 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Text Classification": models, code, and papers
Sample based Explanations via Generalized Representers
Oct 27, 2023
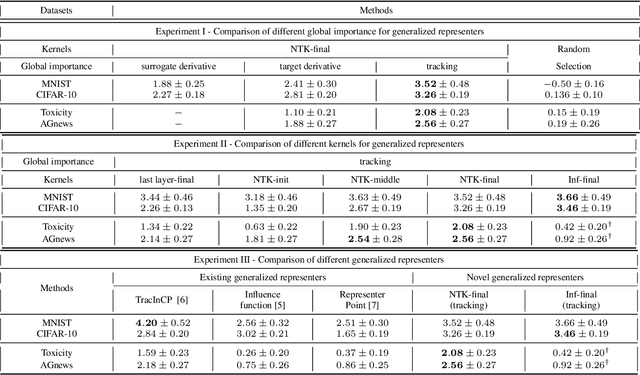
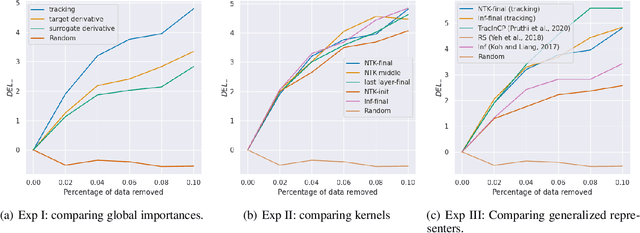
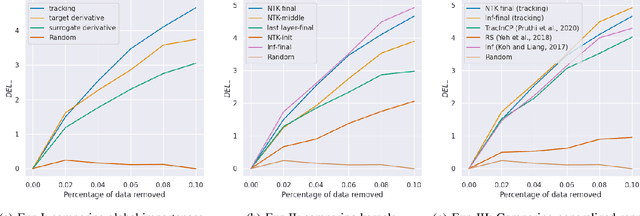
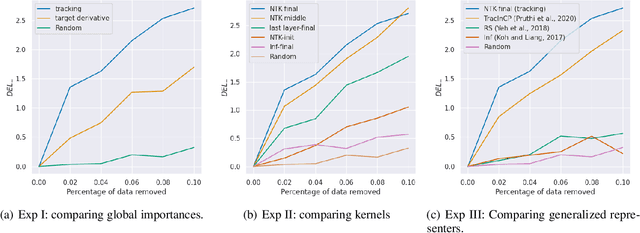
We propose a general class of sample based explanations of machine learning models, which we term generalized representers. To measure the effect of a training sample on a model's test prediction, generalized representers use two components: a global sample importance that quantifies the importance of the training point to the model and is invariant to test samples, and a local sample importance that measures similarity between the training sample and the test point with a kernel. A key contribution of the paper is to show that generalized representers are the only class of sample based explanations satisfying a natural set of axiomatic properties. We discuss approaches to extract global importances given a kernel, and also natural choices of kernels given modern non-linear models. As we show, many popular existing sample based explanations could be cast as generalized representers with particular choices of kernels and approaches to extract global importances. Additionally, we conduct empirical comparisons of different generalized representers on two image and two text classification datasets.
