 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Physics-driven universal twin-image removal network for digital in-line holographic microscopy
Aug 08, 2023
Digital in-line holographic microscopy (DIHM) enables efficient and cost-effective computational quantitative phase imaging with a large field of view, making it valuable for studying cell motility, migration, and bio-microfluidics. However, the quality of DIHM reconstructions is compromised by twin-image noise, posing a significant challenge. Conventional methods for mitigating this noise involve complex hardware setups or time-consuming algorithms with often limited effectiveness. In this work, we propose UTIRnet, a deep learning solution for fast, robust, and universally applicable twin-image suppression, trained exclusively on numerically generated datasets. The availability of open-source UTIRnet codes facilitates its implementation in various DIHM systems without the need for extensive experimental training data. Notably, our network ensures the consistency of reconstruction results with input holograms, imparting a physics-based foundation and enhancing reliability compared to conventional deep learning approaches. Experimental verification was conducted among others on live neural glial cell culture migration sensing, which is crucial for neurodegenerative disease research.
Variational Latent Discrete Representation for Time Series Modelling
Jun 28, 2023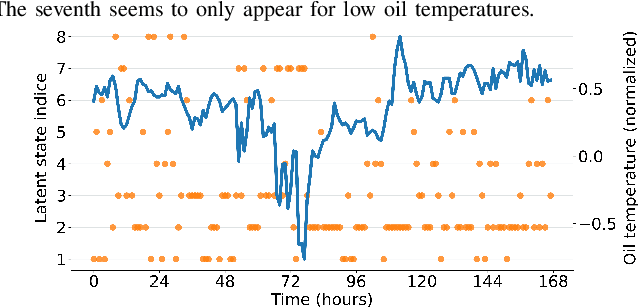
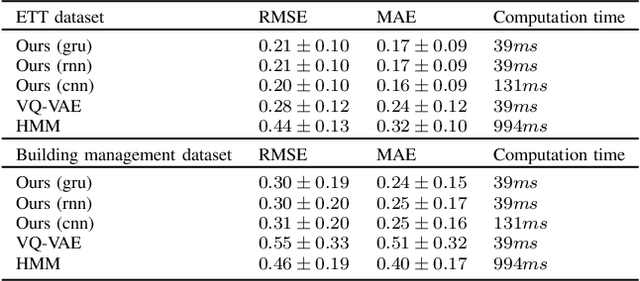
Discrete latent space models have recently achieved performance on par with their continuous counterparts in deep variational inference. While they still face various implementation challenges, these models offer the opportunity for a better interpretation of latent spaces, as well as a more direct representation of naturally discrete phenomena. Most recent approaches propose to train separately very high-dimensional prior models on the discrete latent data which is a challenging task on its own. In this paper, we introduce a latent data model where the discrete state is a Markov chain, which allows fast end-to-end training. The performance of our generative model is assessed on a building management dataset and on the publicly available Electricity Transformer Dataset.
