 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep learning in medical image registration: introduction and survey
Sep 01, 2023


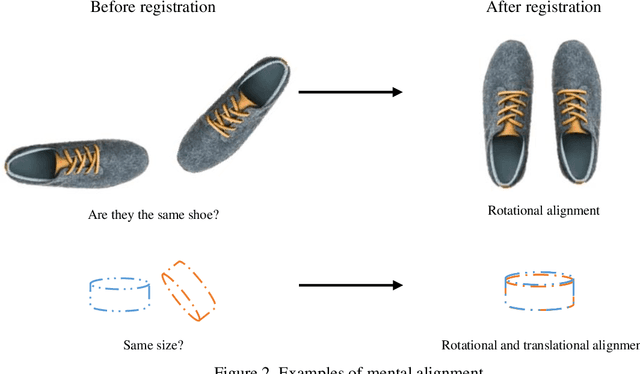
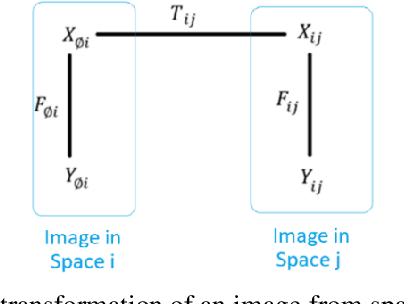
Image registration (IR) is a process that deforms images to align them with respect to a reference space, making it easier for medical practitioners to examine various medical images in a standardized reference frame, such as having the same rotation and scale. This document introduces image registration using a simple numeric example. It provides a definition of image registration along with a space-oriented symbolic representation. This review covers various aspects of image transformations, including affine, deformable, invertible, and bidirectional transformations, as well as medical image registration algorithms such as Voxelmorph, Demons, SyN, Iterative Closest Point, and SynthMorph. It also explores atlas-based registration and multistage image registration techniques, including coarse-fine and pyramid approaches. Furthermore, this survey paper discusses medical image registration taxonomies, datasets, evaluation measures, such as correlation-based metrics, segmentation-based metrics, processing time, and model size. It also explores applications in image-guided surgery, motion tracking, and tumor diagnosis. Finally, the document addresses future research directions, including the further development of transformers.
Learning Shared Safety Constraints from Multi-task Demonstrations
Sep 01, 2023Regardless of the particular task we want them to perform in an environment, there are often shared safety constraints we want our agents to respect. For example, regardless of whether it is making a sandwich or clearing the table, a kitchen robot should not break a plate. Manually specifying such a constraint can be both time-consuming and error-prone. We show how to learn constraints from expert demonstrations of safe task completion by extending inverse reinforcement learning (IRL) techniques to the space of constraints. Intuitively, we learn constraints that forbid highly rewarding behavior that the expert could have taken but chose not to. Unfortunately, the constraint learning problem is rather ill-posed and typically leads to overly conservative constraints that forbid all behavior that the expert did not take. We counter this by leveraging diverse demonstrations that naturally occur in multi-task settings to learn a tighter set of constraints. We validate our method with simulation experiments on high-dimensional continuous control tasks.
