 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Privacy-Preserving Constrained Domain Generalization for Medical Image Classification
May 14, 2021
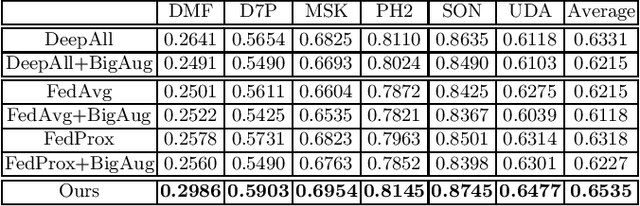
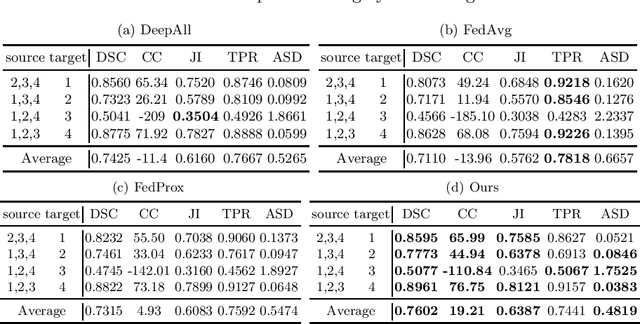
Deep neural networks (DNN) have demonstrated unprecedented success for medical imaging applications. However, due to the issue of limited dataset availability and the strict legal and ethical requirements for patient privacy protection, the broad applications of medical imaging classification driven by DNN with large-scale training data have been largely hindered. For example, when training the DNN from one domain (e.g., with data only from one hospital), the generalization capability to another domain (e.g., data from another hospital) could be largely lacking. In this paper, we aim to tackle this problem by developing the privacy-preserving constrained domain generalization method, aiming to improve the generalization capability under the privacy-preserving condition. In particular, We propose to improve the information aggregation process on the centralized server-side with a novel gradient alignment loss, expecting that the trained model can be better generalized to the "unseen" but related medical images. The rationale and effectiveness of our proposed method can be explained by connecting our proposed method with the Maximum Mean Discrepancy (MMD) which has been widely adopted as the distribution distance measurement. Experimental results on two challenging medical imaging classification tasks indicate that our method can achieve better cross-domain generalization capability compared to the state-of-the-art federated learning methods.
Dealing with CSI Compression to Reduce Losses and Overhead: An Artificial Intelligence Approach
Apr 01, 2021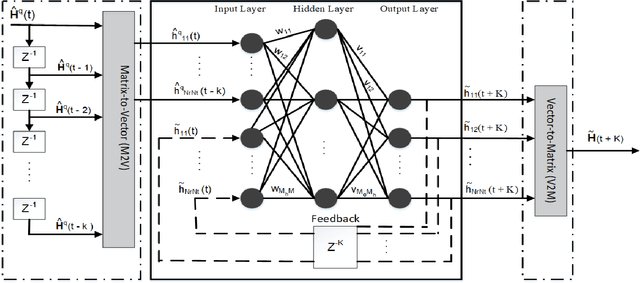
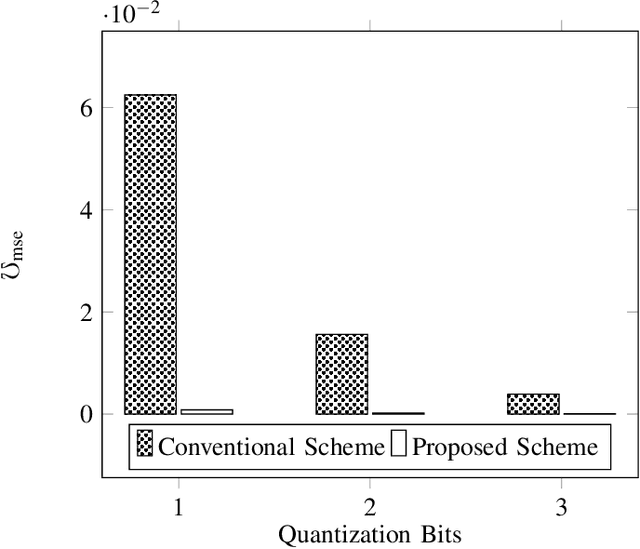
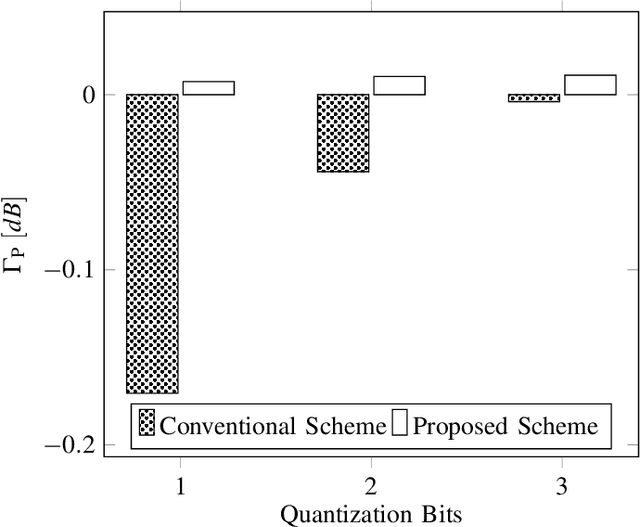
