 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Based Emulation of the Radio Resource Control Layer: Towards AI-Native RAN Protocols
May 22, 2025



Integrating large AI models (LAMs) into 6G mobile networks promises to redefine protocol design and control-plane intelligence by enabling autonomous, cognitive network operations. While industry concepts, such as ETSI's Experiential Networked Intelligence (ENI), envision LAM-driven agents for adaptive network slicing and intent-based management, practical implementations still face challenges in protocol literacy and real-world deployment. This paper presents an end-to-end demonstration of a LAM that generates standards-compliant, ASN.1-encoded Radio Resource Control (RRC) messages as part of control-plane procedures inside a gNB. We treat RRC messaging as a domain-specific language and fine-tune a decoder-only transformer model (LLaMA class) using parameter-efficient Low-Rank Adaptation (LoRA) on RRC messages linearized to retain their ASN.1 syntactic structure before standard byte-pair encoding tokenization. This enables combinatorial generalization over RRC protocol states while minimizing training overhead. On 30k field-test request-response pairs, our 8 B model achieves a median cosine similarity of 0.97 with ground-truth messages on an edge GPU -- a 61 % relative gain over a zero-shot LLaMA-3 8B baseline -- indicating substantially improved structural and semantic RRC fidelity. Overall, our results show that LAMs, when augmented with Radio Access Network (RAN)-specific reasoning, can directly orchestrate control-plane procedures, representing a stepping stone toward the AI-native air-interface paradigm. Beyond RRC emulation, this work lays the groundwork for future AI-native wireless standards.
Cellular Network Design for UAV Corridors via Data-driven High-dimensional Bayesian Optimization
Apr 07, 2025



We address the challenge of designing cellular networks for uncrewed aerial vehicles (UAVs) corridors through a novel data-driven approach. We assess multiple state-of-the-art high-dimensional Bayesian optimization (HD-BO) techniques to jointly optimize the cell antenna tilts and half-power beamwidth (HPBW). We find that some of these approaches achieve over 20dB gains in median SINR along UAV corridors, with negligible degradation to ground user performance. Furthermore, we explore the HD-BO's capabilities in terms of model generalization via transfer learning, where data from a previously observed scenario source is leveraged to predict the optimal solution for a new scenario target. We provide examples of scenarios where such transfer learning is successful and others where it fails. Moreover, we demonstrate that HD-BO enables multi-objective optimization, identifying optimal design trade-offs between data rates on the ground versus UAV coverage reliability. We observe that aiming to provide UAV coverage across the entire sky can lower the rates for ground users compared to setups specifically optimized for UAV corridors. Finally, we validate our approach through a case study in a real-world cellular network, where HD-BO identifies optimal and non-obvious antenna configurations that result in more than double the rates along 3D UAV corridors with negligible ground performance loss.
Towards Practical Deep Schedulers for Allocating Cellular Radio Resources
Nov 13, 2024



Machine learning methods are often suggested to address wireless network functions, such as radio packet scheduling. However, a feasible 3GPP-compliant scheduler capable of delivering fair throughput across users, while keeping a low computational complexity for 5G and beyond is still missing. To address this, we first take a critical look at previous deep scheduler efforts. Secondly, we enhance State-of-the-Art (SoTA) deep Reinforcement Learning (RL) algorithms and adapt them to train our deep scheduler. In particular, we propose novel training techniques for Proximal Policy Optimization (PPO) and a new Distributional Soft Actor-Critic Discrete (DSACD) algorithm, which outperformed other tested variants. These improvements were achieved while maintaining minimal actor network complexity, making them suitable for real-time computing environments. Additionally, the entropy learning in SACD was fine-tuned to accommodate resource allocation action spaces of varying sizes. Our proposed deep schedulers exhibited strong generalization across different bandwidths, number of MU-MIMO layers, and traffic models. Ultimately, we show that our pre-trained deep schedulers outperform their heuristic rivals in realistic and standard-compliant 5G system-level simulations.
Time-Series JEPA for Predictive Remote Control under Capacity-Limited Networks
Jun 07, 2024In remote control systems, transmitting large data volumes (e.g. video feeds) from wireless sensors to faraway controllers is challenging when the uplink channel capacity is limited (e.g. RedCap devices or massive wireless sensor networks). Furthermore, the controllers often only need the information-rich components of the original data. To address this, we propose a Time-Series Joint Embedding Predictive Architecture (TS-JEPA) and a semantic actor trained through self-supervised learning. This approach harnesses TS-JEPA's semantic representation power and predictive capabilities by capturing spatio-temporal correlations in the source data. We leverage this to optimize uplink channel utilization, while the semantic actor calculates control commands directly from the encoded representations, rather than from the original data. We test our model through multiple parallel instances of the well-known inverted cart-pole scenario, where the approach is validated through the maximization of stability under constrained uplink channel capacity.
Intent-Aware DRL-Based Uplink Dynamic Scheduler for 5G-NR
Mar 27, 2024



