 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving Zero-shot Visual Question Answering via Large Language Models with Reasoning Question Prompts
Nov 15, 2023
Zero-shot Visual Question Answering (VQA) is a prominent vision-language task that examines both the visual and textual understanding capability of systems in the absence of training data. Recently, by converting the images into captions, information across multi-modalities is bridged and Large Language Models (LLMs) can apply their strong zero-shot generalization capability to unseen questions. To design ideal prompts for solving VQA via LLMs, several studies have explored different strategies to select or generate question-answer pairs as the exemplar prompts, which guide LLMs to answer the current questions effectively. However, they totally ignore the role of question prompts. The original questions in VQA tasks usually encounter ellipses and ambiguity which require intermediate reasoning. To this end, we present Reasoning Question Prompts for VQA tasks, which can further activate the potential of LLMs in zero-shot scenarios. Specifically, for each question, we first generate self-contained questions as reasoning question prompts via an unsupervised question edition module considering sentence fluency, semantic integrity and syntactic invariance. Each reasoning question prompt clearly indicates the intent of the original question. This results in a set of candidate answers. Then, the candidate answers associated with their confidence scores acting as answer heuristics are fed into LLMs and produce the final answer. We evaluate reasoning question prompts on three VQA challenges, experimental results demonstrate that they can significantly improve the results of LLMs on zero-shot setting and outperform existing state-of-the-art zero-shot methods on three out of four data sets. Our source code is publicly released at \url{https://github.com/ECNU-DASE-NLP/RQP}.
Resource-Aware Hierarchical Federated Learning for Video Caching in Wireless Networks
Nov 12, 2023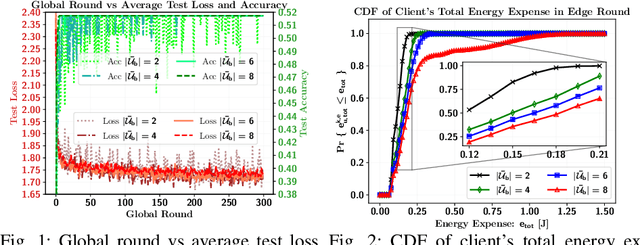
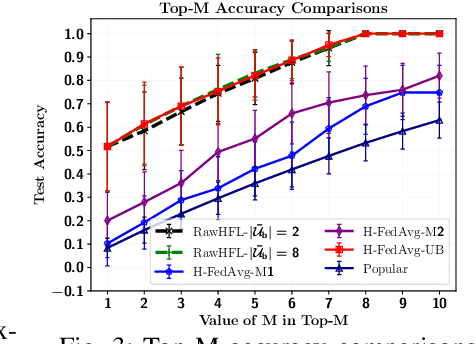
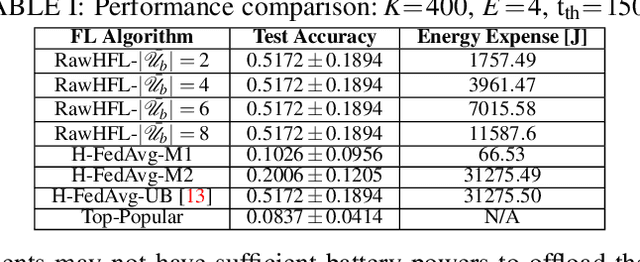
Video caching can significantly improve backhaul traffic congestion by locally storing the popular content that users frequently request. A privacy-preserving method is desirable to learn how users' demands change over time. As such, this paper proposes a novel resource-aware hierarchical federated learning (RawHFL) solution to predict users' future content requests under the realistic assumptions that content requests are sporadic and users' datasets can only be updated based on the requested content's information. Considering a partial client participation case, we first derive the upper bound of the global gradient norm that depends on the clients' local training rounds and the successful reception of their accumulated gradients over the wireless links. Under delay, energy and radio resource constraints, we then optimize client selection and their local rounds and central processing unit (CPU) frequencies to minimize a weighted utility function that facilitates RawHFL's convergence in an energy-efficient way. Our simulation results show that the proposed solution significantly outperforms the considered baselines in terms of prediction accuracy and total energy expenditure.
