 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MultiWay-Adapater: Adapting large-scale multi-modal models for scalable image-text retrieval
Sep 12, 2023
As the size of Large Multi-Modal Models (LMMs) increases consistently, the adaptation of these pre-trained models to specialized tasks has become a computationally and memory-intensive challenge. Traditional fine-tuning methods require isolated, exhaustive retuning for each new task, limiting the models' versatility. Moreover, current efficient adaptation techniques often overlook modality alignment, focusing only on the knowledge extraction of new tasks. To tackle these issues, we introduce Multiway-Adapter, an innovative framework incorporating an 'Alignment Enhancer' to deepen modality alignment, enabling high transferability without tuning pre-trained parameters. Our method adds fewer than 1.25\% of additional parameters to LMMs, exemplified by the BEiT-3 model in our study. This leads to superior zero-shot image-text retrieval performance compared to fully fine-tuned models, while achieving up to a 57\% reduction in fine-tuning time. Our approach offers a resource-efficient and effective adaptation pathway for LMMs, broadening their applicability. The source code is publicly available at: \url{https://github.com/longkukuhi/MultiWay-Adapter}.
SlideSpeech: A Large-Scale Slide-Enriched Audio-Visual Corpus
Sep 12, 2023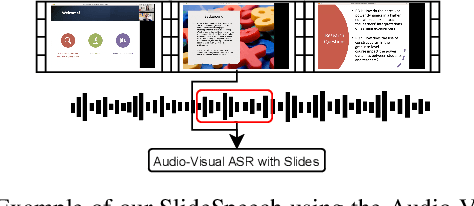
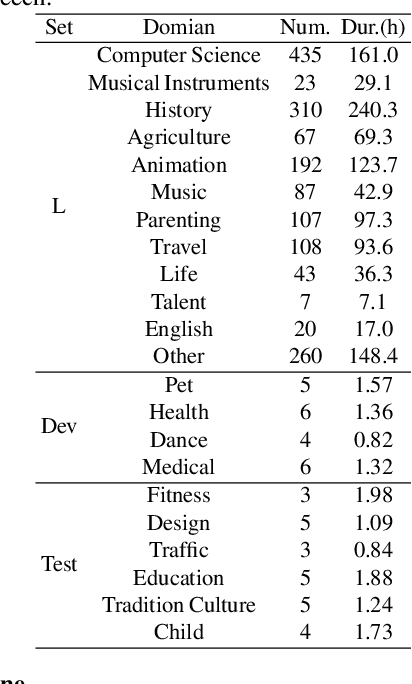
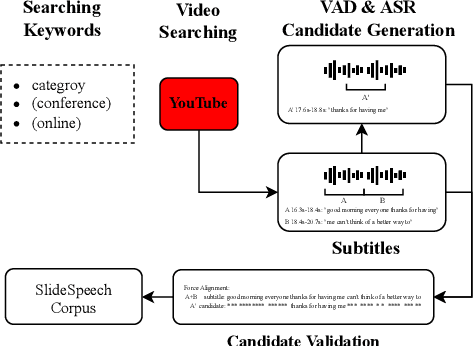

Multi-Modal automatic speech recognition (ASR) techniques aim to leverage additional modalities to improve the performance of speech recognition systems. While existing approaches primarily focus on video or contextual information, the utilization of extra supplementary textual information has been overlooked. Recognizing the abundance of online conference videos with slides, which provide rich domain-specific information in the form of text and images, we release SlideSpeech, a large-scale audio-visual corpus enriched with slides. The corpus contains 1,705 videos, 1,000+ hours, with 473 hours of high-quality transcribed speech. Moreover, the corpus contains a significant amount of real-time synchronized slides. In this work, we present the pipeline for constructing the corpus and propose baseline methods for utilizing text information in the visual slide context. Through the application of keyword extraction and contextual ASR methods in the benchmark system, we demonstrate the potential of improving speech recognition performance by incorporating textual information from supplementary video slides.