A General Implicit Framework for Fast NeRF Composition and Rendering
Aug 09, 2023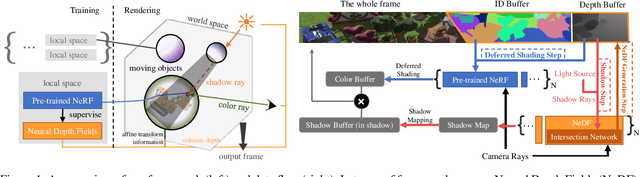

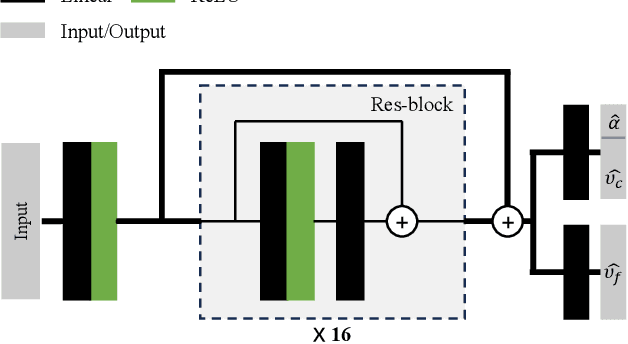
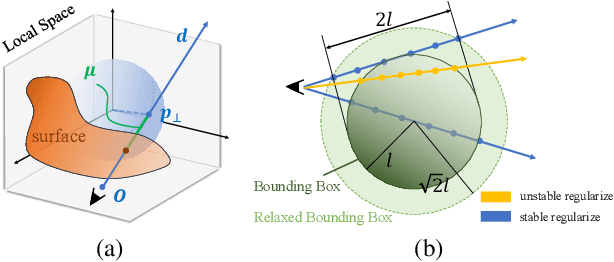
Recently, a variety of Neural radiance fields methods have garnered remarkable success in high render speed. However, current accelerating methods is specialized and not compatible for various implicit method, which prevent a real-time composition over different kinds of NeRF works. Since NeRF relies on sampling along rays, it's possible to provide a guidance generally. We propose a general implicit pipeline to rapidly compose NeRF objects. This new method enables the casting of dynamic shadows within or between objects using analytical light sources while allowing multiple NeRF objects to be seamlessly placed and rendered together with any arbitrary rigid transformations. Mainly, our work introduces a new surface representation known as Neural Depth Fields (NeDF) that quickly determines the spatial relationship between objects by allowing direct intersection computation between rays and implicit surfaces. It leverages an intersection neural network to query NeRF for acceleration instead of depending on an explicit spatial structure.Our proposed method is the first to enable both the progressive and interactive composition of NeRF objects. Additionally, it also serves as a previewing plugin for a range of existing NeRF works.
A Fast and Optimal Learning-based Path Planning Method for Planetary Rovers
Aug 09, 2023
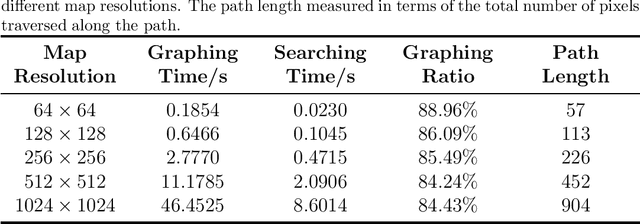

Intelligent autonomous path planning is crucial to improve the exploration efficiency of planetary rovers. In this paper, we propose a learning-based method to quickly search for optimal paths in an elevation map, which is called NNPP. The NNPP model learns semantic information about start and goal locations, as well as map representations, from numerous pre-annotated optimal path demonstrations, and produces a probabilistic distribution over each pixel representing the likelihood of it belonging to an optimal path on the map. More specifically, the paper computes the traversal cost for each grid cell from the slope, roughness and elevation difference obtained from the DEM. Subsequently, the start and goal locations are encoded using a Gaussian distribution and different location encoding parameters are analyzed for their effect on model performance. After training, the NNPP model is able to perform path planning on novel maps. Experiments show that the guidance field generated by the NNPP model can significantly reduce the search time for optimal paths under the same hardware conditions, and the advantage of NNPP increases with the scale of the map.
Evaluating Pedestrian Trajectory Prediction Methods for the Application in Autonomous Driving
Aug 09, 2023In this paper, the state of the art in the field of pedestrian trajectory prediction is evaluated alongside the constant velocity model (CVM) with respect to its applicability in autonomous vehicles. The evaluation is conducted on the widely-used ETH/UCY dataset where the Average Displacement Error (ADE) and the Final Displacement Error (FDE) are reported. To align with requirements in real-world applications, modifications are made to the input features of the initially proposed models. An ablation study is conducted to examine the influence of the observed motion history on the prediction performance, thereby establishing a better understanding of its impact. Additionally, the inference time of each model is measured to evaluate the scalability of each model when confronted with varying amounts of agents. The results demonstrate that simple models remain competitive when generating single trajectories, and certain features commonly thought of as useful have little impact on the overall performance across different architectures. Based on these findings, recommendations are proposed to guide the future development of trajectory prediction algorithms.