Stochastic Configuration Machines for Industrial Artificial Intelligence
Sep 01, 2023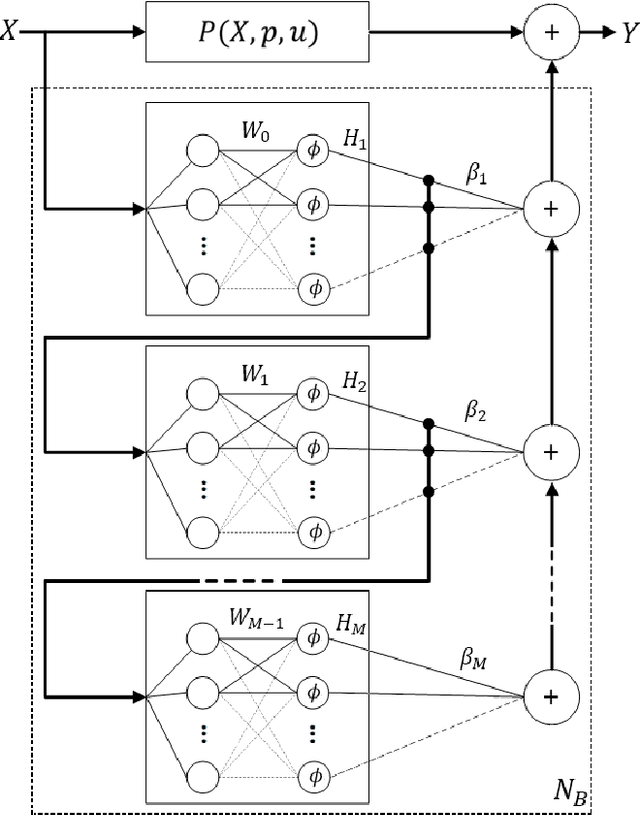
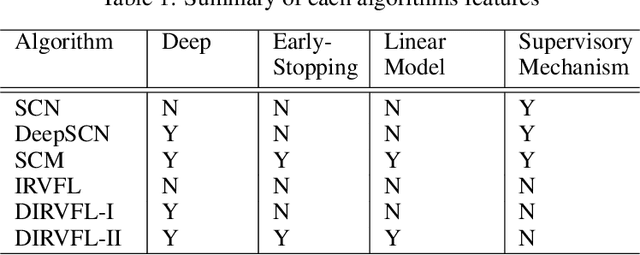
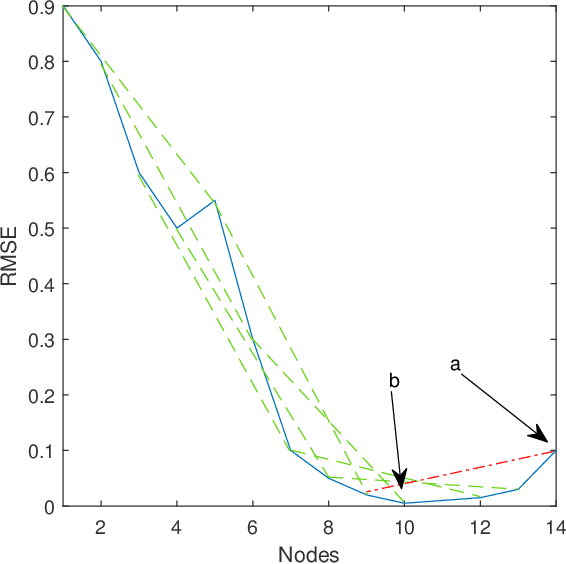
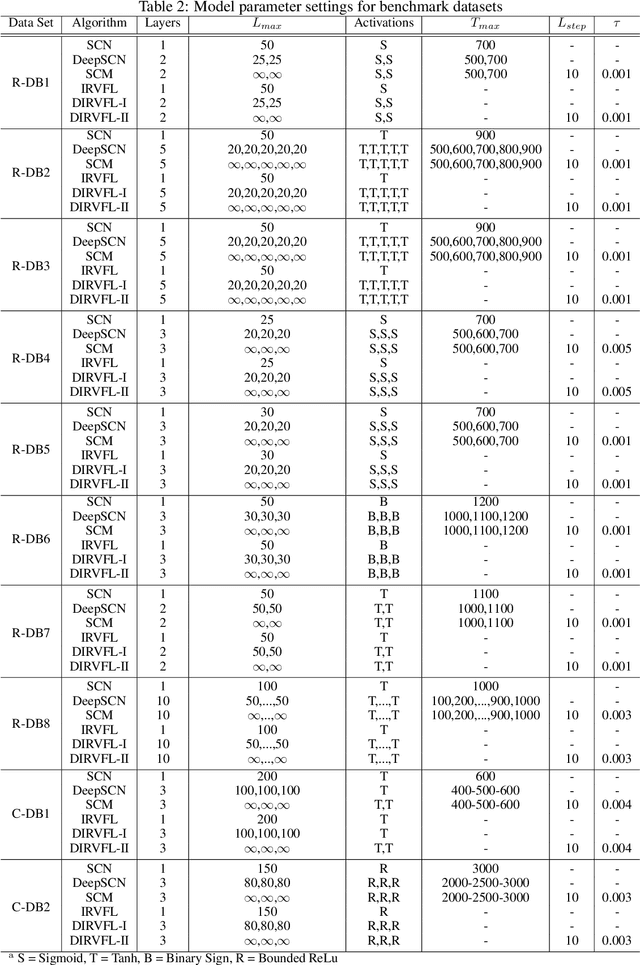
Real-time predictive modelling with desired accuracy is highly expected in industrial artificial intelligence (IAI), where neural networks play a key role. Neural networks in IAI require powerful, high-performance computing devices to operate a large number of floating point data. Based on stochastic configuration networks (SCNs), this paper proposes a new randomized learner model, termed stochastic configuration machines (SCMs), to stress effective modelling and data size saving that are useful and valuable for industrial applications. Compared to SCNs and random vector functional-link (RVFL) nets with binarized implementation, the model storage of SCMs can be significantly compressed while retaining favourable prediction performance. Besides the architecture of the SCM learner model and its learning algorithm, as an important part of this contribution, we also provide a theoretical basis on the learning capacity of SCMs by analysing the model's complexity. Experimental studies are carried out over some benchmark datasets and three industrial applications. The results demonstrate that SCM has great potential for dealing with industrial data analytics.
MeDM: Mediating Image Diffusion Models for Video-to-Video Translation with Temporal Correspondence Guidance
Sep 01, 2023
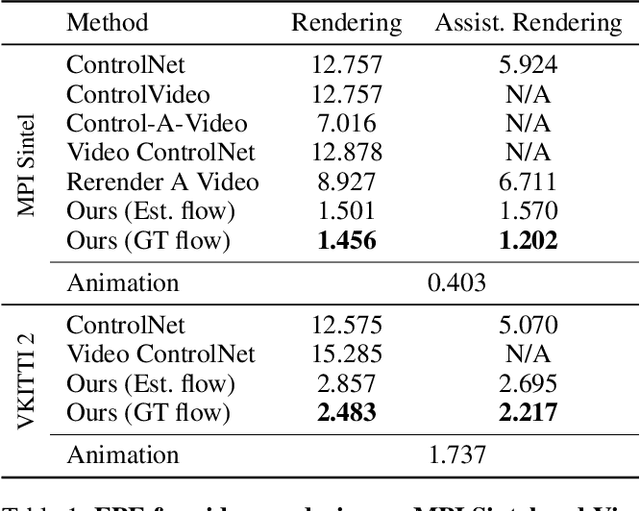
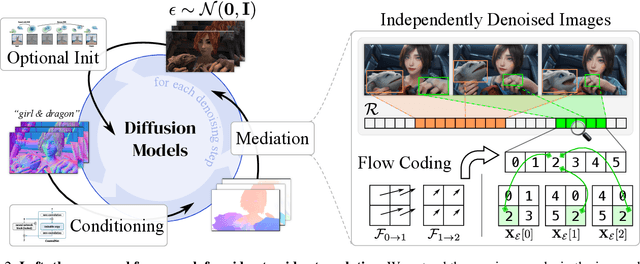
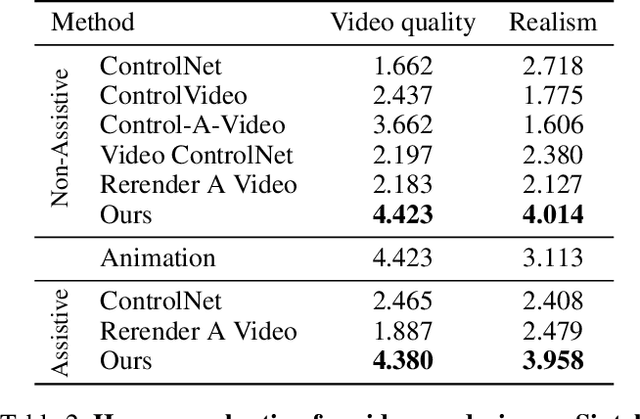
This study introduces an efficient and effective method, MeDM, that utilizes pre-trained image Diffusion Models for video-to-video translation with consistent temporal flow. The proposed framework can render videos from scene position information, such as a normal G-buffer, or perform text-guided editing on videos captured in real-world scenarios. We employ explicit optical flows to construct a practical coding that enforces physical constraints on generated frames and mediates independent frame-wise scores. By leveraging this coding, maintaining temporal consistency in the generated videos can be framed as an optimization problem with a closed-form solution. To ensure compatibility with Stable Diffusion, we also suggest a workaround for modifying observed-space scores in latent-space Diffusion Models. Notably, MeDM does not require fine-tuning or test-time optimization of the Diffusion Models. Through extensive qualitative, quantitative, and subjective experiments on various benchmarks, the study demonstrates the effectiveness and superiority of the proposed approach. Project page can be found at https://medm2023.github.io