Robust Nonlinear Reduced-Order Model Predictive Control
Sep 11, 2023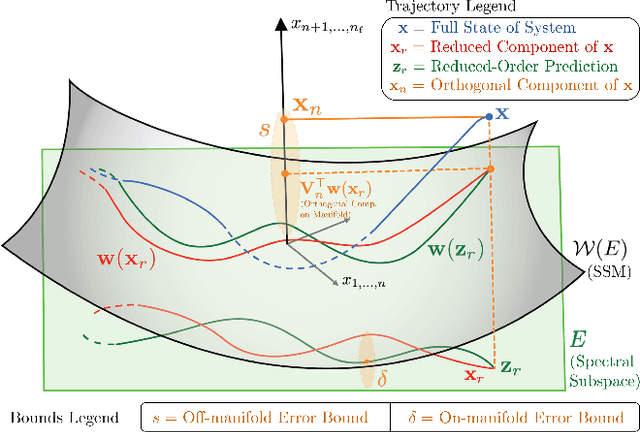
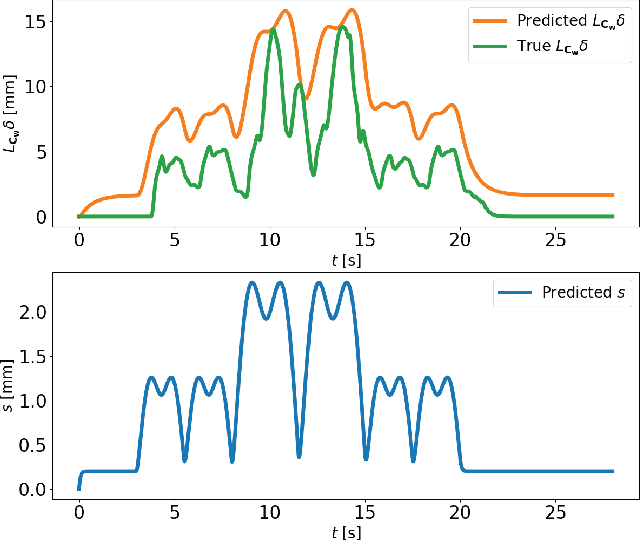
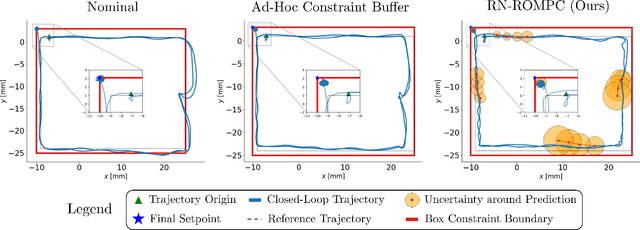
Real-world systems are often characterized by high-dimensional nonlinear dynamics, making them challenging to control in real time. While reduced-order models (ROMs) are frequently employed in model-based control schemes, dimensionality reduction introduces model uncertainty which can potentially compromise the stability and safety of the original high-dimensional system. In this work, we propose a novel reduced-order model predictive control (ROMPC) scheme to solve constrained optimal control problems for nonlinear, high-dimensional systems. To address the challenges of using ROMs in predictive control schemes, we derive an error bounding system that dynamically accounts for model reduction error. Using these bounds, we design a robust MPC scheme that ensures robust constraint satisfaction, recursive feasibility, and asymptotic stability. We demonstrate the effectiveness of our proposed method in simulations on a high-dimensional soft robot with nearly 10,000 states.
Data efficiency, dimensionality reduction, and the generalized symmetric information bottleneck
Sep 11, 2023The Symmetric Information Bottleneck (SIB), an extension of the more familiar Information Bottleneck, is a dimensionality reduction technique that simultaneously compresses two random variables to preserve information between their compressed versions. We introduce the Generalized Symmetric Information Bottleneck (GSIB), which explores different functional forms of the cost of such simultaneous reduction. We then explore the dataset size requirements of such simultaneous compression. We do this by deriving bounds and root-mean-squared estimates of statistical fluctuations of the involved loss functions. We show that, in typical situations, the simultaneous GSIB compression requires qualitatively less data to achieve the same errors compared to compressing variables one at a time. We suggest that this is an example of a more general principle that simultaneous compression is more data efficient than independent compression of each of the input variables.
