 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Vehicle Detection in 6G Systems with OTFS Modulation
Jul 10, 2023
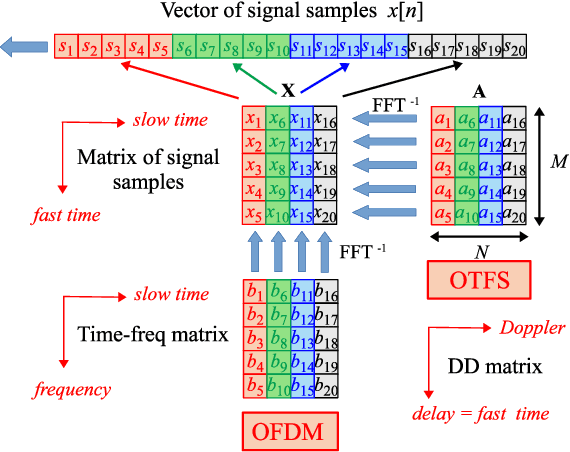
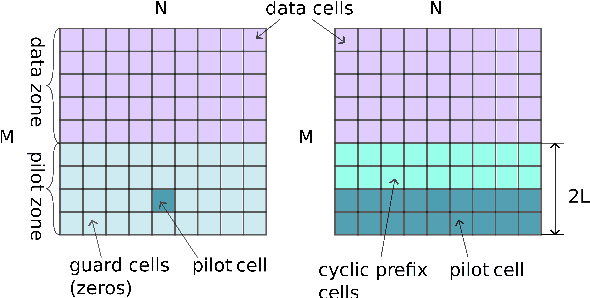
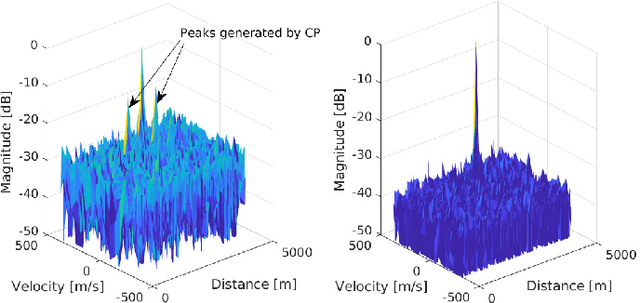
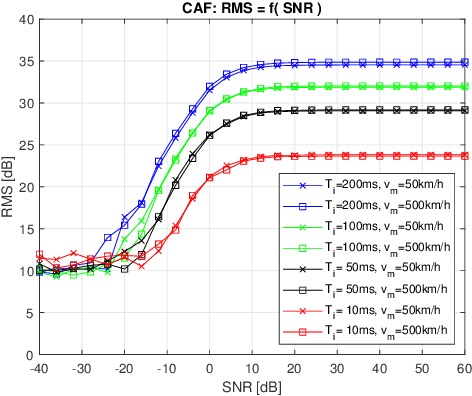
The recently introduced orthogonal time frequency space modulation (OTFSM) is more robust to large narrow-band Doppler frequency shift than the orthogonal frequency division multiplexing (OFDM), used in the 5G standard. In this paper it is shown how the elecommunication OTFSM-based signal with random padding can be used with success in the 6G standard for detection of high-speed vehicles. Two approaches for detecting targets during the random padded OTFS based transmission are compared in the paper
Improved Test-Time Adaptation for Domain Generalization
Apr 10, 2023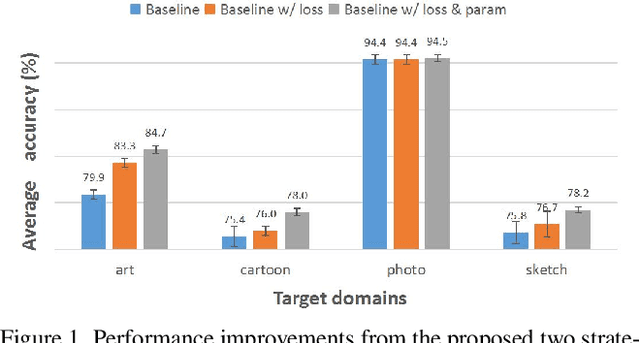
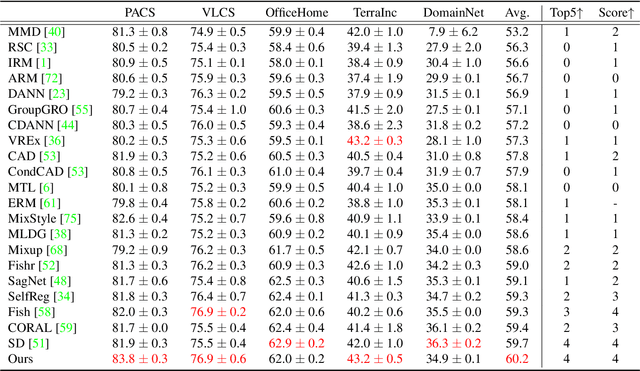
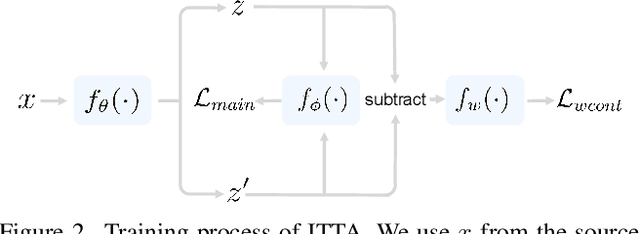
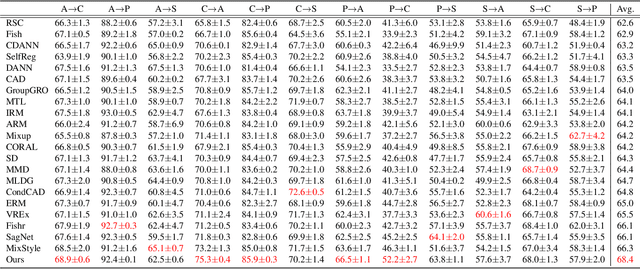
The main challenge in domain generalization (DG) is to handle the distribution shift problem that lies between the training and test data. Recent studies suggest that test-time training (TTT), which adapts the learned model with test data, might be a promising solution to the problem. Generally, a TTT strategy hinges its performance on two main factors: selecting an appropriate auxiliary TTT task for updating and identifying reliable parameters to update during the test phase. Both previous arts and our experiments indicate that TTT may not improve but be detrimental to the learned model if those two factors are not properly considered. This work addresses those two factors by proposing an Improved Test-Time Adaptation (ITTA) method. First, instead of heuristically defining an auxiliary objective, we propose a learnable consistency loss for the TTT task, which contains learnable parameters that can be adjusted toward better alignment between our TTT task and the main prediction task. Second, we introduce additional adaptive parameters for the trained model, and we suggest only updating the adaptive parameters during the test phase. Through extensive experiments, we show that the proposed two strategies are beneficial for the learned model (see Figure 1), and ITTA could achieve superior performance to the current state-of-the-art methods on several DG benchmarks. Code is available at https://github.com/liangchen527/ITTA.
