 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Phase-Specific Augmented Reality Guidance for Microscopic Cataract Surgery Using Long-Short Spatiotemporal Aggregation Transformer
Sep 11, 2023
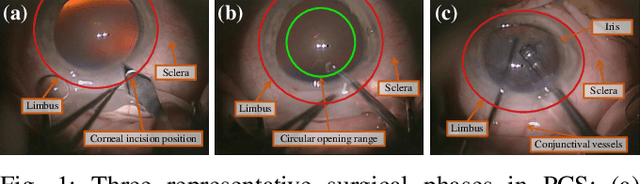
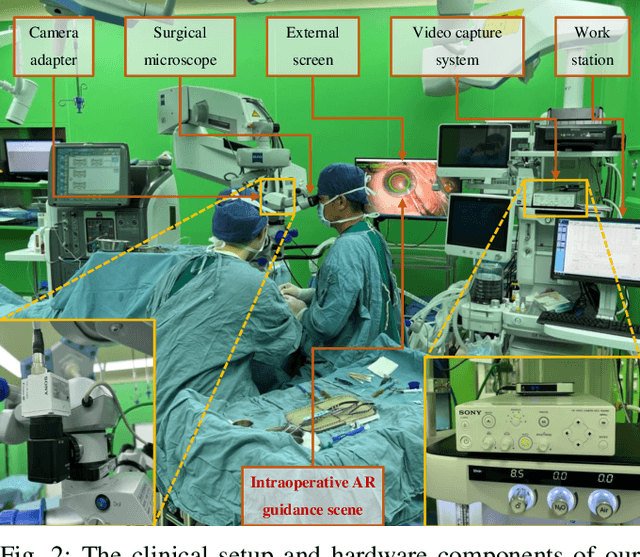
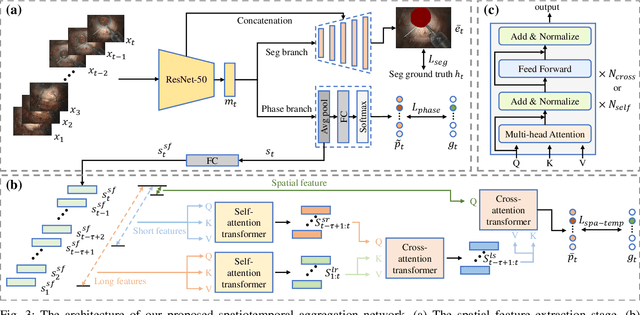
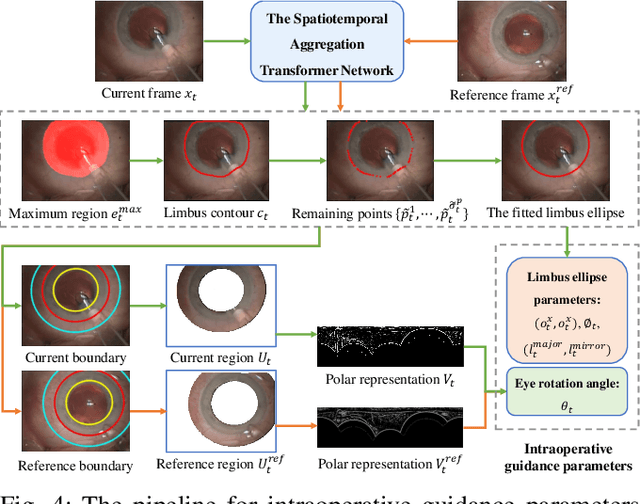
Phacoemulsification cataract surgery (PCS) is a routine procedure conducted using a surgical microscope, heavily reliant on the skill of the ophthalmologist. While existing PCS guidance systems extract valuable information from surgical microscopic videos to enhance intraoperative proficiency, they suffer from non-phasespecific guidance, leading to redundant visual information. In this study, our major contribution is the development of a novel phase-specific augmented reality (AR) guidance system, which offers tailored AR information corresponding to the recognized surgical phase. Leveraging the inherent quasi-standardized nature of PCS procedures, we propose a two-stage surgical microscopic video recognition network. In the first stage, we implement a multi-task learning structure to segment the surgical limbus region and extract limbus region-focused spatial feature for each frame. In the second stage, we propose the long-short spatiotemporal aggregation transformer (LS-SAT) network to model local fine-grained and global temporal relationships, and combine the extracted spatial features to recognize the current surgical phase. Additionally, we collaborate closely with ophthalmologists to design AR visual cues by utilizing techniques such as limbus ellipse fitting and regional restricted normal cross-correlation rotation computation. We evaluated the network on publicly available and in-house datasets, with comparison results demonstrating its superior performance compared to related works. Ablation results further validated the effectiveness of the limbus region-focused spatial feature extractor and the combination of temporal features. Furthermore, the developed system was evaluated in a clinical setup, with results indicating remarkable accuracy and real-time performance. underscoring its potential for clinical applications.
