and a regularised iterative proportional fitting (IPF)-type objective, departing from the sequential nature of standard IPF. Through a series of generative modelling examples and a double-well-based rare event task, we showcase the potential of the proposed methods.
Assessment of the Utilization of Quadruped Robots in Pharmaceutical Research and Development Laboratories
Jul 03, 2023

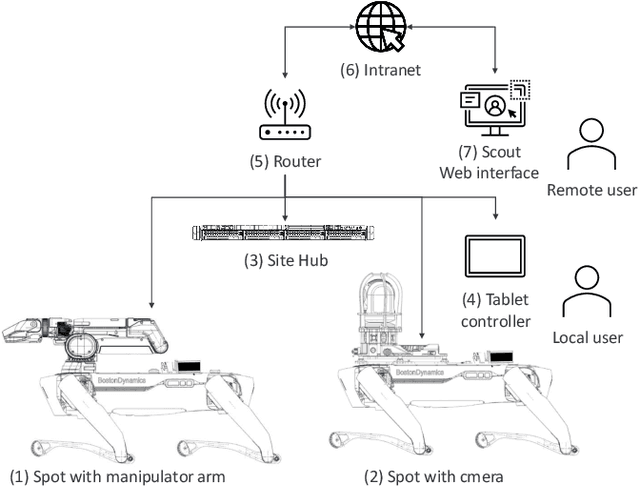
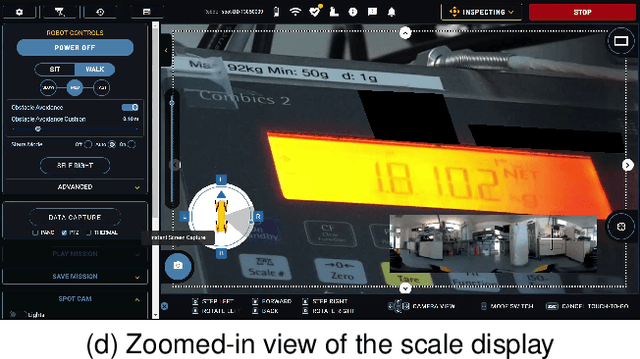
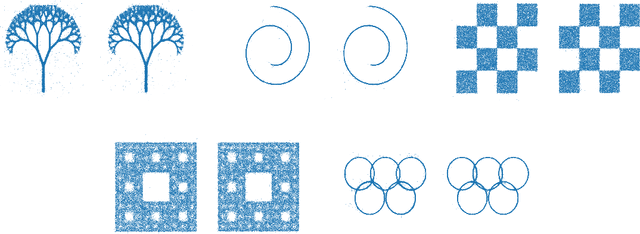
Drug development is becoming more and more complex and resource-intensive. To reduce the costs and the time-to-market, the pharmaceutical industry employs cutting-edge automation solutions. Supportive robotics technologies, such as stationary and mobile manipulators, exist in various laboratory settings. However, they still lack the mobility and dexterity to navigate and operate in human-centered environments. We evaluate the feasibility of quadruped robots for the specific use case of remote inspection, utilizing the out-of-the-box capabilities of Boston Dynamics' Spot platform. We also provide an outlook on the newest technological advancements and the future applications these are anticipated to enable.
