 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Investigating the Encoding of Words in BERT's Neurons using Feature Textualization
Nov 14, 2023
Pretrained language models (PLMs) form the basis of most state-of-the-art NLP technologies. Nevertheless, they are essentially black boxes: Humans do not have a clear understanding of what knowledge is encoded in different parts of the models, especially in individual neurons. The situation is different in computer vision, where feature visualization provides a decompositional interpretability technique for neurons of vision models. Activation maximization is used to synthesize inherently interpretable visual representations of the information encoded in individual neurons. Our work is inspired by this but presents a cautionary tale on the interpretability of single neurons, based on the first large-scale attempt to adapt activation maximization to NLP, and, more specifically, large PLMs. We propose feature textualization, a technique to produce dense representations of neurons in the PLM word embedding space. We apply feature textualization to the BERT model (Devlin et al., 2019) to investigate whether the knowledge encoded in individual neurons can be interpreted and symbolized. We find that the produced representations can provide insights about the knowledge encoded in individual neurons, but that individual neurons do not represent clearcut symbolic units of language such as words. Additionally, we use feature textualization to investigate how many neurons are needed to encode words in BERT.
Test-Time Training for Semantic Segmentation with Output Contrastive Loss
Nov 14, 2023Although deep learning-based segmentation models have achieved impressive performance on public benchmarks, generalizing well to unseen environments remains a major challenge. To improve the model's generalization ability to the new domain during evaluation, the test-time training (TTT) is a challenging paradigm that adapts the source-pretrained model in an online fashion. Early efforts on TTT mainly focus on the image classification task. Directly extending these methods to semantic segmentation easily experiences unstable adaption due to segmentation's inherent characteristics, such as extreme class imbalance and complex decision spaces. To stabilize the adaptation process, we introduce contrastive loss (CL), known for its capability to learn robust and generalized representations. Nevertheless, the traditional CL operates in the representation space and cannot directly enhance predictions. In this paper, we resolve this limitation by adapting the CL to the output space, employing a high temperature, and simplifying the formulation, resulting in a straightforward yet effective loss function called Output Contrastive Loss (OCL). Our comprehensive experiments validate the efficacy of our approach across diverse evaluation scenarios. Notably, our method excels even when applied to models initially pre-trained using domain adaptation methods on test domain data, showcasing its resilience and adaptability.\footnote{Code and more information could be found at~ \url{https://github.com/dazhangyu123/OCL}}
Communication-Constrained Bayesian Active Knowledge Distillation
Nov 14, 2023Consider an active learning setting in which a learner has a training set with few labeled examples and a pool set with many unlabeled inputs, while a remote teacher has a pre-trained model that is known to perform well for the learner's task. The learner actively transmits batches of unlabeled inputs to the teacher through a constrained communication channel for labeling. This paper addresses the following key questions: (i) Active batch selection: Which batch of inputs should be sent to the teacher to acquire the most useful information and thus reduce the number of required communication rounds? (ii) Batch encoding: How do we encode the batch of inputs for transmission to the teacher to reduce the communication resources required at each round? We introduce Communication-Constrained Bayesian Active Knowledge Distillation (CC-BAKD), a novel protocol that integrates Bayesian active learning with compression via a linear mix-up mechanism. Bayesian active learning selects the batch of inputs based on their epistemic uncertainty, addressing the "confirmation bias" that is known to increase the number of required communication rounds. Furthermore, the proposed mix-up compression strategy is integrated with the epistemic uncertainty-based active batch selection process to reduce the communication overhead per communication round.
Bring Your Own KG: Self-Supervised Program Synthesis for Zero-Shot KGQA
Nov 14, 2023We present BYOKG, a universal question-answering (QA) system that can operate on any knowledge graph (KG), requires no human-annotated training data, and can be ready to use within a day -- attributes that are out-of-scope for current KGQA systems. BYOKG draws inspiration from the remarkable ability of humans to comprehend information present in an unseen KG through exploration -- starting at random nodes, inspecting the labels of adjacent nodes and edges, and combining them with their prior world knowledge. In BYOKG, exploration leverages an LLM-backed symbolic agent that generates a diverse set of query-program exemplars, which are then used to ground a retrieval-augmented reasoning procedure to predict programs for arbitrary questions. BYOKG is effective over both small- and large-scale graphs, showing dramatic gains in QA accuracy over a zero-shot baseline of 27.89 and 58.02 F1 on GrailQA and MetaQA, respectively. On GrailQA, we further show that our unsupervised BYOKG outperforms a supervised in-context learning method, demonstrating the effectiveness of exploration. Lastly, we find that performance of BYOKG reliably improves with continued exploration as well as improvements in the base LLM, notably outperforming a state-of-the-art fine-tuned model by 7.08 F1 on a sub-sampled zero-shot split of GrailQA.