Motivated by the issue of inaccurate channel state information (CSI) at the base station (BS), which is commonly due to feedback/processing delays and compression problems, in this paper, we introduce a scalable idea of adopting artificial intelligence (AI) aided CSI acquisition. The proposed scheme enhances the CSI compression, which is done at the mobile terminal (MT), along with accurate recovery of estimated CSI at the BS. Simulation-based results corroborate the validity of the proposed scheme. Numerically, nearly 100\% recovery of the estimated CSI is observed with relatively lower overhead than the benchmark scheme. The proposed idea can bring potential benefits in the wireless communication environment, e.g., ultra-reliable and low latency communication (URLLC), where imperfect CSI and overhead is intolerable.
VGNMN: Video-grounded Neural Module Network to Video-Grounded Language Tasks
Apr 16, 2021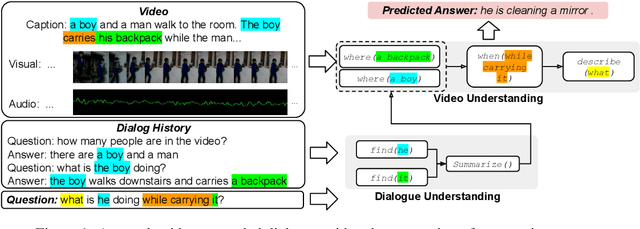

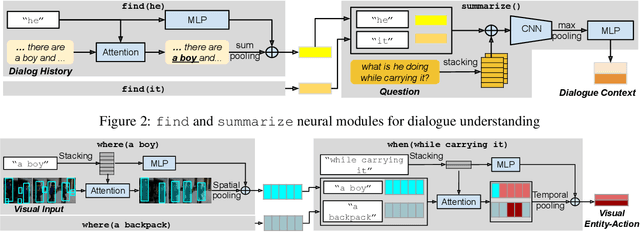
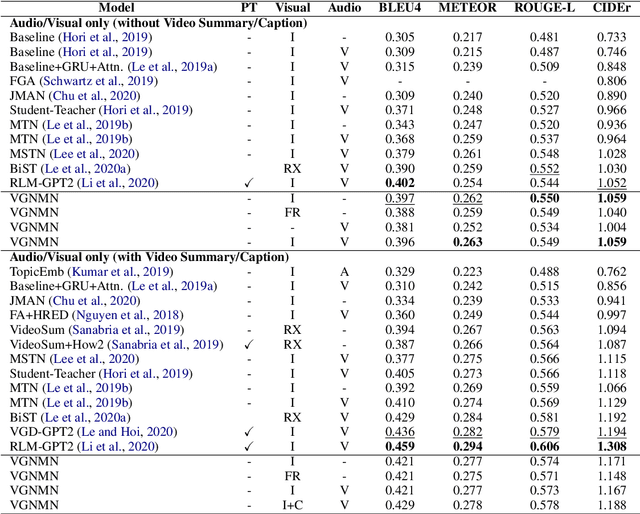
Neural module networks (NMN) have achieved success in image-grounded tasks such as Visual Question Answering (VQA) on synthetic images. However, very limited work on NMN has been studied in the video-grounded language tasks. These tasks extend the complexity of traditional visual tasks with the additional visual temporal variance. Motivated by recent NMN approaches on image-grounded tasks, we introduce Video-grounded Neural Module Network (VGNMN) to model the information retrieval process in video-grounded language tasks as a pipeline of neural modules. VGNMN first decomposes all language components to explicitly resolve any entity references and detect corresponding action-based inputs from the question. The detected entities and actions are used as parameters to instantiate neural module networks and extract visual cues from the video. Our experiments show that VGNMN can achieve promising performance on two video-grounded language tasks: video QA and video-grounded dialogues.
