 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Training image classifiers using Semi-Weak Label Data
Mar 19, 2021


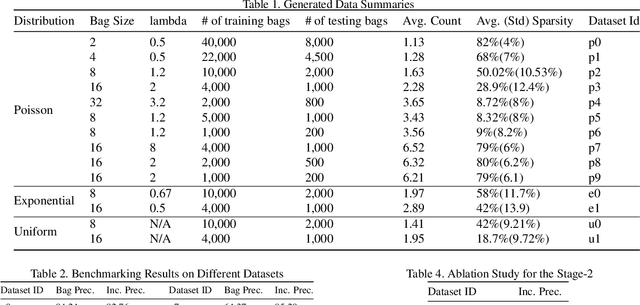

In Multiple Instance learning (MIL), weak labels are provided at the bag level with only presence/absence information known. However, there is a considerable gap in performance in comparison to a fully supervised model, limiting the practical applicability of MIL approaches. Thus, this paper introduces a novel semi-weak label learning paradigm as a middle ground to mitigate the problem. We define semi-weak label data as data where we know the presence or absence of a given class and the exact count of each class as opposed to knowing the label proportions. We then propose a two-stage framework to address the problem of learning from semi-weak labels. It leverages the fact that counting information is non-negative and discrete. Experiments are conducted on generated samples from CIFAR-10. We compare our model with a fully-supervised setting baseline, a weakly-supervised setting baseline and learning from pro-portion (LLP) baseline. Our framework not only outperforms both baseline models for MIL-based weakly super-vised setting and learning from proportion setting, but also gives comparable results compared to the fully supervised model. Further, we conduct thorough ablation studies to analyze across datasets and variation with batch size, losses architectural changes, bag size and regularization
TorontoCL at CMCL 2021 Shared Task: RoBERTa with Multi-Stage Fine-Tuning for Eye-Tracking Prediction
Apr 15, 2021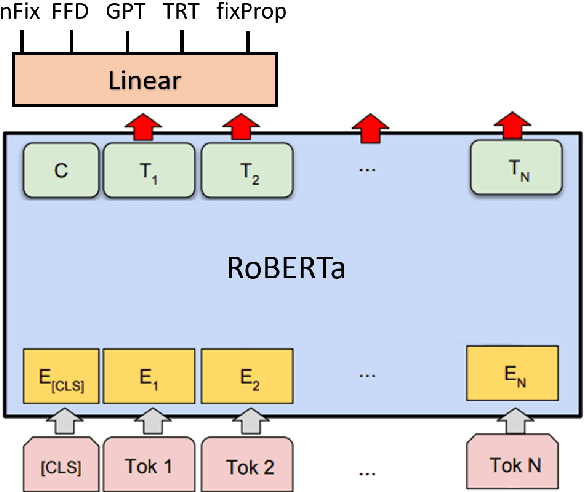

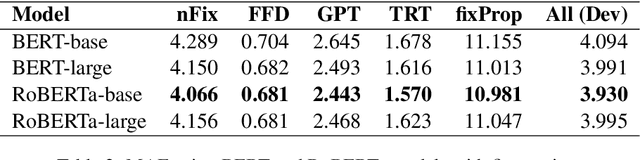
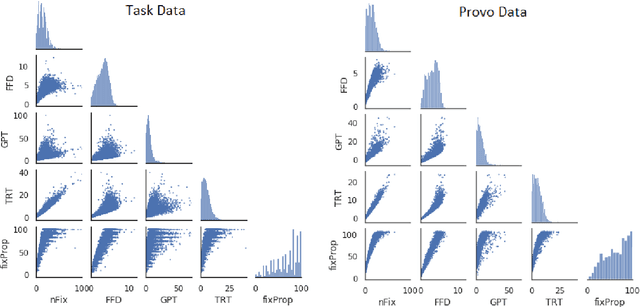
Eye movement data during reading is a useful source of information for understanding language comprehension processes. In this paper, we describe our submission to the CMCL 2021 shared task on predicting human reading patterns. Our model uses RoBERTa with a regression layer to predict 5 eye-tracking features. We train the model in two stages: we first fine-tune on the Provo corpus (another eye-tracking dataset), then fine-tune on the task data. We compare different Transformer models and apply ensembling methods to improve the performance. Our final submission achieves a MAE score of 3.929, ranking 3rd place out of 13 teams that participated in this shared task.