Leveraging sinusoidal representation networks to predict fMRI signals from EEG
Nov 06, 2023In modern neuroscience, functional magnetic resonance imaging (fMRI) has been a crucial and irreplaceable tool that provides a non-invasive window into the dynamics of whole-brain activity. Nevertheless, fMRI is limited by hemodynamic blurring as well as high cost, immobility, and incompatibility with metal implants. Electroencephalography (EEG) is complementary to fMRI and can directly record the cortical electrical activity at high temporal resolution, but has more limited spatial resolution and is unable to recover information about deep subcortical brain structures. The ability to obtain fMRI information from EEG would enable cost-effective, imaging across a wider set of brain regions. Further, beyond augmenting the capabilities of EEG, cross-modality models would facilitate the interpretation of fMRI signals. However, as both EEG and fMRI are high-dimensional and prone to artifacts, it is currently challenging to model fMRI from EEG. To address this challenge, we propose a novel architecture that can predict fMRI signals directly from multi-channel EEG without explicit feature engineering. Our model achieves this by implementing a Sinusoidal Representation Network (SIREN) to learn frequency information in brain dynamics from EEG, which serves as the input to a subsequent encoder-decoder to effectively reconstruct the fMRI signal from a specific brain region. We evaluate our model using a simultaneous EEG-fMRI dataset with 8 subjects and investigate its potential for predicting subcortical fMRI signals. The present results reveal that our model outperforms a recent state-of-the-art model, and indicates the potential of leveraging periodic activation functions in deep neural networks to model functional neuroimaging data.
Exact Recovery and Bregman Hard Clustering of Node-Attributed Stochastic Block Model
Oct 30, 2023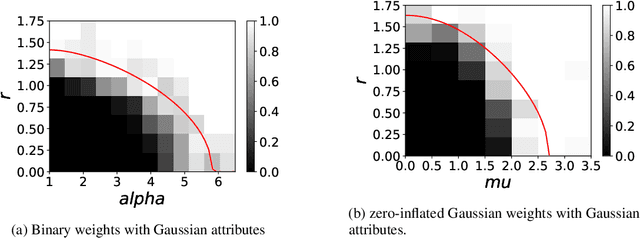
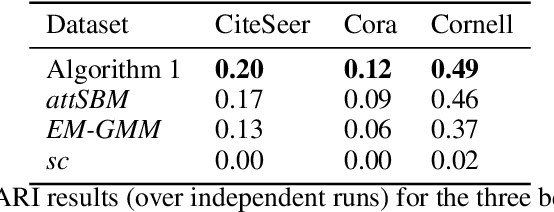
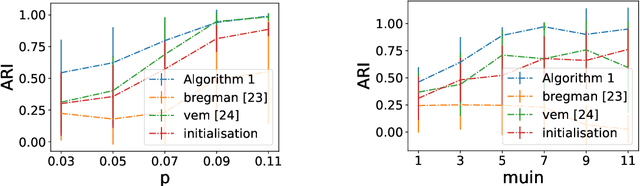
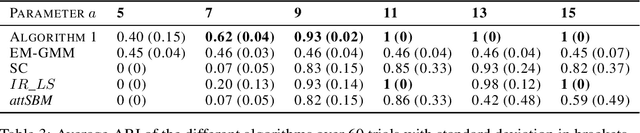
Network clustering tackles the problem of identifying sets of nodes (communities) that have similar connection patterns. However, in many scenarios, nodes also have attributes that are correlated with the clustering structure. Thus, network information (edges) and node information (attributes) can be jointly leveraged to design high-performance clustering algorithms. Under a general model for the network and node attributes, this work establishes an information-theoretic criterion for the exact recovery of community labels and characterizes a phase transition determined by the Chernoff-Hellinger divergence of the model. The criterion shows how network and attribute information can be exchanged in order to have exact recovery (e.g., more reliable network information requires less reliable attribute information). This work also presents an iterative clustering algorithm that maximizes the joint likelihood, assuming that the probability distribution of network interactions and node attributes belong to exponential families. This covers a broad range of possible interactions (e.g., edges with weights) and attributes (e.g., non-Gaussian models), as well as sparse networks, while also exploring the connection between exponential families and Bregman divergences. Extensive numerical experiments using synthetic data indicate that the proposed algorithm outperforms classic algorithms that leverage only network or only attribute information as well as state-of-the-art algorithms that also leverage both sources of information. The contributions of this work provide insights into the fundamental limits and practical techniques for inferring community labels on node-attributed networks.
