 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
iLQR for Piecewise-Smooth Hybrid Dynamical Systems
Mar 26, 2021
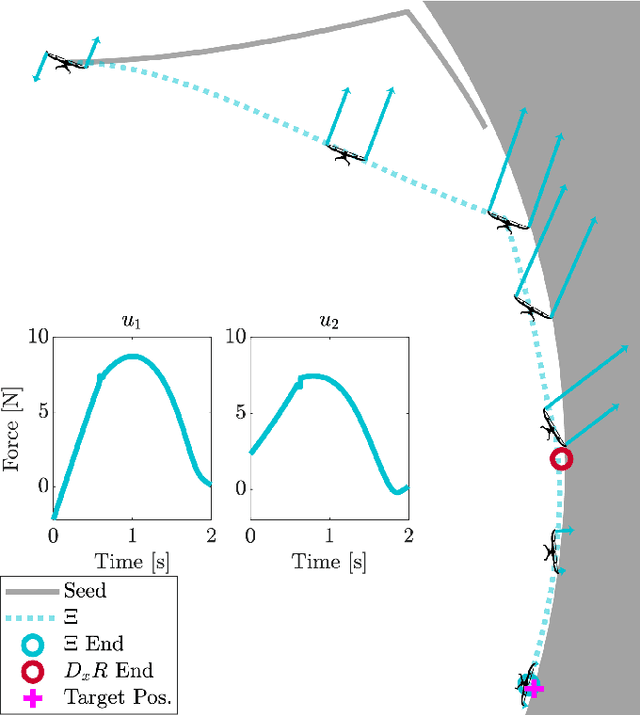
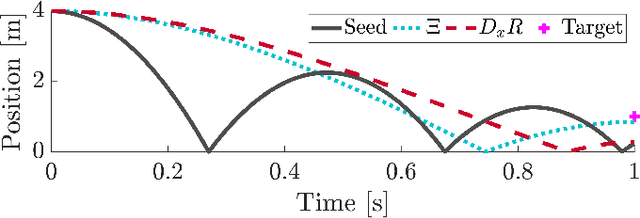
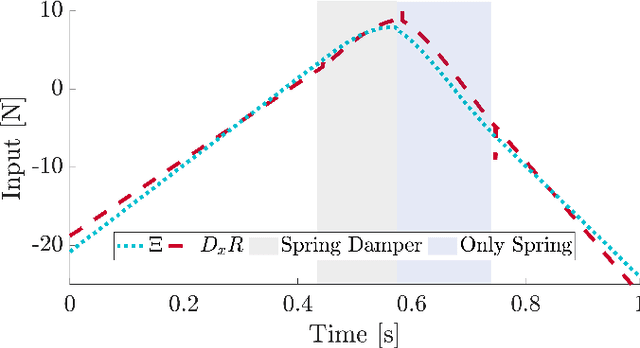
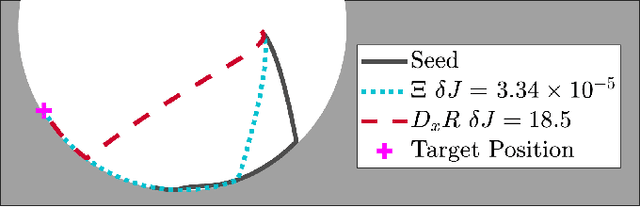
Trajectory optimization is a popular strategy for planning trajectories for robotic systems. However, many robotic tasks require changing contact conditions, which is difficult due to the hybrid nature of the dynamics. The optimal sequence and timing of these modes are typically not known ahead of time. In this work, we extend the Iterative Linear Quadratic Regulator (iLQR) method to a class of piecewise smooth hybrid dynamical systems by allowing for changing hybrid modes in the forward pass, using the saltation matrix to update the gradient information in the backwards pass, and using a reference extension to account for mode mismatch. We demonstrate these changes on a variety of hybrid systems and compare the different strategies for computing the gradients.