Dual-Branch Reconstruction Network for Industrial Anomaly Detection with RGB-D Data
Nov 12, 2023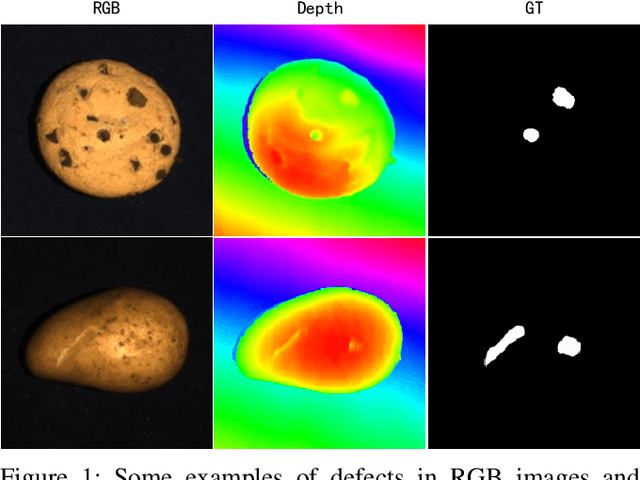
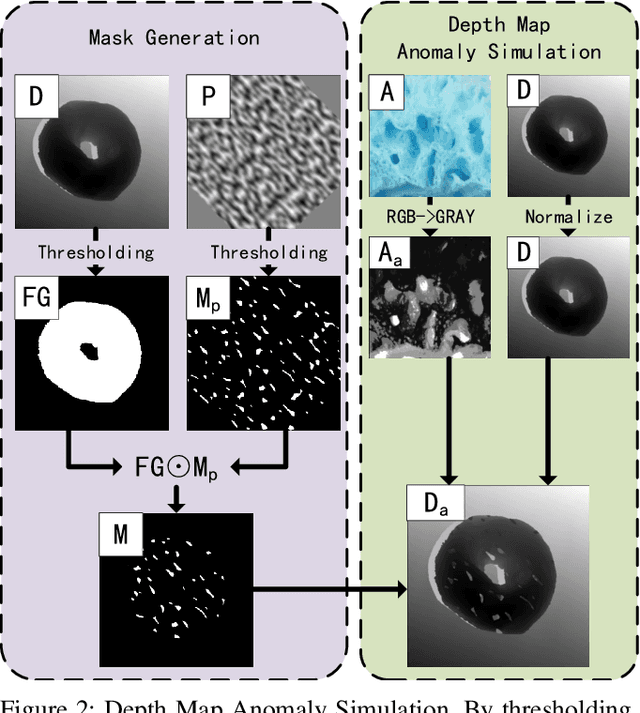
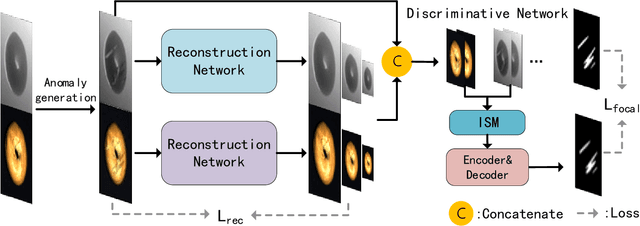
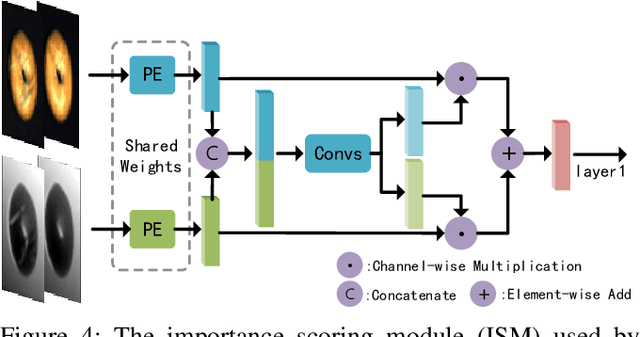
Unsupervised anomaly detection methods are at the forefront of industrial anomaly detection efforts and have made notable progress. Previous work primarily used 2D information as input, but multi-modal industrial anomaly detection based on 3D point clouds and RGB images is just beginning to emerge. The regular approach involves utilizing large pre-trained models for feature representation and storing them in memory banks. However, the above methods require a longer inference time and higher memory usage, which cannot meet the real-time requirements of the industry. To overcome these issues, we propose a lightweight dual-branch reconstruction network(DBRN) based on RGB-D input, learning the decision boundary between normal and abnormal examples. The requirement for alignment between the two modalities is eliminated by using depth maps instead of point cloud input. Furthermore, we introduce an importance scoring module in the discriminative network to assist in fusing features from these two modalities, thereby obtaining a comprehensive discriminative result. DBRN achieves 92.8% AUROC with high inference efficiency on the MVTec 3D-AD dataset without large pre-trained models and memory banks.
