 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Buy when? Survival machine learning model comparison for purchase timing
Aug 28, 2023
The value of raw data is unlocked by converting it into information and knowledge that drives decision-making. Machine Learning (ML) algorithms are capable of analysing large datasets and making accurate predictions. Market segmentation, client lifetime value, and marketing techniques have all made use of machine learning. This article examines marketing machine learning techniques such as Support Vector Machines, Genetic Algorithms, Deep Learning, and K-Means. ML is used to analyse consumer behaviour, propose items, and make other customer choices about whether or not to purchase a product or service, but it is seldom used to predict when a person will buy a product or a basket of products. In this paper, the survival models Kernel SVM, DeepSurv, Survival Random Forest, and MTLR are examined to predict tine-purchase individual decisions. Gender, Income, Location, PurchaseHistory, OnlineBehavior, Interests, PromotionsDiscounts and CustomerExperience all have an influence on purchasing time, according to the analysis. The study shows that the DeepSurv model predicted purchase completion the best. These insights assist marketers in increasing conversion rates.
Machine Unlearning Methodology base on Stochastic Teacher Network
Aug 28, 2023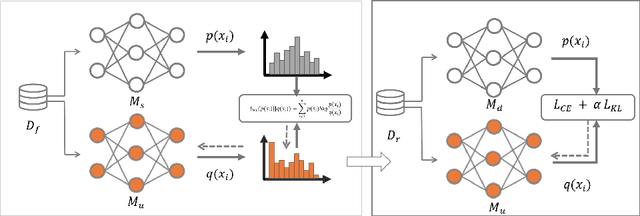
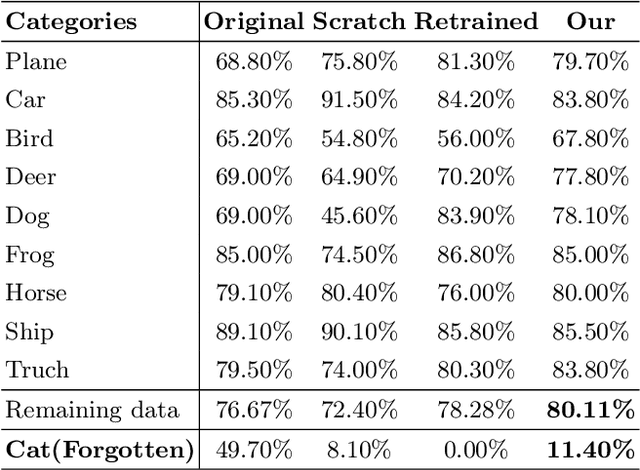
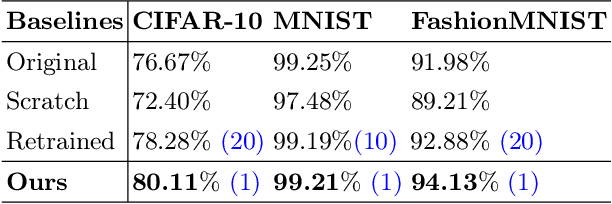
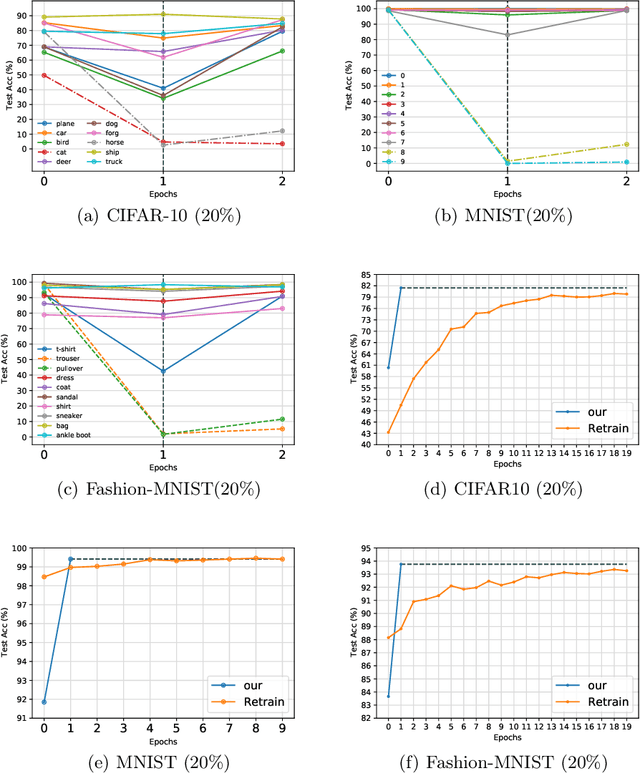
The rise of the phenomenon of the "right to be forgotten" has prompted research on machine unlearning, which grants data owners the right to actively withdraw data that has been used for model training, and requires the elimination of the contribution of that data to the model. A simple method to achieve this is to use the remaining data to retrain the model, but this is not acceptable for other