A Formal Framework for Reasoning about Agents' Independence in Self-organizing Multi-agent Systems
May 21, 2021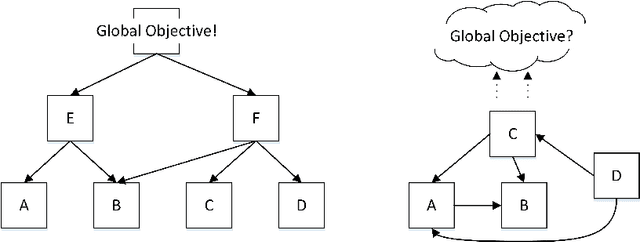
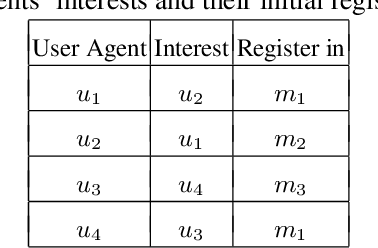
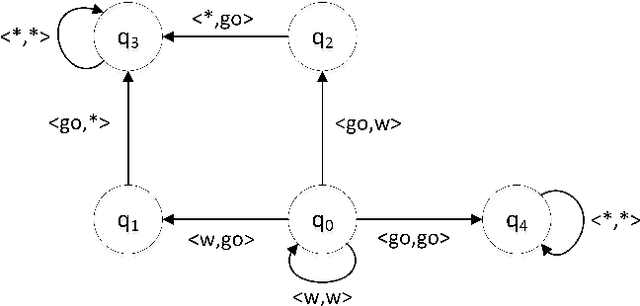
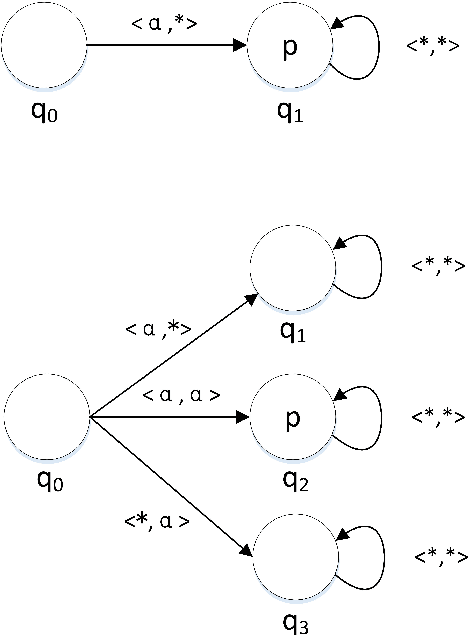
Self-organization is a process where a stable pattern is formed by the cooperative behavior between parts of an initially disordered system without external control or influence. It has been introduced to multi-agent systems as an internal control process or mechanism to solve difficult problems spontaneously. However, because a self-organizing multi-agent system has autonomous agents and local interactions between them, it is difficult to predict the behavior of the system from the behavior of the local agents we design. This paper proposes a logic-based framework of self-organizing multi-agent systems, where agents interact with each other by following their prescribed local rules. The dependence relation between coalitions of agents regarding their contributions to the global behavior of the system is reasoned about from the structural and semantic perspectives. We show that the computational complexity of verifying such a self-organizing multi-agent system remains close to the domain of standard ATL. We then combine our framework with graph theory to decompose a system into different coalitions located in different layers, which allows us to verify agents' full contributions more efficiently. The resulting information about agents' full contributions allows us to understand the complex link between local agent behavior and system level behavior in a self-organizing multi-agent system. Finally, we show how we can use our framework to model a constraint satisfaction problem.
