 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
H3-Mapping: Quasi-Heterogeneous Feature Grids for Real-time Dense Mapping Using Hierarchical Hybrid Representation
Mar 16, 2024
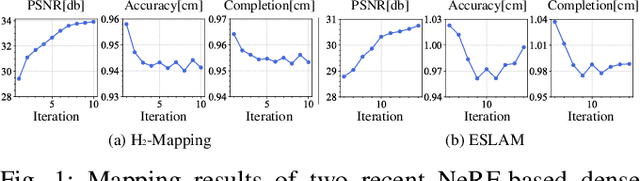


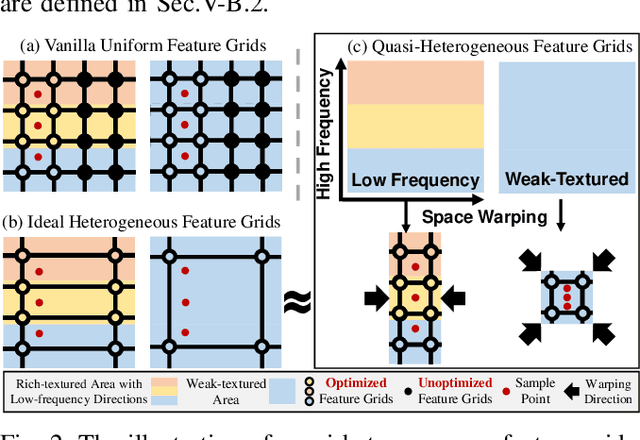
In recent years, implicit online dense mapping methods have achieved high-quality reconstruction results, showcasing great potential in robotics, AR/VR, and digital twins applications. However, existing methods struggle with slow texture modeling which limits their real-time performance. To address these limitations, we propose a NeRF-based dense mapping method that enables faster and higher-quality reconstruction. To improve texture modeling, we introduce quasi-heterogeneous feature grids, which inherit the fast querying ability of uniform feature grids while adapting to varying levels of texture complexity. Besides, we present a gradient-aided coverage-maximizing strategy for keyframe selection that enables the selected keyframes to exhibit a closer focus on rich-textured regions and a broader scope for weak-textured areas. Experimental results demonstrate that our method surpasses existing NeRF-based approaches in texture fidelity, geometry accuracy, and time consumption. The code for our method will be available at: https://github.com/SYSU-STAR/H3-Mapping.
Efficient Multi-branch Segmentation Network for Situation Awareness in Autonomous Navigation
Mar 30, 2024Real-time and high-precision situational awareness technology is critical for autonomous navigation of unmanned surface vehicles (USVs). In particular, robust and fast obstacle semantic segmentation methods are essential. However, distinguishing between the sea and the sky is challenging due to the differences between port and maritime environments. In this study, we built a dataset that captured perspectives from USVs and unmanned aerial vehicles in a maritime port environment and analysed the data features. Statistical analysis revealed a high correlation between the distribution of the sea and sky and row positional information. Based on this finding, a three-branch semantic segmentation network with a row position encoding module (RPEM) was proposed to improve the prediction accuracy between the sea and the sky. The proposed RPEM highlights the effect of row coordinates on feature extraction. Compared to the baseline, the three-branch network with RPEM significantly improved the ability to distinguish between the sea and the sky without significantly reducing the computational speed.
Rethinking Interactive Image Segmentation with Low Latency, High Quality, and Diverse Prompts
Mar 31, 2024The goal of interactive image segmentation is to delineate specific regions within an image via visual or language prompts. Low-latency and high-quality interactive segmentation with diverse prompts remain challenging for existing specialist and generalist models. Specialist models, with their limited prompts and task-specific designs, experience high latency because the image must be recomputed every time the prompt is updated, due to the joint encoding of image and visual prompts. Generalist models, exemplified by the Segment Anything Model (SAM), have recently excelled in prompt diversity and efficiency, lifting image segmentation to the foundation model era. However, for high-quality segmentations, SAM still lags behind state-of-the-art specialist models despite SAM being trained with x100 more segmentation masks. In this work, we delve deep into the architectural differences between the two types of models. We observe that dense representation and fusion of visual prompts are the key design choices contributing to the high segmentation quality of specialist models. In light of this, we reintroduce this dense design into the generalist models, to facilitate the development of generalist models with high segmentation quality. To densely represent diverse visual prompts, we propose to use a dense map to capture five types: clicks, boxes, polygons, scribbles, and masks. Thus, we propose SegNext, a next-generation interactive segmentation approach offering low latency, high quality, and diverse prompt support. Our method outperforms current state-of-the-art methods on HQSeg-44K and DAVIS, both quantitatively and qualitatively.
