 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Sources?: Auditing Generative Search Engine Citations for Evidence of AI-Generated Sources
May 22, 2026The growing accessibility of Large Language Models via conversational interfaces capable of responding to users' questions by drawing on, synthesizing, and citing information from the web (i.e., Generative Search Engines) has simplified the information-seeking process for users. However, with the proliferation of AI-generated content on the web, it is unclear whether these engines can reliably omit citing synthetic sources (i.e., AI-generated sources). Should these engines be unable to do so, this puts users at risk of harm by treating information from AI-generated sources synthesized in responses of generative search engines as equivalent to information from authoritative or official sources. In a step towards identifying whether AI-generated sources are being cited by these engines, this work presents an audit of four generative search engines (ChatGPT, Copilot, Gemini, Perplexity) using a total of 712 real-world human-generated queries spanning domains of public importance: politics, health, and the environment. Our findings show evidence of AI-generated sources being cited across all four generative search engines (~16% of cited sources) and identifies key source web domains these sources belong to that are frequently cited across these engines and topics. In addition, we observed that generative search engines include a somewhat narrow set of repeatedly cited domains while predominantly surfacing a large number of minimally cited domains in responses to users' queries. These findings contribute to the growing body of work on assessing the risks of generative search engines with the objective of increasing public awareness of their limitations and encouraging appropriate measures to improve information quality and governance of these systems.
Scenarios in Computing Research: A Systematic Review of the Use of Scenario Methods for Exploring the Future of Computing Technologies in Society
Jun 05, 2025



Scenario building is an established method to anticipate the future of emerging technologies. Its primary goal is to use narratives to map future trajectories of technology development and sociotechnical adoption. Following this process, risks and benefits can be identified early on, and strategies can be developed that strive for desirable futures. In recent years, computer science has adopted this method and applied it to various technologies, including Artificial Intelligence (AI). Because computing technologies play such an important role in shaping modern societies, it is worth exploring how scenarios are being used as an anticipatory tool in the field -- and what possible traditional uses of scenarios are not yet covered but have the potential to enrich the field. We address this gap by conducting a systematic literature review on the use of scenario building methods in computer science over the last decade (n = 59). We guide the review along two main questions. First, we aim to uncover how scenarios are used in computing literature, focusing especially on the rationale for why scenarios are used. Second, in following the potential of scenario building to enhance inclusivity in research, we dive deeper into the participatory element of the existing scenario building literature in computer science.
Towards Leveraging News Media to Support Impact Assessment of AI Technologies
Nov 04, 2024Expert-driven frameworks for impact assessments (IAs) may inadvertently overlook the effects of AI technologies on the public's social behavior, policy, and the cultural and geographical contexts shaping the perception of AI and the impacts around its use. This research explores the potentials of fine-tuning LLMs on negative impacts of AI reported in a diverse sample of articles from 266 news domains spanning 30 countries around the world to incorporate more diversity into IAs. Our findings highlight (1) the potential of fine-tuned open-source LLMs in supporting IA of AI technologies by generating high-quality negative impacts across four qualitative dimensions: coherence, structure, relevance, and plausibility, and (2) the efficacy of small open-source LLM (Mistral-7B) fine-tuned on impacts from news media in capturing a wider range of categories of impacts that GPT-4 had gaps in covering.
De-jargonizing Science for Journalists with GPT-4: A Pilot Study
Oct 15, 2024