ChatSim: Underwater Simulation with Natural Language Prompting
Aug 09, 2023
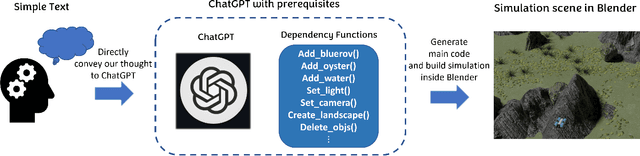
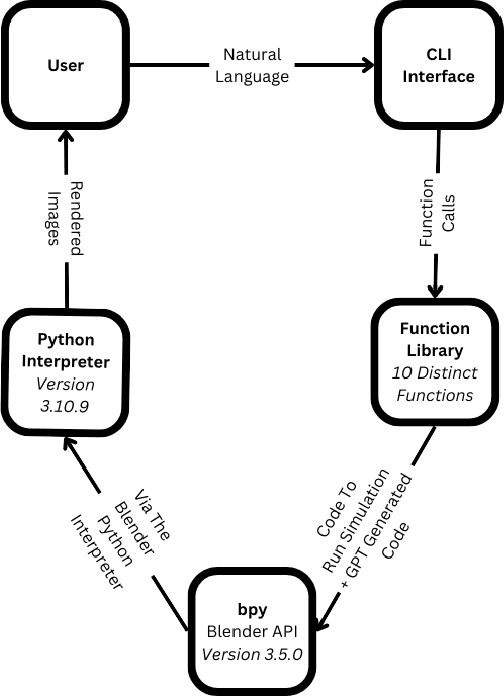

Robots are becoming an essential part of many operations including marine exploration or environmental monitoring. However, the underwater environment presents many challenges, including high pressure, limited visibility, and harsh conditions that can damage equipment. Real-world experimentation can be expensive and difficult to execute. Therefore, it is essential to simulate the performance of underwater robots in comparable environments to ensure their optimal functionality within practical real-world contexts.OysterSim generates photo-realistic images and segmentation masks of objects in marine environments, providing valuable training data for underwater computer vision applications. By integrating ChatGPT into underwater simulations, users can convey their thoughts effortlessly and intuitively create desired underwater environments without intricate coding. \invis{Moreover, researchers can realize substantial time and cost savings by evaluating their algorithms across diverse underwater conditions in the simulation.} The objective of ChatSim is to integrate Large Language Models (LLM) with a simulation environment~(OysterSim), enabling direct control of the simulated environment via natural language input. This advancement can greatly enhance the capabilities of underwater simulation, with far-reaching benefits for marine exploration and broader scientific research endeavors.