Context-Based Soft Actor Critic for Environments with Non-stationary Dynamics
May 07, 2021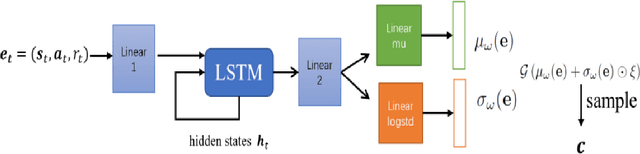
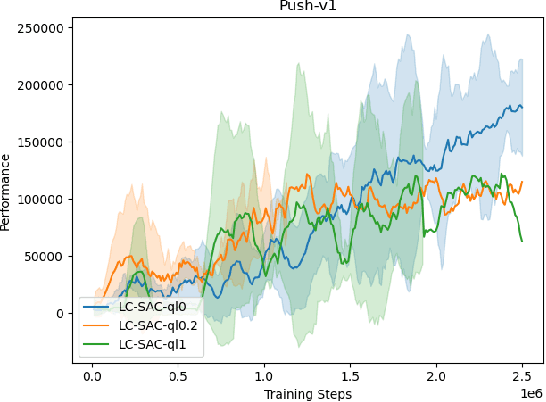
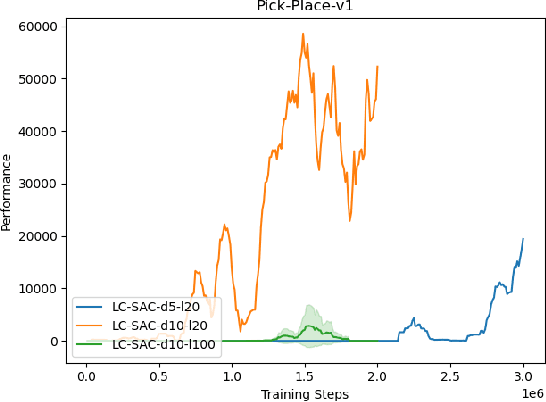
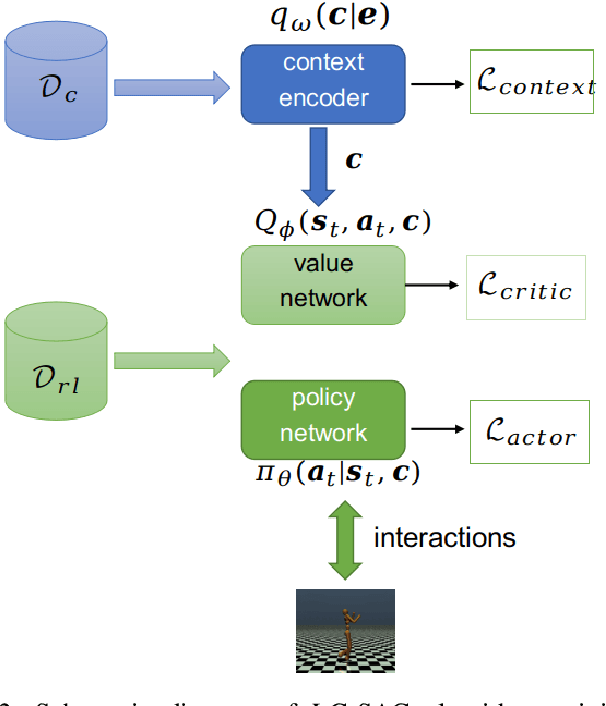
The performance of deep reinforcement learning methods prone to degenerate when applied to environments with non-stationary dynamics. In this paper, we utilize the latent context recurrent encoders motivated by recent Meta-RL materials, and propose the Latent Context-based Soft Actor Critic (LC-SAC) method to address aforementioned issues. By minimizing the contrastive prediction loss function, the learned context variables capture the information of the environment dynamics and the recent behavior of the agent. Then combined with the soft policy iteration paradigm, the LC-SAC method alternates between soft policy evaluation and soft policy improvement until it converges to the optimal policy. Experimental results show that the performance of LC-SAC is significantly better than the SAC algorithm on the MetaWorld ML1 tasks whose dynamics changes drasticly among different episodes, and is comparable to SAC on the continuous control benchmark task MuJoCo whose dynamics changes slowly or doesn't change between different episodes. In addition, we also conduct relevant experiments to determine the impact of different hyperparameter settings on the performance of the Lc-SAC algorithm and give the reasonable suggestions of hyperparameter setting.