One Signal-Noise Separation based Wiener Filter for Magnetogastrogram
Nov 12, 2023Magnetogastrogram (MGG) signal frequency is about 0.05 Hz, the low-frequency environmental noise interference is serious and can be several times stronger in magnitude than the signals of interest and may severely impede the extraction of relevant information. Wiener filter is one classic denoising solution for biomagnetic applications. Since the reference channels are usually placed not far enough from the biomagnetic sources under test, they will inevitably detect the signals and the Wiener filters may produce ill-conditioned solutions. Considering the solutions to improve the signal-to-noise ratio (SNR) of Wiener filter output, there are few methods to separate the signals from the noises of the reference signal at the filter input. In this paper, a new signal processing framework called signal-noise separation based Wiener filter (SNSWF) is proposed that it separates the main noise as the input signal of the filter to improve the output SNR of Wiener filter. The filter was successfully applied to the noise suppression for MGG signal detection. Using the SNSWF, the filter SNR is 16.7 dB better than the classic Wiener filter.
Polarimetric PatchMatch Multi-View Stereo
Nov 11, 2023PatchMatch Multi-View Stereo (PatchMatch MVS) is one of the popular MVS approaches, owing to its balanced accuracy and efficiency. In this paper, we propose Polarimetric PatchMatch multi-view Stereo (PolarPMS), which is the first method exploiting polarization cues to PatchMatch MVS. The key of PatchMatch MVS is to generate depth and normal hypotheses, which form local 3D planes and slanted stereo matching windows, and efficiently search for the best hypothesis based on the consistency among multi-view images. In addition to standard photometric consistency, our PolarPMS evaluates polarimetric consistency to assess the validness of a depth and normal hypothesis, motivated by the physical property that the polarimetric information is related to the object's surface normal. Experimental results demonstrate that our PolarPMS can improve the accuracy and the completeness of reconstructed 3D models, especially for texture-less surfaces, compared with state-of-the-art PatchMatch MVS methods.
