 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Is Certifying $\ell_p$ Robustness Still Worthwhile?
Oct 13, 2023
Over the years, researchers have developed myriad attacks that exploit the ubiquity of adversarial examples, as well as defenses that aim to guard against the security vulnerabilities posed by such attacks. Of particular interest to this paper are defenses that provide provable guarantees against the class of $\ell_p$-bounded attacks. Certified defenses have made significant progress, taking robustness certification from toy models and datasets to large-scale problems like ImageNet classification. While this is undoubtedly an interesting academic problem, as the field has matured, its impact in practice remains unclear, thus we find it useful to revisit the motivation for continuing this line of research. There are three layers to this inquiry, which we address in this paper: (1) why do we care about robustness research? (2) why do we care about the $\ell_p$-bounded threat model? And (3) why do we care about certification as opposed to empirical defenses? In brief, we take the position that local robustness certification indeed confers practical value to the field of machine learning. We focus especially on the latter two questions from above. With respect to the first of the two, we argue that the $\ell_p$-bounded threat model acts as a minimal requirement for safe application of models in security-critical domains, while at the same time, evidence has mounted suggesting that local robustness may lead to downstream external benefits not immediately related to robustness. As for the second, we argue that (i) certification provides a resolution to the cat-and-mouse game of adversarial attacks; and furthermore, that (ii) perhaps contrary to popular belief, there may not exist a fundamental trade-off between accuracy, robustness, and certifiability, while moreover, certified training techniques constitute a particularly promising way for learning robust models.
SE(3)-Stochastic Flow Matching for Protein Backbone Generation
Oct 03, 2023The computational design of novel protein structures has the potential to impact numerous scientific disciplines greatly. Toward this goal, we introduce $\text{FoldFlow}$ a series of novel generative models of increasing modeling power based on the flow-matching paradigm over $3\text{D}$ rigid motions -- i.e. the group $\text{SE(3)}$ -- enabling accurate modeling of protein backbones. We first introduce $\text{FoldFlow-Base}$, a simulation-free approach to learning deterministic continuous-time dynamics and matching invariant target distributions on $\text{SE(3)}$. We next accelerate training by incorporating Riemannian optimal transport to create $\text{FoldFlow-OT}$, leading to the construction of both more simple and stable flows. Finally, we design $\text{FoldFlow-SFM}$ coupling both Riemannian OT and simulation-free training to learn stochastic continuous-time dynamics over $\text{SE(3)}$. Our family of $\text{FoldFlow}$ generative models offer several key advantages over previous approaches to the generative modeling of proteins: they are more stable and faster to train than diffusion-based approaches, and our models enjoy the ability to map any invariant source distribution to any invariant target distribution over $\text{SE(3)}$. Empirically, we validate our FoldFlow models on protein backbone generation of up to $300$ amino acids leading to high-quality designable, diverse, and novel samples.
