 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
Long-Horizon Plan Execution in Large Tool Spaces through Entropy-Guided Branching
Apr 13, 2026Large Language Models (LLMs) have significantly advanced tool-augmented agents, enabling autonomous reasoning via API interactions. However, executing multi-step tasks within massive tool libraries remains challenging due to two critical bottlenecks: (1) the absence of rigorous, plan-level evaluation frameworks and (2) the computational demand of exploring vast decision spaces stemming from large toolsets and long-horizon planning. To bridge these gaps, we first introduce SLATE (Synthetic Large-scale API Toolkit for E-commerce), a large-scale context-aware benchmark designed for the automated assessment of tool-integrated agents. Unlike static metrics, SLATE accommodates diverse yet functionally valid execution trajectories, revealing that current agents struggle with self-correction and search efficiency. Motivated by these findings, we next propose Entropy-Guided Branching (EGB), an uncertainty-aware search algorithm that dynamically expands decision branches where predictive entropy is high. EGB optimizes the exploration-exploitation trade-off, significantly enhancing both task success rates and computational efficiency. Extensive experiments on SLATE demonstrate that our dual contribution provides a robust foundation for developing reliable and scalable LLM agents in tool-rich environments.
Learning Surgical Robotic Manipulation with 3D Spatial Priors
Mar 04, 2026Achieving 3D spatial awareness is crucial for surgical robotic manipulation, where precise and delicate operations are required. Existing methods either explicitly reconstruct the surgical scene prior to manipulation, or enhance multi-view features by adding wrist-mounted cameras to supplement the default stereo endoscopes. However, both paradigms suffer from notable limitations: the former easily leads to error accumulation and prevents end-to-end optimization due to its multi-stage nature, while the latter is rarely adopted in clinical practice since wrist-mounted cameras can interfere with the motion of surgical robot arms. In this work, we introduce the Spatial Surgical Transformer (SST), an end-to-end visuomotor policy that empowers surgical robots with 3D spatial awareness by directly exploring 3D spatial cues embedded in endoscopic images. First, we build Surgical3D, a large-scale photorealistic dataset containing 30K stereo endoscopic image pairs with accurate 3D geometry, addressing the scarcity of 3D data in surgical scenes. Based on Surgical3D, we finetune a powerful geometric transformer to extract robust 3D latent representations from stereo endoscopes images. These representations are then seamlessly aligned with the robot's action space via a lightweight multi-level spatial feature connector (MSFC), all within an endoscope-centric coordinate frame. Extensive real-robot experiments demonstrate that SST achieves state-of-the-art performance and strong spatial generalization on complex surgical tasks such as knot tying and ex-vivo organ dissection, representing a significant step toward practical clinical deployment. The dataset and code will be released.
DCL-SE: Dynamic Curriculum Learning for Spatiotemporal Encoding of Brain Imaging
Nov 19, 2025



High-dimensional neuroimaging analyses for clinical diagnosis are often constrained by compromises in spatiotemporal fidelity and by the limited adaptability of large-scale, general-purpose models. To address these challenges, we introduce Dynamic Curriculum Learning for Spatiotemporal Encoding (DCL-SE), an end-to-end framework centered on data-driven spatiotemporal encoding (DaSE). We leverage Approximate Rank Pooling (ARP) to efficiently encode three-dimensional volumetric brain data into information-rich, two-dimensional dynamic representations, and then employ a dynamic curriculum learning strategy, guided by a Dynamic Group Mechanism (DGM), to progressively train the decoder, refining feature extraction from global anatomical structures to fine pathological details. Evaluated across six publicly available datasets, including Alzheimer's disease and brain tumor classification, cerebral artery segmentation, and brain age prediction, DCL-SE consistently outperforms existing methods in accuracy, robustness, and interpretability. These findings underscore the critical importance of compact, task-specific architectures in the era of large-scale pretrained networks.
Diffusion Blend: Inference-Time Multi-Preference Alignment for Diffusion Models
May 24, 2025