Collaborative Spatial-Temporal Modeling for Language-Queried Video Actor Segmentation
May 14, 2021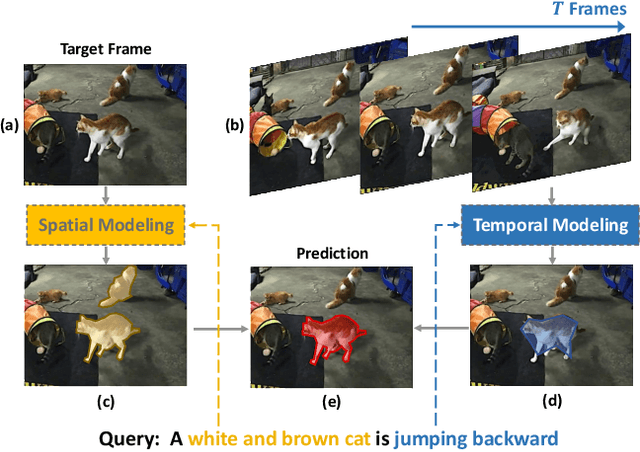
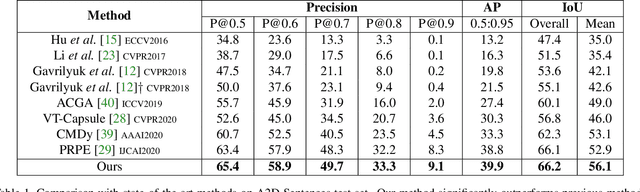
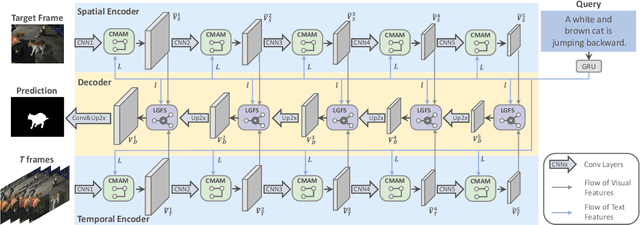
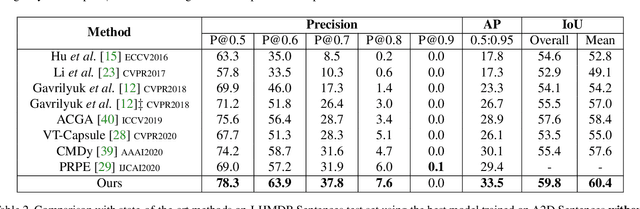
Language-queried video actor segmentation aims to predict the pixel-level mask of the actor which performs the actions described by a natural language query in the target frames. Existing methods adopt 3D CNNs over the video clip as a general encoder to extract a mixed spatio-temporal feature for the target frame. Though 3D convolutions are amenable to recognizing which actor is performing the queried actions, it also inevitably introduces misaligned spatial information from adjacent frames, which confuses features of the target frame and yields inaccurate segmentation. Therefore, we propose a collaborative spatial-temporal encoder-decoder framework which contains a 3D temporal encoder over the video clip to recognize the queried actions, and a 2D spatial encoder over the target frame to accurately segment the queried actors. In the decoder, a Language-Guided Feature Selection (LGFS) module is proposed to flexibly integrate spatial and temporal features from the two encoders. We also propose a Cross-Modal Adaptive Modulation (CMAM) module to dynamically recombine spatial- and temporal-relevant linguistic features for multimodal feature interaction in each stage of the two encoders. Our method achieves new state-of-the-art performance on two popular benchmarks with less computational overhead than previous approaches.