KD-FixMatch: Knowledge Distillation Siamese Neural Networks
Sep 11, 2023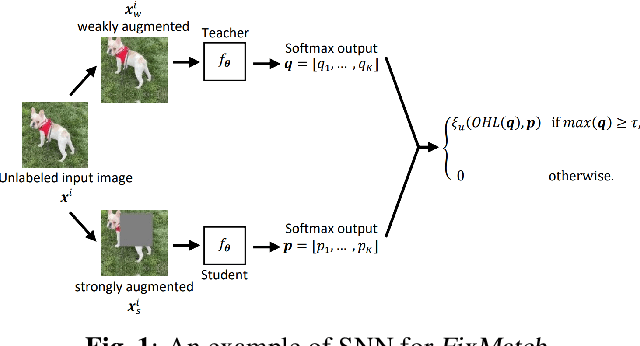
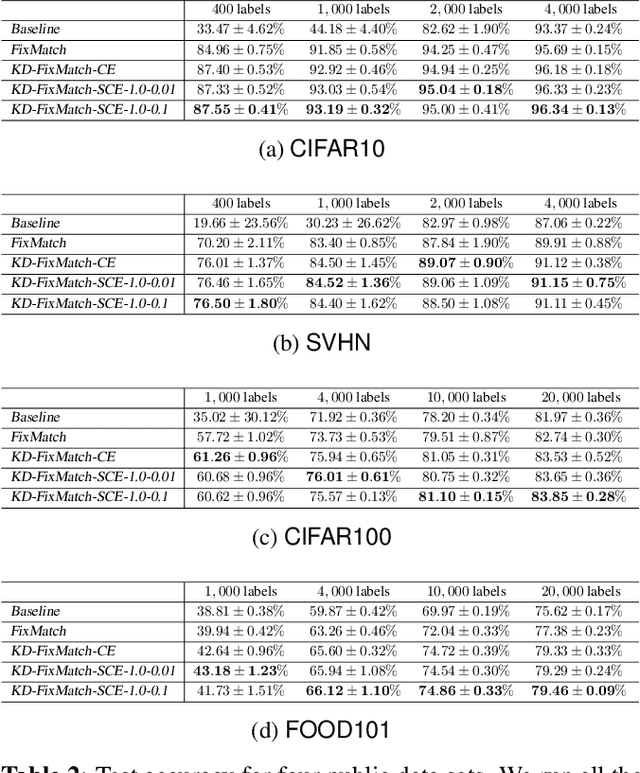
Semi-supervised learning (SSL) has become a crucial approach in deep learning as a way to address the challenge of limited labeled data. The success of deep neural networks heavily relies on the availability of large-scale high-quality labeled data. However, the process of data labeling is time-consuming and unscalable, leading to shortages in labeled data. SSL aims to tackle this problem by leveraging additional unlabeled data in the training process. One of the popular SSL algorithms, FixMatch, trains identical weight-sharing teacher and student networks simultaneously using a siamese neural network (SNN). However, it is prone to performance degradation when the pseudo labels are heavily noisy in the early training stage. We present KD-FixMatch, a novel SSL algorithm that addresses the limitations of FixMatch by incorporating knowledge distillation. The algorithm utilizes a combination of sequential and simultaneous training of SNNs to enhance performance and reduce performance degradation. Firstly, an outer SNN is trained using labeled and unlabeled data. After that, the network of the well-trained outer SNN generates pseudo labels for the unlabeled data, from which a subset of unlabeled data with trusted pseudo labels is then carefully created through high-confidence sampling and deep embedding clustering. Finally, an inner SNN is trained with the labeled data, the unlabeled data, and the subset of unlabeled data with trusted pseudo labels. Experiments on four public data sets demonstrate that KD-FixMatch outperforms FixMatch in all cases. Our results indicate that KD-FixMatch has a better training starting point that leads to improved model performance compared to FixMatch.