Digital Twinning in Smart Grid Networks: Interplay, Resource Allocation and Use Cases
Jun 26, 2023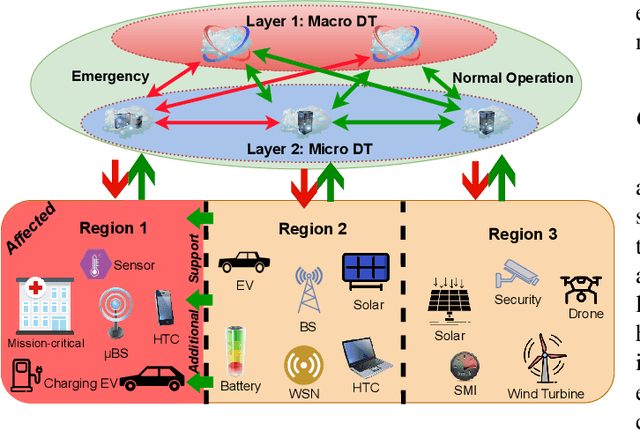
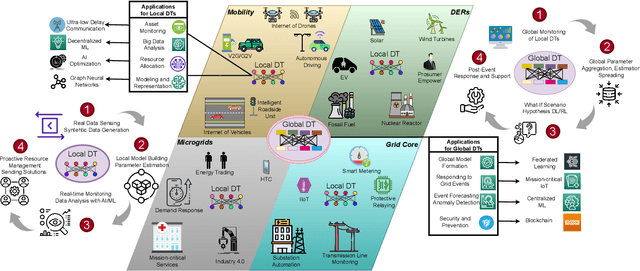
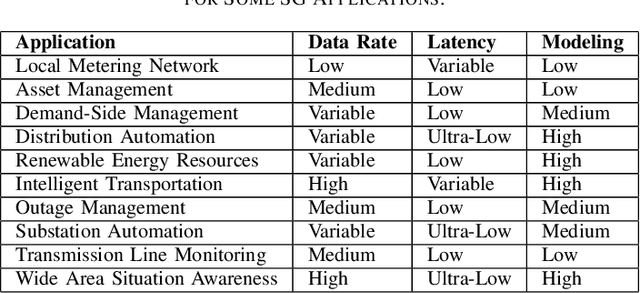
Motivated by climate change, increasing industrialization and energy reliability concerns, the smart grid is set to revolutionize traditional power systems. Moreover, the exponential annual rise in number of grid-connected users and emerging key players e.g. electric vehicles strain the limited radio resources, which stresses the need for novel and scalable resource management techniques. Digital twin is a cutting-edge virtualization technology that has shown great potential by offering solutions for inherent bottlenecks in traditional wireless networks. In this article, we set the stage for various roles digital twinning can fulfill by optimizing congested radio resources in a proactive and resilient smart grid. Digital twins can help smart grid networks through real-time monitoring, advanced precise modeling and efficient radio resource allocation for normal operations and service restoration following unexpected events. However, reliable real-time communications, intricate abstraction abilities, interoperability with other smart grid technologies, robust computing capabilities and resilient security schemes are some open challenges for future work on digital twins.
Automated Identication of Atrial Fibrillation from Single-lead ECGs Using Multi-branching ResNet
Jun 26, 2023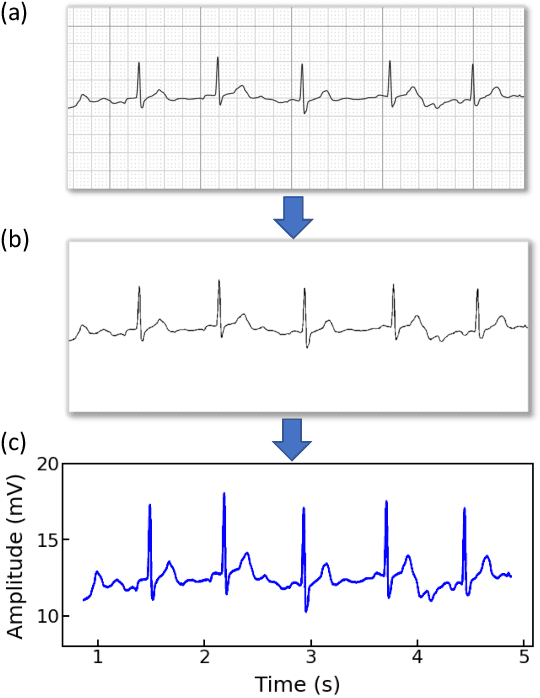
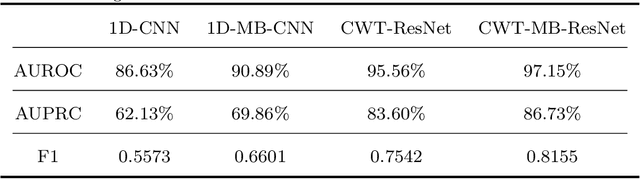
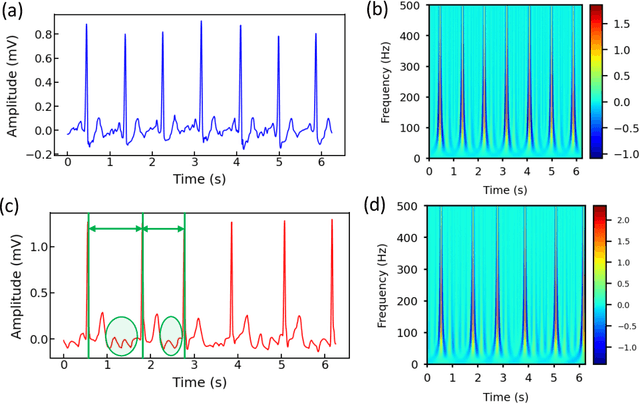
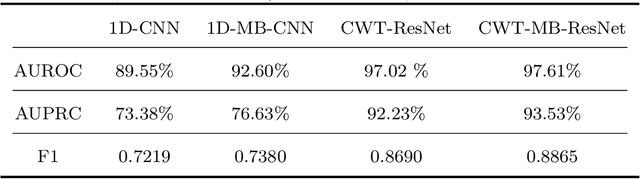
Atrial fibrillation (AF) is the most common cardiac arrhythmia, which is clinically identified with irregular and rapid heartbeat rhythm. AF puts a patient at risk of forming blood clots, which can eventually lead to heart failure, stroke, or even sudden death. It is of critical importance to develop an advanced analytical model that can effectively interpret