Towards Prior-Free Approximately Truthful One-Shot Auction Learning via Differential Privacy
Mar 31, 2021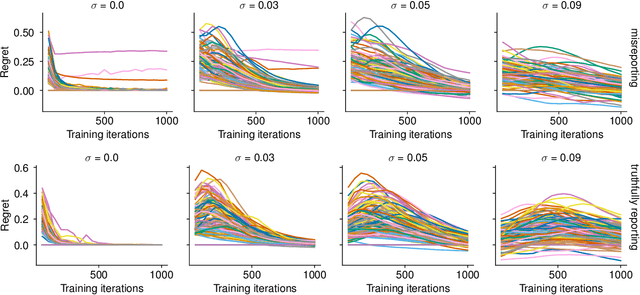
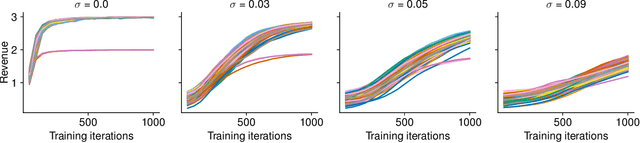

Designing truthful, revenue maximizing auctions is a core problem of auction design. Multi-item settings have long been elusive. Recent work (arXiv:1706.03459) introduces effective deep learning techniques to find such auctions for the prior-dependent setting, in which distributions about bidder preferences are known. One remaining problem is to obtain priors in a way that excludes the possibility of manipulating the resulting auctions. Using techniques from differential privacy for the construction of approximately truthful mechanisms, we modify the RegretNet approach to be applicable to the prior-free setting. In this more general setting, no distributional information is assumed, but we trade this property for worse performance. We present preliminary empirical results and qualitative analysis for this work in progress.
Toward Interactive Modulation for Photo-Realistic Image Restoration
May 07, 2021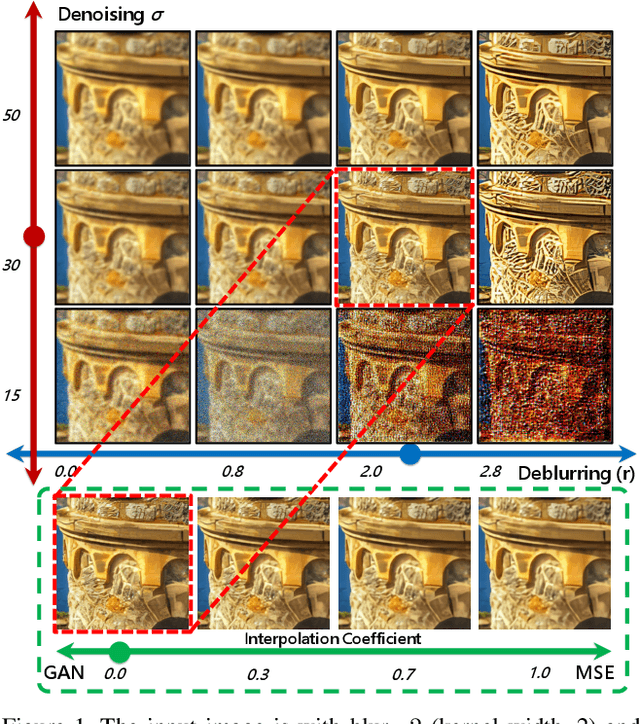
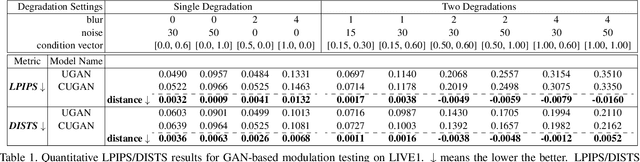

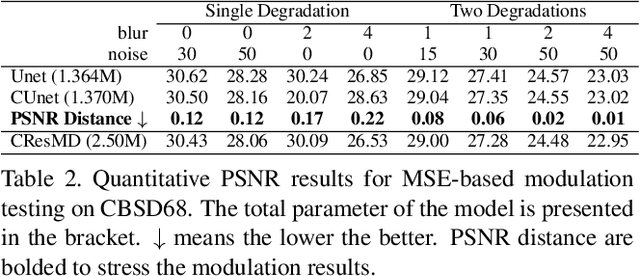
Modulating image restoration level aims to generate a restored image by altering a factor that represents the restoration strength. Previous works mainly focused on optimizing the mean squared reconstruction error, which brings high reconstruction accuracy but lacks finer texture details. This paper presents a Controllable Unet Generative Adversarial Network (CUGAN) to generate high-frequency textures in the modulation tasks. CUGAN consists of two modules -- base networks and condition networks. The base networks comprise a generator and a discriminator. In the generator, we realize the interactive control of restoration levels by tuning the weights of different features from different scales in the Unet