 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Moon's Many Faces: A Single Unified Transformer for Multimodal Lunar Reconstruction
May 08, 2025



Multimodal learning is an emerging research topic across multiple disciplines but has rarely been applied to planetary science. In this contribution, we identify that reflectance parameter estimation and image-based 3D reconstruction of lunar images can be formulated as a multimodal learning problem. We propose a single, unified transformer architecture trained to learn shared representations between multiple sources like grayscale images, digital elevation models, surface normals, and albedo maps. The architecture supports flexible translation from any input modality to any target modality. Predicting DEMs and albedo maps from grayscale images simultaneously solves the task of 3D reconstruction of planetary surfaces and disentangles photometric parameters and height information. Our results demonstrate that our foundation model learns physically plausible relations across these four modalities. Adding more input modalities in the future will enable tasks such as photometric normalization and co-registration.
RadarScenes: A Real-World Radar Point Cloud Data Set for Automotive Applications
Apr 06, 2021
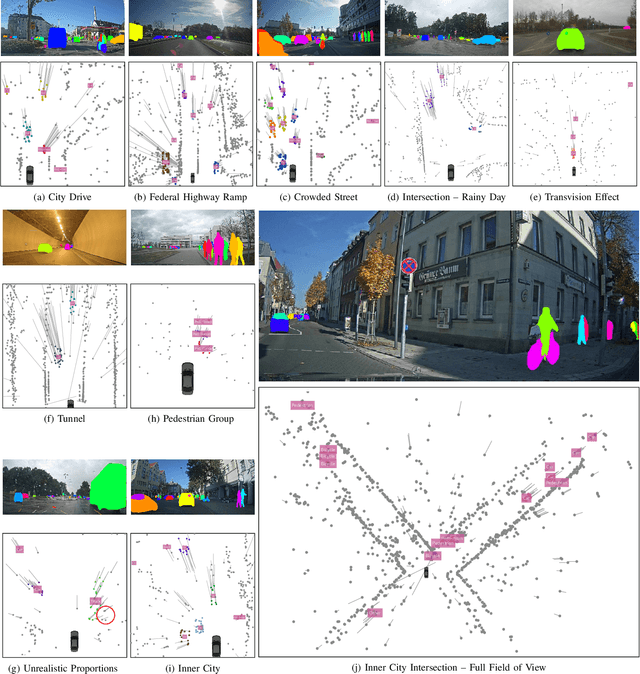
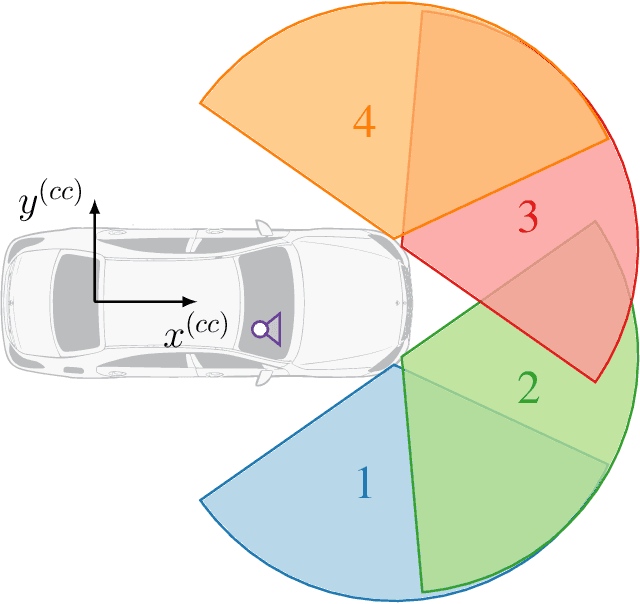
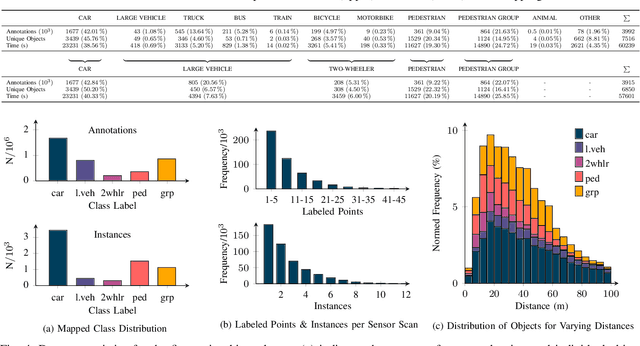
A new automotive radar data set with measurements and point-wise annotations from more than four hours of driving is presented. Data provided by four series radar sensors mounted on one test vehicle were recorded and the individual detections of dynamic objects were manually grouped to clusters and labeled afterwards. The purpose of this data set is to enable the development of novel (machine learning-based) radar perception algorithms with the focus on moving road users. Images of the recorded sequences were captured using a documentary camera. For the evaluation of future object detection and classification algorithms, proposals for score calculation are made so that researchers can evaluate their algorithms on a common basis. Additional information as well as download instructions can be found on the website of the data set: www.radar-scenes.com.