 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PKE-RRT: Efficient Multi-Goal Path Finding Algorithm Driven by Multi-Task Learning Model
Aug 15, 2023
Multi-goal path finding (MGPF) aims to find a closed and collision-free path to visit a sequence of goals orderly. As a physical travelling salesman problem, an undirected complete graph with accurate weights is crucial for determining the visiting order. Lack of prior knowledge of local paths between vertices poses challenges in meeting the optimality and efficiency requirements of algorithms. In this study, a multi-task learning model designated Prior Knowledge Extraction (PKE), is designed to estimate the local path length between pairwise vertices as the weights of the graph. Simultaneously, a promising region and a guideline are predicted as heuristics for the path-finding process. Utilizing the outputs of the PKE model, a variant of Rapidly-exploring Random Tree (RRT) is proposed known as PKE-RRT. It effectively tackles the MGPF problem by a local planner incorporating a prioritized visiting order, which is obtained from the complete graph. Furthermore, the predicted region and guideline facilitate efficient exploration of the tree structure, enabling the algorithm to rapidly provide a sub-optimal solution. Extensive numerical experiments demonstrate the outstanding performance of the PKE-RRT for the MGPF problem with a different number of goals, in terms of calculation time, path cost, sample number, and success rate.
Reinforcement Learning (RL) Augmented Cold Start Frequency Reduction in Serverless Computing
Aug 15, 2023Function-as-a-Service is a cloud computing paradigm offering an event-driven execution model to applications. It features serverless attributes by eliminating resource management responsibilities from developers and offers transparent and on-demand scalability of applications. Typical serverless applications have stringent response time and scalability requirements and therefore rely on deployed services to provide quick and fault-tolerant feedback to clients. However, the FaaS paradigm suffers from cold starts as there is a non-negligible delay associated with on-demand function initialization. This work focuses on reducing the frequency of cold starts on the platform by using Reinforcement Learning. Our approach uses Q-learning and considers metrics such as function CPU utilization, existing function instances, and response failure rate to proactively initialize functions in advance based on the expected demand. The proposed solution was implemented on Kubeless and was evaluated using a normalised real-world function demand trace with matrix multiplication as the workload. The results demonstrate a favourable performance of the RL-based agent when compared to Kubeless' default policy and function keep-alive policy by improving throughput by up to 8.81% and reducing computation load and resource wastage by up to 55% and 37%, respectively, which is a direct outcome of reduced cold starts.
Unbiased Decisions Reduce Regret: Adversarial Domain Adaptation for the Bank Loan Problem
Aug 15, 2023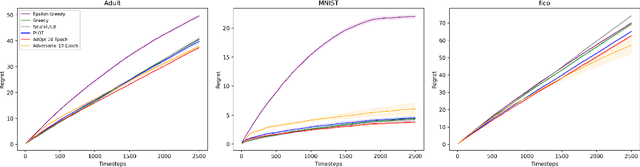

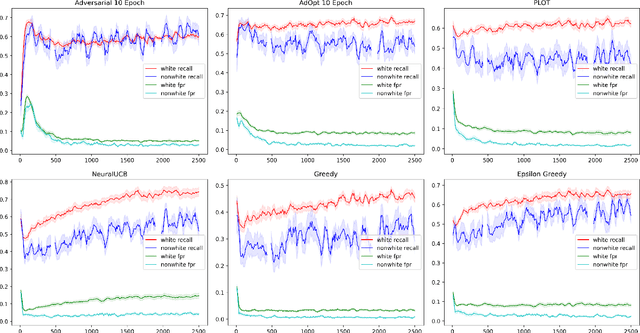

In many real world settings binary classification decisions are made based on limited data in near real-time, e.g. when assessing a loan application. We focus on a class of these problems that share a common feature: the true label is only observed when a data point is assigned a positive label by the principal, e.g. we only find out whether an applicant defaults if we accepted their loan application. As a consequence, the false rejections become self-reinforcing and cause the labelled training set, that is being continuously updated by the model decisions, to accumulate bias. Prior work mitigates this effect by injecting optimism into the model, however this comes at the cost of increased false acceptance rate. We introduce adversarial optimism (AdOpt) to directly address bias in the training set using adversarial domain adaptation. The goal of AdOpt is to learn an unbiased but informative representation of past data, by reducing the distributional shift between the set of accepted data points and all data points seen thus far. AdOpt significantly exceeds state-of-the-art performance on a set of challenging benchmark problems. Our experiments also provide initial evidence that the introduction of adversarial domain adaptation improves fairness in this setting.