Graph Neural Networks for Text Classification: A Survey
Apr 27, 2023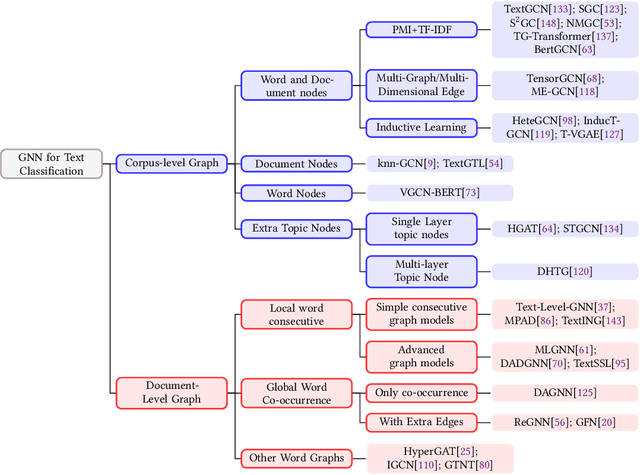
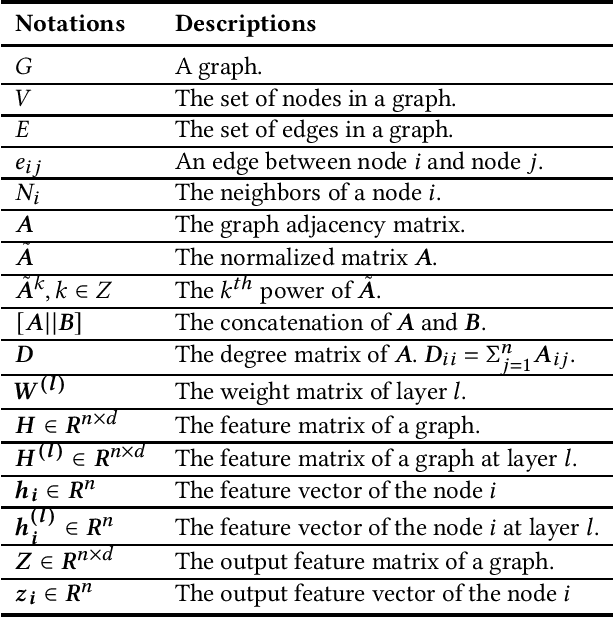
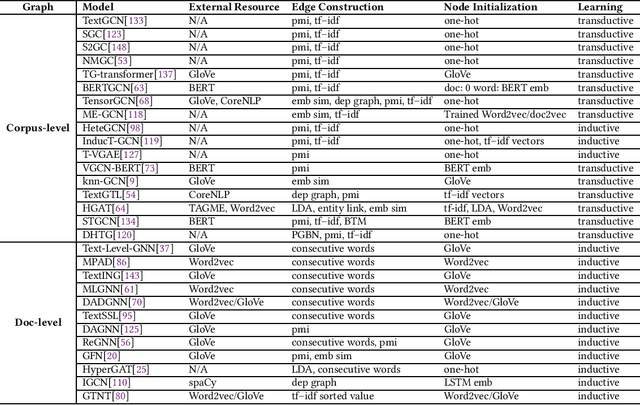
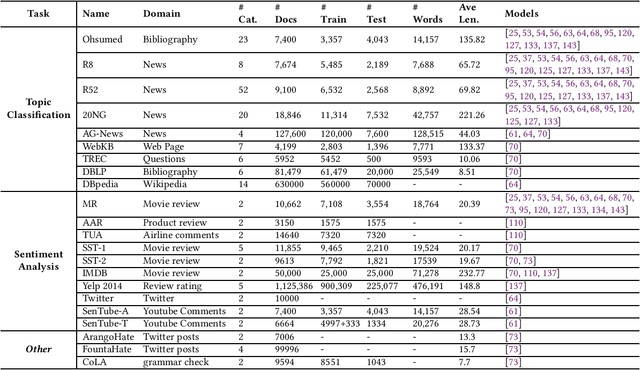
Text Classification is the most essential and fundamental problem in Natural Language Processing. While numerous recent text classification models applied the sequential deep learning technique, graph neural network-based models can directly deal with complex structured text data and exploit global information. Many real text classification applications can be naturally cast into a graph, which captures words, documents, and corpus global features. In this survey, we bring the coverage of methods up to 2023, including corpus-level and document-level graph neural networks. We discuss each of these methods in detail, dealing with the graph construction mechanisms and the graph-based learning process. As well as the technological survey, we look at issues behind and future directions addressed in text classification using graph neural networks. We also cover datasets, evaluation metrics, and experiment design and present a summary of published performance on the publicly available benchmarks. Note that we present a comprehensive comparison between different techniques and identify the pros and cons of various evaluation metrics in this survey.