Parmesan: mathematical concept extraction for education
Jul 17, 2023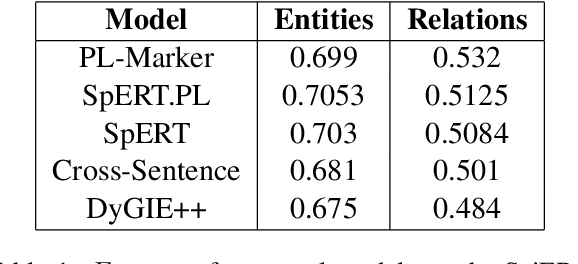
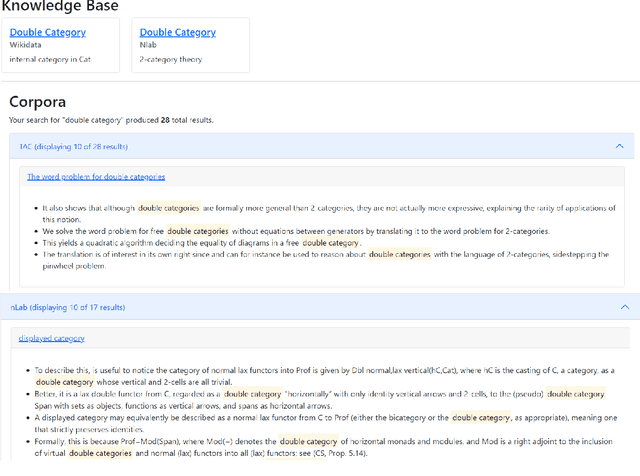
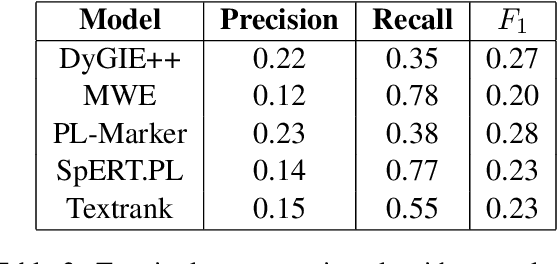
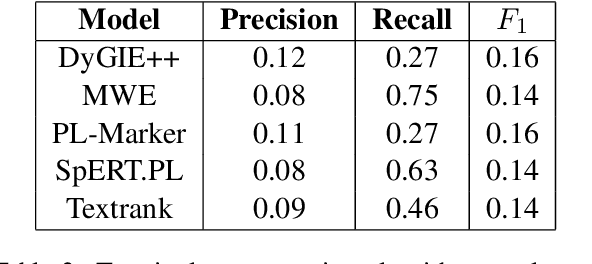
Mathematics is a highly specialized domain with its own unique set of challenges that has seen limited study in natural language processing. However, mathematics is used in a wide variety of fields and multidisciplinary research in many different domains often relies on an understanding of mathematical concepts. To aid researchers coming from other fields, we develop a prototype system for searching for and defining mathematical concepts in context, focusing on the field of category theory. This system, Parmesan, depends on natural language processing components including concept extraction, relation extraction, definition extraction, and entity linking. In developing this system, we show that existing techniques cannot be applied directly to the category theory domain, and suggest hybrid techniques that do perform well, though we expect the system to evolve over time. We also provide two cleaned mathematical corpora that power the prototype system, which are based on journal articles and wiki pages, respectively. The corpora have been annotated with dependency trees, lemmas, and part-of-speech tags.
The FathomNet2023 Competition Dataset
Jul 17, 2023

Ocean scientists have been collecting visual data to study marine organisms for decades. These images and videos are extremely valuable both for basic science and environmental monitoring tasks. There are tools for automatically processing these data, but none that are capable of handling the extreme variability in sample populations, image quality, and habitat characteristics that are common in visual sampling of the ocean. Such distribution shifts can occur over very short physical distances and in narrow time windows. Creating models that are able to recognize when an image or video sequence contains a new organism, an unusual collection of animals, or is otherwise out-of-sample is critical to fully leverage visual data in the ocean. The FathomNet2023 competition dataset presents a realistic scenario where the set of animals in the target data differs from the training data. The challenge is both to identify the organisms in a target image and assess whether it is out-of-sample.