Improving Robustness and Accuracy of Ponzi Scheme Detection on Ethereum Using Time-Dependent Features
Aug 31, 2023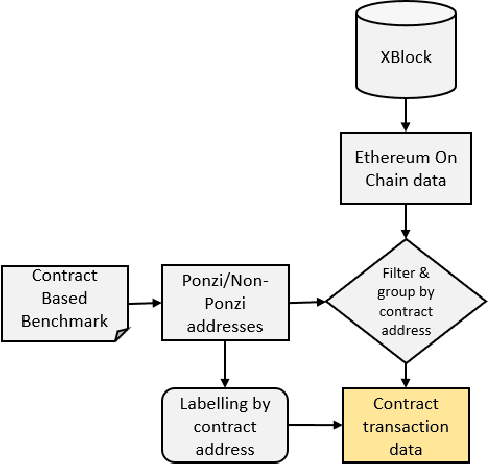
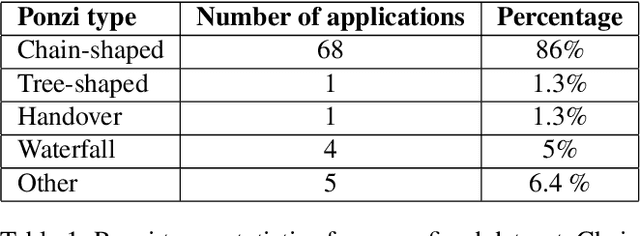
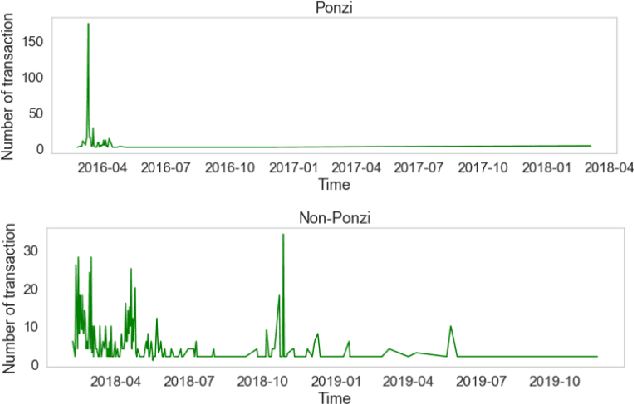
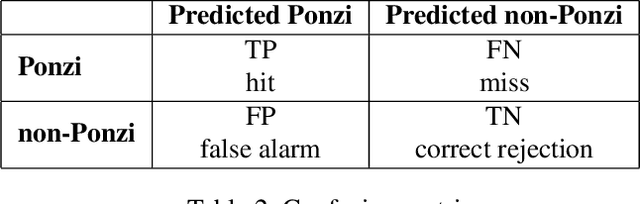
The rapid development of blockchain has led to more and more funding pouring into the cryptocurrency market, which also attracted cybercriminals' interest in recent years. The Ponzi scheme, an old-fashioned fraud, is now popular on the blockchain, causing considerable financial losses to many crypto-investors. A few Ponzi detection methods have been proposed in the literature, most of which detect a Ponzi scheme based on its smart contract source code or opcode. The contract-code-based approach, while achieving very high accuracy, is not robust: first, the source codes of a majority of contracts on Ethereum are not available, and second, a Ponzi developer can fool a contract-code-based detection model by obfuscating the opcode or inventing a new profit distribution logic that cannot be detected (since these models were trained on existing Ponzi logics only). A transaction-based approach could improve the robustness of detection because transactions, unlike smart contracts, are harder to be manipulated. However, the current transaction-based detection models achieve fairly low accuracy. We address this gap in the literature by developing new detection models that rely only on the transactions, hence guaranteeing the robustness, and moreover, achieve considerably higher Accuracy, Precision, Recall, and F1-score than existing transaction-based models. This is made possible thanks to the introduction of novel time-dependent features that capture Ponzi behaviours characteristics derived from our comprehensive data analyses on Ponzi and non-Ponzi data from the XBlock-ETH repository
Time-Aware Item Weighting for the Next Basket Recommendations
Jul 30, 2023
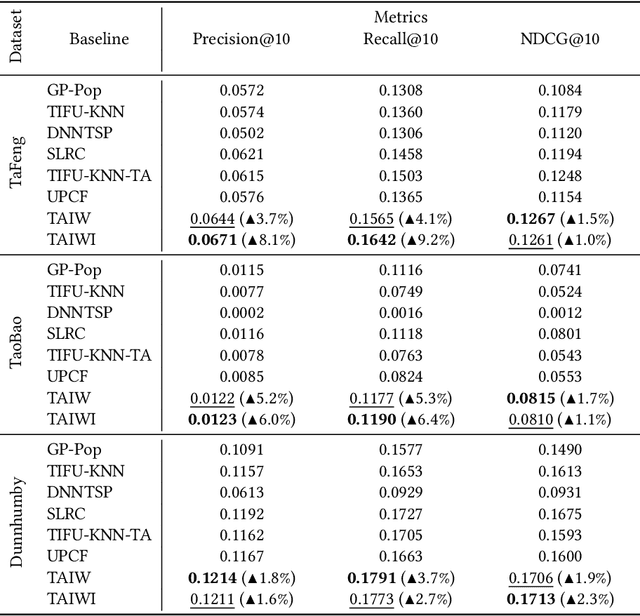
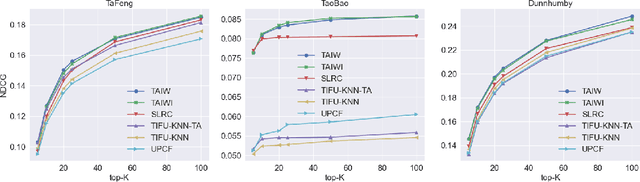
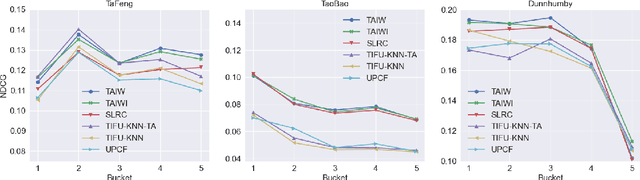
In this paper we study the next basket recommendation problem. Recent methods use different approaches to achieve better performance. However, many of them do not use information about the time of prediction and time intervals between baskets. To fill this gap, we propose a novel method, Time-Aware Item-based Weighting (TAIW), which takes timestamps and intervals into account. We provide experiments on three real-world datasets, and TAIW outperforms well-tuned state-of-the-art baselines for next-basket recommendations. In addition, we show the results of an ablation study and a case study of a few items.