MedAI Dialog Corpus (MEDIC): Zero-Shot Classification of Doctor and AI Responses in Health Consultations
Oct 19, 2023
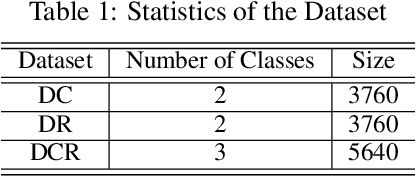

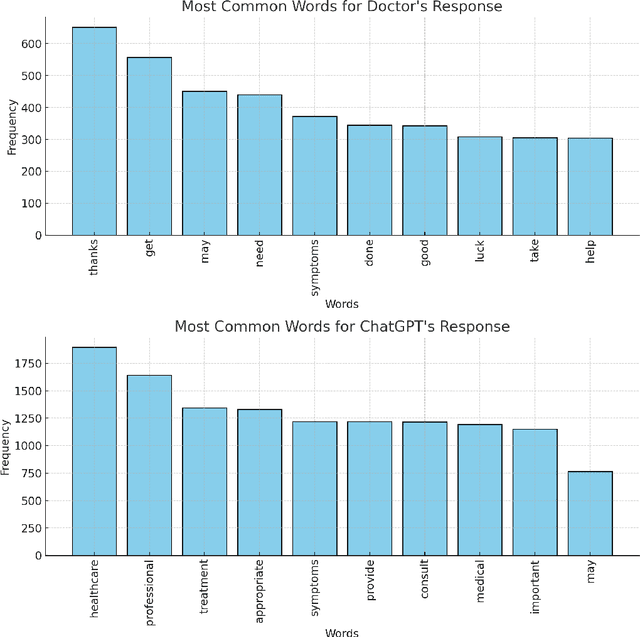
Zero-shot classification has enabled the classification of text into classes that were not seen during training. In this paper, we investigate the effectiveness of pre-trained language models to accurately classify responses from Doctors and AI in health consultations through zero-shot learning. Our study aims to determine whether these models can effectively detect if a text originates from human or AI models without specific corpus training. For our experiments, we collected responses from doctors to patient inquiries about their health and posed the same question/response to AI models. Our findings revealed that while pre-trained language models demonstrate a strong understanding of language generally, they may require specific corpus training or other techniques to achieve accurate classification of doctor- and AI-generated text in healthcare consultations. As a baseline approach, this study shows the limitations of relying solely on zero-shot classification in medical classification tasks. This research lays the groundwork for further research into the field of medical text classification, informing the development of more effective approaches to accurately classify doctor- and AI-generated text in health consultations.
Leveraging Label Variation in Large Language Models for Zero-Shot Text Classification
Jul 24, 2023The zero-shot learning capabilities of large language models (LLMs) make them ideal for text classification without annotation or supervised training. Many studies have shown impressive results across multiple tasks. While tasks, data, and results differ widely, their similarities to human annotation can aid us in tackling new tasks with minimal expenses. We evaluate using 5 state-of-the-art LLMs as "annotators" on 5 different tasks (age, gender, topic, sentiment prediction, and hate speech detection), across 4 languages: English, French, German, and Spanish. No single model excels at all tasks, across languages, or across all labels within a task. However, aggregation techniques designed for human annotators perform substantially better than any one individual model. Overall, though, LLMs do not rival even simple supervised models, so they do not (yet) replace the need for human annotation. We also discuss the tradeoffs between speed, accuracy, cost, and bias when it comes to aggregated model labeling versus human annotation.
LightCLIP: Learning Multi-Level Interaction for Lightweight Vision-Language Models
Dec 01, 2023Vision-language pre-training like CLIP has shown promising performance on various downstream tasks such as zero-shot image classification and image-text retrieval. Most of the existing CLIP-alike works usually adopt relatively large image encoders like ResNet50 and ViT, while the lightweight counterparts are rarely discussed. In this paper, we propose a multi-level interaction paradigm for training lightweight CLIP models. Firstly, to mitigate the problem that some image-text pairs are not strictly one-to-one correspondence, we improve the conventional global instance-level alignment objective by softening the label of negative samples progressively. Secondly, a relaxed bipartite matching based token-level alignment objective is introduced for finer-grained alignment between image patches and textual words. Moreover, based on the observation that the accuracy of CLIP model does not increase correspondingly as the parameters of text encoder increase, an extra objective of masked language modeling (MLM) is leveraged for maximizing the potential of the shortened text encoder. In practice, an auxiliary fusion module injecting unmasked image embedding into masked text embedding at different network stages is proposed for enhancing the MLM. Extensive experiments show that without introducing additional computational cost during inference, the proposed method achieves a higher performance on multiple downstream tasks.