the electrocardiography (ECG) signals and provide decision support for accurate AF diagnostics. In this paper, we propose an innovative deep-learning method for automated AF identification from single-lead ECGs. We first engage the continuous wavelet transform (CWT) to extract time-frequency features from ECG signals. Then, we develop a convolutional neural network (CNN) structure that incorporates ResNet for effective network training and multi-branching architectures for addressing the imbalanced data issue to process the 2D time-frequency features for AF classification. We evaluate the proposed methodology using two real-world ECG databases. The experimental results show a superior performance of our method compared with traditional deep learning models.
Copula-Based Deep Survival Models for Dependent Censoring
Jun 20, 2023
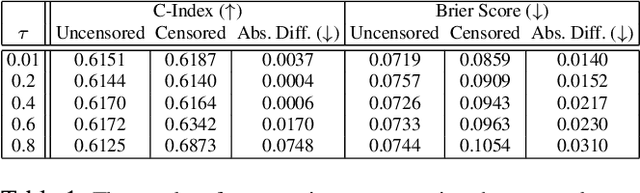
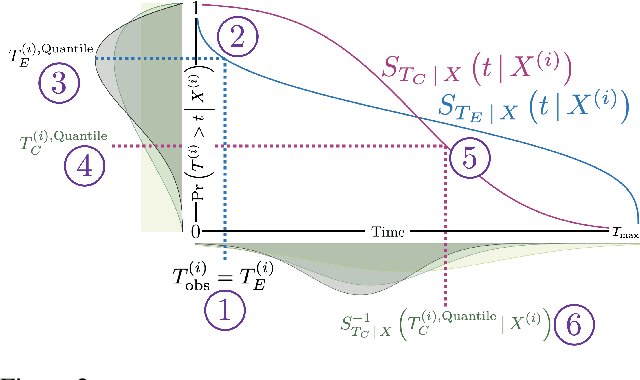
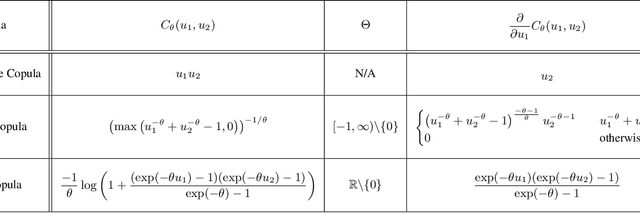
A survival dataset describes a set of instances (e.g. patients) and provides, for each, either the time until an event (e.g. death), or the censoring time (e.g. when lost to follow-up - which is a lower bound on the time until the event). We consider the challenge of survival prediction: learning, from such data, a predictive model that can produce an individual survival distribution for a novel instance. Many contemporary methods of survival prediction implicitly assume that the event and censoring distributions are independent conditional on the instance's covariates - a strong assumption that is difficult to verify (as we observe only one outcome for each instance) and which can induce significant bias when it does not hold. This paper presents a parametric model of survival that extends modern non-linear survival analysis by relaxing the assumption of conditional independence. On synthetic and semi-synthetic data, our approach significantly improves estimates of survival distributions compared to the standard that assumes conditional independence in the data.