Efficient and Accurate Optimal Transport with Mirror Descent and Conjugate Gradients
Jul 17, 2023We design a novel algorithm for optimal transport by drawing from the entropic optimal transport, mirror descent and conjugate gradients literatures. Our algorithm is able to compute optimal transport costs with arbitrary accuracy without running into numerical stability issues. The algorithm is implemented efficiently on GPUs and is shown empirically to converge more quickly than traditional algorithms such as Sinkhorn's Algorithm both in terms of number of iterations and wall-clock time in many cases. We pay particular attention to the entropy of marginal distributions and show that high entropy marginals make for harder optimal transport problems, for which our algorithm is a good fit. We provide a careful ablation analysis with respect to algorithm and problem parameters, and present benchmarking over the MNIST dataset. The results suggest that our algorithm can be a useful addition to the practitioner's optimal transport toolkit. Our code is open-sourced at https://github.com/adaptive-agents-lab/MDOT-PNCG .
Navigating Fairness Measures and Trade-Offs
Jul 17, 2023In order to monitor and prevent bias in AI systems we can use a wide range of (statistical) fairness measures. However, it is mathematically impossible to optimize for all of these measures at the same time. In addition, optimizing a fairness measure often greatly reduces the accuracy of the system (Kozodoi et al, 2022). As a result, we need a substantive theory that informs us how to make these decisions and for what reasons. I show that by using Rawls' notion of justice as fairness, we can create a basis for navigating fairness measures and the accuracy trade-off. In particular, this leads to a principled choice focusing on both the most vulnerable groups and the type of fairness measure that has the biggest impact on that group. This also helps to close part of the gap between philosophical accounts of distributive justice and the fairness literature that has been observed (Kuppler et al, 2021) and to operationalise the value of fairness.
Natural Actor-Critic for Robust Reinforcement Learning with Function Approximation
Jul 17, 2023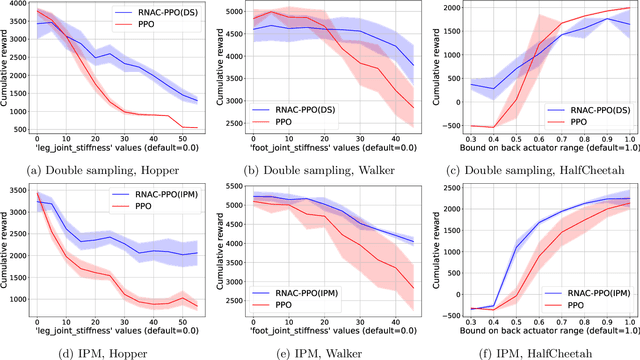
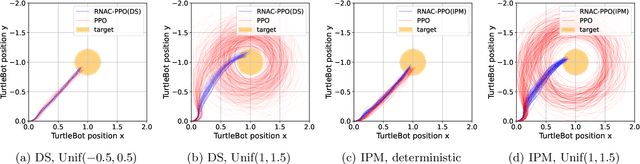
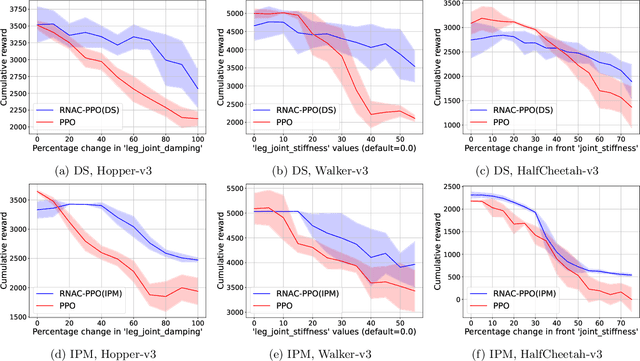
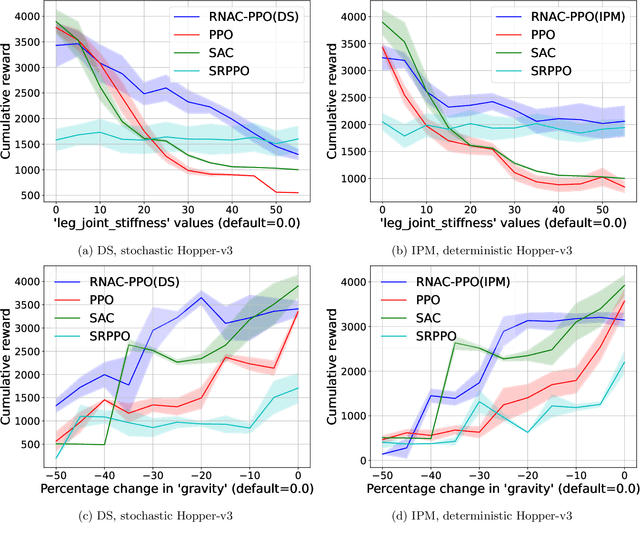
