 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstantBooth: Personalized Text-to-Image Generation without Test-Time Finetuning
Apr 06, 2023Recent advances in personalized image generation allow a pre-trained text-to-image model to learn a new concept from a set of images. However, existing personalization approaches usually require heavy test-time finetuning for each concept, which is time-consuming and difficult to scale. We propose InstantBooth, a novel approach built upon pre-trained text-to-image models that enables instant text-guided image personalization without any test-time finetuning. We achieve this with several major components. First, we learn the general concept of the input images by converting them to a textual token with a learnable image encoder. Second, to keep the fine details of the identity, we learn rich visual feature representation by introducing a few adapter layers to the pre-trained model. We train our components only on text-image pairs without using paired images of the same concept. Compared to test-time finetuning-based methods like DreamBooth and Textual-Inversion, our model can generate competitive results on unseen concepts concerning language-image alignment, image fidelity, and identity preservation while being 100 times faster.
Evaluating Classifiers Without Expert Labels
Dec 05, 2012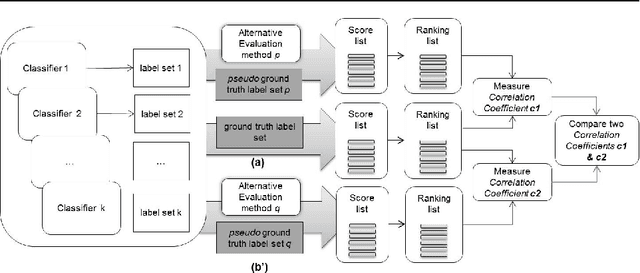
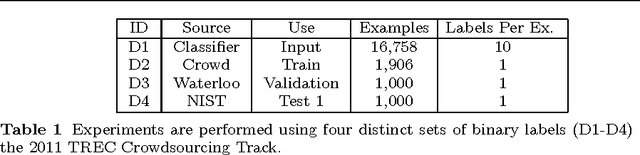
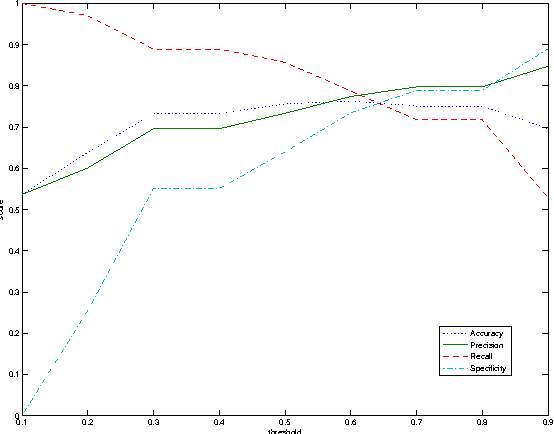
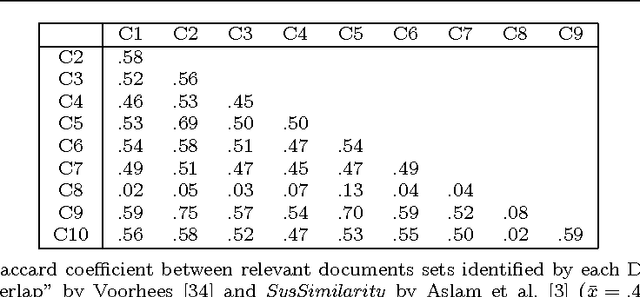
This paper considers the challenge of evaluating a set of classifiers, as done in shared task evaluations like the KDD Cup or NIST TREC, without expert labels. While expert labels provide the traditional cornerstone for evaluating statistical learners, limited or expensive access to experts represents a practical bottleneck. Instead, we seek methodology for estimating performance of the classifiers which is more scalable than expert labeling yet preserves high correlation with evaluation based on expert labels. We consider both: 1) using only labels automatically generated by the classifiers (blind evaluation); and 2) using labels obtained via crowdsourcing. While crowdsourcing methods are lauded for scalability, using such data for evaluation raises serious concerns given the prevalence of label noise. In regard to blind evaluation, two broad strategies are investigated: combine & score and score & combine methods infer a single pseudo-gold label set by aggregating classifier labels; classifiers are then evaluated based on this single pseudo-gold label set. On the other hand, score & combine methods: 1) sample multiple label sets from classifier outputs, 2) evaluate classifiers on each label set, and 3) average classifier performance across label sets. When additional crowd labels are also collected, we investigate two alternative avenues for exploiting them: 1) direct evaluation of classifiers; or 2) supervision of combine & score methods. To assess generality of our techniques, classifier performance is measured using four common classification metrics, with statistical significance tests. Finally, we measure both score and rank correlations between estimated classifier performance vs. actual performance according to expert judgments. Rigorous evaluation of classifiers from the TREC 2011 Crowdsourcing Track shows reliable evaluation can be achieved without reliance on expert labels.