 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
OmniVid: A Generative Framework for Universal Video Understanding
Mar 26, 2024
The core of video understanding tasks, such as recognition, captioning, and tracking, is to automatically detect objects or actions in a video and analyze their temporal evolution. Despite sharing a common goal, different tasks often rely on distinct model architectures and annotation formats. In contrast, natural language processing benefits from a unified output space, i.e., text sequences, which simplifies the training of powerful foundational language models, such as GPT-3, with extensive training corpora. Inspired by this, we seek to unify the output space of video understanding tasks by using languages as labels and additionally introducing time and box tokens. In this way, a variety of video tasks could be formulated as video-grounded token generation. This enables us to address various types of video tasks, including classification (such as action recognition), captioning (covering clip captioning, video question answering, and dense video captioning), and localization tasks (such as visual object tracking) within a fully shared encoder-decoder architecture, following a generative framework. Through comprehensive experiments, we demonstrate such a simple and straightforward idea is quite effective and can achieve state-of-the-art or competitive results on seven video benchmarks, providing a novel perspective for more universal video understanding. Code is available at https://github.com/wangjk666/OmniVid.
Don't Listen To Me: Understanding and Exploring Jailbreak Prompts of Large Language Models
Mar 26, 2024Recent advancements in generative AI have enabled ubiquitous access to large language models (LLMs). Empowered by their exceptional capabilities to understand and generate human-like text, these models are being increasingly integrated into our society. At the same time, there are also concerns on the potential misuse of this powerful technology, prompting defensive measures from service providers. To overcome such protection, jailbreaking prompts have recently emerged as one of the most effective mechanisms to circumvent security restrictions and elicit harmful content originally designed to be prohibited. Due to the rapid development of LLMs and their ease of access via natural languages, the frontline of jailbreak prompts is largely seen in online forums and among hobbyists. To gain a better understanding of the threat landscape of semantically meaningful jailbreak prompts, we systemized existing prompts and measured their jailbreak effectiveness empirically. Further, we conducted a user study involving 92 participants with diverse backgrounds to unveil the process of manually creating jailbreak prompts. We observed that users often succeeded in jailbreak prompts generation regardless of their expertise in LLMs. Building on the insights from the user study, we also developed a system using AI as the assistant to automate the process of jailbreak prompt generation.
Sparse-Graph-Enabled Formation Planning for Large-Scale Aerial Swarms
Mar 26, 2024The formation trajectory planning using complete graphs to model collaborative constraints becomes computationally intractable as the number of drones increases due to the curse of dimensionality. To tackle this issue, this paper presents a sparse graph construction method for formation planning to realize better efficiency-performance trade-off. Firstly, a sparsification mechanism for complete graphs is designed to ensure the global rigidity of sparsified graphs, which is a necessary condition for uniquely corresponding to a geometric shape. Secondly, a good sparse graph is constructed to preserve the main structural feature of complete graphs sufficiently. Since the graph-based formation constraint is described by Laplacian matrix, the sparse graph construction problem is equivalent to submatrix selection, which has combinatorial time complexity and needs a scoring metric. Via comparative simulations, the Max-Trace matrix-revealing metric shows the promising performance. The sparse graph is integrated into the formation planning. Simulation results with 72 drones in complex environments demonstrate that when preserving 30\% connection edges, our method has comparative formation error and recovery performance w.r.t. complete graphs. Meanwhile, the planning efficiency is improved by approximate an order of magnitude. Benchmark comparisons and ablation studies are conducted to fully validate the merits of our method.
Cognitively Biased Users Interacting with Algorithmically Biased Results in Whole-Session Search on Controversial Topics
Mar 26, 2024When interacting with information retrieval (IR) systems, users, affected by confirmation biases, tend to select search results that confirm their existing beliefs on socially significant contentious issues. To understand the judgments and attitude changes of users searching online, our study examined how cognitively biased users interact with algorithmically biased search engine result pages (SERPs). We designed three-query search sessions on debated topics under various bias conditions. We recruited 1,321 crowdsourcing participants and explored their attitude changes, search interactions, and the effects of confirmation bias. Three key findings emerged: 1) most attitude changes occur in the initial query of a search session; 2) confirmation bias and result presentation on SERPs affect search behaviors in the current query and perceived familiarity with clicked results in subsequent queries. The bias position also affect attitude changes of users with lower perceived openness to conflicting opinions; 3) Interactions in the first query and and dwell time throughout the session are associated with users' attitude changes in different forms. Our study goes beyond traditional simulation-based evaluation settings and simulated rational users, sheds light on the mixed effects of human biases and algorithmic biases in controversial information retrieval tasks, and can inform the design of bias-aware user models, human-centered bias mitigation techniques, and socially responsible intelligent IR systems.
