 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
VR PreM+ : An Immersive Pre-learning Branching Visualization System for Museum Tours
Nov 01, 2023

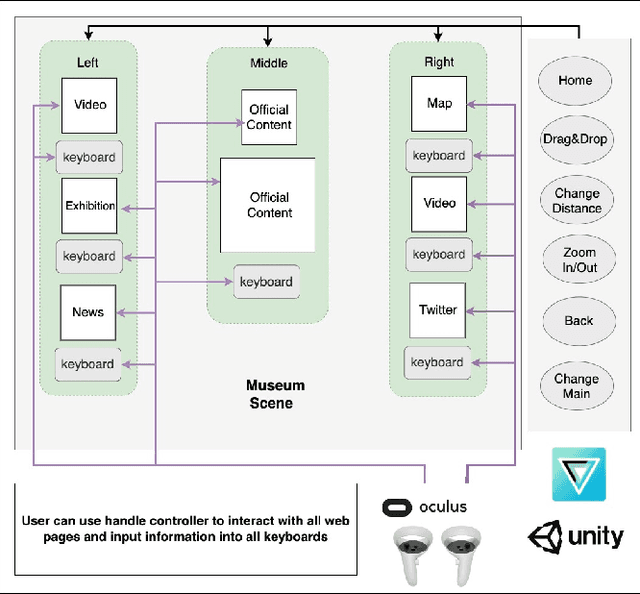

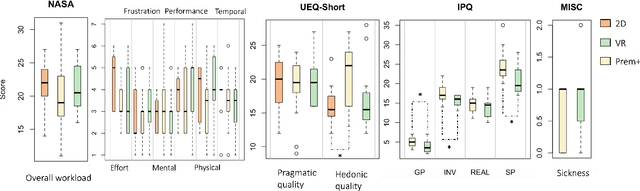
We present VR PreM+, an innovative VR system designed to enhance web exploration beyond traditional computer screens. Unlike static 2D displays, VR PreM+ leverages 3D environments to create an immersive pre-learning experience. Using keyword-based information retrieval allows users to manage and connect various content sources in a dynamic 3D space, improving communication and data comparison. We conducted preliminary and user studies that demonstrated efficient information retrieval, increased user engagement, and a greater sense of presence. These findings yielded three design guidelines for future VR information systems: display, interaction, and user-centric design. VR PreM+ bridges the gap between traditional web browsing and immersive VR, offering an interactive and comprehensive approach to information acquisition. It holds promise for research, education, and beyond.
CoLLM: Integrating Collaborative Embeddings into Large Language Models for Recommendation
Oct 30, 2023Leveraging Large Language Models as Recommenders (LLMRec) has gained significant attention and introduced fresh perspectives in user preference modeling. Existing LLMRec approaches prioritize text semantics, usually neglecting the valuable collaborative information from user-item interactions in recommendations. While these text-emphasizing approaches excel in cold-start scenarios, they may yield sub-optimal performance in warm-start situations. In pursuit of superior recommendations for both cold and warm start scenarios, we introduce CoLLM, an innovative LLMRec methodology that seamlessly incorporates collaborative information into LLMs for recommendation. CoLLM captures collaborative information through an external traditional model and maps it to the input token embedding space of LLM, forming collaborative embeddings for LLM usage. Through this external integration of collaborative information, CoLLM ensures effective modeling of collaborative information without modifying the LLM itself, providing the flexibility to employ various collaborative information modeling techniques. Extensive experiments validate that CoLLM adeptly integrates collaborative information into LLMs, resulting in enhanced recommendation performance. We release the code and data at https://github.com/zyang1580/CoLLM.