Data-Free Quantization via Mixed-Precision Compensation without Fine-Tuning
Jul 02, 2023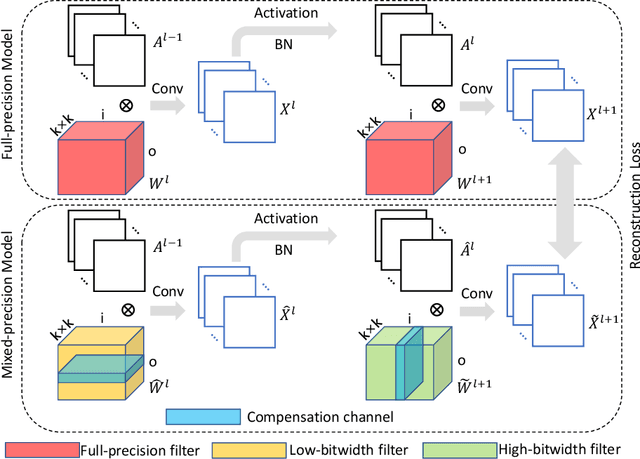
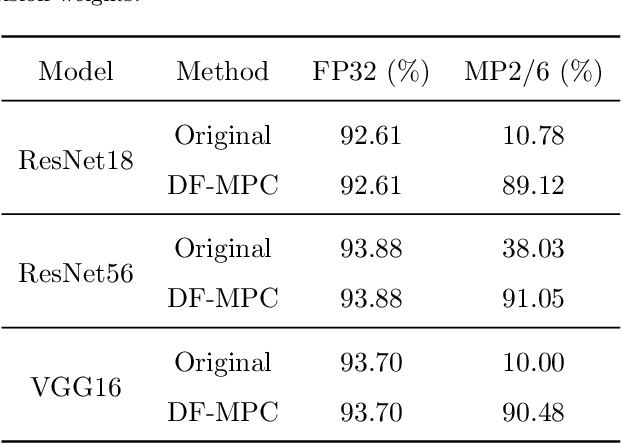
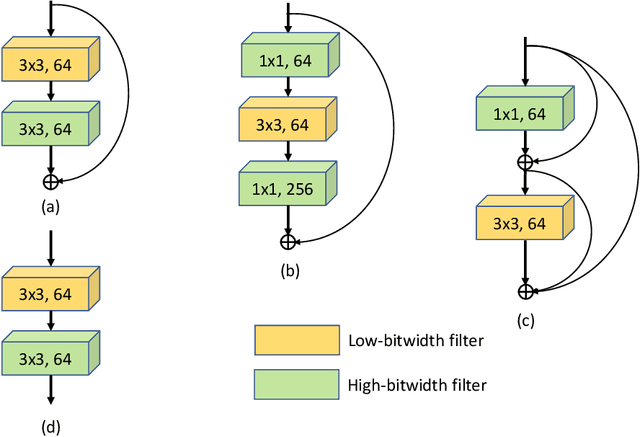
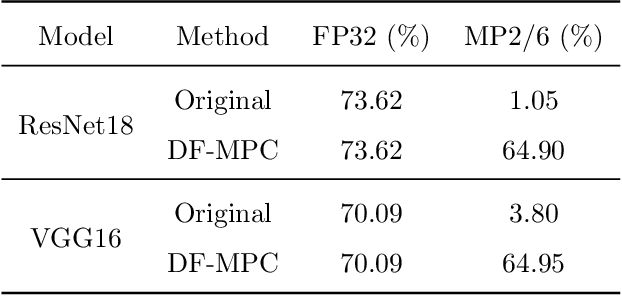
Neural network quantization is a very promising solution in the field of model compression, but its resulting accuracy highly depends on a training/fine-tuning process and requires the original data. This not only brings heavy computation and time costs but also is not conducive to privacy and sensitive information protection. Therefore, a few recent works are starting to focus on data-free quantization. However, data-free quantization does not perform well while dealing with ultra-low precision quantization. Although researchers utilize generative methods of synthetic data to address this problem partially, data synthesis needs to take a lot of computation and time. In this paper, we propose a data-free mixed-precision compensation (DF-MPC) method to recover the performance of an ultra-low precision quantized model without any data and fine-tuning process. By assuming the quantized error caused by a low-precision quantized layer can be restored via the reconstruction of a high-precision quantized layer, we mathematically formulate the reconstruction loss between the pre-trained full-precision model and its layer-wise mixed-precision quantized model. Based on our formulation, we theoretically deduce the