We study robust reinforcement learning (RL) with the goal of determining a well-performing policy that is robust against model mismatch between the training simulator and the testing environment. Previous policy-based robust RL algorithms mainly focus on the tabular setting under uncertainty sets that facilitate robust policy evaluation, but are no longer tractable when the number of states scales up. To this end, we propose two novel uncertainty set formulations, one based on double sampling and the other on an integral probability metric. Both make large-scale robust RL tractable even when one only has access to a simulator. We propose a robust natural actor-critic (RNAC) approach that incorporates the new uncertainty sets and employs function approximation. We provide finite-time convergence guarantees for the proposed RNAC algorithm to the optimal robust policy within the function approximation error. Finally, we demonstrate the robust performance of the policy learned by our proposed RNAC approach in multiple MuJoCo environments and a real-world TurtleBot navigation task.
Distributed Radar Imaging Based on Accelerated ADMM
Jul 17, 2023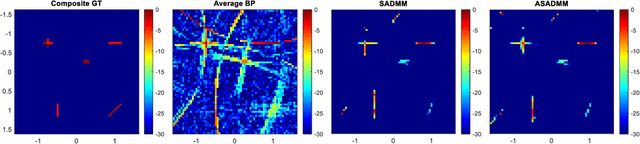
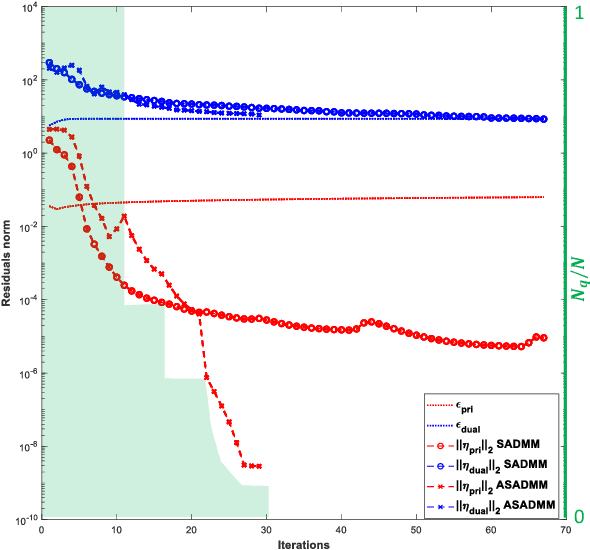
The ability of widely distributed radar systems to capture diverse spatial scattering properties substantially improves radar imaging performance. Traditional imaging methods leverage regularized optimization techniques to reconstruct sparse images from local sensors and later combine them to create a global image. Alternatively, we proposed in an earlier work a joint reconstruction technique based on two problem formulations according to the optimization framework of the Alternating Direction Method of Multipliers (ADMM). The joint reconstruction of the global image offers faster convergence, flexible implementation, and a general distributed reconstruction framework. However, despite its benefits, ADMM framework still exhibits a slow convergence rate, making its employment in some contexts impractical. In this paper, we introduce a heuristic method to accelerate the convergence of the previously proposed ADMM formulations based on the gradual elimination of the already converged pixels in accordance with a predetermined criterion. In addition to reducing running time, the accelerated implementation offers reduced computational complexity and lower communication cost between the sensors during iterative updates.