Improved Multi-Shot Diffusion-Weighted MRI with Zero-Shot Self-Supervised Learning Reconstruction
Aug 09, 2023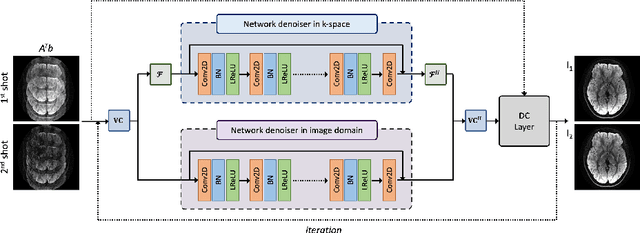
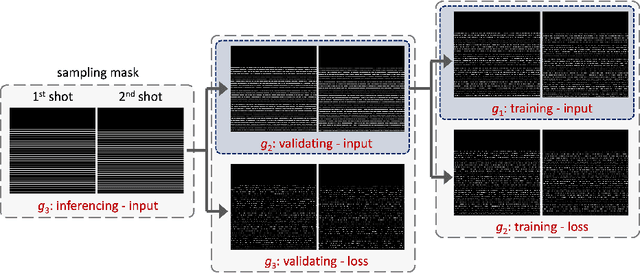
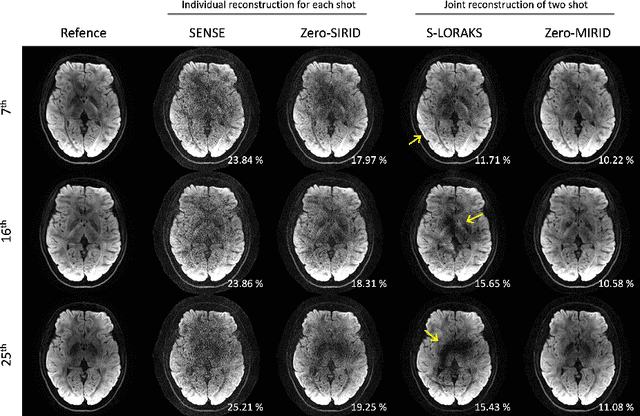
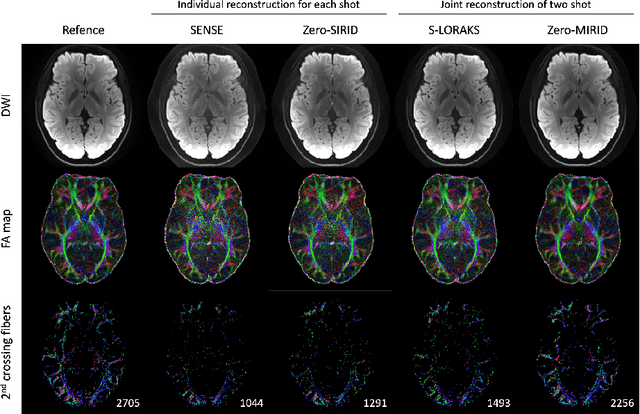
Diffusion MRI is commonly performed using echo-planar imaging (EPI) due to its rapid acquisition time. However, the resolution of diffusion-weighted images is often limited by magnetic field inhomogeneity-related artifacts and blurring induced by T2- and T2*-relaxation effects. To address these limitations, multi-shot EPI (msEPI) combined with parallel imaging techniques is frequently employed. Nevertheless, reconstructing msEPI can be challenging due to phase variation between multiple shots. In this study, we introduce a novel msEPI reconstruction approach called zero-MIRID (zero-shot self-supervised learning of Multi-shot Image Reconstruction for Improved Diffusion MRI). This method jointly reconstructs msEPI data by incorporating deep learning-based image regularization techniques. The network incorporates CNN denoisers in both k- and image-spaces, while leveraging virtual coils to enhance image reconstruction conditioning. By employing a self-supervised learning technique and dividing sampled data into three groups, the proposed approach achieves superior results compared to the state-of-the-art parallel imaging method, as demonstrated in an in-vivo experiment.
Seeing in Flowing: Adapting CLIP for Action Recognition with Motion Prompts Learning
Aug 09, 2023The Contrastive Language-Image Pre-training (CLIP) has recently shown remarkable generalization on "zero-shot" training and has applied to many downstream tasks. We explore the adaptation of CLIP to achieve a more efficient and generalized action recognition method. We propose that the key lies in explicitly modeling the motion cues flowing in video frames. To that end, we design a two-stream motion modeling block to capture motion and spatial information at the same time. And then, the obtained motion cues are utilized to drive a dynamic prompts learner to generate motion-aware prompts, which contain much semantic information concerning human actions. In addition, we propose a multimodal communication block to achieve a collaborative learning and further improve the performance. We conduct extensive experiments on HMDB-51, UCF-101, and Kinetics-400 datasets. Our method outperforms most existing state-of-the-art methods by a significant margin on "few-shot" and "zero-shot" training. We also achieve competitive performance on "closed-set" training with extremely few trainable parameters and additional computational costs.