An Analysis of Switchback Designs in Reinforcement Learning
Mar 26, 2024This paper offers a detailed investigation of switchback designs in A/B testing, which alternate between baseline and new policies over time. Our aim is to thoroughly evaluate the effects of these designs on the accuracy of their resulting average treatment effect (ATE) estimators. We propose a novel "weak signal analysis" framework, which substantially simplifies the calculations of the mean squared errors (MSEs) of these ATEs in Markov decision process environments. Our findings suggest that (i) when the majority of reward errors are positively correlated, the switchback design is more efficient than the alternating-day design which switches policies in a daily basis. Additionally, increasing the frequency of policy switches tends to reduce the MSE of the ATE estimator. (ii) When the errors are uncorrelated, however, all these designs become asymptotically equivalent. (iii) In cases where the majority of errors are negative correlated, the alternating-day design becomes the optimal choice. These insights are crucial, offering guidelines for practitioners on designing experiments in A/B testing. Our analysis accommodates a variety of policy value estimators, including model-based estimators, least squares temporal difference learning estimators, and double reinforcement learning estimators, thereby offering a comprehensive understanding of optimal design strategies for policy evaluation in reinforcement learning.
Leveraging Non-Decimated Wavelet Packet Features and Transformer Models for Time Series Forecasting
Mar 13, 2024
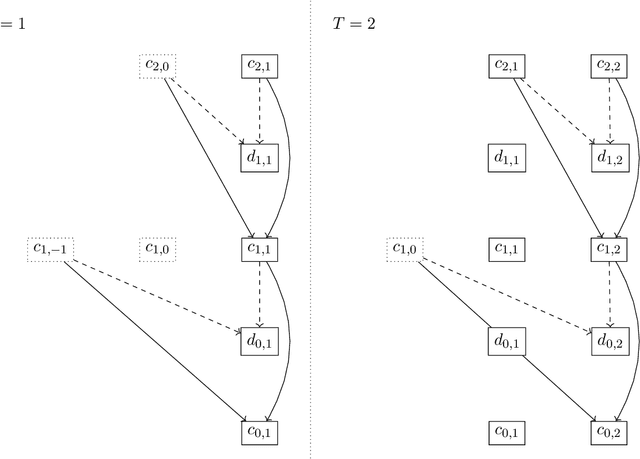
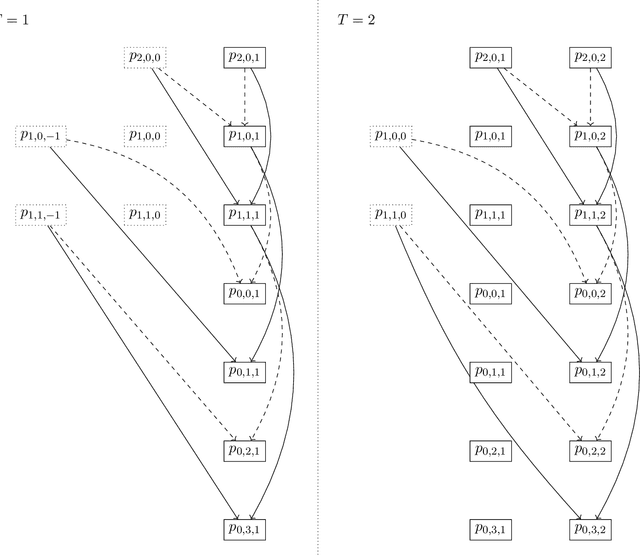
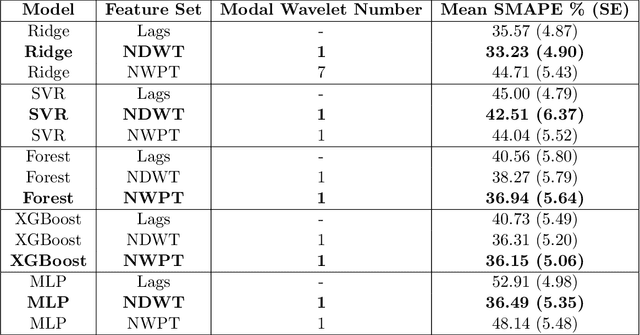
This article combines wavelet analysis techniques with machine learning methods for univariate time series forecasting, focusing on three main contributions. Firstly, we consider the use of Daubechies wavelets with different numbers of vanishing moments as input features to both non-temporal and temporal forecasting methods, by selecting these numbers during the cross-validation phase. Secondly, we compare the use of both the non-decimated wavelet transform and the non-decimated wavelet packet transform for computing these features, the latter providing a much larger set of potentially useful coefficient vectors. The wavelet coefficients are computed using a shifted version of the typical pyramidal algorithm to ensure no leakage of future information into these inputs. Thirdly, we evaluate the use of these wavelet features on a significantly wider set of forecasting methods than previous studies, including both temporal and non-temporal models, and both statistical and deep learning-based methods. The latter include state-of-the-art transformer-based neural network architectures. Our experiments suggest significant benefit in replacing higher-order lagged features with wavelet features across all examined non-temporal methods for one-step-forward forecasting, and modest benefit when used as inputs for temporal deep learning-based models for long-horizon forecasting.