Reinforcement learning (RL) algorithms have been used recently to align diffusion models with downstream objectives such as aesthetic quality and text-image consistency by fine-tuning them to maximize a single reward function under a fixed KL regularization. However, this approach is inherently restrictive in practice, where alignment must balance multiple, often conflicting objectives. Moreover, user preferences vary across prompts, individuals, and deployment contexts, with varying tolerances for deviation from a pre-trained base model. We address the problem of inference-time multi-preference alignment: given a set of basis reward functions and a reference KL regularization strength, can we design a fine-tuning procedure so that, at inference time, it can generate images aligned with any user-specified linear combination of rewards and regularization, without requiring additional fine-tuning? We propose Diffusion Blend, a novel approach to solve inference-time multi-preference alignment by blending backward diffusion processes associated with fine-tuned models, and we instantiate this approach with two algorithms: DB-MPA for multi-reward alignment and DB-KLA for KL regularization control. Extensive experiments show that Diffusion Blend algorithms consistently outperform relevant baselines and closely match or exceed the performance of individually fine-tuned models, enabling efficient, user-driven alignment at inference-time. The code is available at https://github.com/bluewoods127/DB-2025}{github.com/bluewoods127/DB-2025.
Provable Policy Gradient Methods for Average-Reward Markov Potential Games
Mar 09, 2024We study Markov potential games under the infinite horizon average reward criterion. Most previous studies have been for discounted rewards. We prove that both algorithms based on independent policy gradient and independent natural policy gradient converge globally to a Nash equilibrium for the average reward criterion. To set the stage for gradient-based methods, we first establish that the average reward is a smooth function of policies and provide sensitivity bounds for the differential value functions, under certain conditions on ergodicity and the second largest eigenvalue of the underlying Markov decision process (MDP). We prove that three algorithms, policy gradient, proximal-Q, and natural policy gradient (NPG), converge to an $\epsilon$-Nash equilibrium with time complexity $O(\frac{1}{\epsilon^2})$, given a gradient/differential Q function oracle. When policy gradients have to be estimated, we propose an algorithm with $\tilde{O}(\frac{1}{\min_{s,a}\pi(a|s)\delta})$ sample complexity to achieve $\delta$ approximation error w.r.t~the $\ell_2$ norm. Equipped with the estimator, we derive the first sample complexity analysis for a policy gradient ascent algorithm, featuring a sample complexity of $\tilde{O}(1/\epsilon^5)$. Simulation studies are presented.
Natural Actor-Critic for Robust Reinforcement Learning with Function Approximation
Jul 17, 2023



We study robust reinforcement learning (RL) with the goal of determining a well-performing policy that is robust against model mismatch between the training simulator and the testing environment. Previous policy-based robust RL algorithms mainly focus on the tabular setting under uncertainty sets that facilitate robust policy evaluation, but are no longer tractable when the number of states scales up. To this end, we propose two novel uncertainty set formulations, one based on double sampling and the other on an integral probability metric. Both make large-scale robust RL tractable even when one only has access to a simulator. We propose a robust natural actor-critic (RNAC) approach that incorporates the new uncertainty sets and employs function approximation. We provide finite-time convergence guarantees for the proposed RNAC algorithm to the optimal robust policy within the function approximation error. Finally, we demonstrate the robust performance of the policy learned by our proposed RNAC approach in multiple MuJoCo environments and a real-world TurtleBot navigation task.
MMED: A Multi-domain and Multi-modality Event Dataset
Apr 09, 2019

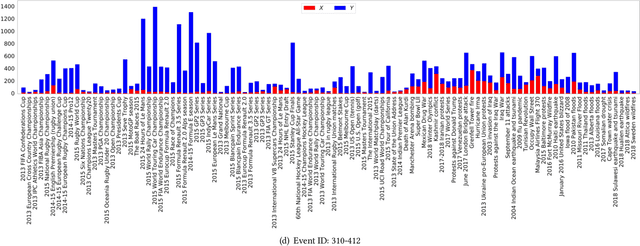
In this work, we construct and release a multi-domain and multi-modality event dataset (MMED), containing 25,165 textual news articles collected from hundreds of news media sites (e.g., Yahoo News, Google News, CNN News.) and 76,516 image posts shared on Flickr social media, which are annotated according to 412 real-world events. The dataset is collected to explore the problem of organizing heterogeneous data contributed by professionals and amateurs in different data domains, and the problem of transferring event knowledge obtained from one data domain to heterogeneous data domain, thus summarizing the data with different contributors. We hope that the release of the MMED dataset can stimulate innovate research on related challenging problems, such as event discovery, cross-modal (event) retrieval, and visual question answering, etc.