On the Interplay between Fairness and Explainability
Oct 25, 2023In order to build reliable and trustworthy NLP applications, models need to be both fair across different demographics and explainable. Usually these two objectives, fairness and explainability, are optimized and/or examined independently of each other. Instead, we argue that forthcoming, trustworthy NLP systems should consider both. In this work, we perform a first study to understand how they influence each other: do fair(er) models rely on more plausible rationales? and vice versa. To this end, we conduct experiments on two English multi-class text classification datasets, BIOS and ECtHR, that provide information on gender and nationality, respectively, as well as human-annotated rationales. We fine-tune pre-trained language models with several methods for (i) bias mitigation, which aims to improve fairness; (ii) rationale extraction, which aims to produce plausible explanations. We find that bias mitigation algorithms do not always lead to fairer models. Moreover, we discover that empirical fairness and explainability are orthogonal.
Pushdown Layers: Encoding Recursive Structure in Transformer Language Models
Oct 29, 2023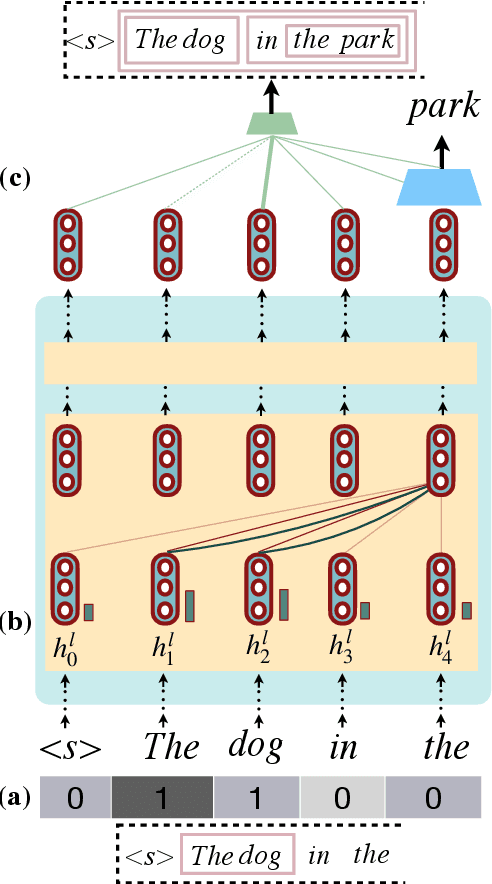
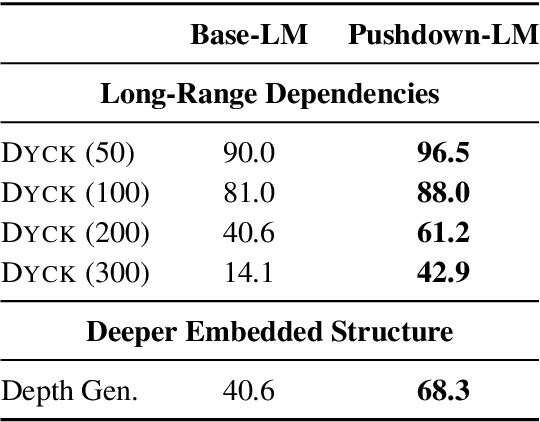
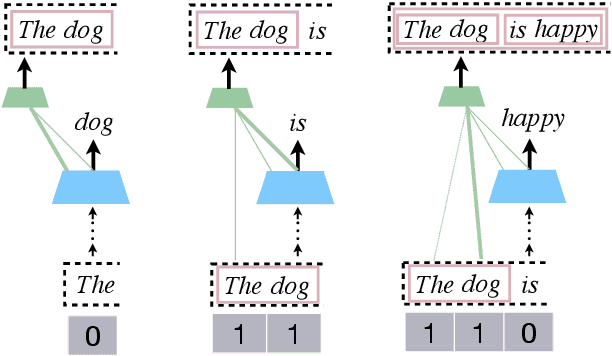
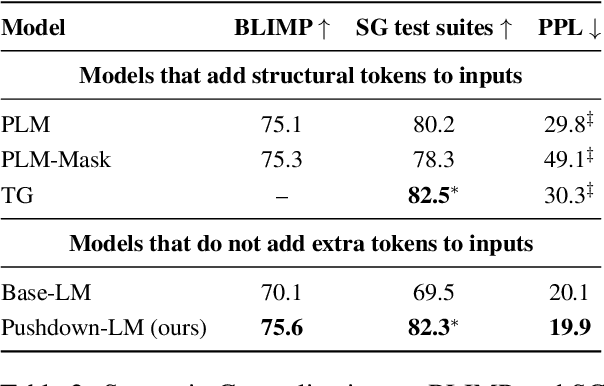
Recursion is a prominent feature of human language, and fundamentally challenging for self-attention due to the lack of an explicit recursive-state tracking mechanism. Consequently, Transformer language models poorly capture long-tail recursive structure and exhibit sample-inefficient syntactic generalization. This work introduces Pushdown Layers, a new self-attention layer that models recursive state via a stack tape that tracks estimated depths of every token in an incremental parse of the observed prefix. Transformer LMs with Pushdown Layers are syntactic language models that autoregressively and synchronously update this stack tape as they predict new tokens, in turn using the stack tape to softly modulate attention over tokens -- for instance, learning to "skip" over closed constituents. When trained on a corpus of strings annotated with silver constituency parses, Transformers equipped with Pushdown Layers achieve dramatically better and 3-5x more sample-efficient syntactic generalization, while maintaining similar perplexities. Pushdown Layers are a drop-in replacement for standard self-attention. We illustrate this by finetuning GPT2-medium with Pushdown Layers on an automatically parsed WikiText-103, leading to improvements on several GLUE text classification tasks.