Interpreting Depression From Question-wise Long-term Video Recording of SDS Evaluation
Jun 25, 2021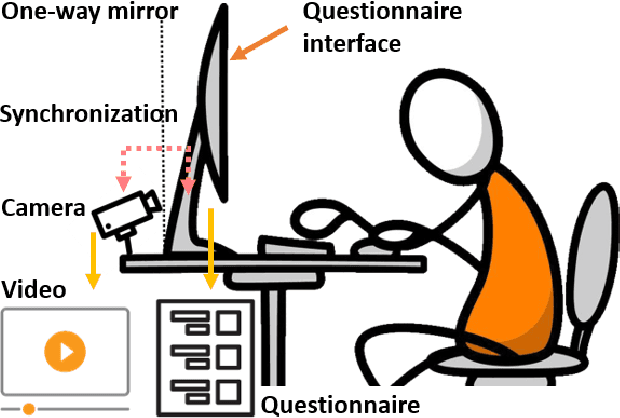

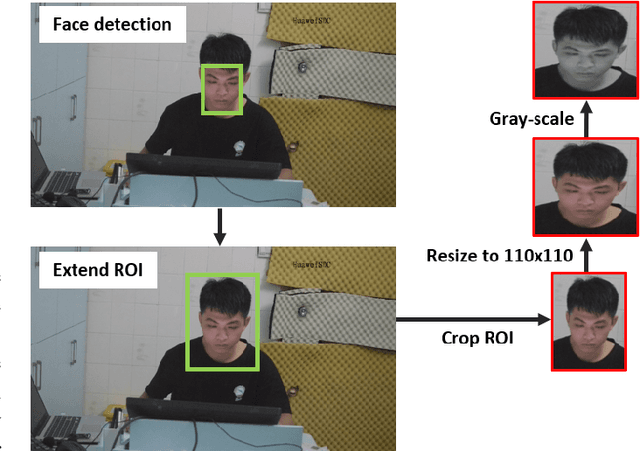
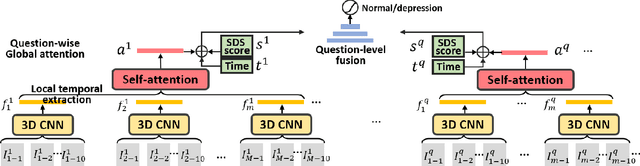
Self-Rating Depression Scale (SDS) questionnaire has frequently been used for efficient depression preliminary screening. However, the uncontrollable self-administered measure can be easily affected by insouciantly or deceptively answering, and producing the different results with the clinician-administered Hamilton Depression Rating Scale (HDRS) and the final diagnosis. Clinically, facial expression (FE) and actions play a vital role in clinician-administered evaluation, while FE and action are underexplored for self-administered evaluations. In this work, we collect a novel dataset of 200 subjects to evidence the validity of self-rating questionnaires with their corresponding question-wise video recording. To automatically interpret depression from the SDS evaluation and the paired video, we propose an end-to-end hierarchical framework for the long-term variable-length video, which is also conditioned on the questionnaire results and the answering time. Specifically, we resort to a hierarchical model which utilizes a 3D CNN for local temporal pattern exploration and a redundancy-aware self-attention (RAS) scheme for question-wise global feature aggregation. Targeting for the redundant long-term FE video processing, our RAS is able to effectively exploit the correlations of each video clip within a question set to emphasize the discriminative information and eliminate the redundancy based on feature pair-wise affinity. Then, the question-wise video feature is concatenated with the questionnaire scores for final depression detection. Our thorough evaluations also show the validity of fusing SDS evaluation and its video recording, and the superiority of our framework to the conventional state-of-the-art temporal modeling methods.
Conformal Prediction in Learning Under Privileged Information Paradigm with Applications in Drug Discovery
Apr 04, 2018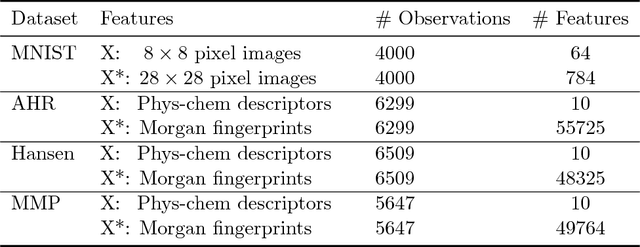
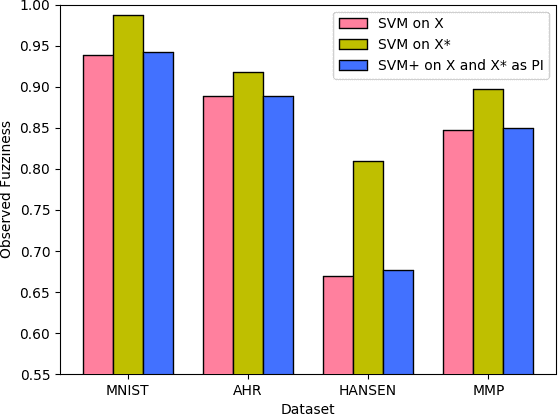

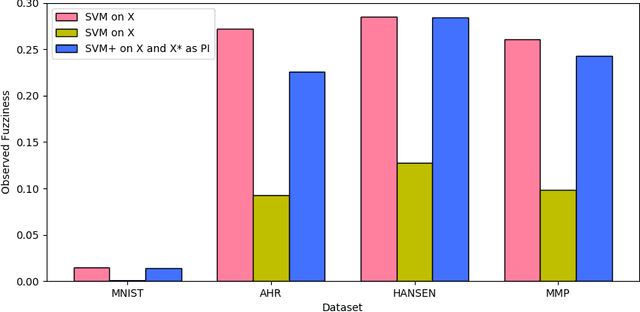
This paper explores conformal prediction in the learning under privileged information (LUPI) paradigm. We use the SVM+ realization of LUPI in an inductive conformal predictor, and apply it to the MNIST benchmark dataset and three datasets in drug discovery. The results show that using privileged information produces valid models and improves efficiency compared to standard SVM, however the improvement varies between the tested datasets and is not substantial in the drug discovery applications. More importantly, using SVM+ in a conformal prediction framework enables valid prediction intervals at specified significance levels.