data owners who continue to participate in training. Existing machine unlearning methods have been found to be ineffective in quickly removing knowledge from deep learning models. This paper proposes using a stochastic network as a teacher to expedite the mitigation of the influence caused by forgotten data on the model. We performed experiments on three datasets, and the findings demonstrate that our approach can efficiently mitigate the influence of target data on the model within a single epoch. This allows for one-time erasure and reconstruction of the model, and the reconstruction model achieves the same performance as the retrained model.
R-C-P Method: An Autonomous Volume Calculation Method Using Image Processing and Machine Vision
Aug 19, 2023
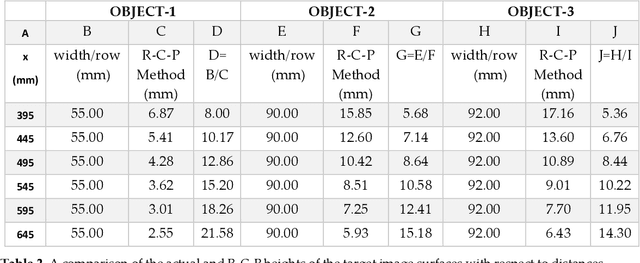

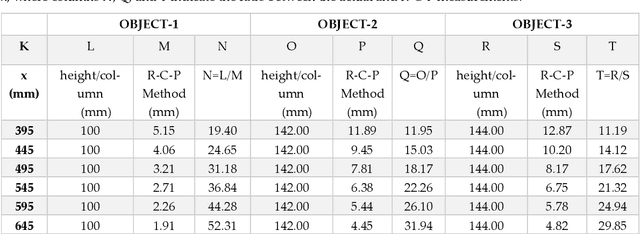
Machine vision and image processing are often used with sensors for situation awareness in autonomous systems, from industrial robots to self-driving cars. The 3D depth sensors, such as LiDAR (Light Detection and Ranging), Radar, are great invention for autonomous systems. Due to the complexity of the setup, LiDAR may not be suitable for some operational environments, for example, a space environment. This study was motivated by a desire to get real-time volumetric and change information with multiple 2D cameras instead of a depth camera. Two cameras were used to measure the dimensions of a rectangular object in real-time. The R-C-P (row-column-pixel) method is developed using image processing and edge detection. In addition to the surface areas, the R-C-P method also detects discontinuous edges or volumes. Lastly, experimental work is presented for illustration of the R-C-P method, which provides the equations for calculating surface area dimensions. Using the equations with given distance information between the object and the camera, the vision system provides the dimensions of actual objects.