A Non-Intrusive Machine Learning Solution for Malware Detection and Data Theft Classification in Smartphones
Feb 12, 2021
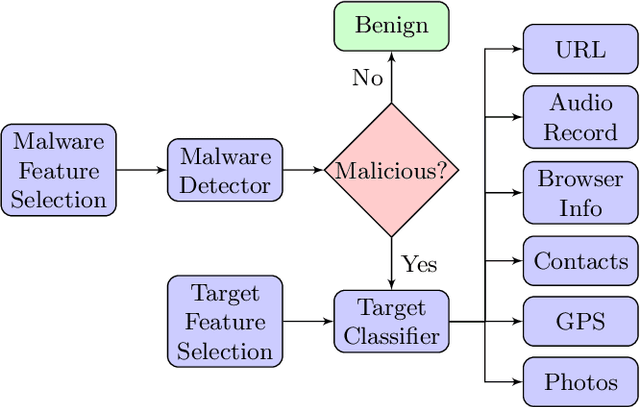
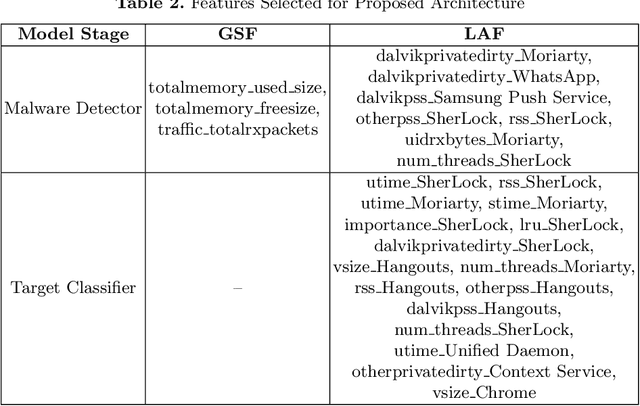
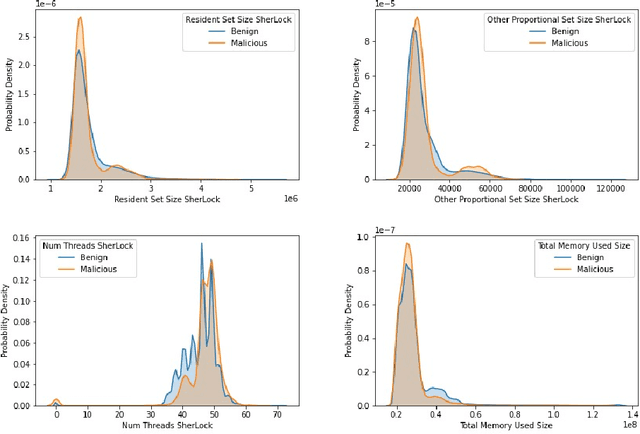
Smartphones contain information that is more sensitive and personal than those found on computers and laptops. With an increase in the versatility of smartphone functionality, more data has become vulnerable and exposed to attackers. Successful mobile malware attacks could steal a user's location, photos, or even banking information. Due to a lack of post-attack strategies firms also risk going out of business due to data theft. Thus, there is a need besides just detecting malware intrusion in smartphones but to also identify the data that has been stolen to assess, aid in recovery and prevent future attacks. In this paper, we propose an accessible, non-intrusive machine learning solution to not only detect malware intrusion but also identify the type of data stolen for any app under supervision. We do this with Android usage data obtained by utilising publicly available data collection framework- SherLock. We test the performance of our architecture for multiple users on real-world data collected using the same framework. Our architecture exhibits less than 9% inaccuracy in detecting malware and can classify with 83% certainty on the type of data that is being stolen.
Self-Supervised Steering Angle Prediction for Vehicle Control Using Visual Odometry
Mar 20, 2021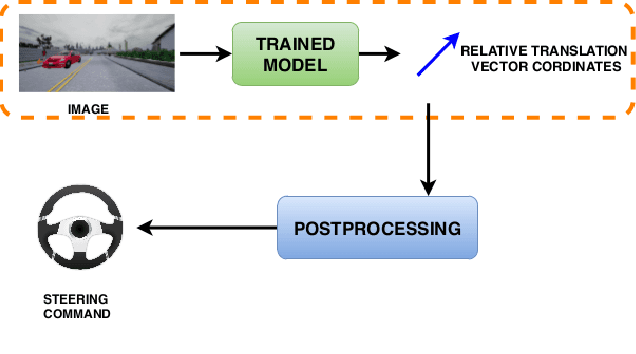
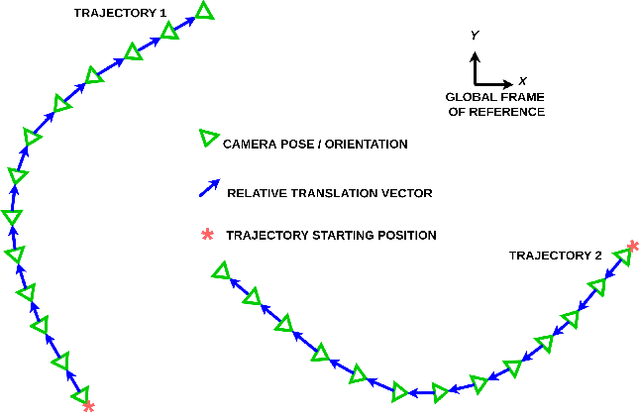
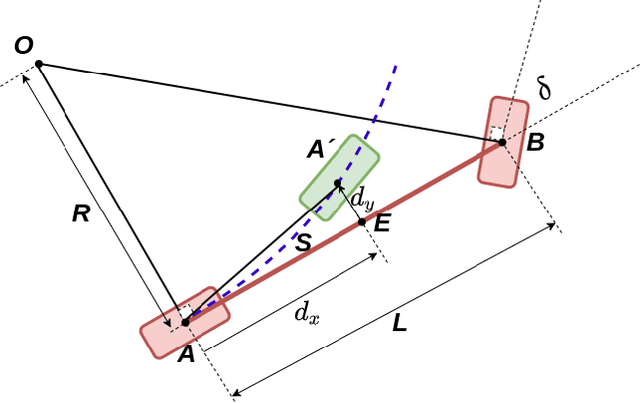
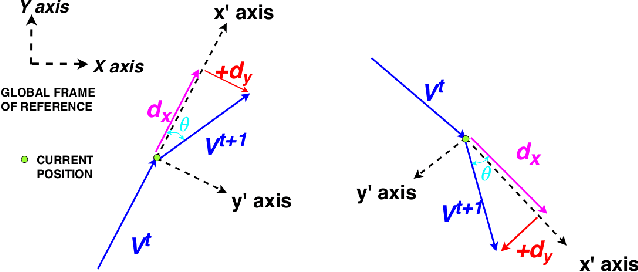