ECtHR-PCR: A Dataset for Precedent Understanding and Prior Case Retrieval in the European Court of Human Rights
Mar 31, 2024In common law jurisdictions, legal practitioners rely on precedents to construct arguments, in line with the doctrine of \emph{stare decisis}. As the number of cases grow over the years, prior case retrieval (PCR) has garnered significant attention. Besides lacking real-world scale, existing PCR datasets do not simulate a realistic setting, because their queries use complete case documents while only masking references to prior cases. The query is thereby exposed to legal reasoning not yet available when constructing an argument for an undecided case as well as spurious patterns left behind by citation masks, potentially short-circuiting a comprehensive understanding of case facts and legal principles. To address these limitations, we introduce a PCR dataset based on judgements from the European Court of Human Rights (ECtHR), which explicitly separate facts from arguments and exhibit precedential practices, aiding us to develop this PCR dataset to foster systems' comprehensive understanding. We benchmark different lexical and dense retrieval approaches with various negative sampling strategies, adapting them to deal with long text sequences using hierarchical variants. We found that difficulty-based negative sampling strategies were not effective for the PCR task, highlighting the need for investigation into domain-specific difficulty criteria. Furthermore, we observe performance of the dense models degrade with time and calls for further research into temporal adaptation of retrieval models. Additionally, we assess the influence of different views , Halsbury's and Goodhart's, in practice in ECtHR jurisdiction using PCR task.
Improved Genetic Algorithm Based on Greedy and Simulated Annealing Ideas for Vascular Robot Ordering Strategy
Mar 28, 2024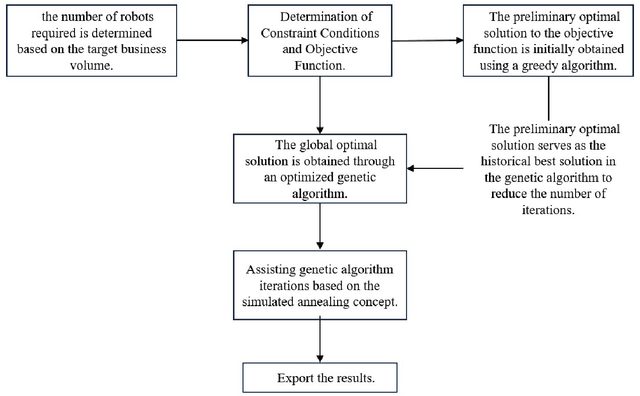

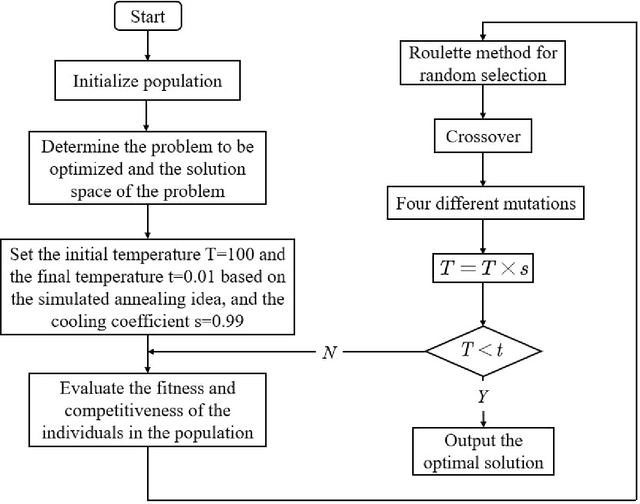
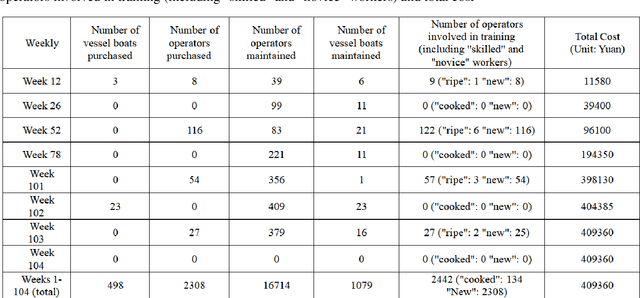
This study presents a comprehensive approach for optimizing the acquisition, utilization, and maintenance of ABLVR vascular robots in healthcare settings. Medical robotics, particularly in vascular treatments, necessitates precise resource allocation and optimization due to the complex nature of robot and operator maintenance. Traditional heuristic methods, though intuitive, often