Koopa: Learning Non-stationary Time Series Dynamics with Koopman Predictors
May 30, 2023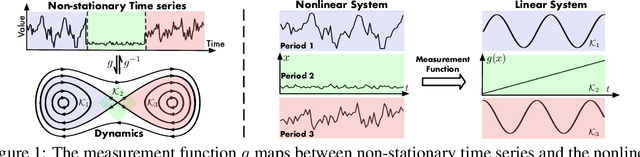
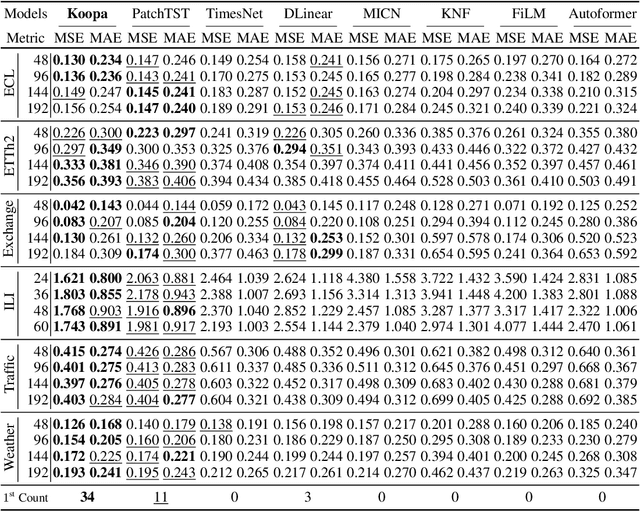
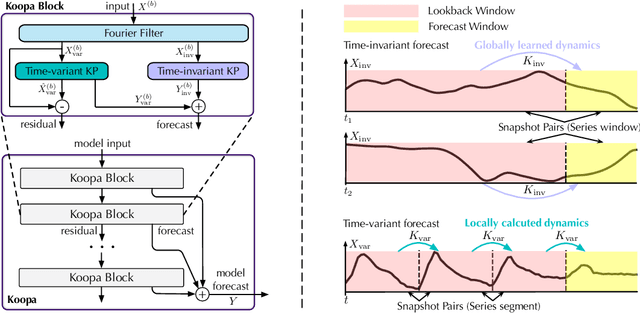

Real-world time series is characterized by intrinsic non-stationarity that poses a principal challenge for deep forecasting models. While previous models suffer from complicated series variations induced by changing temporal distribution, we tackle non-stationary time series with modern Koopman theory that fundamentally considers the underlying time-variant dynamics. Inspired by Koopman theory of portraying complex dynamical systems, we disentangle time-variant and time-invariant components from intricate non-stationary series by Fourier Filter and design Koopman Predictor to advance respective dynamics forward. Technically, we propose Koopa as a novel Koopman forecaster composed of stackable blocks that learn hierarchical dynamics. Koopa seeks measurement functions for Koopman embedding and utilizes Koopman operators as linear portraits of implicit transition. To cope with time-variant dynamics that exhibits strong locality, Koopa calculates context-aware operators in the temporal neighborhood and is able to utilize incoming ground truth to scale up forecast horizon. Besides, by integrating Koopman Predictors into deep residual structure, we ravel out the binding reconstruction loss in previous Koopman forecasters and achieve end-to-end forecasting objective optimization. Compared with the state-of-the-art model, Koopa achieves competitive performance while saving 77.3% training time and 76.0% memory.
Integrated Approach of Gearbox Fault Diagnosis
Aug 27, 2023Gearbox fault diagnosis is one of the most important parts in any industrial systems. Failure of components inside gearbox can lead to a catastrophic failure, uneven breakdown, and financial losses in industrial organization. In that case intelligent maintenance of the gearbox comes into context. This paper presents an integrated gearbox fault diagnosis approach which can easily deploy in online condition monitoring. This work introduces a nonparametric data preprocessing technique i.e., calculus enhanced energy operator (CEEO) to preserve the characteristics frequencies in the noisy and inferred vibrational signal. A set of time domain and spectral domain features are calculated from the raw and CEEO vibration signal and inputted to the multiclass support vector machine (MCSVM) to diagnose the faults on the system. An effective comparison between raw signal and CEEO signal are presented to show the impact of CEEO in gearbox fault diagnosis. The obtained results of this work look very promising and can be implemented in any type of industrial system due to its nonparametric nature.