This study offers an initial evaluation of a human-in-the-loop system leveraging GPT-4 (a large language model or LLM), and Retrieval-Augmented Generation (RAG) to identify and define jargon terms in scientific abstracts, based on readers' self-reported knowledge. The system achieves fairly high recall in identifying jargon and preserves relative differences in readers' jargon identification, suggesting personalization as a feasible use-case for LLMs to support sense-making of complex information. Surprisingly, using only abstracts for context to generate definitions yields slightly more accurate and higher quality definitions than using RAG-based context from the fulltext of an article. The findings highlight the potential of generative AI for assisting science reporters, and can inform future work on developing tools to simplify dense documents.
Using Generative Agents to Create Tip Sheets for Investigative Data Reporting
Sep 11, 2024This paper introduces a system using generative AI agents to create tip sheets for investigative data reporting. Our system employs three specialized agents--an analyst, a reporter, and an editor--to collaboratively generate and refine tips from datasets. We validate this approach using real-world investigative stories, demonstrating that our agent-based system generally generates more newsworthy and accurate insights compared to a baseline model without agents, although some variability was noted between different stories. Our findings highlight the potential of generative AI to provide leads for investigative data reporting.
Simulating Policy Impacts: Developing a Generative Scenario Writing Method to Evaluate the Perceived Effects of Regulation
May 15, 2024



The rapid advancement of AI technologies yields numerous future impacts on individuals and society. Policy-makers are therefore tasked to react quickly and establish policies that mitigate those impacts. However, anticipating the effectiveness of policies is a difficult task, as some impacts might only be observable in the future and respective policies might not be applicable to the future development of AI. In this work we develop a method for using large language models (LLMs) to evaluate the efficacy of a given piece of policy at mitigating specified negative impacts. We do so by using GPT-4 to generate scenarios both pre- and post-introduction of policy and translating these vivid stories into metrics based on human perceptions of impacts. We leverage an already established taxonomy of impacts of generative AI in the media environment to generate a set of scenario pairs both mitigated and non-mitigated by the transparency legislation of Article 50 of the EU AI Act. We then run a user study (n=234) to evaluate these scenarios across four risk-assessment dimensions: severity, plausibility, magnitude, and specificity to vulnerable populations. We find that this transparency legislation is perceived to be effective at mitigating harms in areas such as labor and well-being, but largely ineffective in areas such as social cohesion and security. Through this case study on generative AI harms we demonstrate the efficacy of our method as a tool to iterate on the effectiveness of policy on mitigating various negative impacts. We expect this method to be useful to researchers or other stakeholders who want to brainstorm the potential utility of different pieces of policy or other mitigation strategies.
Supporting Anticipatory Governance using LLMs: Evaluating and Aligning Large Language Models with the News Media to Anticipate the Negative Impacts of AI
Jan 31, 2024Anticipating the negative impacts of emerging AI technologies is a challenge, especially in the early stages of development. An understudied approach to such anticipation is the use of LLMs to enhance and guide this process. Despite advancements in LLMs and evaluation metrics to account for biases in generated text, it is unclear how well these models perform in anticipatory tasks. Specifically, the use of LLMs to anticipate AI impacts raises questions about the quality and range of categories of negative impacts these models are capable of generating. In this paper we leverage news media, a diverse data source that is rich with normative assessments of emerging technologies, to formulate a taxonomy of impacts to act as a baseline for comparing against. By computationally analyzing thousands of news articles published by hundreds of online news domains around the world, we develop a taxonomy consisting of ten categories of AI impacts. We then evaluate both instruction-based (GPT-4 and Mistral-7B-Instruct) and fine-tuned completion models (Mistral-7B and GPT-3) using a sample from this baseline. We find that the generated impacts using Mistral-7B, fine-tuned on impacts from the news media, tend to be qualitatively on par with impacts generated using a larger scale model such as GPT-4. Moreover, we find that these LLMs generate impacts that largely reflect the taxonomy of negative impacts identified in the news media, however the impacts produced by instruction-based models had gaps in the production of certain categories of impacts in comparison to fine-tuned models. This research highlights a potential bias in state-of-the-art LLMs when used for anticipating impacts and demonstrates the advantages of aligning smaller LLMs with a diverse range of impacts, such as those reflected in the news media, to better reflect such impacts during anticipatory exercises.
Understanding Practices around Computational News Discovery Tools in the Domain of Science Journalism
Nov 28, 2023