Learning Perturbations to Explain Time Series Predictions
May 30, 2023Explaining predictions based on multivariate time series data carries the additional difficulty of handling not only multiple features, but also time dependencies. It matters not only what happened, but also when, and the same feature could have a very different impact on a prediction depending on this time information. Previous work has used perturbation-based saliency methods to tackle this issue, perturbing an input using a trainable mask to discover which features at which times are driving the predictions. However these methods introduce fixed perturbations, inspired from similar methods on static data, while there seems to be little motivation to do so on temporal data. In this work, we aim to explain predictions by learning not only masks, but also associated perturbations. We empirically show that learning these perturbations significantly improves the quality of these explanations on time series data.
LibreFace: An Open-Source Toolkit for Deep Facial Expression Analysis
Aug 24, 2023
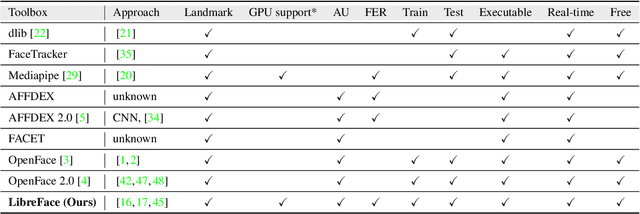
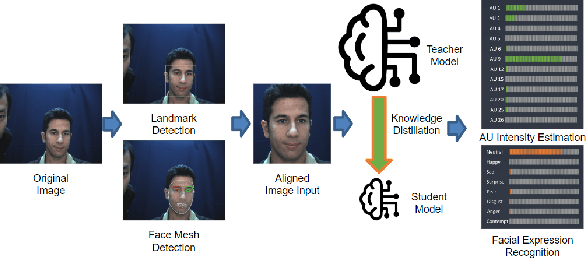

Facial expression analysis is an important tool for human-computer interaction. In this paper, we introduce LibreFace, an open-source toolkit for facial expression analysis. This open-source toolbox offers real-time and offline analysis of facial behavior through deep learning models, including facial action unit (AU) detection, AU intensity estimation, and facial expression recognition. To accomplish this, we employ several techniques, including the utilization of a large-scale pre-trained network, feature-wise knowledge distillation, and task-specific fine-tuning. These approaches are designed to effectively and accurately analyze facial expressions by leveraging visual information, thereby facilitating the implementation of real-time interactive applications. In terms of Action Unit (AU) intensity estimation, we achieve a Pearson Correlation Coefficient (PCC) of 0.63 on DISFA, which is 7% higher than the performance of OpenFace 2.0 while maintaining highly-efficient inference that runs two times faster than OpenFace 2.0. Despite being compact, our model also demonstrates competitive performance to state-of-the-art facial expression analysis methods on AffecNet, FFHQ, and RAF-DB. Our code will be released at https://github.com/ihp-lab/LibreFace