fail to achieve global optimization. To address these challenges, this research introduces a novel strategy, combining mathematical modeling, a hybrid genetic algorithm, and ARIMA time series forecasting. Considering the dynamic healthcare environment, our approach includes a robust resource allocation model for robotic vessels and operators. We incorporate the unique requirements of the adaptive learning process for operators and the maintenance needs of robotic components. The hybrid genetic algorithm, integrating simulated annealing and greedy approaches, efficiently solves the optimization problem. Additionally, ARIMA time series forecasting predicts the demand for vascular robots, further enhancing the adaptability of our strategy. Experimental results demonstrate the superiority of our approach in terms of optimization, transparency, and convergence speed from other state-of-the-art methods.
Exploiting Individual Graph Structures to Enhance Ecological Momentary Assessment (EMA) Forecasting
Mar 28, 2024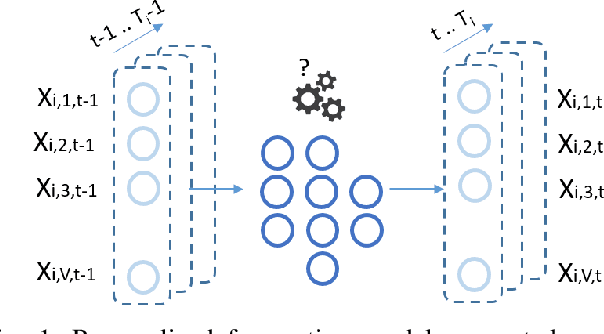
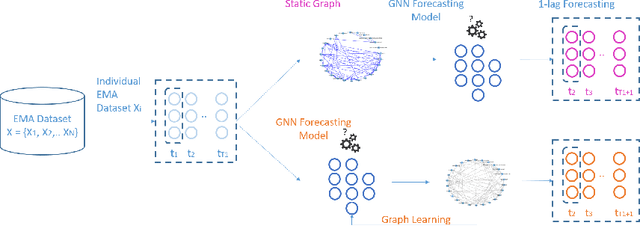
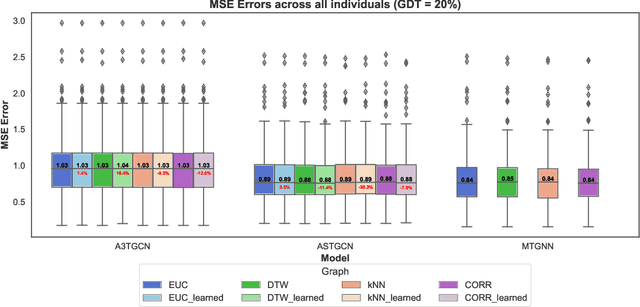
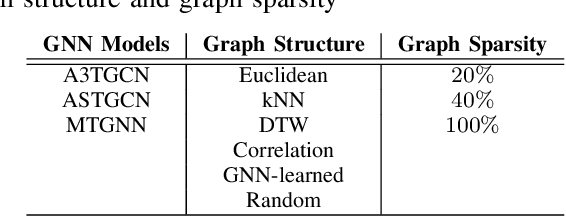
In the evolving field of psychopathology, the accurate assessment and forecasting of data derived from Ecological Momentary Assessment (EMA) is crucial. EMA offers contextually-rich psychopathological measurements over time, that practically lead to Multivariate Time Series (MTS) data. Thus, many challenges arise in analysis from the temporal complexities inherent in emotional, behavioral, and contextual EMA data as well as their inter-dependencies. To address both of these aspects, this research investigates the performance of Recurrent and Temporal Graph Neural Networks (GNNs). Overall, GNNs, by incorporating additional information from graphs reflecting the inner relationships between the variables, notably enhance the results by decreasing the Mean Squared Error (MSE) to 0.84 compared to the baseline LSTM model at 1.02. Therefore, the effect of constructing graphs with different characteristics on GNN performance is also explored. Additionally, GNN-learned graphs, which are dynamically refined during the training process, were evaluated. Using such graphs showed a similarly good performance. Thus, graph learning proved also promising for other GNN methods, potentially refining the pre-defined graphs.