Stochastic Gradient Descent-like relaxation is equivalent to Glauber dynamics in discrete optimization and inference problems
Sep 11, 2023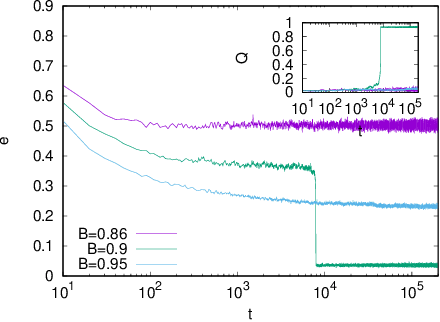
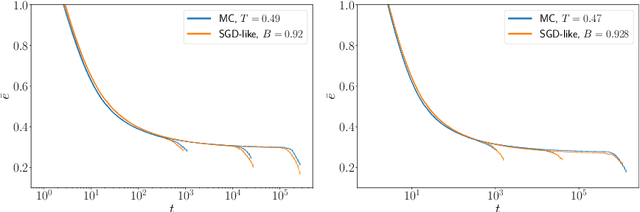
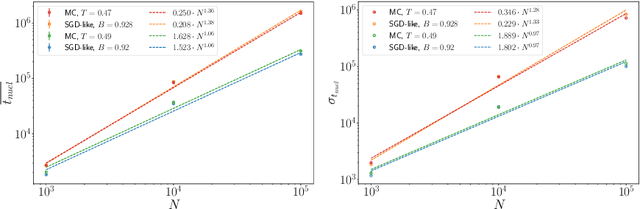
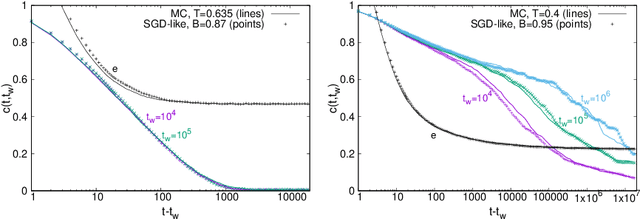
Is Stochastic Gradient Descent (SGD) substantially different from Glauber dynamics? This is a fundamental question at the time of understanding the most used training algorithm in the field of Machine Learning, but it received no answer until now. Here we show that in discrete optimization and inference problems, the dynamics of an SGD-like algorithm resemble very closely that of Metropolis Monte Carlo with a properly chosen temperature, which depends on the mini-batch size. This quantitative matching holds both at equilibrium and in the out-of-equilibrium regime, despite the two algorithms having fundamental differences (e.g.\ SGD does not satisfy detailed balance). Such equivalence allows us to use results about performances and limits of Monte Carlo algorithms to optimize the mini-batch size in the SGD-like algorithm and make it efficient at recovering the signal in hard inference problems.
Leveraging Watch-time Feedback for Short-Video Recommendations: A Causal Labeling Framework
Jun 30, 2023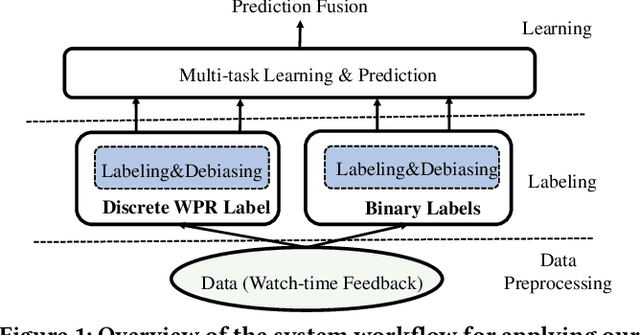

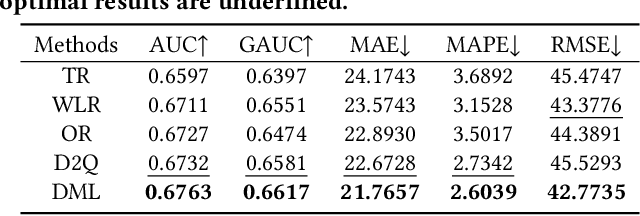
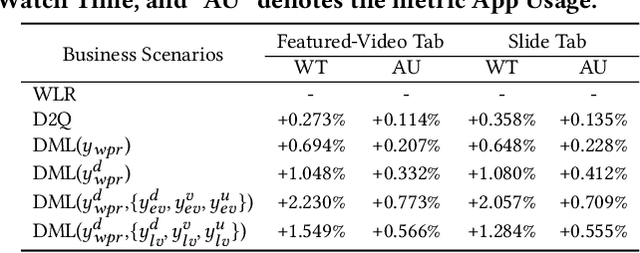
With the proliferation of short video applications, the significance of short video recommendations has vastly increased. Unlike other recommendation scenarios, short video recommendation systems heavily rely on feedback from watch time. Existing approaches simply treat watch time as a direct label, failing to effectively harness its extensive semantics and introduce bias, thereby limiting the potential for modeling user interests based on watch time. To overcome this challenge, we propose a framework named Debiasied Multiple-semantics-extracting Labeling (DML). DML constructs labels that encompass various semantics by utilizing quantiles derived from the distribution of watch time, prioritizing relative order rather than absolute label values. This approach facilitates easier model learning while aligning with the ranking objective of recommendations. Furthermore, we introduce a method inspired by causal adjustment to refine label definitions, thereby reducing the impact of bias on the label and directly mitigating bias at the label level. We substantiate the effectiveness of our DML framework through both online and offline experiments. Extensive results demonstrate that our DML could effectively leverage watch time to discover users' real interests, enhancing their engagement in our application.