Grid-based Hybrid 3DMA GNSS and Terrestrial Positioning
Sep 11, 2023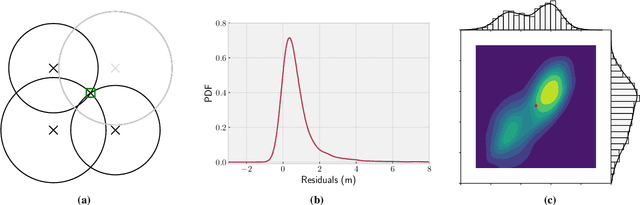
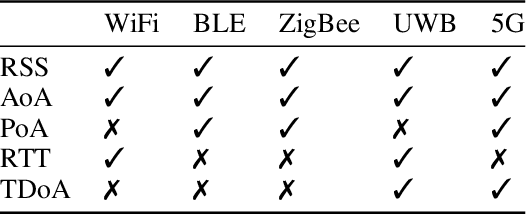

The paper discusses the increasing use of hybridized sensor information for GNSS-based localization and navigation, including the use of 3D map-aided GNSS positioning and terrestrial systems based on different geometric measurement principles. However, both GNSS and terrestrial systems are subject to negative impacts from the propagation environment, which can violate the assumptions of conventionally applied parametric state estimators. Furthermore, dynamic parametric state estimation does not account for multi-modalities within the state space leading to an information loss within the prediction step. In addition, the synchronization of non-deterministic multi-rate measurement systems needs to be accounted. In order to address these challenges, the paper proposes the use of a non-parametric filtering method, specifically a 3DMA multi-epoch Grid Filter, for the tight integration of GNSS and terrestrial signals. Specifically, the fusion of GNSS, Ultra-wide Band (UWB) and vehicle motion data is introduced based on a discrete state representation. Algorithmic challenges, including the use of different measurement models and time synchronization, are addressed. In order to evaluate the proposed method, real-world tests were conducted on an urban automotive testbed in both static and dynamic scenarios. We empirically show that we achieve sub-meter accuracy in the static scenario by averaging a positioning error of $0.64$ m, whereas in the dynamic scenario the average positioning error amounts to $1.62$ m. The paper provides a proof-of-concept of the introduced method and shows the feasibility of the inclusion of terrestrial signals in a 3DMA positioning framework in order to further enhance localization in GNSS-degraded environments.
A Comparative Analysis of Deep Reinforcement Learning-based xApps in O-RAN