We investigate the problem of supporting Industrial Internet of Things user equipment (IIoT UEs) with intent (i.e., requested quality of service (QoS)) and random traffic arrival. A deep reinforcement learning (DRL) based centralized dynamic scheduler for time-frequency resources is proposed to learn how to schedule the available communication resources among the IIoT UEs. The proposed scheduler leverages an RL framework to adapt to the dynamic changes in the wireless communication system and traffic arrivals. Moreover, a graph-based reduction scheme is proposed to reduce the state and action space of the RL framework to allow fast convergence and a better learning strategy. Simulation results demonstrate the effectiveness of the proposed intelligent scheduler in guaranteeing the expressed intent of IIoT UEs compared to several traditional scheduling schemes, such as round-robin, semi-static, and heuristic approaches. The proposed scheduler also outperforms the contention-free and contention-based schemes in maximizing the number of successfully computed tasks.
Emergent Communication Protocol Learning for Task Offloading in Industrial Internet of Things
Jan 23, 2024



In this paper, we leverage a multi-agent reinforcement learning (MARL) framework to jointly learn a computation offloading decision and multichannel access policy with corresponding signaling. Specifically, the base station and industrial Internet of Things mobile devices are reinforcement learning agents that need to cooperate to execute their computation tasks within a deadline constraint. We adopt an emergent communication protocol learning framework to solve this problem. The numerical results illustrate the effectiveness of emergent communication in improving the channel access success rate and the number of successfully computed tasks compared to contention-based, contention-free, and no-communication approaches. Moreover, the proposed task offloading policy outperforms remote and local computation baselines.
Designing Cellular Networks for UAV Corridors via Bayesian Optimization
Aug 09, 2023



As traditional cellular base stations (BSs) are optimized for 2D ground service, providing 3D connectivity to uncrewed aerial vehicles (UAVs) requires re-engineering of the existing infrastructure. In this paper, we propose a new methodology for designing cellular networks that cater for both ground users and UAV corridors based on Bayesian optimization. We present a case study in which we maximize the signal-to-interference-plus-noise ratio (SINR) for both populations of users by optimizing the electrical antenna tilts and the transmit power employed at each BS. Our proposed optimized network significantly boosts the UAV performance, with a 23.4dB gain in mean SINR compared to an all-downtilt, full-power baseline. At the same time, this optimal tradeoff nearly preserves the performance on the ground, even attaining a gain of 1.3dB in mean SINR with respect to said baseline. Thanks to its ability to optimize black-box stochastic functions, the proposed framework is amenable to maximize any desired function of the SINR or even the capacity per area.
Bayesian and Multi-Armed Contextual Meta-Optimization for Efficient Wireless Radio Resource Management
Jan 16, 2023