architecture. Moreover, we adaptively modulate the intermediate features in the discriminator according to the severity of degradations. The condition networks accept the condition vector (encoded degradation information) as input, then generate modulation parameters for both the generator and the discriminator. During testing, users can control the output effects by tweaking the condition vector. We also provide a smooth transition between GAN and MSE effects by a simple transition method. Extensive experiments demonstrate that the proposed CUGAN achieves excellent performance on image restoration modulation tasks.
$FM^2$: Field-matrixed Factorization Machines for Recommender Systems
Feb 20, 2021Click-through rate (CTR) prediction plays a critical role in recommender systems and online advertising. The data used in these applications are multi-field categorical data, where each feature belongs to one field. Field information is proved to be important and there are several works considering fields in their models. In this paper, we proposed a novel approach to model the field information effectively and efficiently. The proposed approach is a direct improvement of FwFM, and is named as Field-matrixed Factorization Machines (FmFM, or $FM^2$). We also proposed a new explanation of FM and FwFM within the FmFM framework, and compared it with the FFM. Besides pruning the cross terms, our model supports field-specific variable dimensions of embedding vectors, which acts as soft pruning. We also proposed an efficient way to minimize the dimension while keeping the model performance. The FmFM model can also be optimized further by caching the intermediate vectors, and it only takes thousands of floating-point operations (FLOPs) to make a prediction. Our experiment results show that it can out-perform the FFM, which is more complex. The FmFM model's performance is also comparable to DNN models which require much more FLOPs in runtime.