Universal Approximation of Linear Time-Invariant (LTI) Systems through RNNs: Power of Randomness in Reservoir Computing
Aug 04, 2023Recurrent neural networks (RNNs) are known to be universal approximators of dynamic systems under fairly mild and general assumptions, making them good tools to process temporal information. However, RNNs usually suffer from the issues of vanishing and exploding gradients in the standard RNN training. Reservoir computing (RC), a special RNN where the recurrent weights are randomized and left untrained, has been introduced to overcome these issues and has demonstrated superior empirical performance in fields as diverse as natural language processing and wireless communications especially in scenarios where training samples are extremely limited. On the contrary, the theoretical grounding to support this observed performance has not been fully developed at the same pace. In this work, we show that RNNs can provide universal approximation of linear time-invariant (LTI) systems. Specifically, we show that RC can universally approximate a general LTI system. We present a clear signal processing interpretation of RC and utilize this understanding in the problem of simulating a generic LTI system through RC. Under this setup, we analytically characterize the optimal probability distribution function for generating the recurrent weights of the underlying RNN of the RC. We provide extensive numerical evaluations to validate the optimality of the derived optimum distribution of the recurrent weights of the RC for the LTI system simulation problem. Our work results in clear signal processing-based model interpretability of RC and provides theoretical explanation for the power of randomness in setting instead of training RC's recurrent weights. It further provides a complete optimum analytical characterization for the untrained recurrent weights, marking an important step towards explainable machine learning (XML) which is extremely important for applications where training samples are limited.