Optimal resource allocation in modern communication networks calls for the optimization of objective functions that are only accessible via costly separate evaluations for each candidate solution. The conventional approach carries out the optimization of resource-allocation parameters for each system configuration, characterized, e.g., by topology and traffic statistics, using global search methods such as Bayesian optimization (BO). These methods tend to require a large number of iterations, and hence a large number of key performance indicator (KPI) evaluations. In this paper, we propose the use of meta-learning to transfer knowledge from data collected from related, but distinct, configurations in order to speed up optimization on new network configurations. Specifically, we combine meta-learning with BO, as well as with multi-armed bandit (MAB) optimization, with the latter having the potential advantage of operating directly on a discrete search space. Furthermore, we introduce novel contextual meta-BO and meta-MAB algorithms, in which transfer of knowledge across configurations occurs at the level of a mapping from graph-based contextual information to resource-allocation parameters. Experiments for the problem of open loop power control (OLPC) parameter optimization for the uplink of multi-cell multi-antenna systems provide insights into the potential benefits of meta-learning and contextual optimization.
Fairness Based Energy-Efficient 3D Path Planning of a Portable Access Point: A Deep Reinforcement Learning Approach
Aug 10, 2022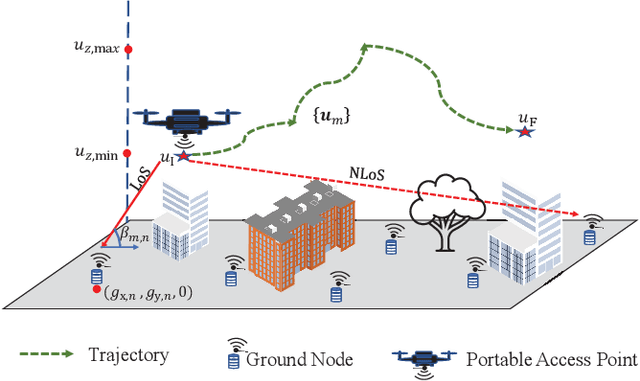
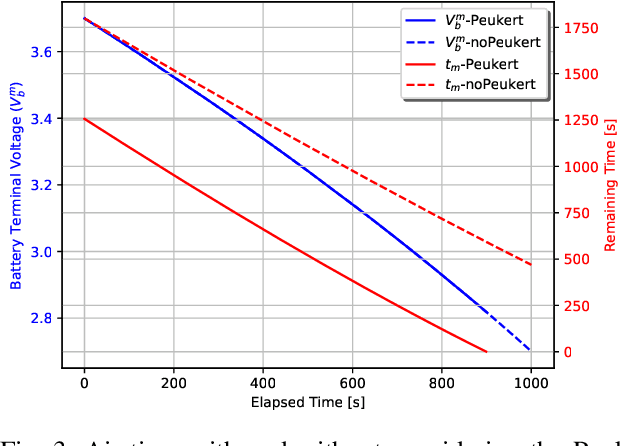
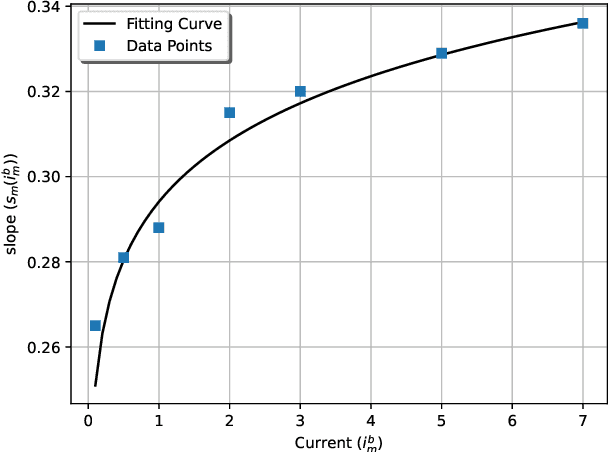
In this work, we optimize the 3D trajectory of an unmanned aerial vehicle (UAV)-based portable access point (PAP) that provides wireless services to a set of ground nodes (GNs). Moreover, as per the Peukert effect, we consider pragmatic non-linear battery discharge for the battery of the UAV. Thus, we formulate the problem in a novel manner that represents the maximization of a fairness-based energy efficiency metric and is named fair energy efficiency (FEE). The FEE metric defines a system that lays importance on both the per-user service fairness and the energy