Matching aggregate posteriors in the variational autoencoder
Nov 13, 2023The variational autoencoder (VAE) is a well-studied, deep, latent-variable model (DLVM) that efficiently optimizes the variational lower bound of the log marginal data likelihood and has a strong theoretical foundation. However, the VAE's known failure to match the aggregate posterior often results in \emph{pockets/holes} in the latent distribution (i.e., a failure to match the prior) and/or \emph{posterior collapse}, which is associated with a loss of information in the latent space. This paper addresses these shortcomings in VAEs by reformulating the objective function associated with VAEs in order to match the aggregate/marginal posterior distribution to the prior. We use kernel density estimate (KDE) to model the aggregate posterior in high dimensions. The proposed method is named the \emph{aggregate variational autoencoder} (AVAE) and is built on the theoretical framework of the VAE. Empirical evaluation of the proposed method on multiple benchmark data sets demonstrates the effectiveness of the AVAE relative to state-of-the-art (SOTA) methods.
Analyzing and Predicting Low-Listenership Trends in a Large-Scale Mobile Health Program: A Preliminary Investigation
Nov 13, 2023Mobile health programs are becoming an increasingly popular medium for dissemination of health information among beneficiaries in less privileged communities. Kilkari is one of the world's largest mobile health programs which delivers time sensitive audio-messages to pregnant women and new mothers. We have been collaborating with ARMMAN, a non-profit in India which operates the Kilkari program, to identify bottlenecks to improve the efficiency of the program. In particular, we provide an initial analysis of the trajectories of beneficiaries' interaction with the mHealth program and examine elements of the program that can be potentially enhanced to boost its success. We cluster the cohort into different buckets based on listenership so as to analyze listenership patterns for each group that could help boost program success. We also demonstrate preliminary results on using historical data in a time-series prediction to identify beneficiary dropouts and enable NGOs in devising timely interventions to strengthen beneficiary retention.
How are Prompts Different in Terms of Sensitivity?
Nov 13, 2023In-context learning (ICL) has become one of the most popular learning paradigms. While there is a growing body of literature focusing on prompt engineering, there is a lack of systematic analysis comparing the effects of prompts across different models and tasks. To address this gap, we present a comprehensive prompt analysis based on the sensitivity of a function. Our analysis reveals that sensitivity is an unsupervised proxy for model performance, as it exhibits a strong negative correlation with accuracy. We use gradient-based saliency scores to empirically demonstrate how different prompts affect the relevance of input tokens to the output, resulting in different levels of sensitivity. Furthermore, we introduce sensitivity-aware decoding which incorporates sensitivity estimation as a penalty term in the standard greedy decoding. We show that this approach is particularly helpful when information in the input is scarce. Our work provides a fresh perspective on the analysis of prompts, and contributes to a better understanding of the mechanism of ICL.
Distributed pressure matching strategy using diffusion adaptation
Nov 13, 2023Personal sound zone (PSZ) systems, which aim to create listening (bright) and silent (dark) zones in neighboring regions of space, are often based on time-varying acoustics. Conventional adaptive-based methods for handling PSZ tasks suffer from the collection and processing of acoustic transfer functions~(ATFs) between all the matching microphones and all the loudspeakers in a centralized manner, resulting in high calculation complexity and costly accuracy requirements. This paper presents a distributed pressure-matching (PM) method relying on diffusion adaptation (DPM-D) to spread the computational load amongst nodes in order to overcome these issues. The global PM problem is defined as a sum of local costs, and the diffusion adaption approach is then used to create a distributed solution that just needs local information exchanges. Simulations over multi-frequency bins and a computational complexity analysis are conducted to evaluate the properties of the algorithm and to compare it with centralized counterparts.
Temporal Performance Prediction for Deep Convolutional Long Short-Term Memory Networks
Nov 13, 2023Quantifying predictive uncertainty of deep semantic segmentation networks is essential in safety-critical tasks. In applications like autonomous driving, where video data is available, convolutional long short-term memory networks are capable of not only providing semantic segmentations but also predicting the segmentations of the next timesteps. These models use cell states to broadcast information from previous data by taking a time series of inputs to predict one or even further steps into the future. We present a temporal postprocessing method which estimates the prediction performance of convolutional long short-term memory networks by either predicting the intersection over union of predicted and ground truth segments or classifying between intersection over union being equal to zero or greater than zero. To this end, we create temporal cell state-based input metrics per segment and investigate different models for the estimation of the predictive quality based on these metrics. We further study the influence of the number of considered cell states for the proposed metrics.