SDR-GAIN: A High Real-Time Occluded Pedestrian Pose Completion Method for Autonomous Driving
Jun 10, 2023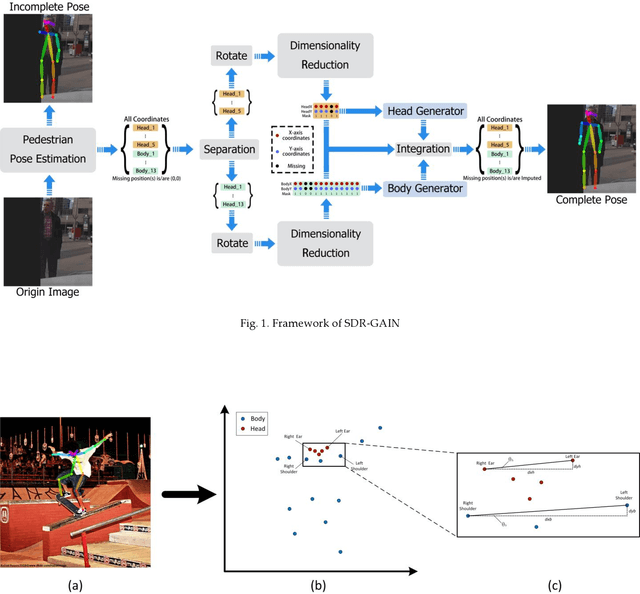
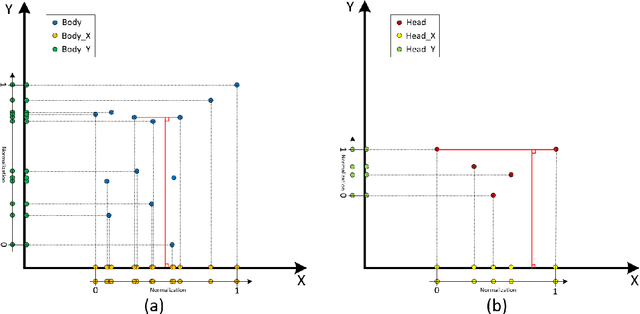
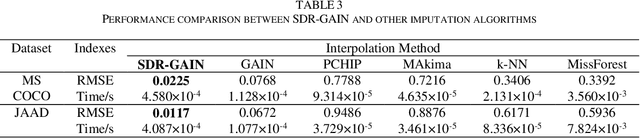
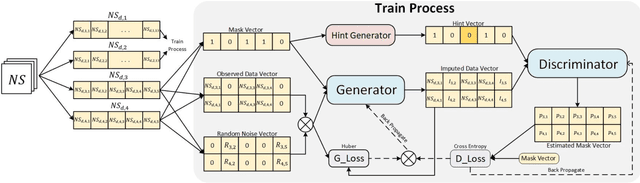
To mitigate the challenges arising from partial occlusion in human pose keypoint based pedestrian detection methods , we present a novel pedestrian pose keypoint completion method called the separation and dimensionality reduction-based generative adversarial imputation networks (SDR-GAIN). Firstly, we utilize OpenPose to estimate pedestrian poses in images. Then, we isolate the head and torso keypoints of pedestrians with incomplete keypoints due to occlusion or other factors and perform dimensionality reduction to enhance features and further unify feature distribution. Finally, we introduce two generative models based on the generative adversarial networks (GAN) framework, which incorporate Huber loss, residual structure, and L1 regularization to generate missing parts of the incomplete head and torso pose keypoints of partially occluded pedestrians, resulting in pose completion. Our experiments on MS COCO and JAAD datasets demonstrate that SDR-GAIN outperforms basic GAIN framework, interpolation methods PCHIP and MAkima, machine learning methods k-NN and MissForest in terms of pose completion task. Furthermore, the SDR-GAIN algorithm exhibits a remarkably short running time of approximately 0.4ms and boasts exceptional real-time performance. As such, it holds significant practical value in the domain of autonomous driving, wherein high system response speeds are of paramount importance. Specifically, it excels at rapidly and precisely capturing human pose key points, thus enabling an expanded range of applications for pedestrian detection tasks based on pose key points, including but not limited to pedestrian behavior recognition and prediction.