Communication Efficient and Privacy-Preserving Federated Learning Based on Evolution Strategies
Nov 09, 2023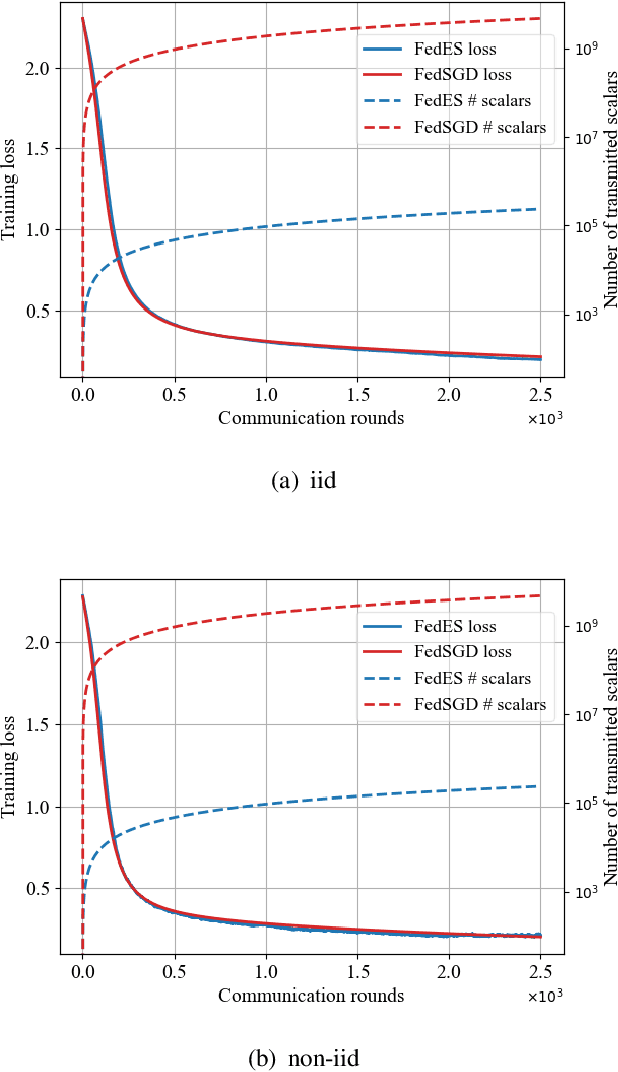
Federated learning (FL) is an emerging paradigm for training deep neural networks (DNNs) in distributed manners. Current FL approaches all suffer from high communication overhead and information leakage. In this work, we present a federated learning algorithm based on evolution strategies (FedES), a zeroth-order training method. Instead of transmitting model parameters, FedES only communicates loss values, and thus has very low communication overhead. Moreover, a third party is unable to estimate gradients without knowing the pre-shared seed, which protects data privacy. Experimental results demonstrate FedES can achieve the above benefits while keeping convergence performance the same as that with back propagation methods.
Unifying Structure and Language Semantic for Efficient Contrastive Knowledge Graph Completion with Structured Entity Anchors
Nov 07, 2023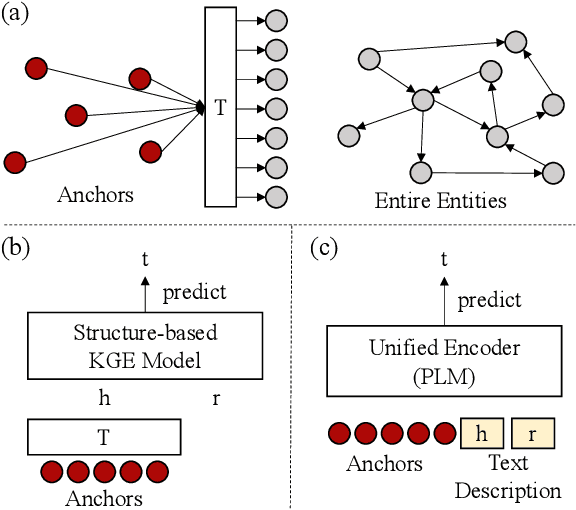
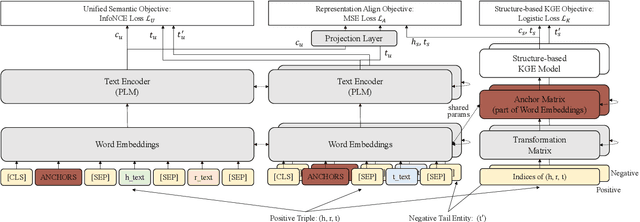
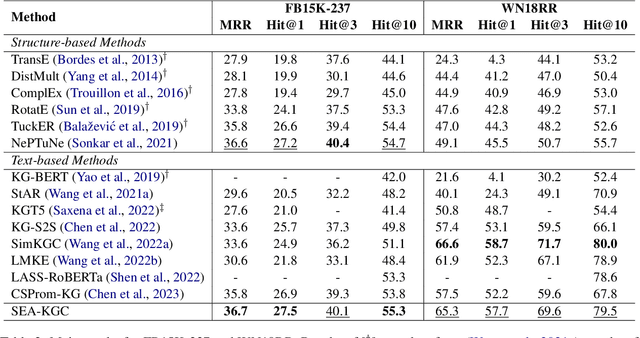
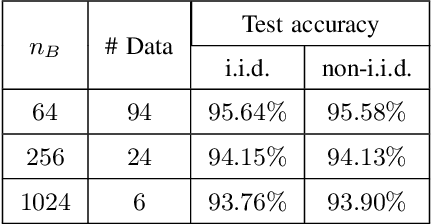
The goal of knowledge graph completion (KGC) is to predict missing links in a KG using trained facts that are already known. In recent, pre-trained language model (PLM) based methods that utilize both textual and structural information are emerging, but their performances lag behind state-of-the-art (SOTA) structure-based methods or some methods lose their inductive inference capabilities in the process of fusing structure embedding to text encoder. In this paper, we propose a novel method to effectively unify structure information and language semantics without losing the power of inductive reasoning. We adopt entity anchors and these anchors and textual description of KG elements are fed together into the PLM-based encoder to learn unified representations. In addition, the proposed method utilizes additional random negative samples which can be reused in the each mini-batch during contrastive learning to learn a generalized entity representations. We verify the effectiveness of the our proposed method through various experiments and analysis. The experimental results on standard benchmark widely used in link prediction task show that the proposed model outperforms existing the SOTA KGC models. Especially, our method show the largest performance improvement on FB15K-237, which is competitive to the SOTA of structure-based KGC methods.