Two-Dimensional DOA Estimation for L-shaped Nested Array via Tensor Modeling
Apr 14, 2021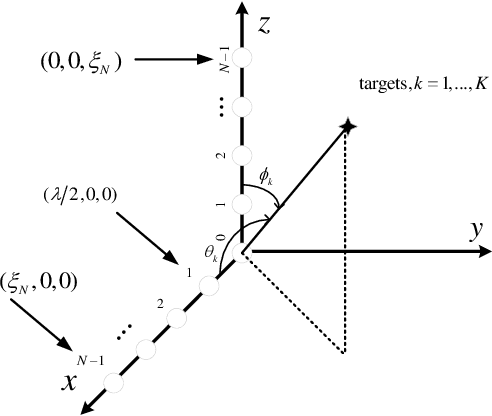
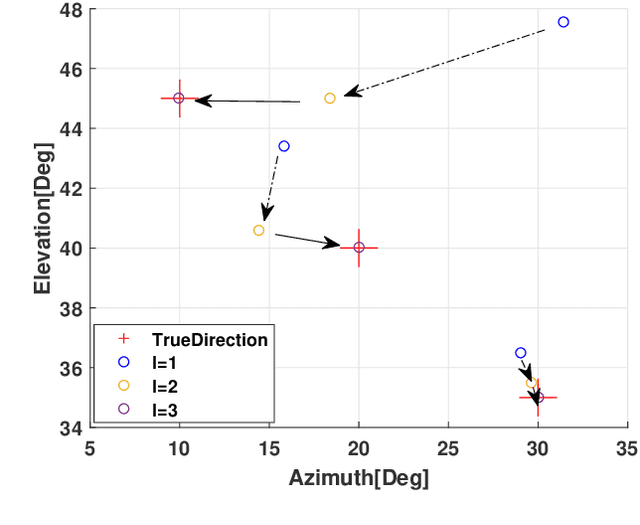
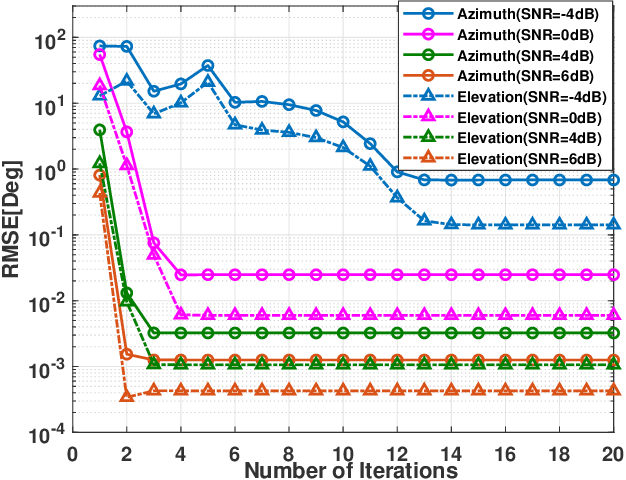
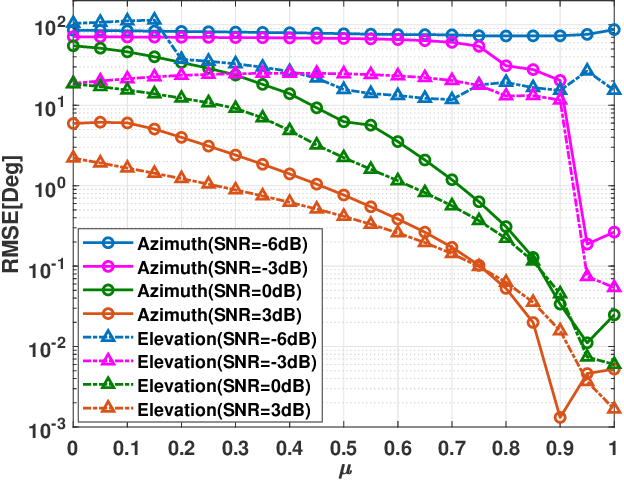
The problem of two-dimensional (2-D) direction-of-arrival (DOA) estimation for L-shaped nested array is considered. Typically, the multi-dimensional structure of the received signal in co-array domain is ignored in the problem considered. Moreover, the cross term generated by the correlated signal and noise components degrades the 2-D DOA estimation performance seriously. To tackle these issues, an iterative 2-D DOA estimation approach based on tensor modeling is proposed. To develop such approach, a higher-order tensor is constructed, whose factor matrices contain the target azimuth and elevation information. By exploiting the Vandermonde structure of the factor matrix, a computationally efficient tensor decomposition method is then developed to estimate the targets DOA information in each dimension independently. Then, an eigenvalue-based approach that exploits a natural coupling of the 2-D spatial parameters is proposed to pair the azimuth and elevation angles. Finally, an iterative method is designed to improve the DOA estimation performance. Specifically, the cross term is estimated and removed in the next step of such iterative procedure on the basis of the DOA estimates originated from the tensor decomposition in the previous step. Consequently, the DOA estimation with better accuracy and higher resolution is obtained. The proposed iterative 2-D DOA estimation method for L-shaped nested array can resolve more targets than the number of real elements, even when the azimuth or elevation angles are identical, which is superior to conventional approaches. Simulation results validate the performance improvement of the proposed 2-D DOA estimation method as compared to existing state-of-the-art DOA estimation techniques for L-shaped nested array.