Efficient Real-time Smoke Filtration with 3D LiDAR for Search and Rescue with Autonomous Heterogeneous Robotic Systems
Aug 14, 2023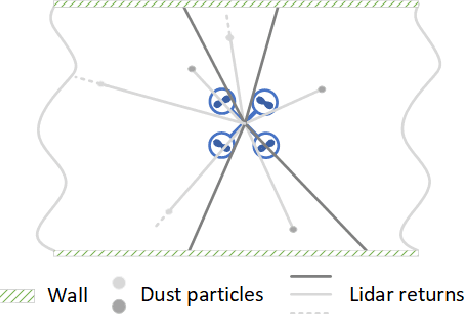
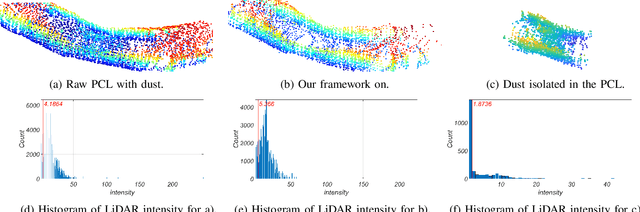


Search and Rescue (SAR) missions in harsh and unstructured Sub-Terranean (Sub-T) environments in the presence of aerosol particles have recently become the main focus in the field of robotics. Aerosol particles such as smoke and dust directly affect the performance of any mobile robotic platform due to their reliance on their onboard perception systems for autonomous navigation and localization in Global Navigation Satellite System (GNSS)-denied environments. Although obstacle avoidance and object detection algorithms are robust to the presence of noise to some degree, their performance directly relies on the quality of captured data by onboard sensors such as Light Detection And Ranging (LiDAR) and camera. Thus, this paper proposes a novel modular agnostic filtration pipeline based on intensity and spatial information such as local point density for removal of detected smoke particles from Point Cloud (PCL) prior to its utilization for collision detection. Furthermore, the efficacy of the proposed framework in the presence of smoke during multiple frontier exploration missions is investigated while the experimental results are presented to facilitate comparison with other methodologies and their computational impact. This provides valuable insight to the research community for better utilization of filtration schemes based on available computation resources while considering the safe autonomous navigation of mobile robots.
FishMOT: A Simple and Effective Method for Fish Tracking Based on IoU Matching
Sep 06, 2023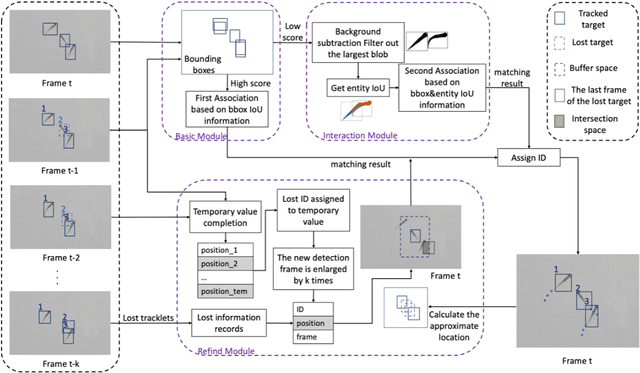

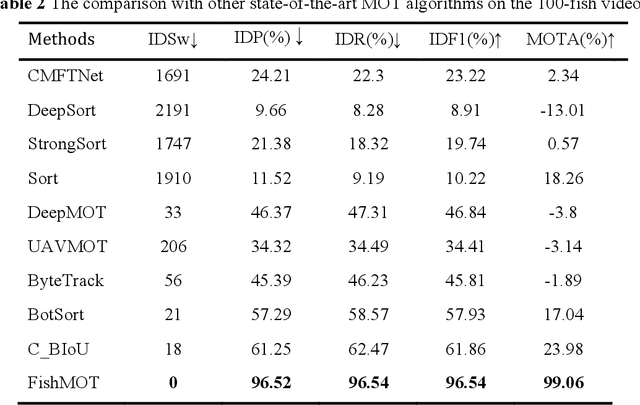
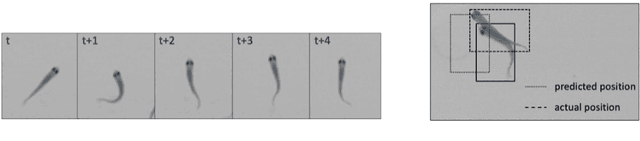