Multi-Frame, Lightweight & Efficient Vision-Language Models for Question Answering in Autonomous Driving
Mar 28, 2024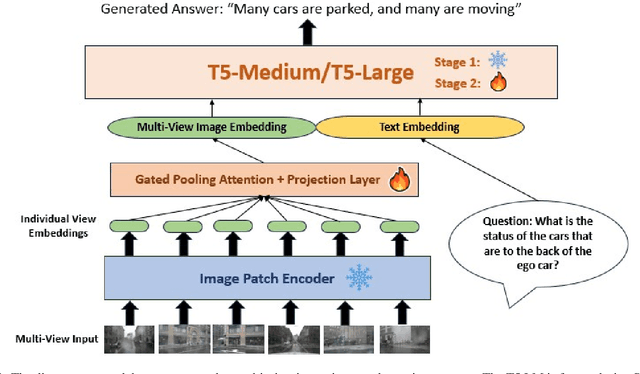


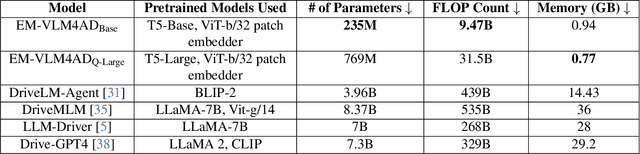
Vision-Language Models (VLMs) and Multi-Modal Language models (MMLMs) have become prominent in autonomous driving research, as these models can provide interpretable textual reasoning and responses for end-to-end autonomous driving safety tasks using traffic scene images and other data modalities. However, current approaches to these systems use expensive large language model (LLM) backbones and image encoders, making such systems unsuitable for real-time autonomous driving systems where tight memory constraints exist and fast inference time is necessary. To address these previous issues, we develop EM-VLM4AD, an efficient, lightweight, multi-frame vision language model which performs Visual Question Answering for autonomous driving. In comparison to previous approaches, EM-VLM4AD requires at least 10 times less memory and floating point operations, while also achieving higher BLEU-4, METEOR, CIDEr, and ROGUE scores than the existing baseline on the DriveLM dataset. EM-VLM4AD also exhibits the ability to extract relevant information from traffic views related to prompts and can answer questions for various autonomous driving subtasks. We release our code to train and evaluate our model at https://github.com/akshaygopalkr/EM-VLM4AD.