Vision-based learning methods for self-driving cars have primarily used supervised approaches that require a large number of labels for training. However, those labels are usually difficult and expensive to obtain. In this paper, we demonstrate how a model can be trained to control a vehicle's trajectory using camera poses estimated through visual odometry methods in an entirely self-supervised fashion. We propose a scalable framework that leverages trajectory information from several different runs using a camera setup placed at the front of a car. Experimental results on the CARLA simulator demonstrate that our proposed approach performs at par with the model trained with supervision.
RadarScenes: A Real-World Radar Point Cloud Data Set for Automotive Applications
Apr 06, 2021
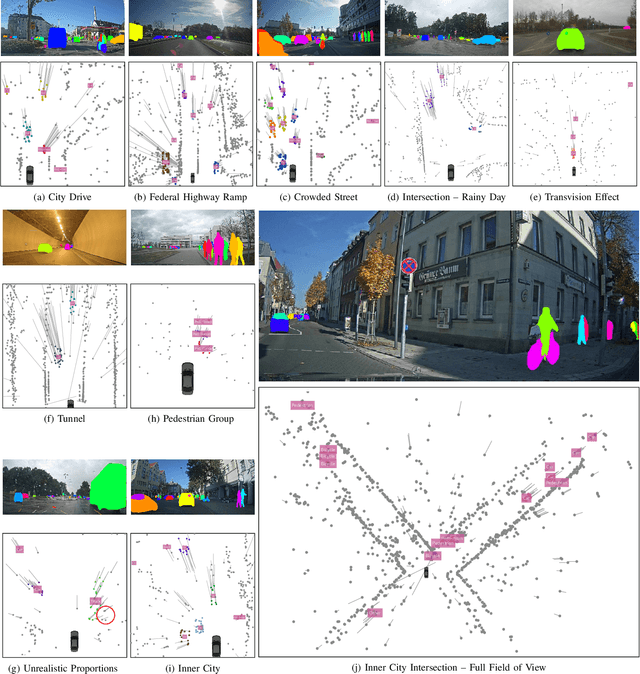
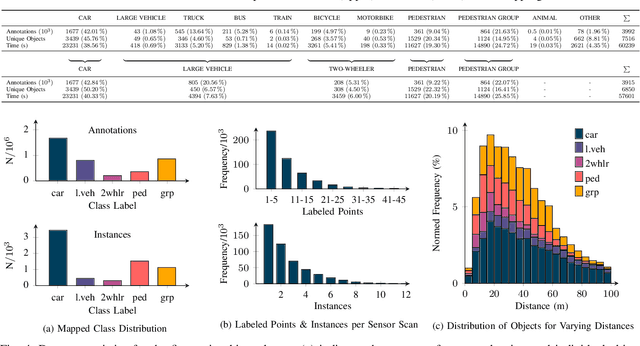
A new automotive radar data set with measurements and point-wise annotations from more than four hours of driving is presented. Data provided by four series radar sensors mounted on one test vehicle were recorded and the individual detections of dynamic objects were manually grouped to clusters and labeled afterwards. The purpose of this data set is to enable the development of novel (machine learning-based) radar perception algorithms with the focus on moving road users. Images of the recorded sequences were captured using a documentary camera. For the evaluation of future object detection and classification algorithms, proposals for score calculation are made so that researchers can evaluate their algorithms on a common basis. Additional information as well as download instructions can be found on the website of the data set: www.radar-scenes.com.