The tracking of various fish species plays a profoundly significant role in understanding the behavior of individual fish and their groups. Present tracking methods suffer from issues of low accuracy or poor robustness. In order to address these concerns, this paper proposes a novel tracking approach, named FishMOT (Fish Multiple Object Tracking). This method combines object detection techniques with the IoU matching algorithm, thereby achieving efficient, precise, and robust fish detection and tracking. Diverging from other approaches, this method eliminates the need for multiple feature extractions and identity assignments for each individual, instead directly utilizing the output results of the detector for tracking, thereby significantly reducing computational time and storage space. Furthermore, this method imposes minimal requirements on factors such as video quality and variations in individual appearance. As long as the detector can accurately locate and identify fish, effective tracking can be achieved. This approach enhances robustness and generalizability. Moreover, the algorithm employed in this method addresses the issue of missed detections without relying on complex feature matching or graph optimization algorithms. This contributes to improved accuracy and reliability. Experimental trials were conducted in the open-source video dataset provided by idtracker.ai, and comparisons were made with state-of-the-art detector-based multi-object tracking methods. Additionally, comparisons were made with idtracker.ai and TRex, two tools that demonstrate exceptional performance in the field of animal tracking. The experimental results demonstrate that the proposed method outperforms other approaches in various evaluation metrics, exhibiting faster speed and lower memory requirements. The source codes and pre-trained models are available at: https://github.com/gakkistar/FishMOT
Towards Unsupervised Graph Completion Learning on Graphs with Features and Structure Missing
Sep 06, 2023In recent years, graph neural networks (GNN) have achieved significant developments in a variety of graph analytical tasks. Nevertheless, GNN's superior performance will suffer from serious damage when the collected node features or structure relationships are partially missing owning to numerous unpredictable factors. Recently emerged graph completion learning (GCL) has received increasing attention, which aims to reconstruct the missing node features or structure relationships under the guidance of a specifically supervised task. Although these proposed GCL methods have made great success, they still exist the following problems: the reliance on labels, the