Sep 11, 2023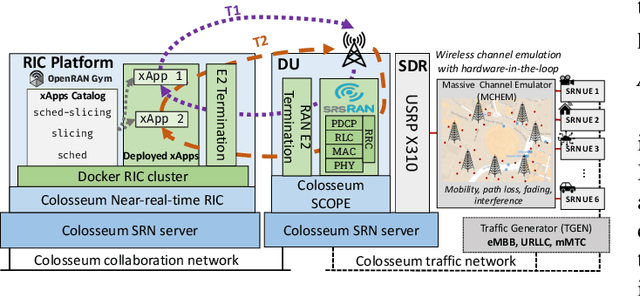
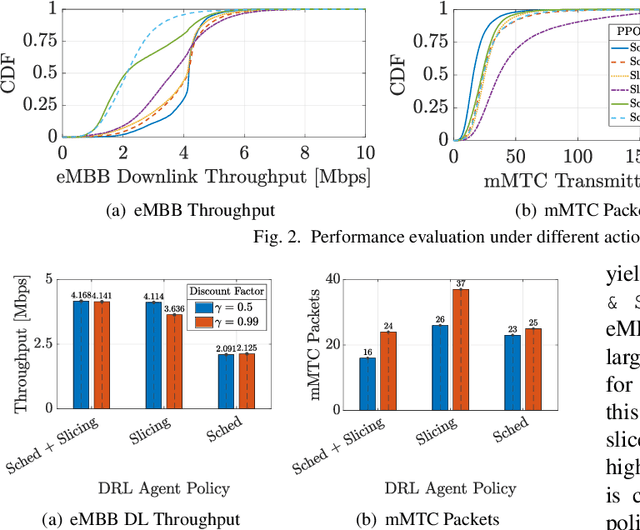
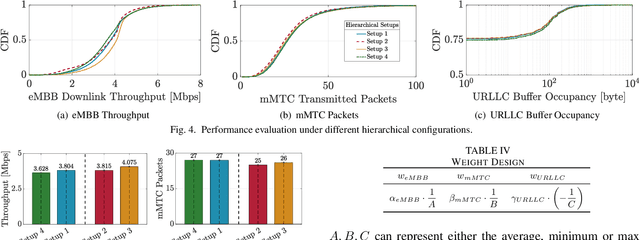
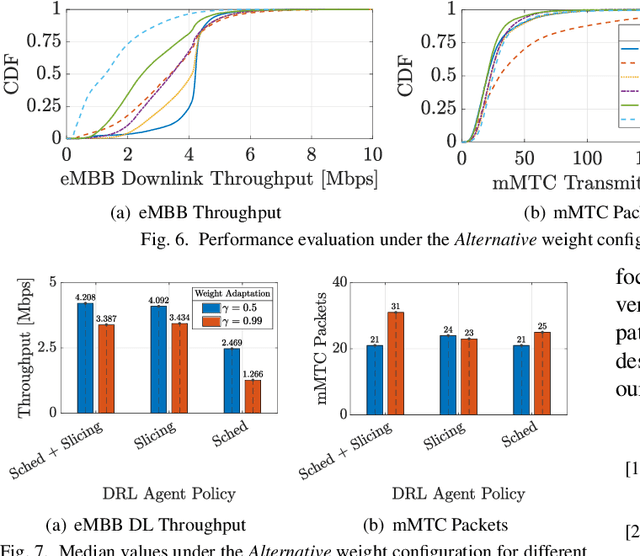
The highly heterogeneous ecosystem of Next Generation (NextG) wireless communication systems calls for novel networking paradigms where functionalities and operations can be dynamically and optimally reconfigured in real time to adapt to changing traffic conditions and satisfy stringent and diverse Quality of Service (QoS) demands. Open Radio Access Network (RAN) technologies, and specifically those being standardized by the O-RAN Alliance, make it possible to integrate network intelligence into the once monolithic RAN via intelligent applications, namely, xApps and rApps. These applications enable flexible control of the network resources and functionalities, network management, and orchestration through data-driven control loops. Despite recent work demonstrating the effectiveness of Deep Reinforcement Learning (DRL) in controlling O-RAN systems, how to design these solutions in a way that does not create conflicts and unfair resource allocation policies is still an open challenge. In this paper, we perform a comparative analysis where we dissect the impact of different DRL-based xApp designs on network performance. Specifically, we benchmark 12 different xApps that embed DRL agents trained using different reward functions, with different action spaces and with the ability to hierarchically control different network parameters. We prototype and evaluate these xApps on Colosseum, the world's largest O-RAN-compliant wireless network emulator with hardware-in-the-loop. We share the lessons learned and discuss our experimental results, which demonstrate how certain design choices deliver the highest performance while others might result in a competitive behavior between different classes of traffic with similar objectives.