Science and technology journalists today face challenges in finding newsworthy leads due to increased workloads, reduced resources, and expanding scientific publishing ecosystems. Given this context, we explore computational methods to aid these journalists' news discovery in terms of time-efficiency and agency. In particular, we prototyped three computational information subsidies into an interactive tool that we used as a probe to better understand how such a tool may offer utility or more broadly shape the practices of professional science journalists. Our findings highlight central considerations around science journalists' agency, context, and responsibilities that such tools can influence and could account for in design. Based on this, we suggest design opportunities for greater and longer-term user agency; incorporating contextual, personal and collaborative notions of newsworthiness; and leveraging flexible interfaces and generative models. Overall, our findings contribute a richer view of the sociotechnical system around computational news discovery tools, and suggest ways to improve such tools to better support the practices of science journalists.
Controversy and Sentiment in Online News
Sep 29, 2014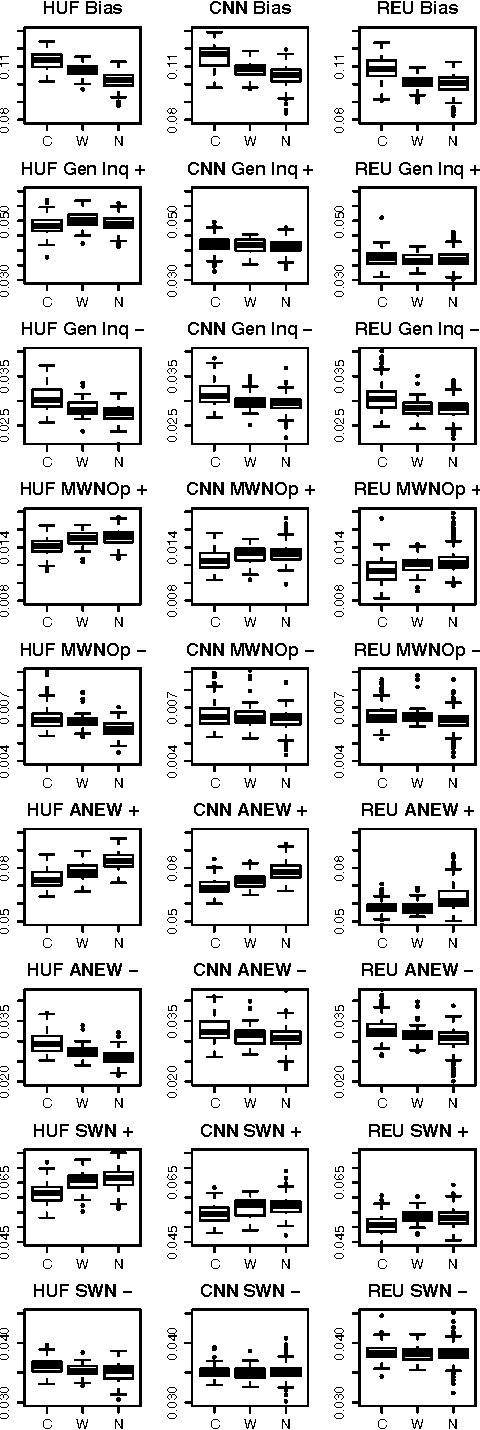


How do news sources tackle controversial issues? In this work, we take a data-driven approach to understand how controversy interplays with emotional expression and biased language in the news. We begin by introducing a new dataset of controversial and non-controversial terms collected using crowdsourcing. Then, focusing on 15 major U.S. news outlets, we compare millions of articles discussing controversial and non-controversial issues over a span of 7 months. We find that in general, when it comes to controversial issues, the use of negative affect and biased language is prevalent, while the use of strong emotion is tempered. We also observe many differences across news sources. Using these findings, we show that we can indicate to what extent an issue is controversial, by comparing it with other issues in terms of how they are portrayed across different media.