GraphControl: Adding Conditional Control to Universal Graph Pre-trained Models for Graph Domain Transfer Learning
Oct 12, 2023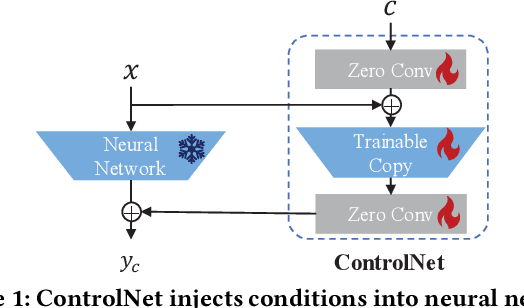
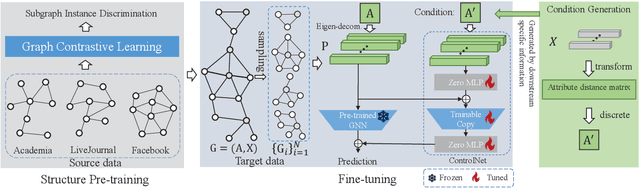
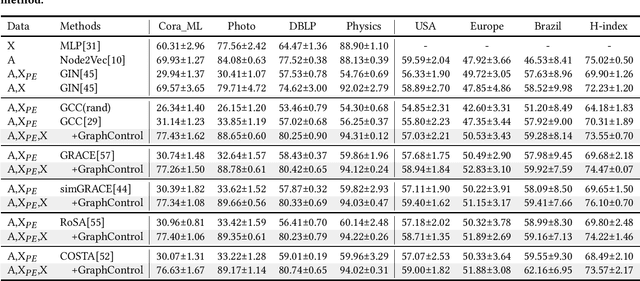
Graph-structured data is ubiquitous in the world which models complex relationships between objects, enabling various Web applications. Daily influxes of unlabeled graph data on the Web offer immense potential for these applications. Graph self-supervised algorithms have achieved significant success in acquiring generic knowledge from abundant unlabeled graph data. These pre-trained models can be applied to various downstream Web applications, saving training time and improving downstream (target) performance. However, different graphs, even across seemingly similar domains, can differ significantly in terms of attribute semantics, posing difficulties, if not infeasibility, for transferring the pre-trained models to downstream tasks. Concretely speaking, for example, the additional task-specific node information in downstream tasks (specificity) is usually deliberately omitted so that the pre-trained representation (transferability) can be leveraged. The trade-off as such is termed as "transferability-specificity dilemma" in this work. To address this challenge, we introduce an innovative deployment module coined as GraphControl, motivated by ControlNet, to realize better graph domain transfer learning. Specifically, by leveraging universal structural pre-trained models and GraphControl, we align the input space across various graphs and incorporate unique characteristics of target data as conditional inputs. These conditions will be progressively integrated into the model during fine-tuning or prompt tuning through ControlNet, facilitating personalized deployment. Extensive experiments show that our method significantly enhances the adaptability of pre-trained models on target attributed datasets, achieving 1.4-3x performance gain. Furthermore, it outperforms training-from-scratch methods on target data with a comparable margin and exhibits faster convergence.