Back to the Basics: A Quantitative Analysis of Statistical and Graph-Based Term Weighting Schemes for Keyword Extraction
Apr 16, 2021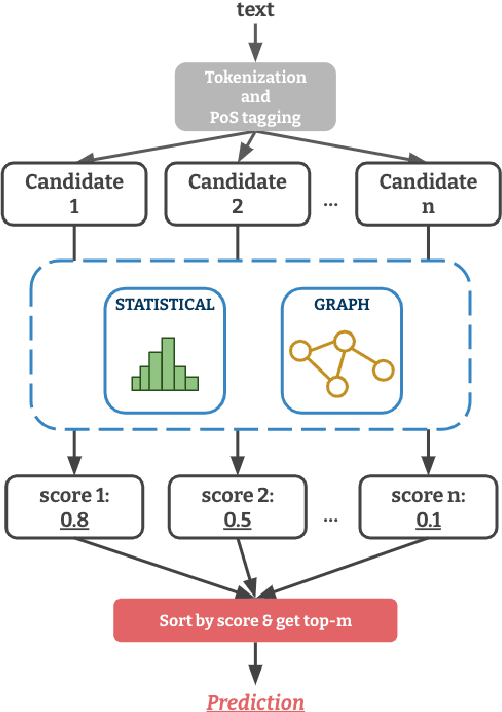
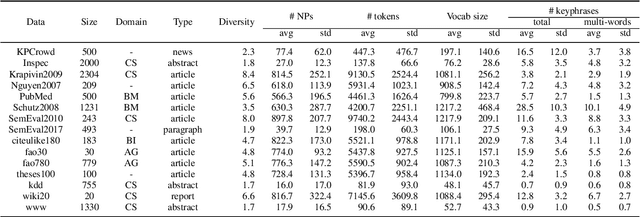
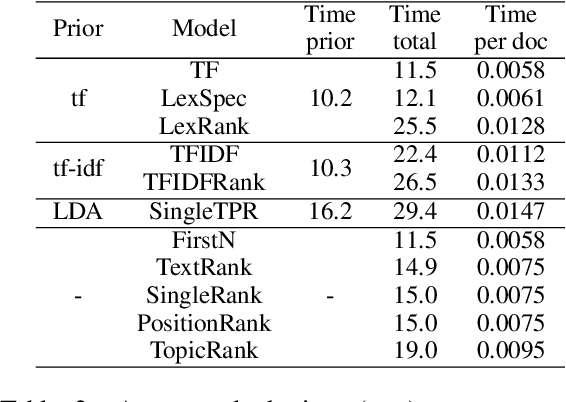
Term weighting schemes are widely used in Natural Language Processing and Information Retrieval. In particular, term weighting is the basis for keyword extraction. However, there are relatively few evaluation studies that shed light about the strengths and shortcomings of each weighting scheme. In fact, in most cases researchers and practitioners resort to the well-known tf-idf as default, despite the existence of other suitable alternatives, including graph-based models. In this paper, we perform an exhaustive and large-scale empirical comparison of both statistical and graph-based term weighting methods in the context of keyword extraction. Our analysis reveals some interesting findings such as the advantages of the less-known lexical specificity with respect to tf-idf, or the qualitative differences between statistical and graph-based methods. Finally, based on our findings we discuss and devise some suggestions for practitioners. We release our code at https://github.com/asahi417/kex .