GreeDy and CoDy: Counterfactual Explainers for Dynamic Graphs
Mar 25, 2024Temporal Graph Neural Networks (TGNNs), crucial for modeling dynamic graphs with time-varying interactions, face a significant challenge in explainability due to their complex model structure. Counterfactual explanations, crucial for understanding model decisions, examine how input graph changes affect outcomes. This paper introduces two novel counterfactual explanation methods for TGNNs: GreeDy (Greedy Explainer for Dynamic Graphs) and CoDy (Counterfactual Explainer for Dynamic Graphs). They treat explanations as a search problem, seeking input graph alterations that alter model predictions. GreeDy uses a simple, greedy approach, while CoDy employs a sophisticated Monte Carlo Tree Search algorithm. Experiments show both methods effectively generate clear explanations. Notably, CoDy outperforms GreeDy and existing factual methods, with up to 59\% higher success rate in finding significant counterfactual inputs. This highlights CoDy's potential in clarifying TGNN decision-making, increasing their transparency and trustworthiness in practice.
Fusing Domain-Specific Content from Large Language Models into Knowledge Graphs for Enhanced Zero Shot Object State Classification
Mar 25, 2024
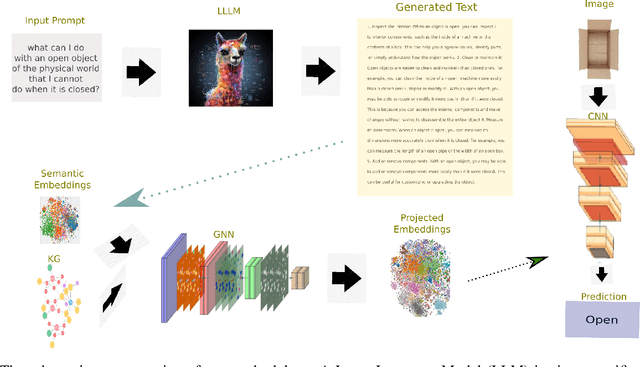


Domain-specific knowledge can significantly contribute to addressing a wide variety of vision tasks. However, the generation of such knowledge entails considerable human labor and time costs. This study investigates the potential of Large Language Models (LLMs) in generating and providing domain-specific information through semantic embeddings. To achieve this, an LLM is integrated into a pipeline that utilizes Knowledge Graphs and pre-trained semantic vectors in the context of the Vision-based Zero-shot Object State Classification task. We thoroughly examine the behavior of the LLM through an extensive ablation study. Our findings reveal that the integration of LLM-based embeddings, in combination with general-purpose pre-trained embeddings, leads to substantial performance improvements. Drawing insights from this ablation study, we conduct a comparative analysis against competing models, thereby highlighting the state-of-the-art performance achieved by the proposed approach.