From Chaos to Clarity: Time Series Anomaly Detection in Astronomical Observations
Mar 15, 2024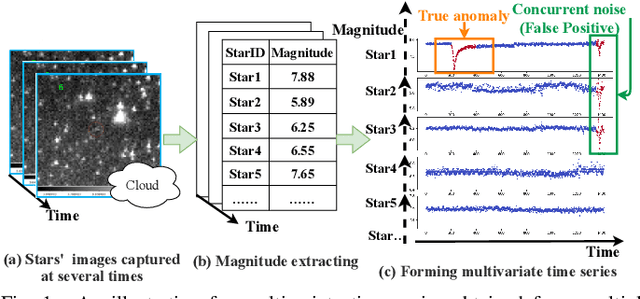
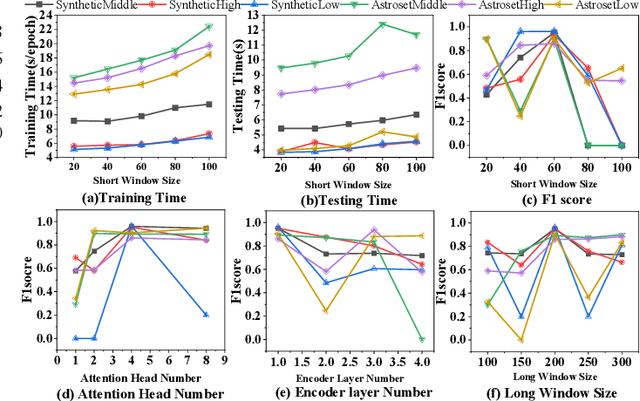
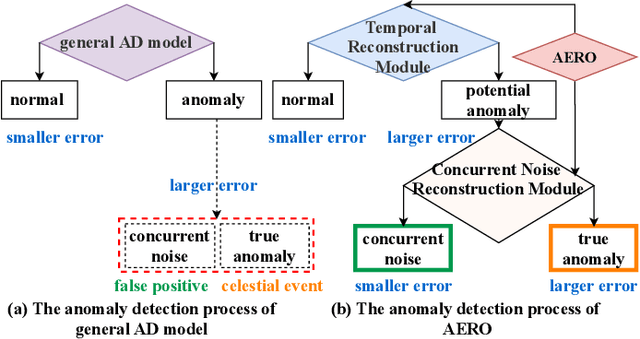
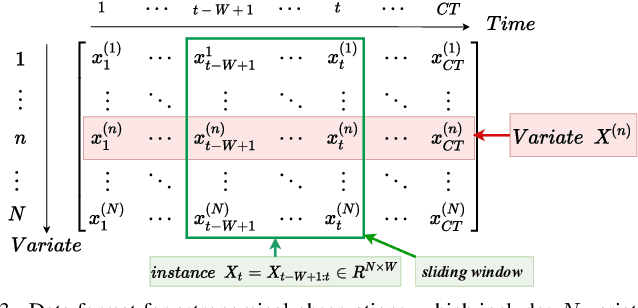
With the development of astronomical facilities, large-scale time series data observed by these facilities is being collected. Analyzing anomalies in these astronomical observations is crucial for uncovering potential celestial events and physical phenomena, thus advancing the scientific research process. However, existing time series anomaly detection methods fall short in tackling the unique characteristics of astronomical observations where each star is inherently independent but interfered by random concurrent noise, resulting in a high rate of false alarms. To overcome the challenges, we propose AERO, a novel two-stage framework tailored for unsupervised anomaly detection in astronomical observations. In the first stage, we employ a Transformer-based encoder-decoder architecture to learn the normal temporal patterns on each variate (i.e., star) in alignment with the characteristic of variate independence. In the second stage, we enhance the graph neural network with a window-wise graph structure learning to tackle the occurrence of concurrent noise characterized by spatial and temporal randomness. In this way, AERO is not only capable of distinguishing normal temporal patterns from potential anomalies but also effectively differentiating concurrent noise, thus decreasing the number of false alarms. We conducted extensive experiments on three synthetic datasets and three real-world datasets. The results demonstrate that AERO outperforms the compared baselines. Notably, compared to the state-of-the-art model, AERO improves the F1-score by up to 8.76% and 2.63% on synthetic and real-world datasets respectively.