Learning to Guide Human Experts via Personalized Large Language Models
Aug 11, 2023
In learning to defer, a predictor identifies risky decisions and defers them to a human expert. One key issue with this setup is that the expert may end up over-relying on the machine's decisions, due to anchoring bias. At the same time, whenever the machine chooses the deferral option the expert has to take decisions entirely unassisted. As a remedy, we propose learning to guide (LTG), an alternative framework in which -- rather than suggesting ready-made decisions -- the machine provides guidance useful to guide decision-making, and the human is entirely responsible for coming up with a decision. We also introduce SLOG, an LTG implementation that leverages (a small amount of) human supervision to convert a generic large language model into a module capable of generating textual guidance, and present preliminary but promising results on a medical diagnosis task.
A Hybrid Machine Learning Model for Classifying Gene Mutations in Cancer using LSTM, BiLSTM, CNN, GRU, and GloVe
Aug 07, 2023This study presents an ensemble model combining LSTM, BiLSTM, CNN, GRU, and GloVe to classify gene mutations using Kaggle's Personalized Medicine: Redefining Cancer Treatment dataset. The results were compared against well-known transformers like as BERT, Electra, Roberta, XLNet, Distilbert, and their LSTM ensembles. Our model outperformed all other models in terms of accuracy, precision, recall, F1 score, and Mean Squared Error. Surprisingly, it also needed less training time, resulting in a perfect combination of performance and efficiency. This study demonstrates the utility of ensemble models for difficult tasks such as gene mutation classification.
Bayesian Flow Networks
Aug 14, 2023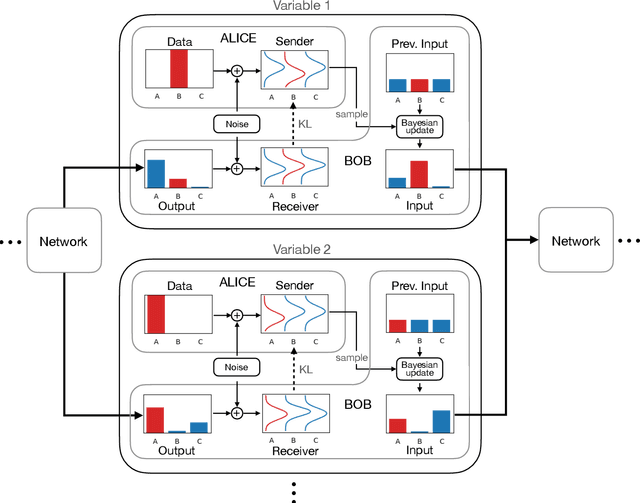
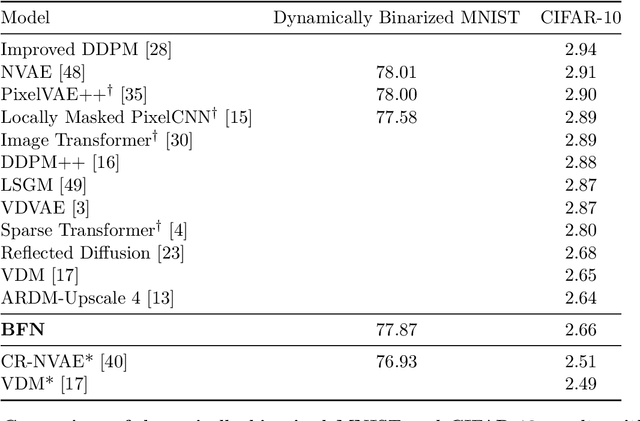
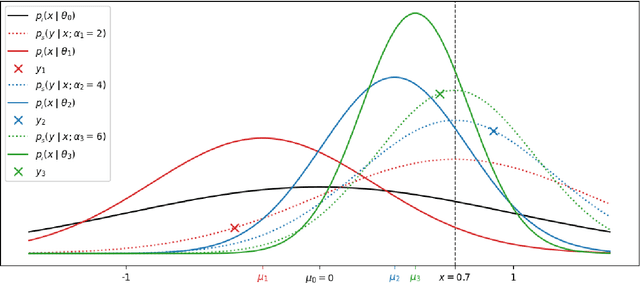

This paper introduces Bayesian Flow Networks (BFNs), a new class of generative model in which the parameters of a set of independent distributions are modified with Bayesian inference in the light of noisy data samples, then passed as input to a neural network that outputs a second, interdependent distribution. Starting from a simple prior and iteratively updating the two distributions yields a generative procedure similar to the reverse process of diffusion models; however it is conceptually simpler in that no forward process is required. Discrete and continuous-time loss functions are derived for continuous, discretised and discrete data, along with sample generation procedures. Notably, the network inputs for discrete data lie on the probability simplex, and are therefore natively differentiable, paving the way for gradient-based sample guidance and few-step generation in discrete domains such as language modelling. The loss function directly optimises data compression and places no restrictions on the network architecture. In our experiments BFNs achieve competitive log-likelihoods for image modelling on dynamically binarized MNIST and CIFAR-10, and outperform all known discrete diffusion models on the text8 character-level language modelling task.