Fast deep learning correspondence for neuron tracking and identification in C.elegans using synthetic training
Jan 20, 2021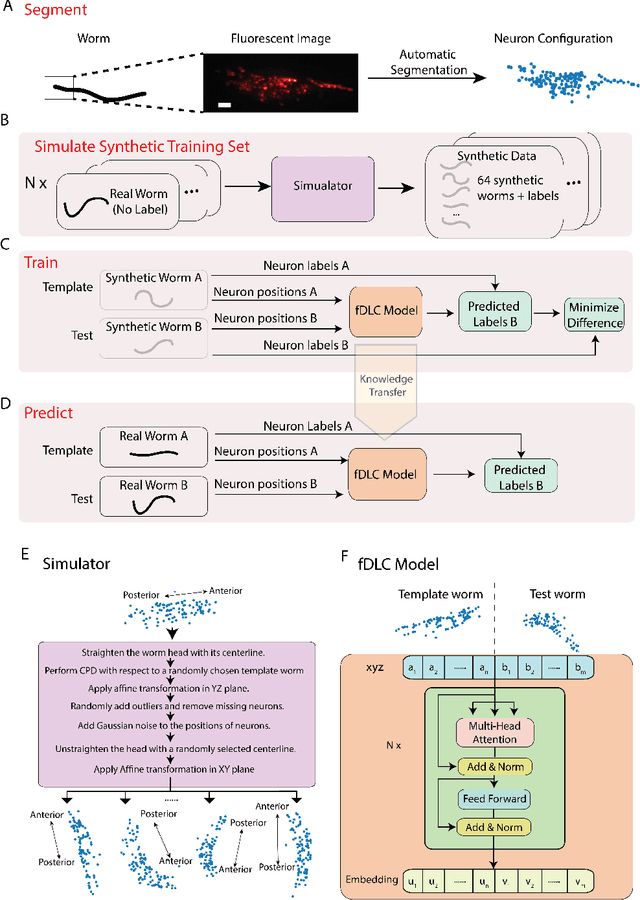
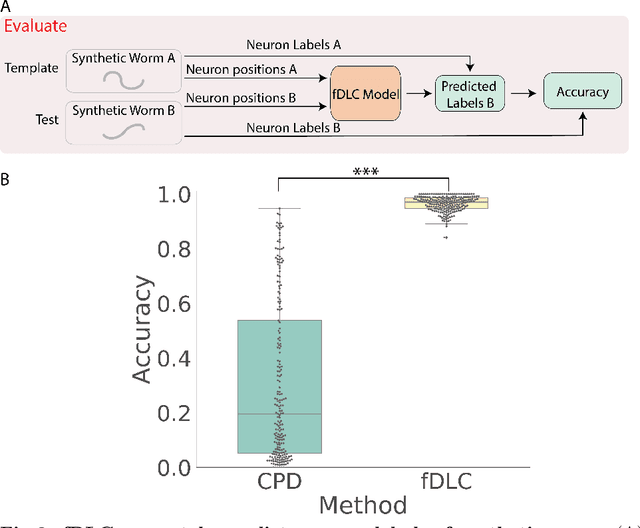
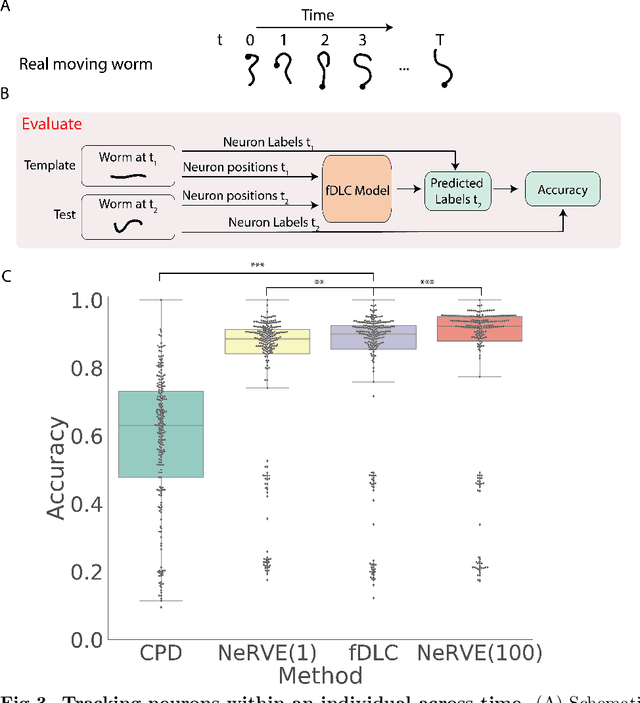
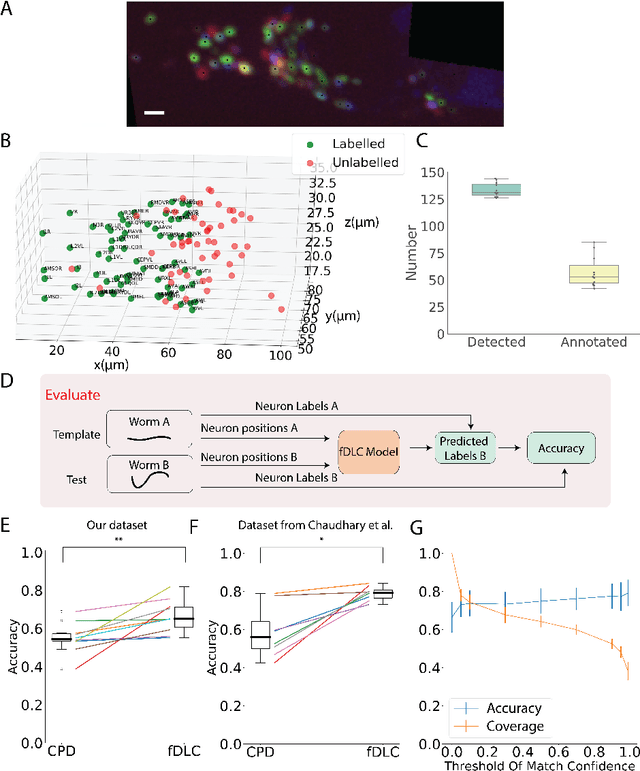
We present an automated method to track and identify neurons in C. elegans, called "fast Deep Learning Correspondence" or fDLC, based on the transformer network architecture. The model is trained once on empirically derived synthetic data and then predicts neural correspondence across held-out real animals via transfer learning. The same pre-trained model both tracks neurons across time and identifies corresponding neurons across individuals. Performance is evaluated against hand-annotated datasets, including NeuroPAL [1]. Using only position information, the method achieves 80.0% accuracy at tracking neurons within an individual and 65.8% accuracy at identifying neurons across individuals. Accuracy is even higher on a published dataset [2]. Accuracy reaches 76.5% when using color information from NeuroPAL. Unlike previous methods, fDLC