CoReEcho: Continuous Representation Learning for 2D+time Echocardiography Analysis
Mar 15, 2024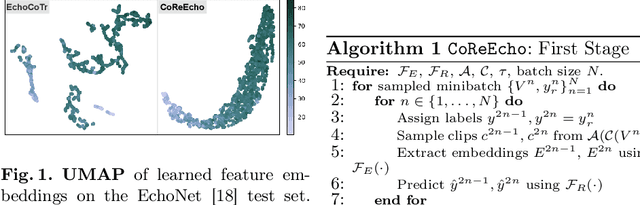
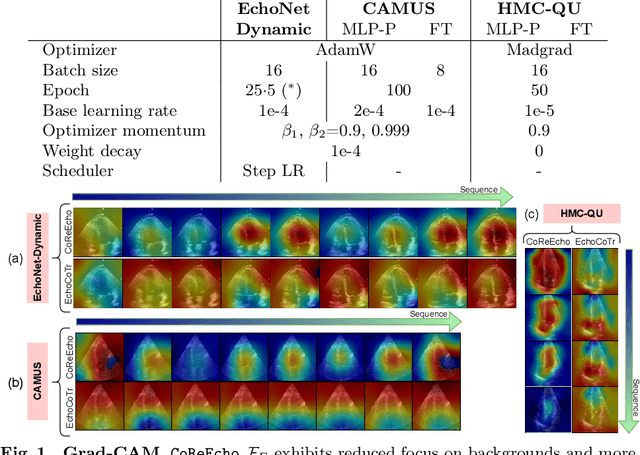
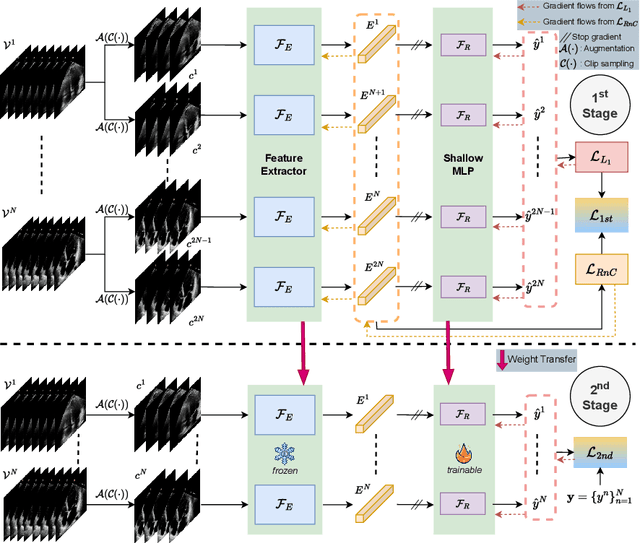

Deep learning (DL) models have been advancing automatic medical image analysis on various modalities, including echocardiography, by offering a comprehensive end-to-end training pipeline. This approach enables DL models to regress ejection fraction (EF) directly from 2D+time echocardiograms, resulting in superior performance. However, the end-to-end training pipeline makes the learned representations less explainable. The representations may also fail to capture the continuous relation among echocardiogram clips, indicating the existence of spurious correlations, which can negatively affect the generalization. To mitigate this issue, we propose CoReEcho, a novel training framework emphasizing continuous representations tailored for direct EF regression. Our extensive experiments demonstrate that CoReEcho: 1) outperforms the current state-of-the-art (SOTA) on the largest echocardiography dataset (EchoNet-Dynamic) with MAE of 3.90 & R2 of 82.44, and 2) provides robust and generalizable features that transfer more effectively in related downstream tasks. The code is publicly available at https://github.com/fadamsyah/CoReEcho.
PID Control-Based Self-Healing to Improve the Robustness of Large Language Models
Mar 31, 2024Despite the effectiveness of deep neural networks in numerous natural language processing applications, recent findings have exposed the vulnerability of these language models when minor perturbations are introduced. While appearing semantically indistinguishable to humans, these perturbations can significantly reduce the performance of well-trained language models, raising concerns about the reliability of deploying them in safe-critical situations. In this work, we construct a computationally efficient self-healing process to correct undesired model behavior during online inference when perturbations are applied to input data. This is formulated as a trajectory optimization problem in which the internal states of the neural network layers are automatically corrected using a PID (Proportional-Integral-Derivative) control mechanism. The P controller targets immediate state adjustments, while the I and D controllers consider past states and future dynamical trends, respectively. We leverage the geometrical properties of the training data to design effective linear PID controllers. This approach reduces the computational cost to that of using just the P controller, instead of the full PID control. Further, we introduce an analytical method for approximating the optimal control solutions, enhancing the real-time inference capabilities of this controlled system. Moreover, we conduct a theoretical error analysis of the analytic solution in a simplified setting. The proposed PID control-based self-healing is a low cost framework that improves the robustness of pre-trained large language models, whether standard or robustly trained, against a wide range of perturbations. A detailed implementation can be found in:https://github.com/zhuotongchen/PID-Control-Based-Self-Healing-to-Improve-the-Robustness-of-Large-Language-Models.