bias of the reconstructed node features and structure relationships. Besides, the generalization ability of the existing GCL still faces a huge challenge when both collected node features and structure relationships are partially missing at the same time. To solve the above issues, we propose a more general GCL framework with the aid of self-supervised learning for improving the task performance of the existing GNN variants on graphs with features and structure missing, termed unsupervised GCL (UGCL). Specifically, to avoid the mismatch between missing node features and structure during the message-passing process of GNN, we separate the feature reconstruction and structure reconstruction and design its personalized model in turn. Then, a dual contrastive loss on the structure level and feature level is introduced to maximize the mutual information of node representations from feature reconstructing and structure reconstructing paths for providing more supervision signals. Finally, the reconstructed node features and structure can be applied to the downstream node classification task. Extensive experiments on eight datasets, three GNN variants and five missing rates demonstrate the effectiveness of our proposed method.
Recovering a Molecule's 3D Dynamics from Liquid-phase Electron Microscopy Movies
Aug 23, 2023The dynamics of biomolecules are crucial for our understanding of their functioning in living systems. However, current 3D imaging techniques, such as cryogenic electron microscopy (cryo-EM), require freezing the sample, which limits the observation of their conformational changes in real time. The innovative liquid-phase electron microscopy (liquid-phase EM) technique allows molecules to be placed in the native liquid environment, providing a unique opportunity to observe their dynamics. In this paper, we propose TEMPOR, a Temporal Electron MicroscoPy Object Reconstruction algorithm for liquid-phase EM that leverages an implicit neural representation (INR) and a dynamical variational auto-encoder (DVAE) to recover time series of molecular structures. We demonstrate its advantages in recovering different motion dynamics from two simulated datasets, 7bcq and Cas9. To our knowledge, our work is the first attempt to directly recover 3D structures of a temporally-varying particle from liquid-phase EM movies. It provides a promising new approach for studying molecules' 3D dynamics in structural biology.