Hardware Resilience Properties of Text-Guided Image Classifiers
Dec 05, 2023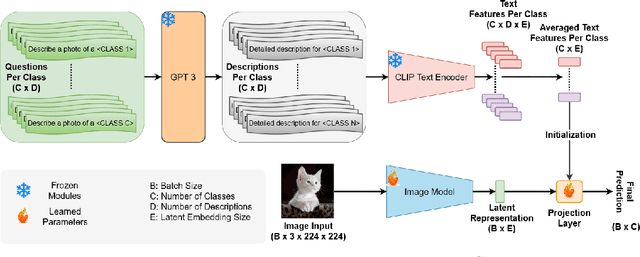
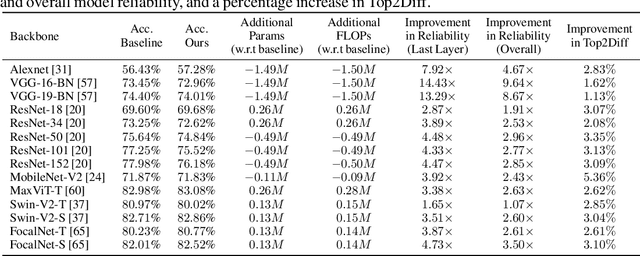
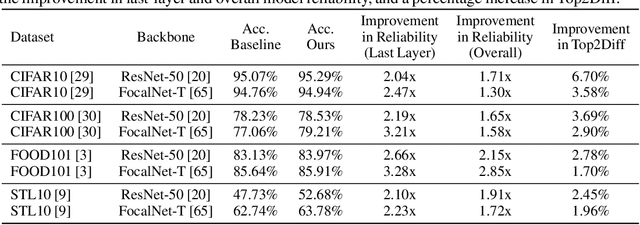

This paper presents a novel method to enhance the reliability of image classification models during deployment in the face of transient hardware errors. By utilizing enriched text embeddings derived from GPT-3 with question prompts per class and CLIP pretrained text encoder, we investigate their impact as an initialization for the classification layer. Our approach achieves a remarkable $5.5\times$ average increase in hardware reliability (and up to $14\times$) across various architectures in the most critical layer, with minimal accuracy drop ($0.3\%$ on average) compared to baseline PyTorch models. Furthermore, our method seamlessly integrates with any image classification backbone, showcases results across various network architectures, decreases parameter and FLOPs overhead, and follows a consistent training recipe. This research offers a practical and efficient solution to bolster the robustness of image classification models against hardware failures, with potential implications for future studies in this domain. Our code and models are released at https://github.com/TalalWasim/TextGuidedResilience.