Visual Attention-Prompted Prediction and Learning
Oct 12, 2023Explanation(attention)-guided learning is a method that enhances a model's predictive power by incorporating human understanding during the training phase. While attention-guided learning has shown promising results, it often involves time-consuming and computationally expensive model retraining. To address this issue, we introduce the attention-prompted prediction technique, which enables direct prediction guided by the attention prompt without the need for model retraining. However, this approach presents several challenges, including: 1) How to incorporate the visual attention prompt into the model's decision-making process and leverage it for future predictions even in the absence of a prompt? and 2) How to handle the incomplete information from the visual attention prompt? To tackle these challenges, we propose a novel framework called Visual Attention-Prompted Prediction and Learning, which seamlessly integrates visual attention prompts into the model's decision-making process and adapts to images both with and without attention prompts for prediction. To address the incomplete information of the visual attention prompt, we introduce a perturbation-based attention map modification method. Additionally, we propose an optimization-based mask aggregation method with a new weight learning function for adaptive perturbed annotation aggregation in the attention map modification process. Our overall framework is designed to learn in an attention-prompt guided multi-task manner to enhance future predictions even for samples without attention prompts and trained in an alternating manner for better convergence. Extensive experiments conducted on two datasets demonstrate the effectiveness of our proposed framework in enhancing predictions for samples, both with and without provided prompts.
Multiclass Classification of Policy Documents with Large Language Models
Oct 12, 2023Classifying policy documents into policy issue topics has been a long-time effort in political science and communication disciplines. Efforts to automate text classification processes for social science research purposes have so far achieved remarkable results, but there is still a large room for progress. In this work, we test the prediction performance of an alternative strategy, which requires human involvement much less than full manual coding. We use the GPT 3.5 and GPT 4 models of the OpenAI, which are pre-trained instruction-tuned Large Language Models (LLM), to classify congressional bills and congressional hearings into Comparative Agendas Project's 21 major policy issue topics. We propose three use-case scenarios and estimate overall accuracies ranging from %58-83 depending on scenario and GPT model employed. The three scenarios aims at minimal, moderate, and major human interference, respectively. Overall, our results point towards the insufficiency of complete reliance on GPT with minimal human intervention, an increasing accuracy along with the human effort exerted, and a surprisingly high accuracy achieved in the most humanly demanding use-case. However, the superior use-case achieved the %83 accuracy on the %65 of the data in which the two models agreed, suggesting that a similar approach to ours can be relatively easily implemented and allow for mostly automated coding of a majority of a given dataset. This could free up resources allowing manual human coding of the remaining %35 of the data to achieve an overall higher level of accuracy while reducing costs significantly.
Dynamic DAG Discovery for Interpretable Imitation Learning