CrisisTransformers: Pre-trained language models and sentence encoders for crisis-related social media texts
Sep 11, 2023
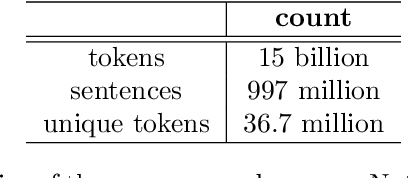
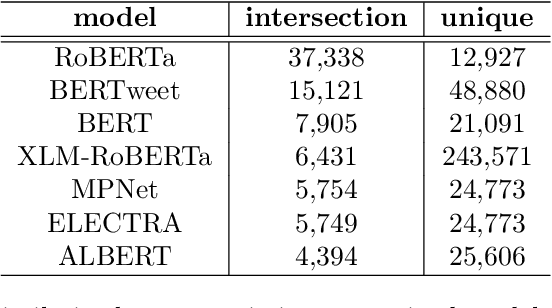
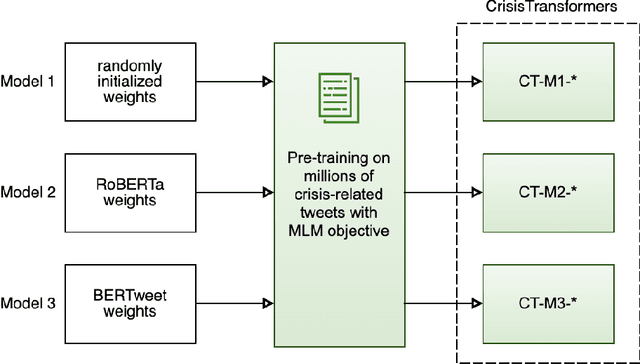
Social media platforms play an essential role in crisis communication, but analyzing crisis-related social media texts is challenging due to their informal nature. Transformer-based pre-trained models like BERT and RoBERTa have shown success in various NLP tasks, but they are not tailored for crisis-related texts. Furthermore, general-purpose sentence encoders are used to generate sentence embeddings, regardless of the textual complexities in crisis-related texts. Advances in applications like text classification, semantic search, and clustering contribute to effective processing of crisis-related texts, which is essential for emergency responders to gain a comprehensive view of a crisis event, whether historical or real-time. To address these gaps in crisis informatics literature, this study introduces CrisisTransformers, an ensemble of pre-trained language models and sentence encoders trained on an extensive corpus of over 15 billion word tokens from tweets associated with more than 30 crisis events, including disease outbreaks, natural disasters, conflicts, and other critical incidents. We evaluate existing models and CrisisTransformers on 18 crisis-specific public datasets. Our pre-trained models outperform strong baselines across all datasets in classification tasks, and our best-performing sentence encoder improves the state-of-the-art by 17.43% in sentence encoding tasks. Additionally, we investigate the impact of model initialization on convergence and evaluate the significance of domain-specific models in generating semantically meaningful sentence embeddings. All models are publicly released (https://huggingface.co/crisistransformers), with the anticipation that they will serve as a robust baseline for tasks involving the analysis of crisis-related social media texts.
Robust Visual Tracking by Motion Analyzing
Sep 06, 2023
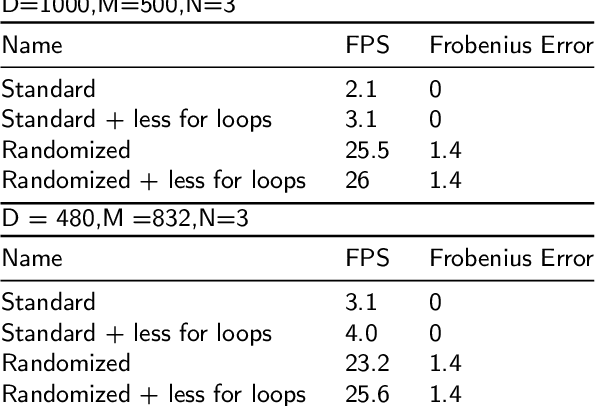
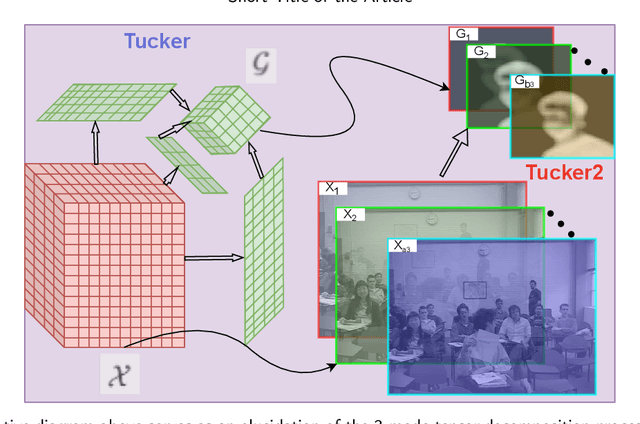
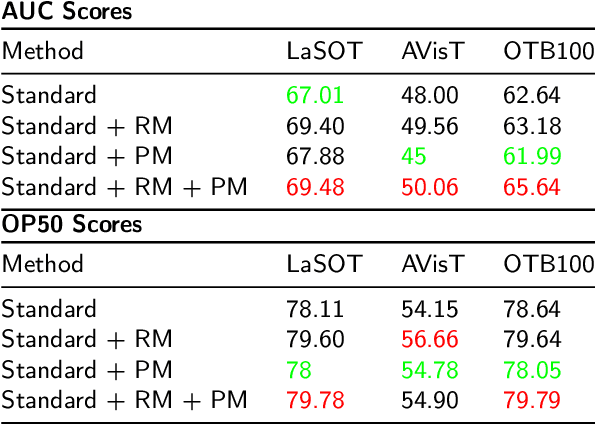
In recent years, Video Object Segmentation (VOS) has emerged as a complementary method to Video Object Tracking (VOT). VOS focuses on classifying all the pixels around the target, allowing for precise shape labeling, while VOT primarily focuses on the approximate region where the target might be. However, traditional segmentation modules usually classify pixels frame by frame, disregarding information between adjacent frames. In this paper, we propose a new algorithm that addresses this limitation by analyzing the motion pattern using the inherent tensor structure. The tensor structure, obtained through Tucker2 tensor decomposition, proves to be effective in describing the target's motion. By incorporating this information, we achieved competitive results on Four benchmarks LaSOT\cite{fan2019lasot}, AVisT\cite{noman2022avist}, OTB100\cite{7001050}, and GOT-10k\cite{huang2019got} LaSOT\cite{fan2019lasot} with SOTA. Furthermore, the proposed tracker is capable of real-time operation, adding value to its practical application.