closed-form solution by minimizing the reconstruction loss of the feature maps. Since DF-MPC does not require any original/synthetic data, it is a more efficient method to approximate the full-precision model. Experimentally, our DF-MPC is able to achieve higher accuracy for an ultra-low precision quantized model compared to the recent methods without any data and fine-tuning process.
* This paper has been accepted for publication in the Pattern Recognition
Efficient Annotation of Medieval Charters
Jun 24, 2023
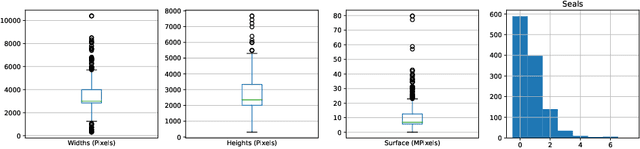
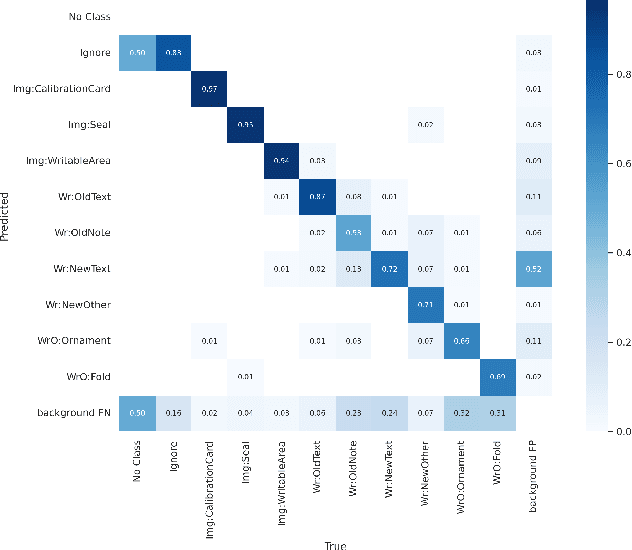
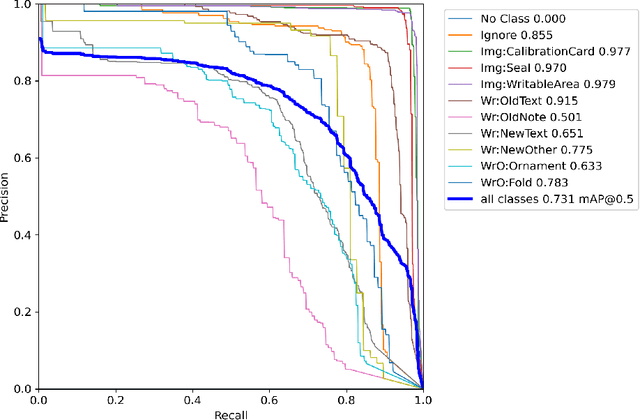
Diplomatics, the analysis of medieval charters, is a major field of research in which paleography is applied. Annotating data, if performed by laymen, needs validation and correction by experts. In this paper, we propose an effective and efficient annotation approach for charter segmentation, essentially reducing it to object detection. This approach allows for a much more efficient use of the paleographer's time and produces results that can compete and even outperform pixel-level segmentation in some use cases. Further experiments shed light on how to design a class ontology in order to make the best use of annotators' time and effort. Exploiting the presence of calibration cards in the image, we further annotate the data with the physical length in pixels and train regression neural networks to predict it from image patches.