Constrained Independent Vector Analysis with Reference for Multi-Subject fMRI Analysis
Nov 08, 2023Independent component analysis (ICA) is now a widely used solution for the analysis of multi-subject functional magnetic resonance imaging (fMRI) data. Independent vector analysis (IVA) generalizes ICA to multiple datasets, i.e., to multi-subject data, and in addition to higher-order statistical information in ICA, it leverages the statistical dependence across the datasets as an additional type of statistical diversity. As such, it preserves variability in the estimation of single-subject maps but its performance might suffer when the number of datasets increases. Constrained IVA is an effective way to bypass computational issues and improve the quality of separation by incorporating available prior information. Existing constrained IVA approaches often rely on user-defined threshold values to define the constraints. However, an improperly selected threshold can have a negative impact on the final results. This paper proposes two novel methods for constrained IVA: one using an adaptive-reverse scheme to select variable thresholds for the constraints and a second one based on a threshold-free formulation by leveraging the unique structure of IVA. We demonstrate that our solutions provide an attractive solution to multi-subject fMRI analysis both by simulations and through analysis of resting state fMRI data collected from 98 subjects -- the highest number of subjects ever used by IVA algorithms. Our results show that both proposed approaches obtain significantly better separation quality and model match while providing computationally efficient and highly reproducible solutions.
Mixed Attention Network for Cross-domain Sequential Recommendation
Nov 14, 2023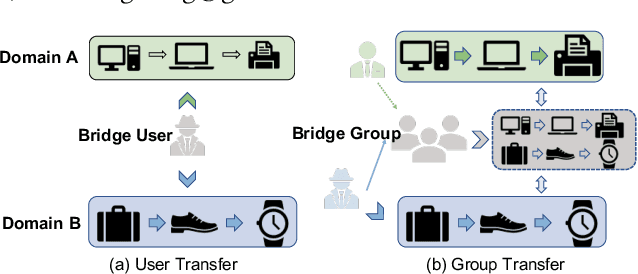
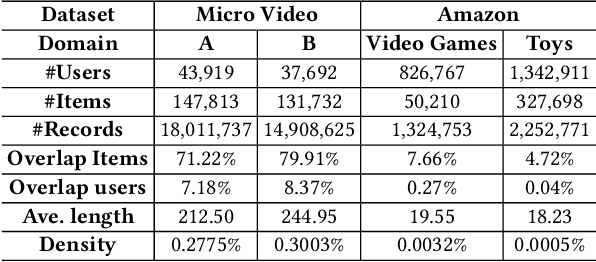
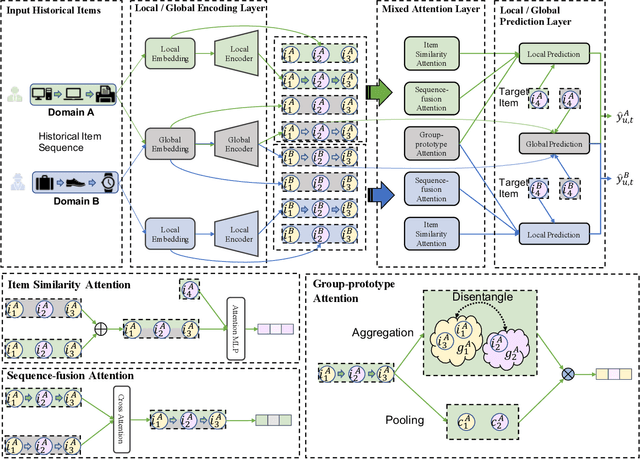
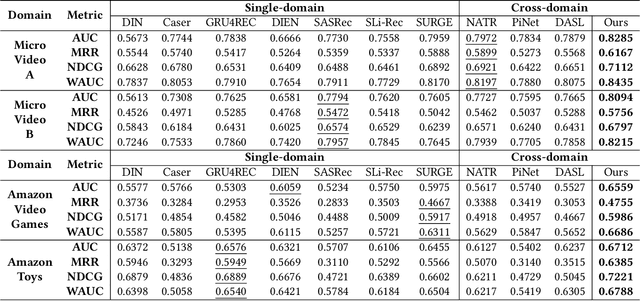
In modern recommender systems, sequential recommendation leverages chronological user behaviors to make effective next-item suggestions, which suffers from data sparsity issues, especially for new users. One promising line of work is the cross-domain recommendation, which trains models with data across multiple domains to improve the performance in data-scarce domains. Recent proposed cross-domain sequential recommendation models such as PiNet and DASL have a common drawback relying heavily on overlapped users in different domains, which limits their usage in practical recommender systems. In this paper, we propose a Mixed