Registered and Segmented Deformable Object Reconstruction from a Single View Point Cloud
Nov 13, 2023In deformable object manipulation, we often want to interact with specific segments of an object that are only defined in non-deformed models of the object. We thus require a system that can recognize and locate these segments in sensor data of deformed real world objects. This is normally done using deformable object registration, which is problem specific and complex to tune. Recent methods utilize neural occupancy functions to improve deformable object registration by registering to an object reconstruction. Going one step further, we propose a system that in addition to reconstruction learns segmentation of the reconstructed object. As the resulting output already contains the information about the segments, we can skip the registration process. Tested on a variety of deformable objects in simulation and the real world, we demonstrate that our method learns to robustly find these segments. We also introduce a simple sampling algorithm to generate better training data for occupancy learning.
Dynamically Weighted Factor-Graph for Feature-based Geo-localization
Nov 13, 2023Feature-based geo-localization relies on associating features extracted from aerial imagery with those detected by the vehicle's sensors. This requires that the type of landmarks must be observable from both sources. This no-variety of feature types generates poor representations that lead to outliers and deviations, produced by ambiguities and lack of detections respectively. To mitigate these drawbacks, in this paper, we present a dynamically weighted factor graph model for the vehicle's trajectory estimation. The weight adjustment in this implementation depends on information quantification in the detections performed using a LiDAR sensor. Also, a prior (GNSS-based) error estimation is included in the model. Then, when the representation becomes ambiguous or sparse, the weights are dynamically adjusted to rely on the corrected prior trajectory, mitigating in this way outliers and deviations. We compare our method against state-of-the-art geo-localization ones in a challenging ambiguous environment, where we also cause detection losses. We demonstrate mitigation of the mentioned drawbacks where the other methods fail.
Forest aboveground biomass estimation using GEDI and earth observation data through attention-based deep learning
Nov 06, 2023Accurate quantification of forest aboveground biomass (AGB) is critical for understanding carbon accounting in the context of climate change. In this study, we presented a novel attention-based deep learning approach for forest AGB estimation, primarily utilizing openly accessible EO data, including: GEDI LiDAR data, C-band Sentinel-1 SAR data, ALOS-2 PALSAR-2 data, and Sentinel-2 multispectral data. The attention UNet (AU) model achieved markedly higher accuracy for biomass estimation compared to the conventional RF algorithm. Specifically, the AU model attained an R2 of 0.66, RMSE of 43.66 Mg ha-1, and bias of 0.14 Mg ha-1, while RF resulted in lower scores of R2 0.62, RMSE 45.87 Mg ha-1, and bias 1.09 Mg ha-1. However, the superiority of the deep learning approach was not uniformly observed across all tested models. ResNet101 only achieved an R2 of 0.50, an RMSE of 52.93 Mg ha-1, and a bias of 0.99 Mg ha-1, while the UNet reported an R2 of 0.65, an RMSE of 44.28 Mg ha-1, and a substantial bias of 1.84 Mg ha-1. Moreover, to explore the performance of AU in the absence of spatial information, fully connected (FC) layers were employed to eliminate spatial information from the remote sensing data. AU-FC achieved intermediate R2 of 0.64, RMSE of 44.92 Mgha-1, and bias of -0.56 Mg ha-1, outperforming RF but underperforming AU model using spatial information. We also generated 10m forest AGB maps across Guangdong for the year 2019 using AU and compared it with that produced by RF. The AGB distributions from both models showed strong agreement with similar mean values; the mean forest AGB estimated by AU was 102.18 Mg ha-1 while that of RF was 104.84 Mg ha-1. Additionally, it was observed that the AGB map generated by AU provided superior spatial information. Overall, this research substantiates the feasibility of employing deep learning for biomass estimation based on satellite data.