Dyadic Reinforcement Learning
Aug 27, 2023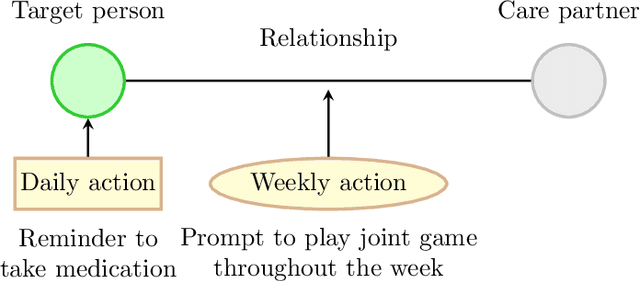

Mobile health aims to enhance health outcomes by delivering interventions to individuals as they go about their daily life. The involvement of care partners and social support networks often proves crucial in helping individuals managing burdensome medical conditions. This presents opportunities in mobile health to design interventions that target the dyadic relationship -- the relationship between a target person and their care partner -- with the aim of enhancing social support. In this paper, we develop dyadic RL, an online reinforcement learning algorithm designed to personalize intervention delivery based on contextual factors and past responses of a target person and their care partner. Here, multiple sets of interventions impact the dyad across multiple time intervals. The developed dyadic RL is Bayesian and hierarchical. We formally introduce the problem setup, develop dyadic RL and establish a regret bound. We demonstrate dyadic RL's empirical performance through simulation studies on both toy scenarios and on a realistic test bed constructed from data collected in a mobile health study.
Advancing Intra-operative Precision: Dynamic Data-Driven Non-Rigid Registration for Enhanced Brain Tumor Resection in Image-Guided Neurosurgery
Aug 18, 2023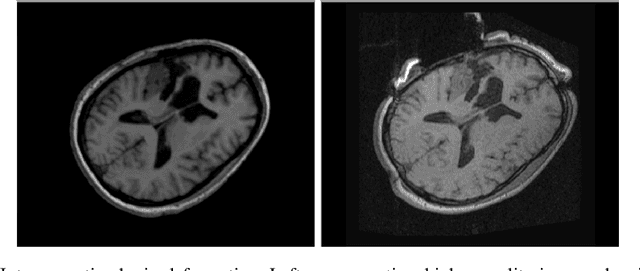

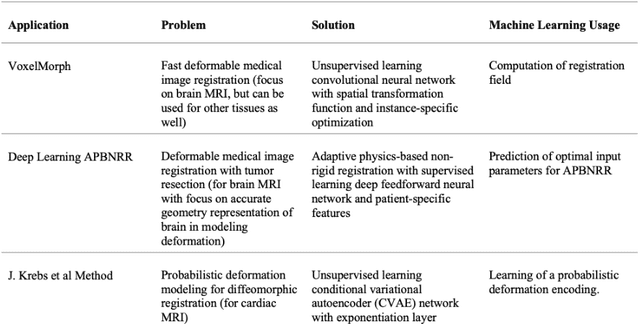
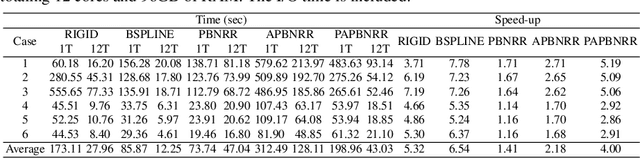
During neurosurgery, medical images of the brain are used to locate tumors and critical structures, but brain tissue shifts make pre-operative images unreliable for accurate removal of tumors. Intra-operative imaging can track these deformations but is not a substitute for pre-operative data. To address this, we use Dynamic Data-Driven Non-Rigid Registration (NRR), a complex and time-consuming image processing operation that adjusts the pre-operative image data to account for intra-operative brain shift. Our review explores a specific NRR method for registering brain MRI during image-guided neurosurgery and examines various strategies for improving the accuracy and speed of the NRR method. We demonstrate that our implementation enables NRR results to be delivered within clinical time constraints while leveraging Distributed Computing and Machine Learning to enhance registration accuracy by identifying optimal parameters for the NRR method. Additionally, we highlight challenges associated with its use in the operating room.