Graph Entropy Guided Node Embedding Dimension Selection for Graph Neural Networks
May 07, 2021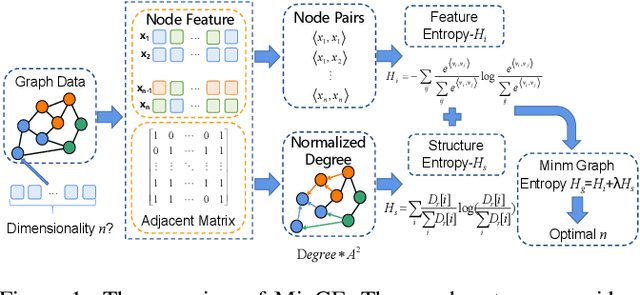
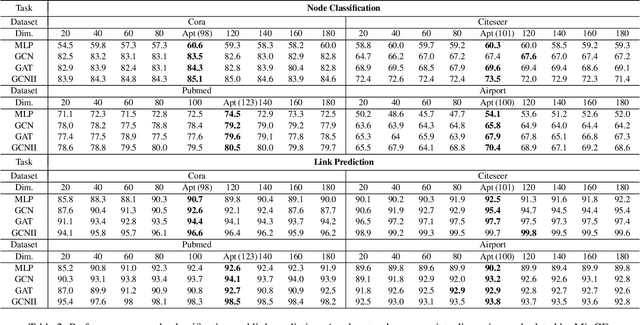
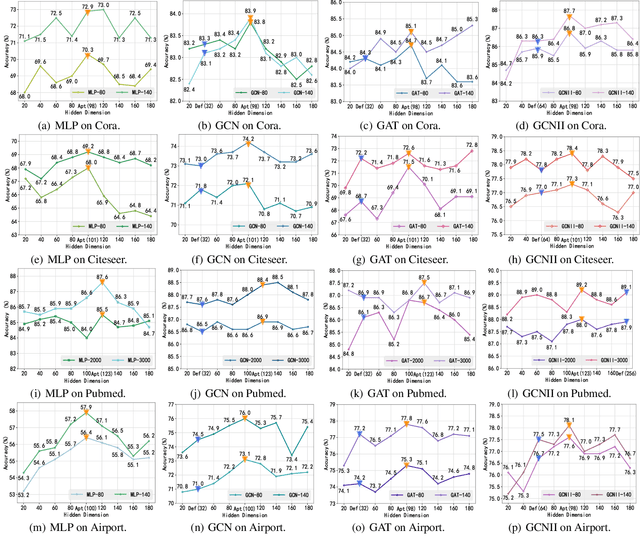
Graph representation learning has achieved great success in many areas, including e-commerce, chemistry, biology, etc. However, the fundamental problem of choosing the appropriate dimension of node embedding for a given graph still remains unsolved. The commonly used strategies for Node Embedding Dimension Selection (NEDS) based on grid search or empirical knowledge suffer from heavy computation and poor model performance. In this paper, we revisit NEDS from the perspective of minimum entropy principle. Subsequently, we propose a novel Minimum Graph Entropy (MinGE) algorithm for NEDS with graph data. To be specific, MinGE considers both feature entropy and structure entropy on graphs, which are carefully designed according to the characteristics of the rich information in them. The feature entropy, which assumes the embeddings of adjacent nodes to be more similar, connects node features and link topology on graphs. The structure entropy takes the normalized degree as basic unit to further measure the higher-order structure of graphs. Based on them, we design MinGE to directly calculate the ideal node embedding dimension for any graph. Finally, comprehensive experiments with popular Graph Neural Networks (GNNs) on benchmark datasets demonstrate the effectiveness and generalizability of our proposed MinGE.
Endmember-Guided Unmixing Network (EGU-Net): A General Deep Learning Framework for Self-Supervised Hyperspectral Unmixing
May 21, 2021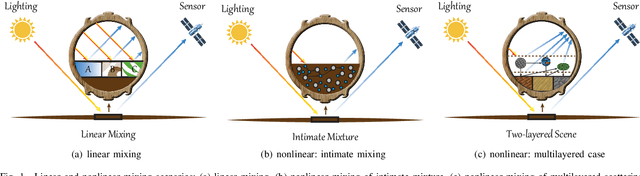
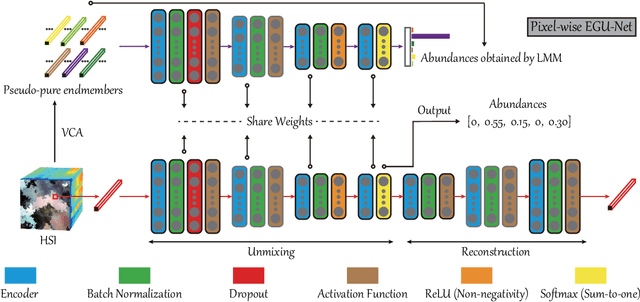
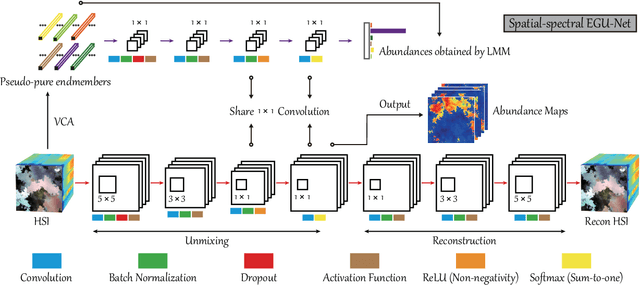

Over the past decades, enormous efforts have been made to improve the performance of linear or nonlinear mixing models for hyperspectral unmixing, yet their ability to simultaneously generalize various spectral variabilities and extract physically meaningful endmembers still remains limited due to the poor ability in data fitting and reconstruction and the sensitivity to various spectral variabilities. Inspired by the powerful learning ability of deep learning, we attempt to develop a general deep learning approach for hyperspectral unmixing, by fully considering the properties of endmembers extracted from the hyperspectral imagery, called