Oct 12, 2023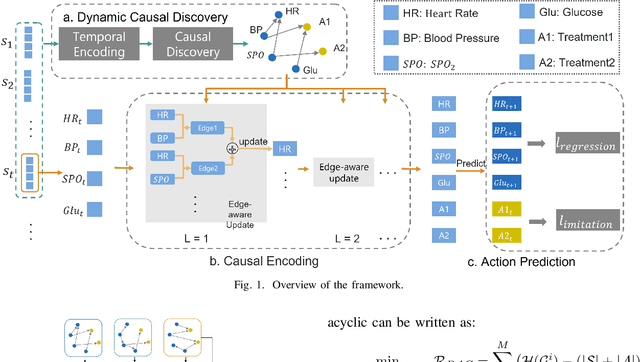
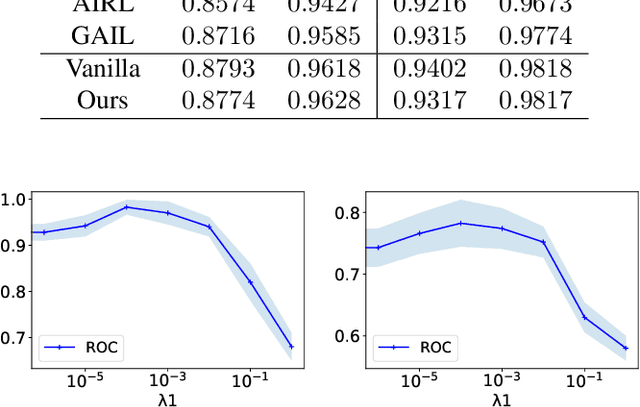
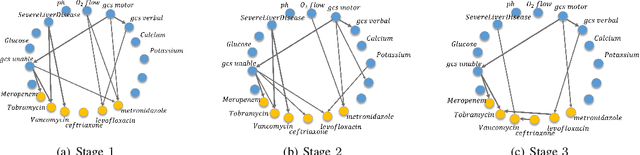
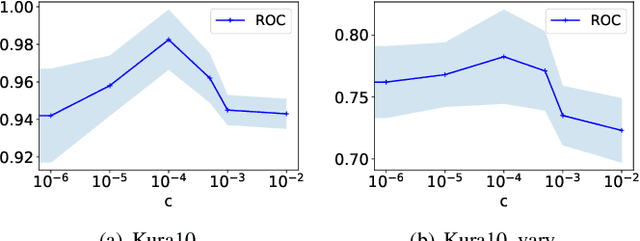
Imitation learning, which learns agent policy by mimicking expert demonstration, has shown promising results in many applications such as medical treatment regimes and self-driving vehicles. However, it remains a difficult task to interpret control policies learned by the agent. Difficulties mainly come from two aspects: 1) agents in imitation learning are usually implemented as deep neural networks, which are black-box models and lack interpretability; 2) the latent causal mechanism behind agents' decisions may vary along the trajectory, rather than staying static throughout time steps. To increase transparency and offer better interpretability of the neural agent, we propose to expose its captured knowledge in the form of a directed acyclic causal graph, with nodes being action and state variables and edges denoting the causal relations behind predictions. Furthermore, we design this causal discovery process to be state-dependent, enabling it to model the dynamics in latent causal graphs. Concretely, we conduct causal discovery from the perspective of Granger causality and propose a self-explainable imitation learning framework, {\method}. The proposed framework is composed of three parts: a dynamic causal discovery module, a causality encoding module, and a prediction module, and is trained in an end-to-end manner. After the model is learned, we can obtain causal relations among states and action variables behind its decisions, exposing policies learned by it. Experimental results on both synthetic and real-world datasets demonstrate the effectiveness of the proposed {\method} in learning the dynamic causal graphs for understanding the decision-making of imitation learning meanwhile maintaining high prediction accuracy.
Spatial encoding of BOLD fMRI time series for categorizing static images across visual datasets: A pilot study on human vision
Sep 07, 2023
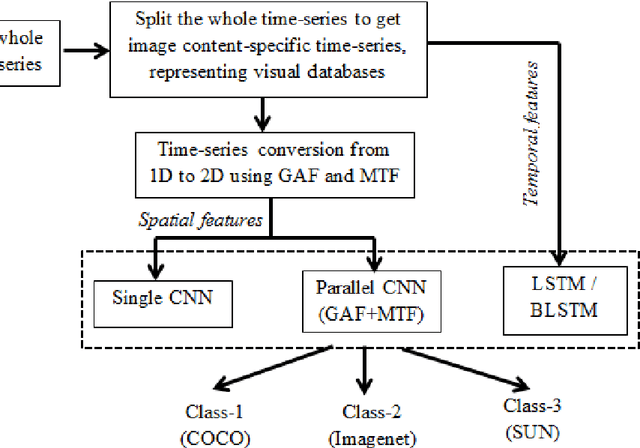
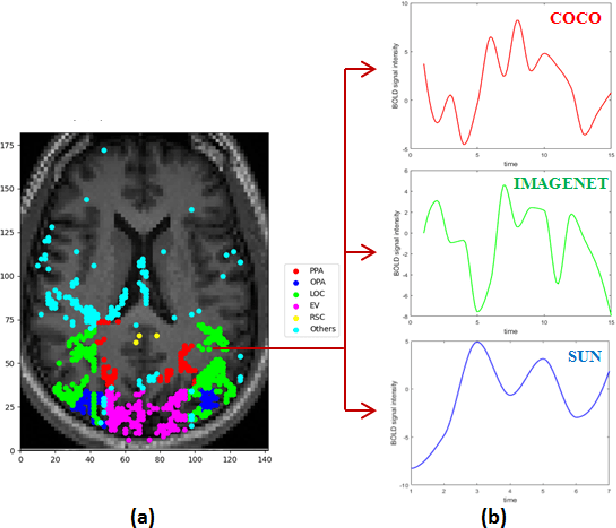
Functional MRI (fMRI) is widely used to examine brain functionality by detecting alteration in oxygenated blood flow that arises with brain activity. In this study, complexity specific image categorization across different visual datasets is performed using fMRI time series (TS) to understand differences in neuronal activities related to vision. Publicly available BOLD5000 dataset is used for this purpose, containing fMRI scans while viewing 5254 images of diverse categories, drawn from three standard computer vision datasets: COCO, ImageNet and SUN. To understand vision, it is important to study how brain functions while looking at different images. To achieve this, spatial encoding of fMRI BOLD TS has been performed that uses classical Gramian Angular Field (GAF) and Markov Transition Field (MTF) to obtain 2D BOLD TS, representing images of COCO, Imagenet and SUN. For classification, individual GAF and MTF features are fed into regular CNN. Subsequently, parallel CNN model is employed that uses combined 2D features for classifying images across COCO, Imagenet and SUN. The result of 2D CNN models is also compared with 1D LSTM and Bi-LSTM that utilizes raw fMRI BOLD signal for classification. It is seen that parallel CNN model outperforms other network models with an improvement of 7% for multi-class classification. Clinical relevance- The obtained result of this analysis establishes a baseline in studying how differently human brain functions while looking at images of diverse complexities.