Attention Network (MAN) with local and global attention modules to extract the domain-specific and cross-domain information. Firstly, we propose a local/global encoding layer to capture the domain-specific/cross-domain sequential pattern. Then we propose a mixed attention layer with item similarity attention, sequence-fusion attention, and group-prototype attention to capture the local/global item similarity, fuse the local/global item sequence, and extract the user groups across different domains, respectively. Finally, we propose a local/global prediction layer to further evolve and combine the domain-specific and cross-domain interests. Experimental results on two real-world datasets (each with two domains) demonstrate the superiority of our proposed model. Further study also illustrates that our proposed method and components are model-agnostic and effective, respectively. The code and data are available at https://github.com/Guanyu-Lin/MAN.
Cooperative Coherent Multistatic Imaging and Phase Synchronization in Networked Sensing
Nov 13, 2023Coherent multistatic radio imaging represents a pivotal opportunity for forthcoming wireless networks, which involves distributed nodes cooperating to achieve accurate sensing resolution and robustness. This paper delves into cooperative coherent imaging for vehicular radar networks. Herein, multiple radar-equipped vehicles cooperate to improve collective sensing capabilities and address the fundamental issue of distinguishing weak targets in close proximity to strong ones, a critical challenge for vulnerable road users protection. We prove the significant benefits of cooperative coherent imaging in the considered automotive scenario in terms of both probability of correct detection, evaluated considering several system parameters, as well as resolution capabilities, showcased by a dedicated experimental campaign wherein the collaboration between two vehicles enables the detection of the legs of a pedestrian close to a parked car. Moreover, as \textit{coherent} processing of several sensors' data requires very tight accuracy on clock synchronization and sensor's positioning -- referred to as \textit{phase synchronization} -- (such that to predict sensor-target distances up to a fraction of the carrier wavelength), we present a general three-step cooperative multistatic phase synchronization procedure, detailing the required information exchange among vehicles in the specific automotive radar context and assessing its feasibility and performance by hybrid Cram\'er-Rao bound.