InstantBooth: Personalized Text-to-Image Generation without Test-Time Finetuning
Apr 06, 2023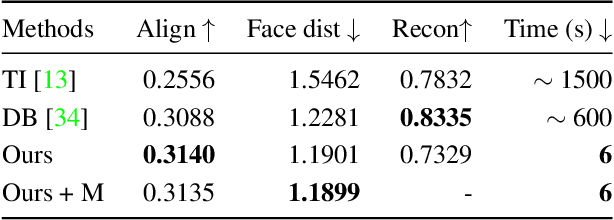
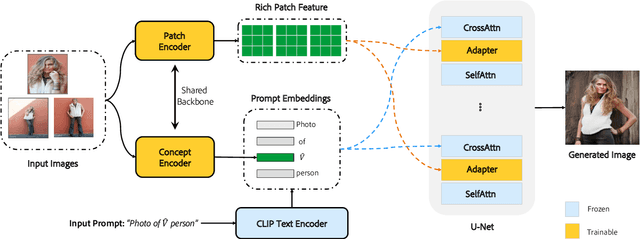

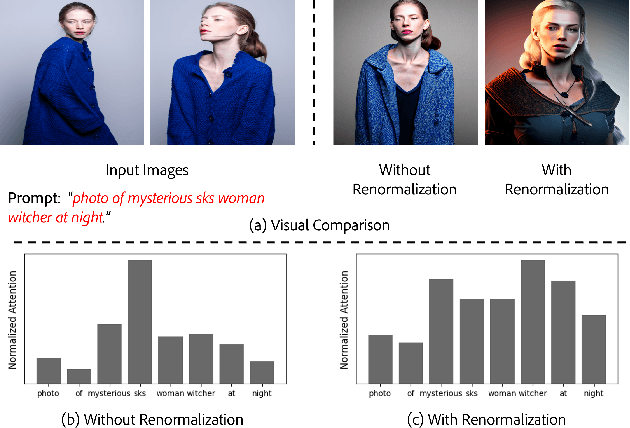
Recent advances in personalized image generation allow a pre-trained text-to-image model to learn a new concept from a set of images. However, existing personalization approaches usually require heavy test-time finetuning for each concept, which is time-consuming and difficult to scale. We propose InstantBooth, a novel approach built upon pre-trained text-to-image models that enables instant text-guided image personalization without any test-time finetuning. We achieve this with several major components. First, we learn the general concept of the input images by converting them to a textual token with a learnable image encoder. Second, to keep the fine details of the identity, we learn rich visual feature representation by introducing a few adapter layers to the pre-trained model. We train our components only on text-image pairs without using paired images of the same concept. Compared to test-time finetuning-based methods like DreamBooth and Textual-Inversion, our model can generate competitive results on unseen concepts concerning language-image alignment, image fidelity, and identity preservation while being 100 times faster.