Tensor Completion via Leverage Sampling and Tensor QR Decomposition for Network Latency Estimation
Jun 27, 2023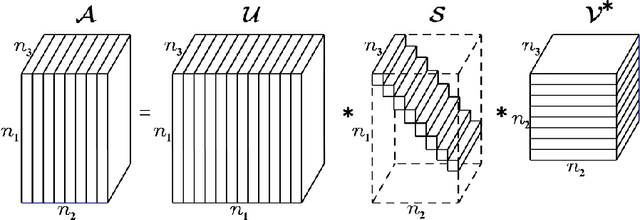
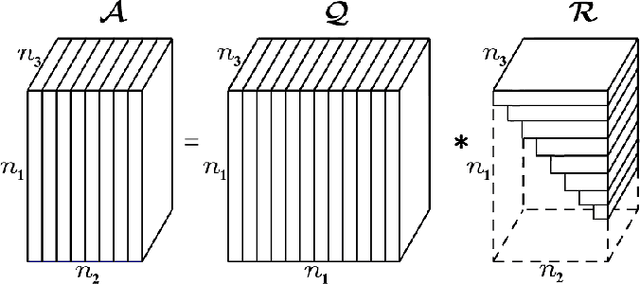
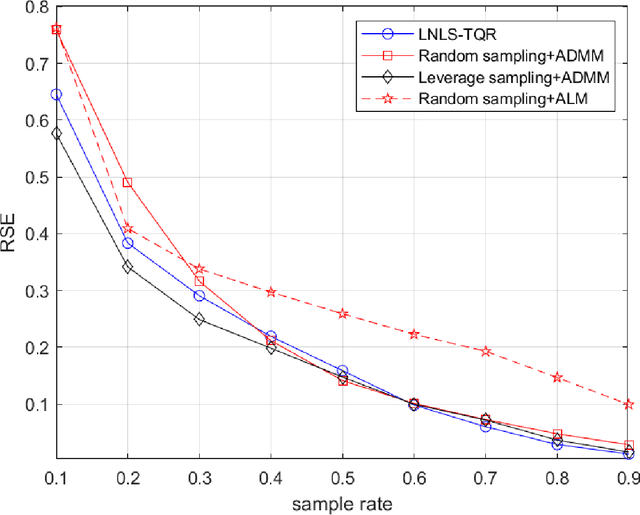
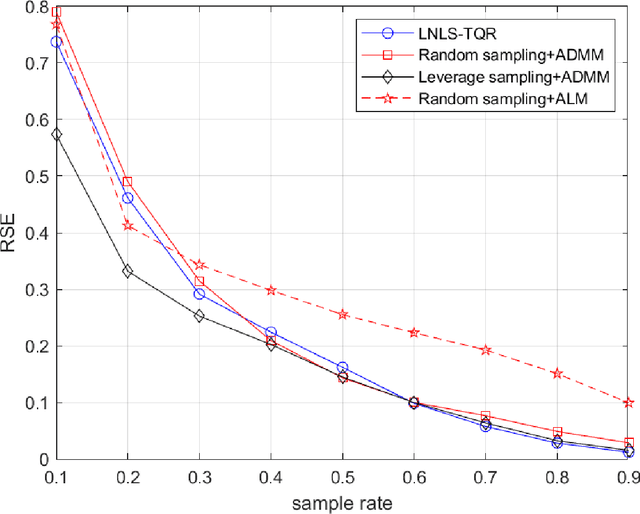
In this paper, we consider the network latency estimation, which has been an important metric for network performance. However, a large scale of network latency estimation requires a lot of computing time. Therefore, we propose a new method that is much faster and maintains high accuracy. The data structure of network nodes can form a matrix, and the tensor model can be formed by introducing the time dimension. Thus, the entire problem can be be summarized as a tensor completion problem. The main idea of our method is improving the tensor leverage sampling strategy and introduce tensor QR decomposition into tensor completion. To achieve faster tensor leverage sampling, we replace tensor singular decomposition (t-SVD) with tensor CSVD-QR to appoximate t-SVD. To achieve faster completion for incomplete tensor, we use the tensor $L_{2,1}$-norm rather than traditional tensor nuclear norm. Furthermore, we introduce tensor QR decomposition into alternating direction method of multipliers (ADMM) framework. Numerical experiments witness that our method is faster than state-of-art algorithms with satisfactory accuracy.
Real-time Multi-person Eyeblink Detection in the Wild for Untrimmed Video
Mar 28, 2023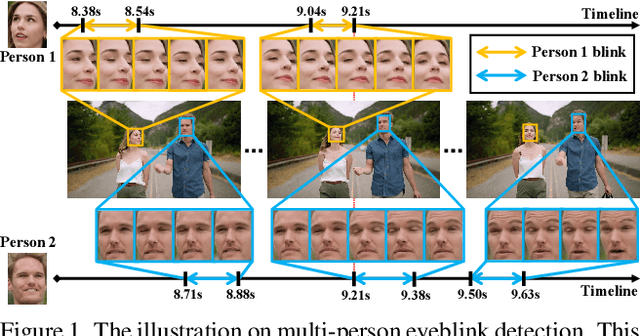


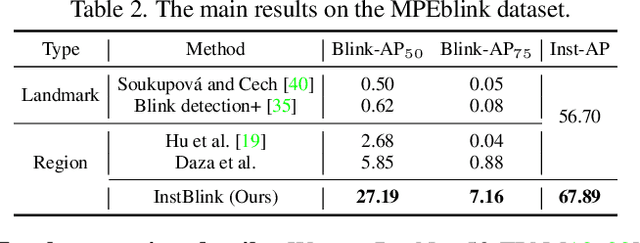