Leveraging Label Information for Multimodal Emotion Recognition
Sep 05, 2023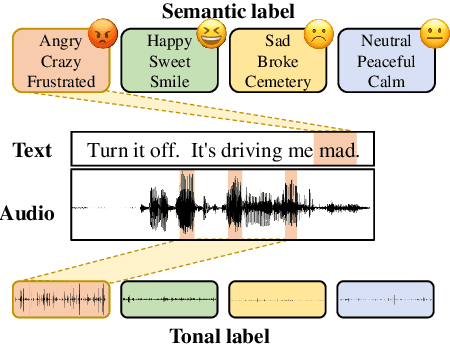

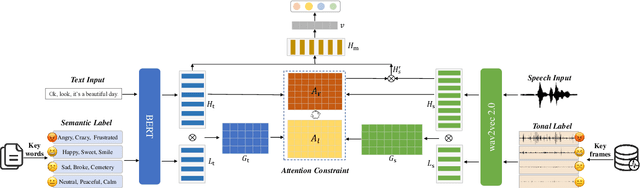
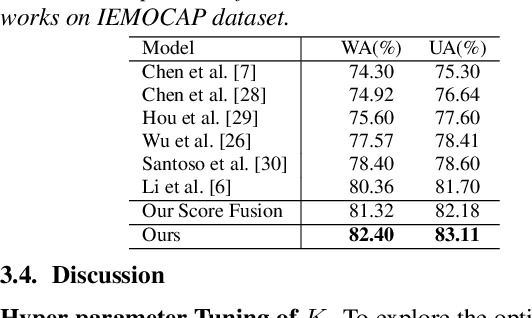
Multimodal emotion recognition (MER) aims to detect the emotional status of a given expression by combining the speech and text information. Intuitively, label information should be capable of helping the model locate the salient tokens/frames relevant to the specific emotion, which finally facilitates the MER task. Inspired by this, we propose a novel approach for MER by leveraging label information. Specifically, we first obtain the representative label embeddings for both text and speech modalities, then learn the label-enhanced text/speech representations for each utterance via label-token and label-frame interactions. Finally, we devise a novel label-guided attentive fusion module to fuse the label-aware text and speech representations for emotion classification. Extensive experiments were conducted on the public IEMOCAP dataset, and experimental results demonstrate that our proposed approach outperforms existing baselines and achieves new state-of-the-art performance.
ChatGPT-3.5, ChatGPT-4, Google Bard, and Microsoft Bing to Improve Health Literacy and Communication in Pediatric Populations and Beyond
Nov 16, 2023Purpose: Enhanced health literacy has been linked to better health outcomes; however, few interventions have been studied. We investigate whether large language models (LLMs) can serve as a medium to improve health literacy in children and other populations. Methods: We ran 288 conditions using 26 different prompts through ChatGPT-3.5, Microsoft Bing, and Google Bard. Given constraints imposed by rate limits, we tested a subset of 150 conditions through ChatGPT-4. The primary outcome measurements were the reading grade level (RGL) and word counts of output. Results: Across all models, output for basic prompts such as "Explain" and "What is (are)" were at, or exceeded, a 10th-grade RGL. When prompts were specified to explain conditions from the 1st to 12th RGL, we found that LLMs had varying abilities to tailor responses based on RGL. ChatGPT-3.5 provided responses that ranged from the 7th-grade to college freshmen RGL while ChatGPT-4 outputted responses from the 6th-grade to the college-senior RGL. Microsoft Bing provided responses from the 9th to 11th RGL while Google Bard provided responses from the 7th to 10th RGL. Discussion: ChatGPT-3.5 and ChatGPT-4 did better in achieving lower-grade level outputs. Meanwhile Bard and Bing tended to consistently produce an RGL that is at the high school level regardless of prompt. Additionally, Bard's hesitancy in providing certain outputs indicates a cautious approach towards health information. LLMs demonstrate promise in enhancing health communication, but future research should verify the accuracy and effectiveness of such tools in this context. Implications: LLMs face challenges in crafting outputs below a sixth-grade reading level. However, their capability to modify outputs above this threshold provides a potential mechanism to improve health literacy and communication in a pediatric population and beyond.
Understanding Practices around Computational News Discovery Tools in the Domain of Science Journalism
Nov 12, 2023Science and technology journalists today face challenges in finding newsworthy leads due to increased workloads, reduced resources, and expanding scientific publishing ecosystems. Given this context, we explore computational methods to aid these journalists' news discovery in terms of time-efficiency and agency. In particular, we prototyped three computational information subsidies into an interactive tool that we used as a probe to better understand how such a tool may offer utility or more broadly shape the practices of professional science journalists. Our findings highlight central considerations around science journalists' agency, context, and responsibilities that such tools can influence and could account for in design. Based on this, we suggest design opportunities for greater and longer-term user agency; incorporating contextual, personal and collaborative notions of newsworthiness; and leveraging flexible interfaces and generative models. Overall, our findings contribute a richer view of the sociotechnical system around computational news discovery tools, and suggest ways to improve such tools to better support the practices of science journalists.
Context Unlocks Emotions: Text-based Emotion Classification Dataset Auditing with Large Language Models
Nov 06, 2023The lack of contextual information in text data can make the annotation process of text-based emotion classification datasets challenging. As a result, such datasets often contain labels that fail to consider all the relevant emotions in the vocabulary. This misalignment between text inputs and labels can degrade the performance of machine learning models trained on top of them. As re-annotating entire datasets is a costly and time-consuming task that cannot be done at scale, we propose to use the expressive capabilities of large language models to synthesize additional context for input text to increase its alignment with the annotated emotional labels. In this work, we propose a formal definition of textual context to motivate a prompting strategy to enhance such contextual information. We provide both human and empirical evaluation to demonstrate the efficacy of the enhanced context. Our method improves alignment between inputs and their human-annotated labels from both an empirical and human-evaluated standpoint.