Temporal Inductive Path Neural Network for Temporal Knowledge Graph Reasoning
Sep 06, 2023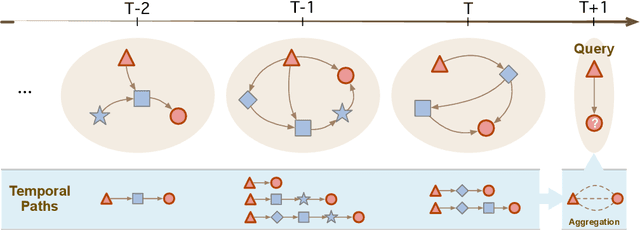

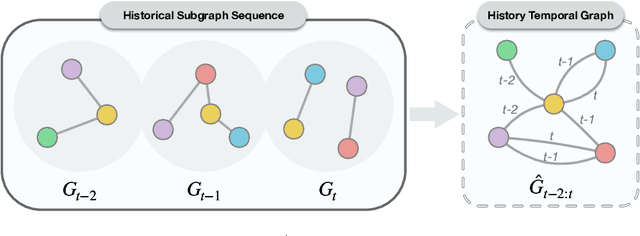
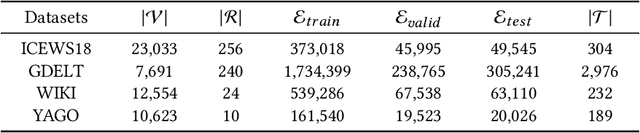
Temporal Knowledge Graph (TKG) is an extension of traditional Knowledge Graph (KG) that incorporates the dimension of time. Reasoning on TKGs is a crucial task that aims to predict future facts based on historical occurrences. The key challenge lies in uncovering structural dependencies within historical subgraphs and temporal patterns. Most existing approaches model TKGs relying on entity modeling, as nodes in the graph play a crucial role in knowledge representation. However, the real-world scenario often involves an extensive number of entities, with new entities emerging over time. This makes it challenging for entity-dependent methods to cope with extensive volumes of entities, and effectively handling newly emerging entities also becomes a significant challenge. Therefore, we propose Temporal Inductive Path Neural Network (TiPNN), which models historical information in an entity-independent perspective. Specifically, TiPNN adopts a unified graph, namely history temporal graph, to comprehensively capture and encapsulate information from history. Subsequently, we utilize the defined query-aware temporal paths to model historical path information related to queries on history temporal graph for the reasoning. Extensive experiments illustrate that the proposed model not only attains significant performance enhancements but also handles inductive settings, while additionally facilitating the provision of reasoning evidence through history temporal graphs.
RepSGG: Novel Representations of Entities and Relationships for Scene Graph Generation
Sep 06, 2023Scene Graph Generation (SGG) has achieved significant progress recently. However, most previous works rely heavily on fixed-size entity representations based on bounding box proposals, anchors, or learnable queries. As each representation's cardinality has different trade-offs between performance and computation overhead, extracting highly representative features efficiently and dynamically is both challenging and crucial for SGG. In this work, a novel architecture called RepSGG is proposed to address the aforementioned challenges, formulating a subject as queries, an object as keys, and their relationship as the maximum attention weight between pairwise queries and keys. With more fine-grained and flexible representation power for entities and relationships, RepSGG learns to sample semantically discriminative and representative points for relationship inference. Moreover, the long-tailed distribution also poses a significant challenge for generalization of SGG. A run-time performance-guided logit adjustment (PGLA) strategy is proposed such that the relationship logits are modified via affine transformations based on run-time performance during training. This strategy encourages a more balanced performance between dominant and rare classes. Experimental results show that RepSGG achieves the state-of-the-art or comparable performance on the Visual Genome and Open Images V6 datasets with fast inference speed, demonstrating the efficacy and efficiency of the proposed methods.
From Specific to Generic Learned Sorted Set Dictionaries: A Theoretically Sound Paradigm Yelding Competitive Data Structural Boosters in Practice
Sep 02, 2023This research concerns Learned Data Structures, a recent area that has emerged at the crossroad of Machine Learning and Classic Data Structures. It is methodologically important and with a high practical impact. We focus on Learned Indexes, i.e., Learned Sorted Set Dictionaries. The proposals available so far are specific in the sense that they can boost, indeed impressively, the time performance of Table Search Procedures with a sorted layout only, e.g., Binary Search. We propose a novel paradigm that, complementing known specialized ones, can produce Learned versions of any Sorted Set Dictionary, for instance, Balanced Binary Search Trees or Binary Search on layouts other that sorted, i.e., Eytzinger. Theoretically, based on it, we obtain several results of interest, such as (a) the first Learned Optimum Binary Search Forest, with mean access time bounded by the Entropy of the probability distribution of the accesses to the Dictionary; (b) the first Learned Sorted Set Dictionary that, in the Dynamic Case and in an amortized analysis setting, matches the same time bounds known for Classic Dictionaries. This latter under widely accepted assumptions regarding the size of the Universe. The experimental part, somewhat complex in terms of software development, clearly indicates the nonobvious finding that the generalization we propose can yield effective and competitive Learned Data Structural Booster, even with respect to specific benchmark models.