Cross Encoding as Augmentation: Towards Effective Educational Text Classification
May 31, 2023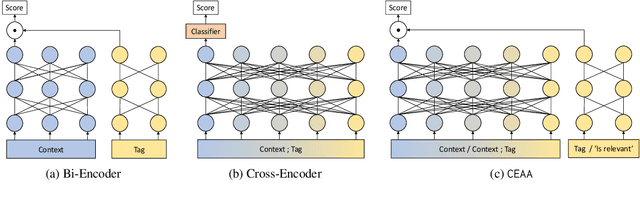
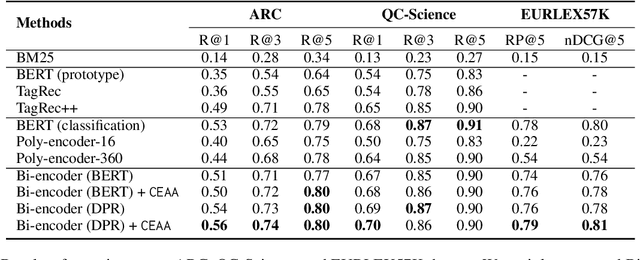
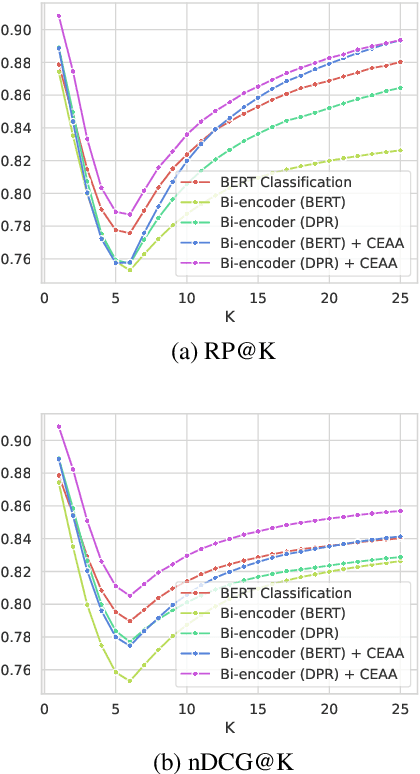
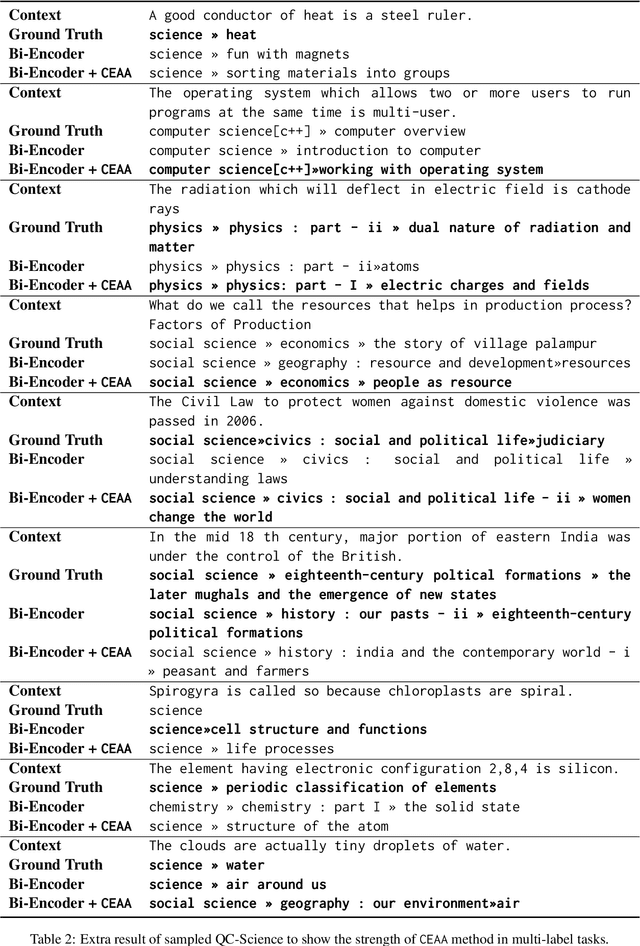
Text classification in education, usually called auto-tagging, is the automated process of assigning relevant tags to educational content, such as questions and textbooks. However, auto-tagging suffers from a data scarcity problem, which stems from two major challenges: 1) it possesses a large tag space and 2) it is multi-label. Though a retrieval approach is reportedly good at low-resource scenarios, there have been fewer efforts to directly address the data scarcity problem. To mitigate these issues, here we propose a novel retrieval approach CEAA that provides effective learning in educational text classification. Our main contributions are as follows: 1) we leverage transfer learning from question-answering datasets, and 2) we propose a simple but effective data augmentation method introducing cross-encoder style texts to a bi-encoder architecture for more efficient inference. An extensive set of experiments shows that our proposed method is effective in multi-label scenarios and low-resource tags compared to state-of-the-art models.