Real-time eyeblink detection in the wild can widely serve for fatigue detection, face anti-spoofing, emotion analysis, etc. The existing research efforts generally focus on single-person cases towards trimmed video. However, multi-person scenario within untrimmed videos is also important for practical applications, which has not been well concerned yet. To address this, we shed light on this research field for the first time with essential contributions on dataset, theory, and practices. In particular, a large-scale dataset termed MPEblink that involves 686 untrimmed videos with 8748 eyeblink events is proposed under multi-person conditions. The samples are captured from unconstrained films to reveal "in the wild" characteristics. Meanwhile, a real-time multi-person eyeblink detection method is also proposed. Being different from the existing counterparts, our proposition runs in a one-stage spatio-temporal way with end-to-end learning capacity. Specifically, it simultaneously addresses the sub-tasks of face detection, face tracking, and human instance-level eyeblink detection. This paradigm holds 2 main advantages: (1) eyeblink features can be facilitated via the face's global context (e.g., head pose and illumination condition) with joint optimization and interaction, and (2) addressing these sub-tasks in parallel instead of sequential manner can save time remarkably to meet the real-time running requirement. Experiments on MPEblink verify the essential challenges of real-time multi-person eyeblink detection in the wild for untrimmed video. Our method also outperforms existing approaches by large margins and with a high inference speed.