Neuromorphic Online Learning for Spatiotemporal Patterns with a Forward-only Timeline
Jul 21, 2023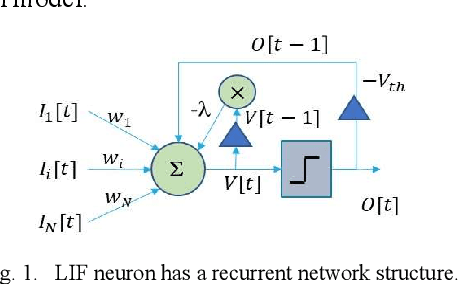
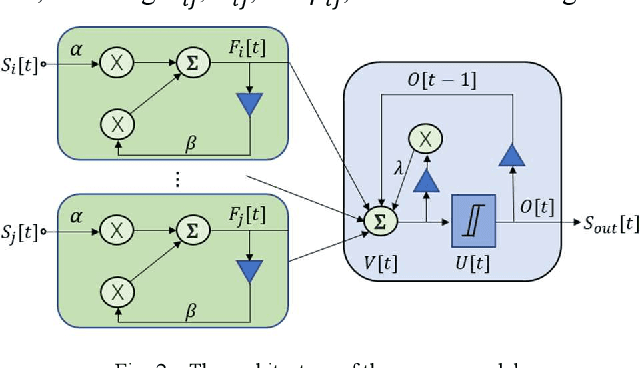
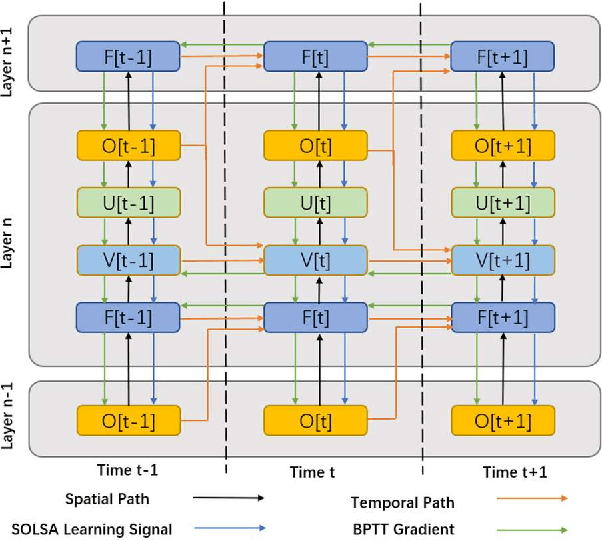
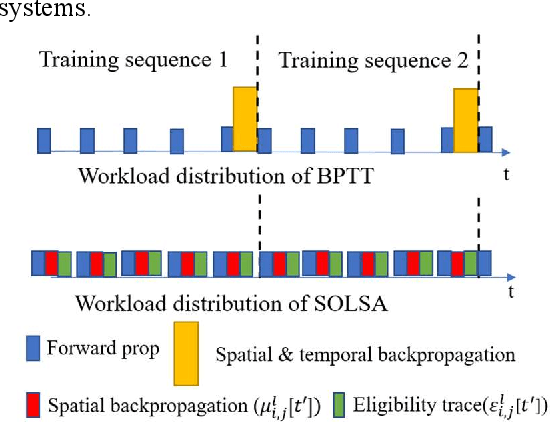
Spiking neural networks (SNNs) are bio-plausible computing models with high energy efficiency. The temporal dynamics of neurons and synapses enable them to detect temporal patterns and generate sequences. While Backpropagation Through Time (BPTT) is traditionally used to train SNNs, it is not suitable for online learning of embedded applications due to its high computation and memory cost as well as extended latency. Previous works have proposed online learning algorithms, but they often utilize highly simplified spiking neuron models without synaptic dynamics and reset feedback, resulting in subpar performance. In this work, we present Spatiotemporal Online Learning for Synaptic Adaptation (SOLSA), specifically designed for online learning of SNNs composed of Leaky Integrate and Fire (LIF) neurons with exponentially decayed synapses and soft reset. The algorithm not only learns the synaptic weight but also adapts the temporal filters associated to the synapses. Compared to the BPTT algorithm, SOLSA has much lower memory requirement and achieves a more balanced temporal workload distribution. Moreover, SOLSA incorporates enhancement techniques such as scheduled weight update, early stop training and adaptive synapse filter, which speed up the convergence and enhance the learning performance. When compared to other non-BPTT based SNN learning, SOLSA demonstrates an average learning accuracy improvement of 14.2%. Furthermore, compared to BPTT, SOLSA achieves a 5% higher average learning accuracy with a 72% reduction in memory cost.