does not require straightening or transforming the animal into a canonical coordinate system. The method is fast and predicts correspondence in 10 ms making it suitable for future real-time applications.
How consistent is my model with the data? Information-Theoretic Model Check
Dec 19, 2017
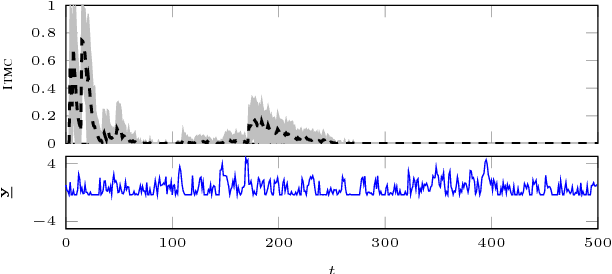
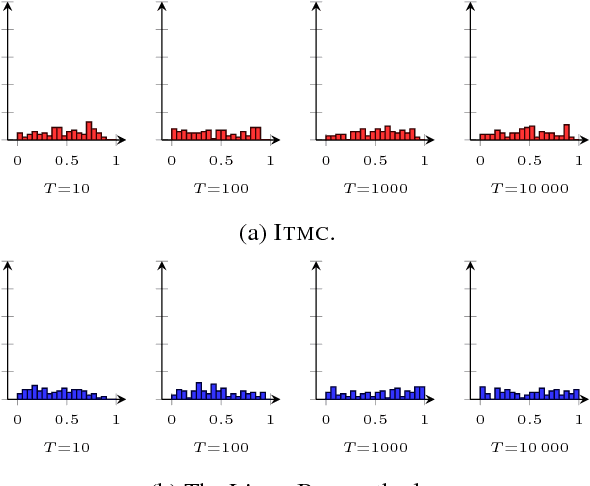
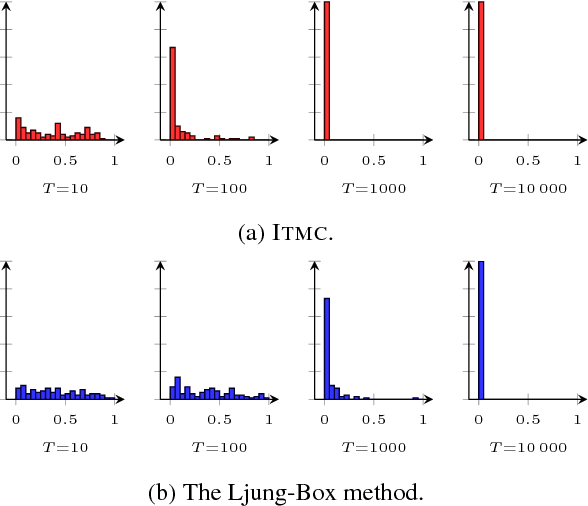
The choice of model class is fundamental in statistical learning and system identification, no matter whether the class is derived from physical principles or is a generic black-box. We develop a method to evaluate the specified model class by assessing its capability of reproducing data that is similar to the observed data record. This model check is based on the information-theoretic properties of models viewed as data generators and is applicable to e.g. sequential data and nonlinear dynamical models. The method can be understood as a specific two-sided posterior predictive test. We apply the information-theoretic model check to both synthetic and real data and compare it with a classical whiteness test.