Dynamic 3D Gaussians: Tracking by Persistent Dynamic View Synthesis
Aug 18, 2023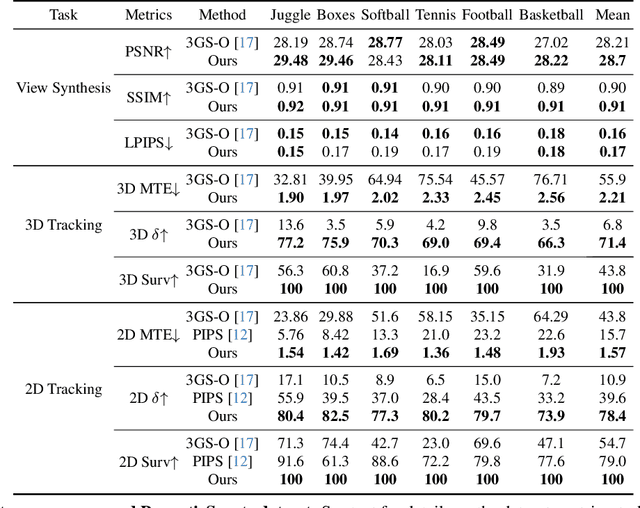

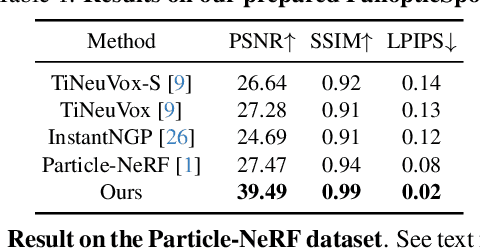

We present a method that simultaneously addresses the tasks of dynamic scene novel-view synthesis and six degree-of-freedom (6-DOF) tracking of all dense scene elements. We follow an analysis-by-synthesis framework, inspired by recent work that models scenes as a collection of 3D Gaussians which are optimized to reconstruct input images via differentiable rendering. To model dynamic scenes, we allow Gaussians to move and rotate over time while enforcing that they have persistent color, opacity, and size. By regularizing Gaussians' motion and rotation with local-rigidity constraints, we show that our Dynamic 3D Gaussians correctly model the same area of physical space over time, including the rotation of that space. Dense 6-DOF tracking and dynamic reconstruction emerges naturally from persistent dynamic view synthesis, without requiring any correspondence or flow as input. We demonstrate a large number of downstream applications enabled by our representation, including first-person view synthesis, dynamic compositional scene synthesis, and 4D video editing.