Time-optimal Point-to-point Motion Planning: A Two-stage Approach
Mar 06, 2024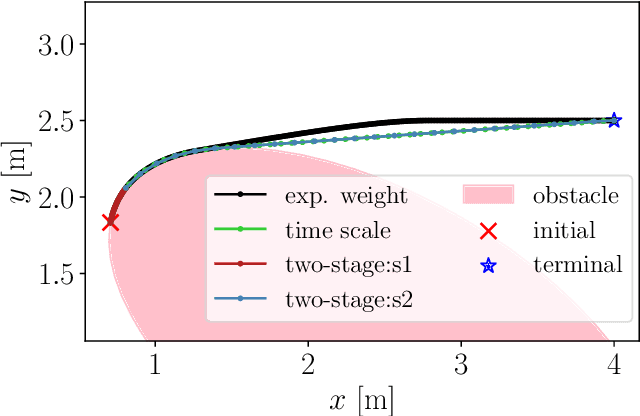
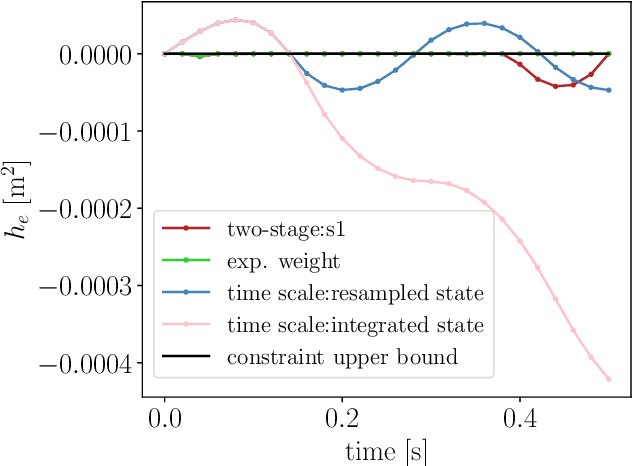
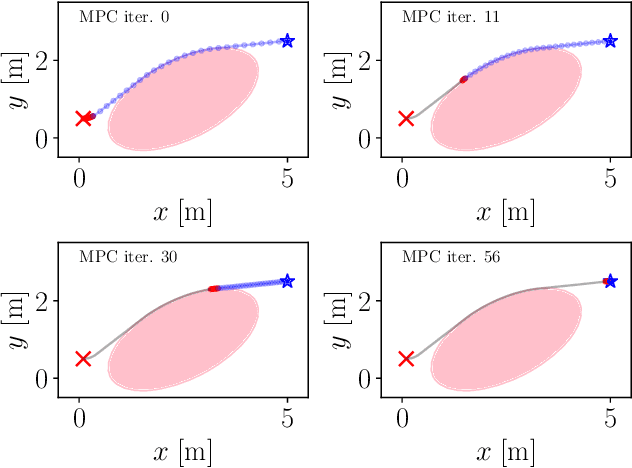
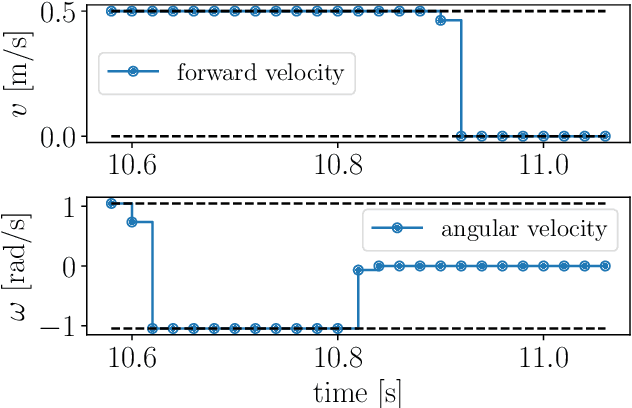
This paper proposes a two-stage approach to formulate the time-optimal point-to-point motion planning problem, involving a first stage with a fixed time grid and a second stage with a variable time grid. The proposed approach brings benefits through its straightforward optimal control problem formulation with a fixed and low number of control steps for manageable computational complexity and the avoidance of interpolation errors associated with time scaling, especially when aiming to reach a distant goal. Additionally, an asynchronous nonlinear model predictive control (NMPC) update scheme is integrated with this two-stage approach to address delayed and fluctuating computation times, facilitating online replanning. The effectiveness of the proposed two-stage approach and NMPC implementation is demonstrated through numerical examples centered on autonomous navigation with collision avoidance.
Improved Long Short-Term Memory-based Wastewater Treatment Simulators for Deep Reinforcement Learning
Mar 22, 2024Even though Deep Reinforcement Learning (DRL) showed outstanding results in the fields of Robotics and Games, it is still challenging to implement it in the optimization of industrial processes like wastewater treatment. One of the challenges is the lack of a simulation environment that will represent the actual plant as accurately as possible to train DRL policies. Stochasticity and non-linearity of wastewater treatment data lead to unstable and incorrect predictions of models over long time horizons. One possible reason for the models' incorrect simulation behavior can be related to the issue of compounding error, which is the accumulation of errors throughout the simulation. The compounding error occurs because the model utilizes its predictions as inputs at each time step. The error between the actual data and the prediction accumulates as the simulation continues. We implemented two methods to improve the trained models for wastewater treatment data, which resulted in more accurate simulators: 1- Using the model's prediction data as input in the training step as a tool of correction, and 2- Change in the loss function to consider the long-term predicted shape (dynamics). The experimental results showed that implementing these methods can improve the behavior of simulators in terms of Dynamic Time Warping throughout a year up to 98% compared to the base model. These improvements demonstrate significant promise in creating simulators for biological processes that do not need pre-existing knowledge of the process but instead depend exclusively on time series data obtained from the system.