A General Implicit Framework for Fast NeRF Composition and Rendering
Aug 14, 2023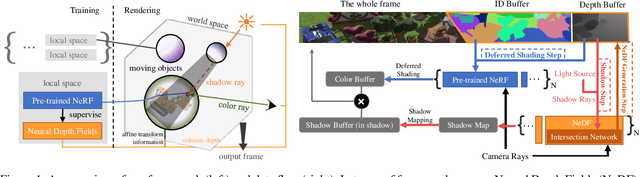

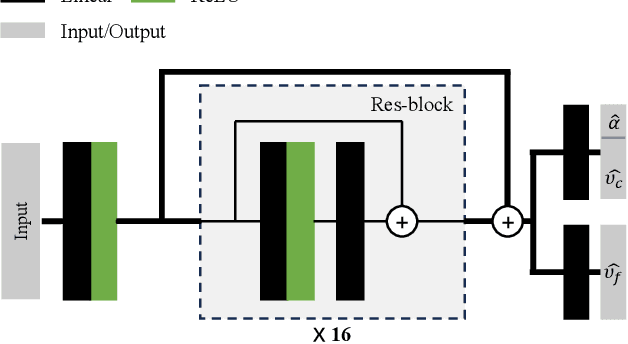
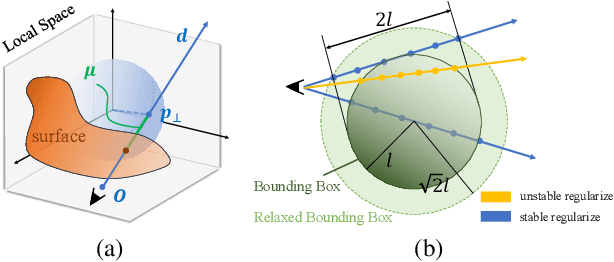
A variety of Neural Radiance Fields (NeRF) methods have recently achieved remarkable success in high render speed. However, current accelerating methods are specialized and incompatible with various implicit methods, preventing real-time composition over various types of NeRF works. Because NeRF relies on sampling along rays, it is possible to provide general guidance for acceleration. To that end, we propose a general implicit pipeline for composing NeRF objects quickly. Our method enables the casting of dynamic shadows within or between objects using analytical light sources while allowing multiple NeRF objects to be seamlessly placed and rendered together with any arbitrary rigid transformations. Mainly, our work introduces a new surface representation known as Neural Depth Fields (NeDF) that quickly determines the spatial relationship between objects by allowing direct intersection computation between rays and implicit surfaces. It leverages an intersection neural network to query NeRF for acceleration instead of depending on an explicit spatial structure.Our proposed method is the first to enable both the progressive and interactive composition of NeRF objects. Additionally, it also serves as a previewing plugin for a range of existing NeRF works.