Continual Road-Scene Semantic Segmentation via Feature-Aligned Symmetric Multi-Modal Network
Aug 09, 2023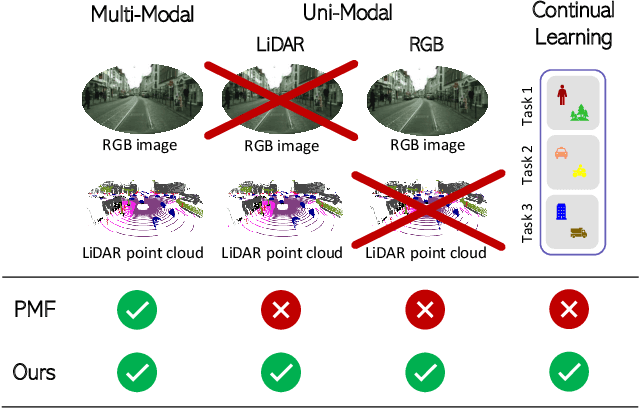
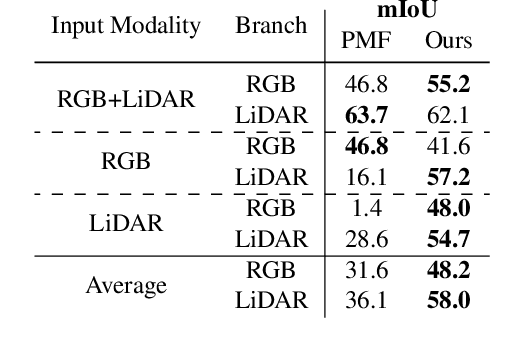
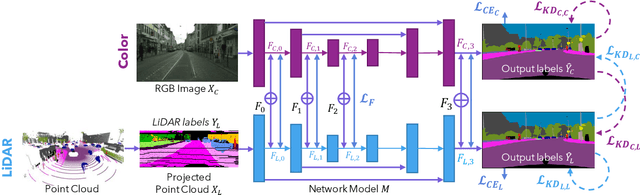

State-of-the-art multimodal semantic segmentation approaches combining LiDAR and color data are usually designed on top of asymmetric information-sharing schemes and assume that both modalities are always available. Regrettably, this strong assumption may not hold in real-world scenarios, where sensors are prone to failure or can face adverse conditions (night-time, rain, fog, etc.) that make the acquired information unreliable. Moreover, these architectures tend to fail in continual learning scenarios. In this work, we re-frame the task of multimodal semantic segmentation by enforcing a tightly-coupled feature representation and a symmetric information-sharing scheme, which allows our approach to work even when one of the input modalities is missing. This makes our model reliable even in safety-critical settings, as is the case of autonomous driving. We evaluate our approach on the SemanticKITTI dataset, comparing it with our closest competitor. We also introduce an ad-hoc continual learning scheme and show results in a class-incremental continual learning scenario that prove the effectiveness of the approach also in this setting.
Designing Cellular Networks for UAV Corridors via Bayesian Optimization
Aug 09, 2023As traditional cellular base stations (BSs) are optimized for 2D ground service, providing 3D connectivity to uncrewed aerial vehicles (UAVs) requires re-engineering of the existing infrastructure. In this paper, we propose a new methodology for designing cellular networks that cater for both ground users and UAV corridors based on Bayesian optimization. We present a case study in which we maximize the signal-to-interference-plus-noise ratio (SINR) for both populations of users by optimizing the electrical antenna tilts and the transmit power employed at each BS. Our proposed optimized network significantly boosts the UAV performance, with a 23.4dB gain in mean SINR compared to an all-downtilt, full-power baseline. At the same time, this optimal tradeoff nearly preserves the performance on the ground, even attaining a gain of 1.3dB in mean SINR with respect to said baseline. Thanks to its ability to optimize black-box stochastic functions, the proposed framework is amenable to maximize any desired function of the SINR or even the capacity per area.