endmember-guided unmixing network (EGU-Net). Beyond the alone autoencoder-like architecture, EGU-Net is a two-stream Siamese deep network, which learns an additional network from the pure or nearly-pure endmembers to correct the weights of another unmixing network by sharing network parameters and adding spectrally meaningful constraints (e.g., non-negativity and sum-to-one) towards a more accurate and interpretable unmixing solution. Furthermore, the resulting general framework is not only limited to pixel-wise spectral unmixing but also applicable to spatial information modeling with convolutional operators for spatial-spectral unmixing. Experimental results conducted on three different datasets with the ground-truth of abundance maps corresponding to each material demonstrate the effectiveness and superiority of the EGU-Net over state-of-the-art unmixing algorithms. The codes will be available from the website: https://github.com/danfenghong/IEEE_TNNLS_EGU-Net.
Surface Detection for Sketched Single Photon Lidar
May 14, 2021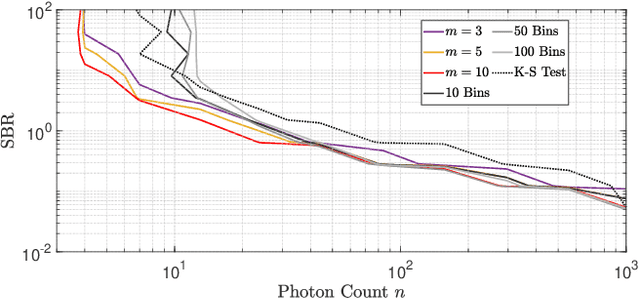
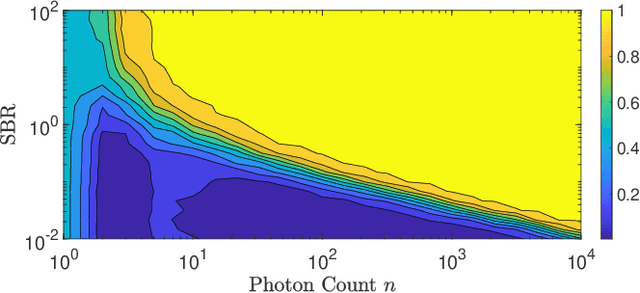
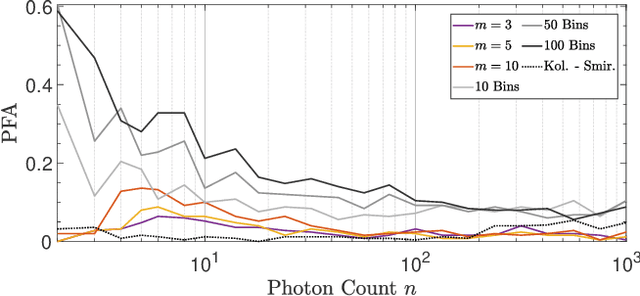

Single-photon lidar devices are able to collect an ever-increasing amount of time-stamped photons in small time periods due to increasingly larger arrays, generating a memory and computational bottleneck on the data processing side. Recently, a sketching technique was introduced to overcome this bottleneck which compresses the amount of information to be stored and processed. The size of the sketch scales with the number of underlying parameters of the time delay distribution and not, fundamentally, with either the number of detected photons or the time-stamp resolution. In this paper, we propose a detection algorithm based solely on a small sketch that determines if there are surfaces or objects in the scene or not. If a surface is detected, the depth and intensity of a single object can be computed in closed-form directly from the sketch. The computational load of the proposed detection algorithm depends solely on the size of the sketch, in contrast to previous algorithms that depend at least linearly in the number of collected photons or histogram bins, paving the way for fast, accurate and memory efficient lidar estimation. Our experiments demonstrate the memory and statistical efficiency of the proposed algorithm both on synthetic and real lidar datasets.