Automatic Feature Engineering for Time Series Classification: Evaluation and Discussion
Aug 02, 2023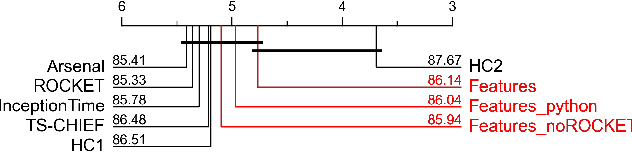
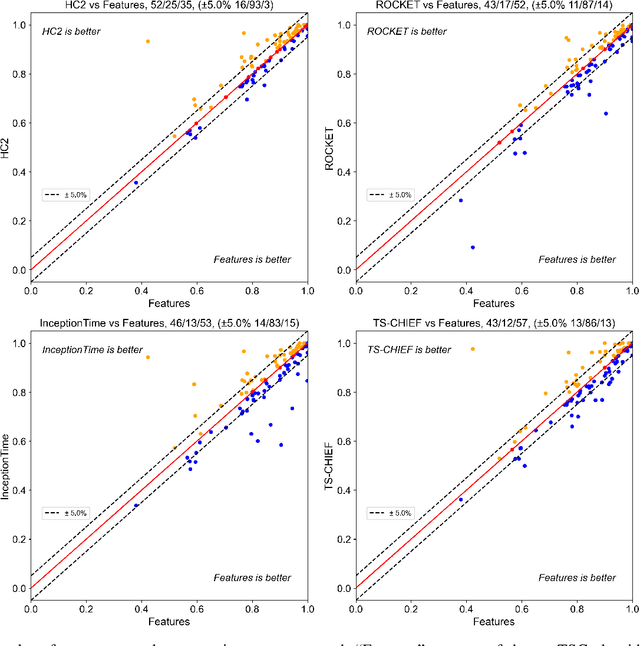
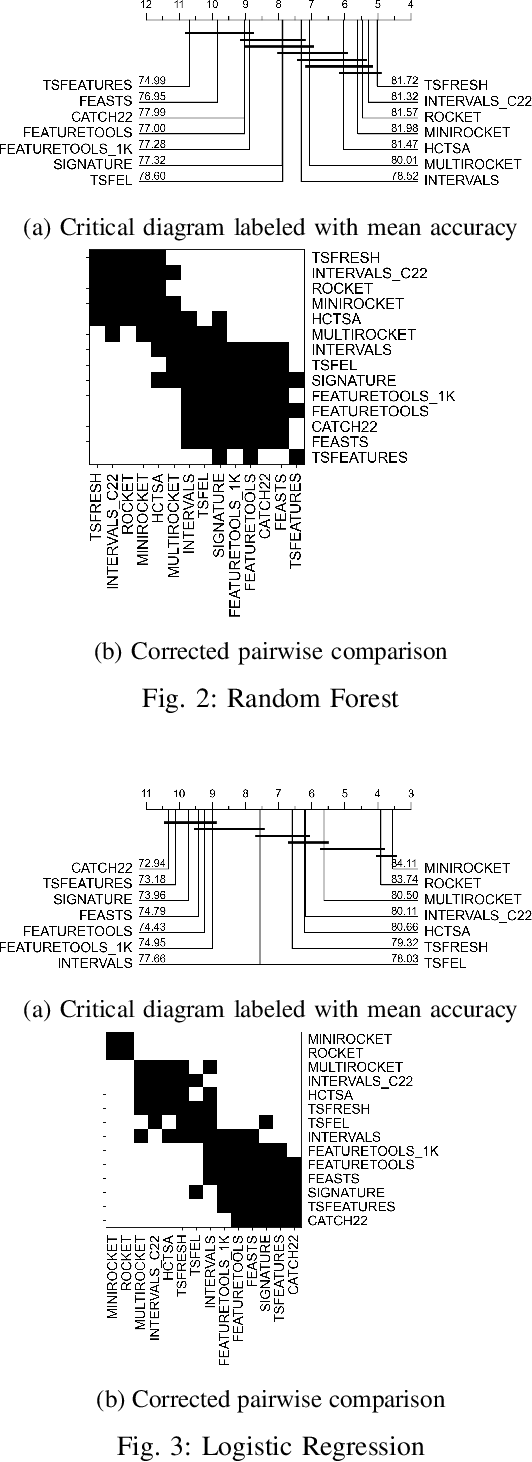
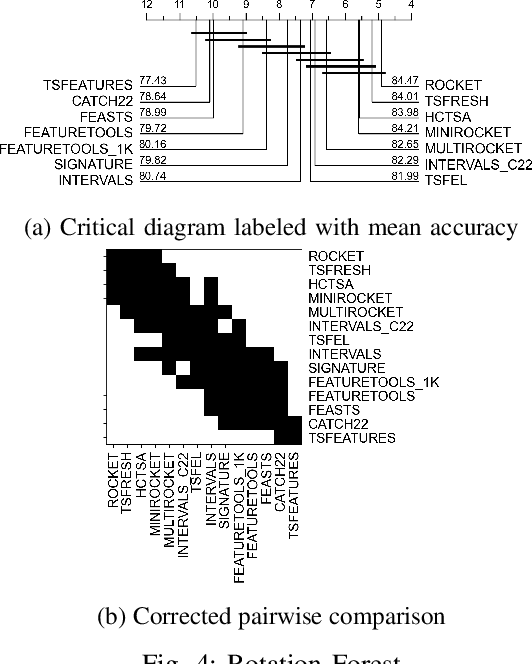
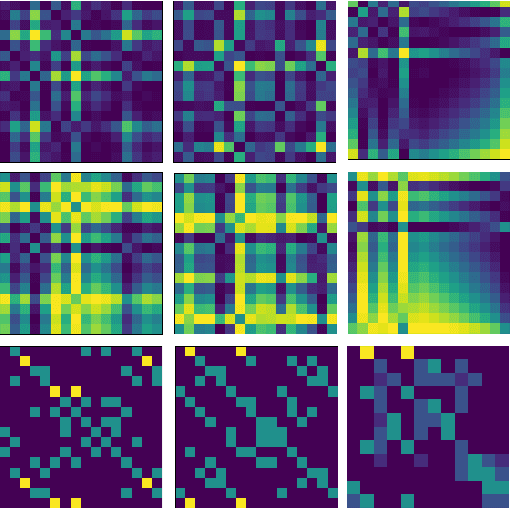
Time Series Classification (TSC) has received much attention in the past two decades and is still a crucial and challenging problem in data science and knowledge engineering. Indeed, along with the increasing availability of time series data, many TSC algorithms have been suggested by the research community in the literature. Besides state-of-the-art methods based on similarity measures, intervals, shapelets, dictionaries, deep learning methods or hybrid ensemble methods, several tools for extracting unsupervised informative summary statistics, aka features, from time series have been designed in the recent years. Originally designed for descriptive analysis and visualization of time series with informative and interpretable features, very few of these feature engineering tools have been benchmarked for TSC problems and compared with state-of-the-art TSC algorithms in terms of predictive performance. In this article, we aim at filling this gap and propose a simple TSC process to evaluate the potential predictive performance of the feature sets obtained with existing feature engineering tools. Thus, we present an empirical study of 11 feature engineering tools branched with 9 supervised classifiers over 112 time series data sets. The analysis of the results of more than 10000 learning experiments indicate that feature-based methods perform as accurately as current state-of-the-art TSC algorithms, and thus should rightfully be considered further in the TSC literature.