Testing properties of distributions in the streaming model
Sep 06, 2023We study distribution testing in the standard access model and the conditional access model when the memory available to the testing algorithm is bounded. In both scenarios, the samples appear in an online fashion and the goal is to test the properties of distribution using an optimal number of samples subject to a memory constraint on how many samples can be stored at a given time. First, we provide a trade-off between the sample complexity and the space complexity for testing identity when the samples are drawn according to the conditional access oracle. We then show that we can learn a succinct representation of a monotone distribution efficiently with a memory constraint on the number of samples that are stored that is almost optimal. We also show that the algorithm for monotone distributions can be extended to a larger class of decomposable distributions.
BigVSAN: Enhancing GAN-based Neural Vocoders with Slicing Adversarial Network
Sep 06, 2023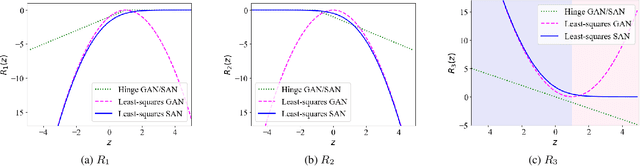

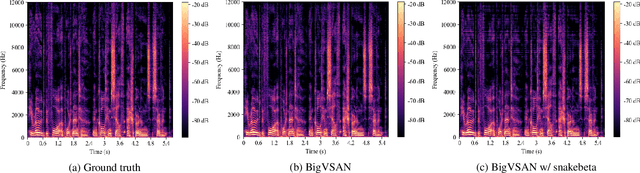
Generative adversarial network (GAN)-based vocoders have been intensively studied because they can synthesize high-fidelity audio waveforms faster than real-time. However, it has been reported that most GANs fail to obtain the optimal projection for discriminating between real and fake data in the feature space. In the literature, it has been demonstrated that slicing adversarial network (SAN), an improved GAN training framework that can find the optimal projection, is effective in the image generation task. In this paper, we investigate the effectiveness of SAN in the vocoding task. For this purpose, we propose a scheme to modify least-squares GAN, which most GAN-based vocoders adopt, so that their loss functions satisfy the requirements of SAN. Through our experiments, we demonstrate that SAN can improve the performance of GAN-based vocoders, including BigVGAN, with small modifications. Our code is available at https://github.com/sony/bigvsan.