efficiency of the PAP. The formulated problem takes the form of a non-convex problem with non-tractable constraints. To obtain a solution, we represent the problem as a Markov Decision Process (MDP) with continuous state and action spaces. Considering the complexity of the solution space, we use the twin delayed deep deterministic policy gradient (TD3) actor-critic deep reinforcement learning (DRL) framework to learn a policy that maximizes the FEE of the system. We perform two types of RL training to exhibit the effectiveness of our approach: the first (offline) approach keeps the positions of the GNs the same throughout the training phase; the second approach generalizes the learned policy to any arrangement of GNs by changing the positions of GNs after each training episode. Numerical evaluations show that neglecting the Peukert effect overestimates the air-time of the PAP and can be addressed by optimally selecting the PAP's flying speed. Moreover, the user fairness, energy efficiency, and hence the FEE value of the system can be improved by efficiently moving the PAP above the GNs. As such, we notice massive FEE improvements over baseline scenarios of up to 88.31%, 272.34%, and 318.13% for suburban, urban, and dense urban environments, respectively.
Scalable Joint Learning of Wireless Multiple-Access Policies and their Signaling
Jun 08, 2022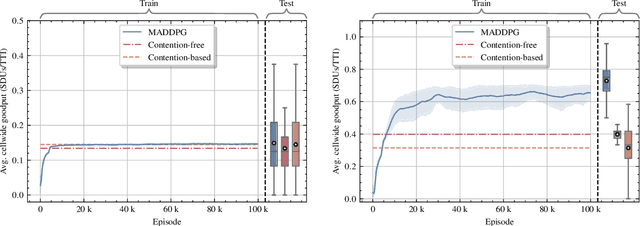
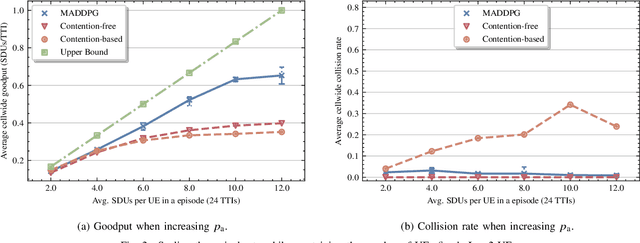
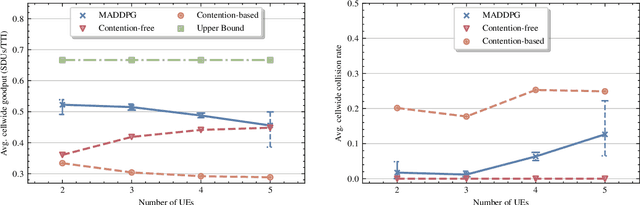
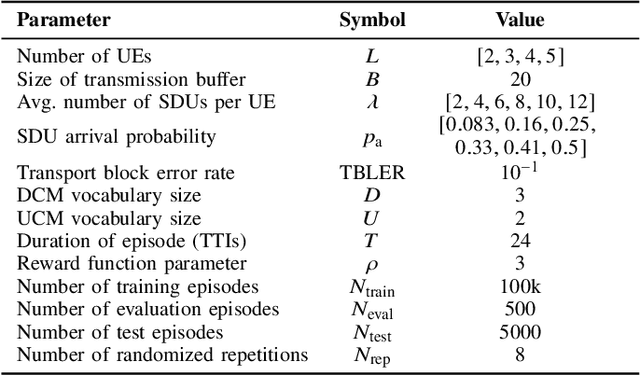
In this paper, we apply an multi-agent reinforcement learning (MARL) framework allowing the base station (BS) and the user equipments (UEs) to jointly learn a channel access policy and its signaling in a wireless multiple access scenario. In this framework, the BS and UEs are reinforcement learning (RL) agents that need to cooperate in order to deliver data. The comparison with a contention-free and a contention-based baselines shows that our framework achieves a superior performance in terms of goodput even in high traffic situations while maintaining a low collision rate. The scalability of the proposed method is studied, since it is a major problem in MARL and this paper provides the first results in order to address it.