Diving with Penguins: Detecting Penguins and their Prey in Animal-borne Underwater Videos via Deep Learning
Aug 14, 2023



African penguins (Spheniscus demersus) are an endangered species. Little is known regarding their underwater hunting strategies and associated predation success rates, yet this is essential for guiding conservation. Modern bio-logging technology has the potential to provide valuable insights, but manually analysing large amounts of data from animal-borne video recorders (AVRs) is time-consuming. In this paper, we publish an animal-borne underwater video dataset of penguins and introduce a ready-to-deploy deep learning system capable of robustly detecting penguins (mAP50@98.0%) and also instances of fish (mAP50@73.3%). We note that the detectors benefit explicitly from air-bubble learning to improve accuracy. Extending this detector towards a dual-stream behaviour recognition network, we also provide the first results for identifying predation behaviour in penguin underwater videos. Whilst results are promising, further work is required for useful applicability of predation behaviour detection in field scenarios. In summary, we provide a highly reliable underwater penguin detector, a fish detector, and a valuable first attempt towards an automated visual detection of complex behaviours in a marine predator. We publish the networks, the DivingWithPenguins video dataset, annotations, splits, and weights for full reproducibility and immediate usability by practitioners.
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
Aug 14, 2023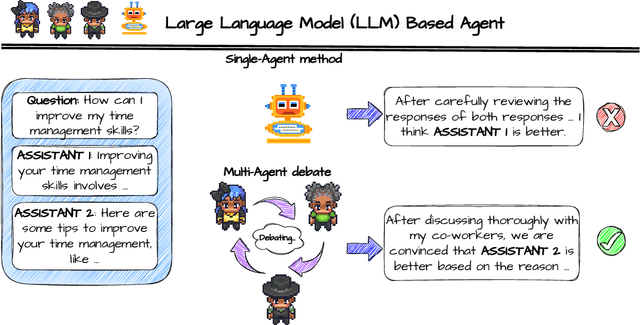
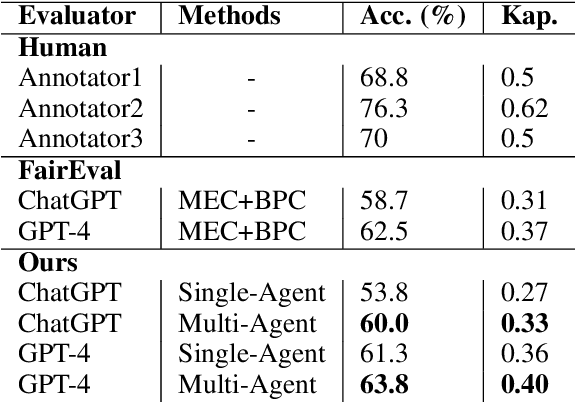
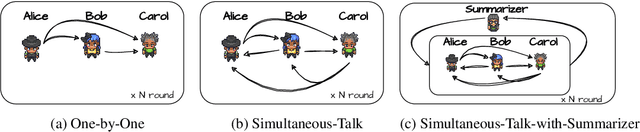
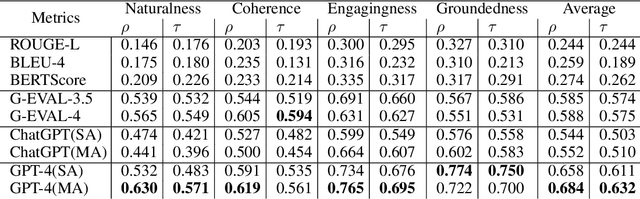
Text evaluation has historically posed significant challenges, often demanding substantial labor and time cost. With the emergence of large language models (LLMs), researchers have explored LLMs' potential as alternatives for human evaluation. While these single-agent-based approaches show promise, experimental results suggest that further advancements are needed to bridge the gap between their current effectiveness and human-level evaluation quality. Recognizing that best practices of human evaluation processes often involve multiple human annotators collaborating in the evaluation, we resort to a multi-agent debate framework, moving beyond single-agent prompting strategies. The multi-agent-based approach enables a group of LLMs to synergize with an array of intelligent counterparts, harnessing their distinct capabilities and expertise to enhance efficiency and effectiveness in handling intricate tasks. In this paper, we construct a multi-agent referee team called ChatEval to autonomously discuss and evaluate the quality of generated responses from different models on open-ended questions and traditional natural language generation (NLG) tasks. Our analysis shows that ChatEval transcends mere textual scoring, offering a human-mimicking evaluation process for reliable assessments. Our code is available at https://github.com/chanchimin/ChatEval.