ETP: Learning Transferable ECG Representations via ECG-Text Pre-training
Sep 06, 2023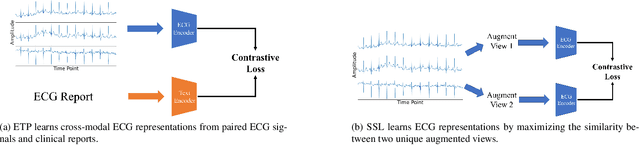
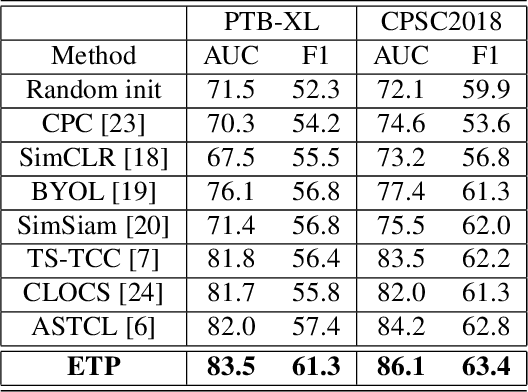
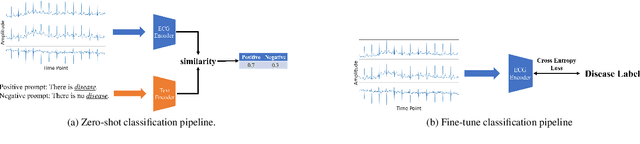
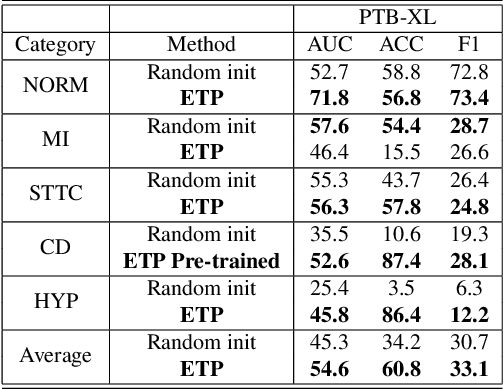
In the domain of cardiovascular healthcare, the Electrocardiogram (ECG) serves as a critical, non-invasive diagnostic tool. Although recent strides in self-supervised learning (SSL) have been promising for ECG representation learning, these techniques often require annotated samples and struggle with classes not present in the fine-tuning stages. To address these limitations, we introduce ECG-Text Pre-training (ETP), an innovative framework designed to learn cross-modal representations that link ECG signals with textual reports. For the first time, this framework leverages the zero-shot classification task in the ECG domain. ETP employs an ECG encoder along with a pre-trained language model to align ECG signals with their corresponding textual reports. The proposed framework excels in both linear evaluation and zero-shot classification tasks, as demonstrated on the PTB-XL and CPSC2018 datasets, showcasing its ability for robust and generalizable cross-modal ECG feature learning.
OTW: Optimal Transport Warping for Time Series
Jun 01, 2023
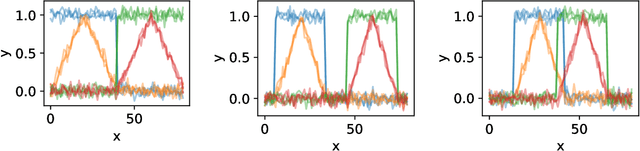
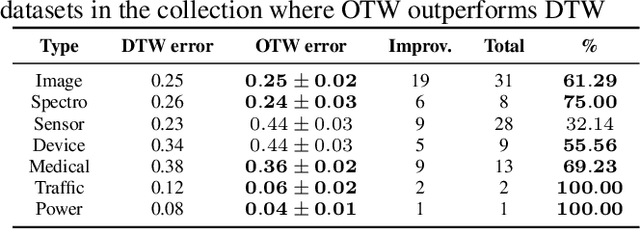
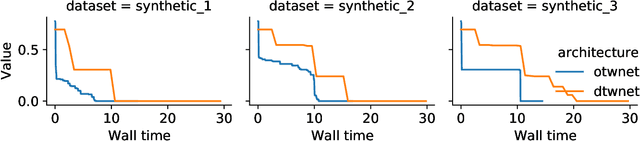
Dynamic Time Warping (DTW) has become the pragmatic choice for measuring distance between time series. However, it suffers from unavoidable quadratic time complexity when the optimal alignment matrix needs to be computed exactly. This hinders its use in deep learning architectures, where layers involving DTW computations cause severe bottlenecks. To alleviate these issues, we introduce a new metric for time series data based on the Optimal Transport (OT) framework, called Optimal Transport Warping (OTW). OTW enjoys linear time/space complexity, is differentiable and can be parallelized. OTW enjoys a moderate sensitivity to time and shape distortions, making it ideal for time series. We show the efficacy and efficiency of OTW on 1-Nearest Neighbor Classification and Hierarchical Clustering, as well as in the case of using OTW instead of DTW in Deep Learning architectures.