Context Aware Query Rewriting for Text Rankers using LLM
Aug 31, 2023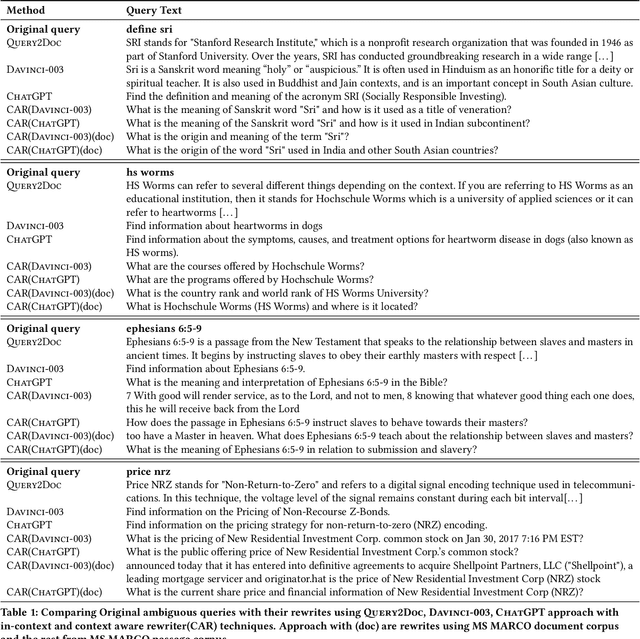
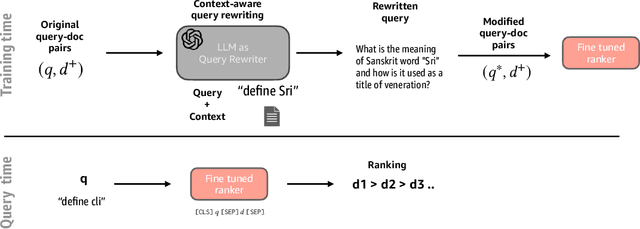

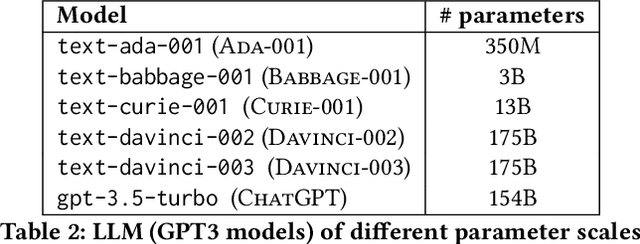
Query rewriting refers to an established family of approaches that are applied to underspecified and ambiguous queries to overcome the vocabulary mismatch problem in document ranking. Queries are typically rewritten during query processing time for better query modelling for the downstream ranker. With the advent of large-language models (LLMs), there have been initial investigations into using generative approaches to generate pseudo documents to tackle this inherent vocabulary gap. In this work, we analyze the utility of LLMs for improved query rewriting for text ranking tasks. We find that there are two inherent limitations of using LLMs as query re-writers -- concept drift when using only queries as prompts and large inference costs during query processing. We adopt a simple, yet surprisingly effective, approach called context aware query rewriting (CAR) to leverage the benefits of LLMs for query understanding. Firstly, we rewrite ambiguous training queries by context-aware prompting of LLMs, where we use only relevant documents as context.Unlike existing approaches, we use LLM-based query rewriting only during the training phase. Eventually, a ranker is fine-tuned on the rewritten queries instead of the original queries during training. In our extensive experiments, we find that fine-tuning a ranker using re-written queries offers a significant improvement of up to 33% on the passage ranking task and up to 28% on the document ranking task when compared to the baseline performance of using original queries.
Privacy-Preserving Medical Image Classification through Deep Learning and Matrix Decomposition
Aug 31, 2023Deep learning (DL)-based solutions have been extensively researched in the medical domain in recent years, enhancing the efficacy of diagnosis, planning, and treatment. Since the usage of health-related data is strictly regulated, processing medical records outside the hospital environment for developing and using DL models demands robust data protection measures. At the same time, it can be challenging to guarantee that a DL solution delivers a minimum level of performance when being trained on secured data, without being specifically designed for the given task. Our approach uses singular value decomposition (SVD) and principal component analysis (PCA) to obfuscate the medical images before employing them in the DL analysis. The capability of DL algorithms to extract relevant information from secured data is assessed on a task of angiographic view classification based on obfuscated frames. The security level is probed by simulated artificial intelligence (AI)-based reconstruction attacks, considering two threat actors with different prior knowledge of the targeted data. The degree of privacy is quantitatively measured using similarity indices. Although a trade-off between privacy and accuracy should be considered, the proposed technique allows for training the angiographic view classifier exclusively on secured data with satisfactory performance and with no computational overhead, model adaptation, or hyperparameter tuning. While the obfuscated medical image content is well protected against human perception, the hypothetical reconstruction attack proved that it is also difficult to recover the complete information of the original frames.
* 6 pages, 9 figures, Published in: 2023 31st Mediterranean Conference on Control and Automation (MED)