DaLAJ - a dataset for linguistic acceptability judgments for Swedish: Format, baseline, sharing
May 14, 2021

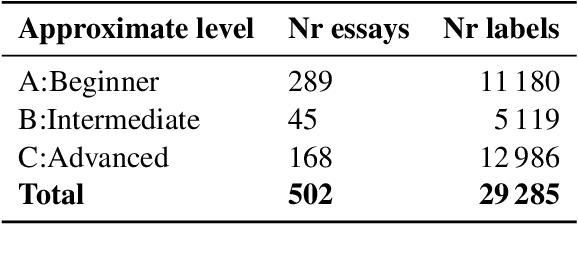
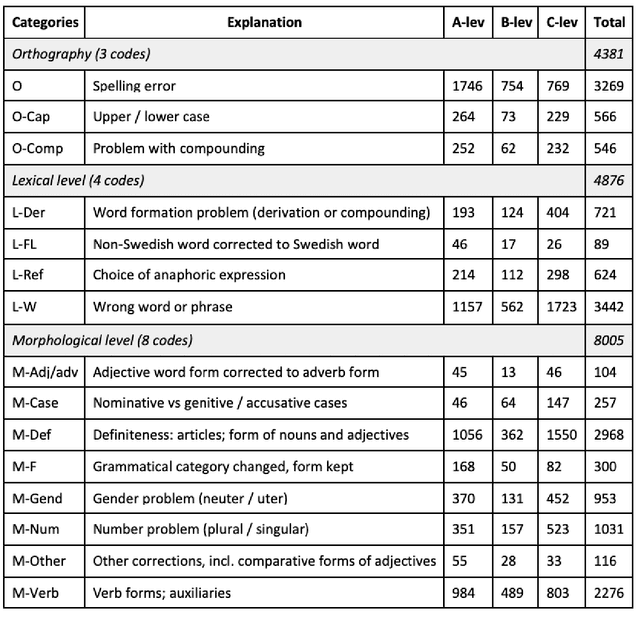
We present DaLAJ 1.0, a Dataset for Linguistic Acceptability Judgments for Swedish, comprising 9 596 sentences in its first version; and the initial experiment using it for the binary classification task. DaLAJ is based on the SweLL second language learner data, consisting of essays at different levels of proficiency. To make sure the dataset can be freely available despite the GDPR regulations, we have sentence-scrambled learner essays and removed part of the metadata about learners, keeping for each sentence only information about the mother tongue and the level of the course where the essay has been written. We use the normalized version of learner language as the basis for the DaLAJ sentences, and keep only one error per sentence. We repeat the same sentence for each individual correction tag used in the sentence. For DaLAJ 1.0 we have used four error categories (out of 35 available in SweLL), all connected to lexical or word-building choices. Our baseline results for the binary classification show an accuracy of 58% for DaLAJ 1.0 using BERT embeddings. The dataset is included in the SwedishGlue (Swe. SuperLim) benchmark. Below, we describe the format of the dataset, first experiments, our insights and the motivation for the chosen approach to data sharing.