Towards NIR-VIS Masked Face Recognition
Apr 14, 2021
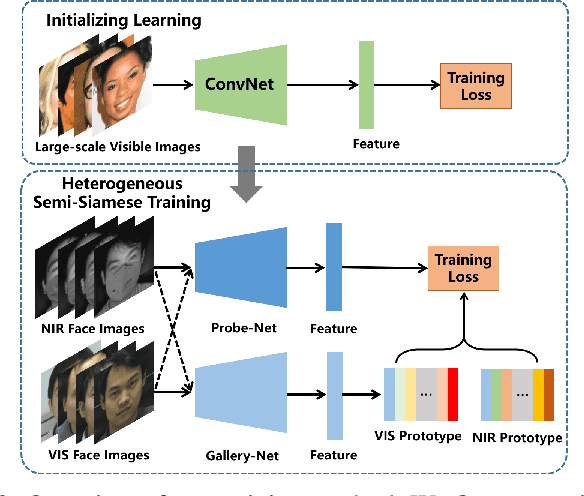
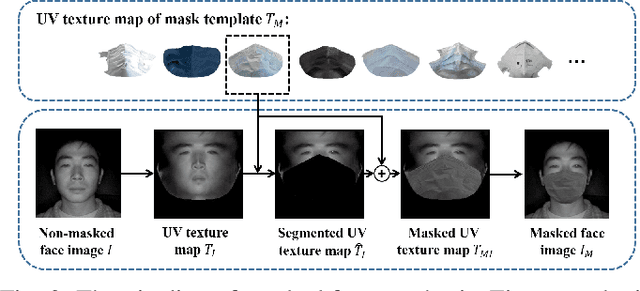

Near-infrared to visible (NIR-VIS) face recognition is the most common case in heterogeneous face recognition, which aims to match a pair of face images captured from two different modalities. Existing deep learning based methods have made remarkable progress in NIR-VIS face recognition, while it encounters certain newly-emerged difficulties during the pandemic of COVID-19, since people are supposed to wear facial masks to cut off the spread of the virus. We define this task as NIR-VIS masked face recognition, and find it problematic with the masked face in the NIR probe image. First, the lack of masked face data is a challenging issue for the network training. Second, most of the facial parts (cheeks, mouth, nose etc.) are fully occluded by the mask, which leads to a large amount of loss of information. Third, the domain gap still exists in the remaining facial parts. In such scenario, the existing methods suffer from significant performance degradation caused by the above issues. In this paper, we aim to address the challenge of NIR-VIS masked face recognition from the perspectives of training data and training method. Specifically, we propose a novel heterogeneous training method to maximize the mutual information shared by the face representation of two domains with the help of semi-siamese networks. In addition, a 3D face reconstruction based approach is employed to synthesize masked face from the existing NIR image. Resorting to these practices, our solution provides the domain-invariant face representation which is also robust to the mask occlusion. Extensive experiments on three NIR-VIS face datasets demonstrate the effectiveness and cross-dataset-generalization capacity of our method.
Boundary-Aware Geometric Encoding for Semantic Segmentation of Point Clouds
Jan 07, 2021
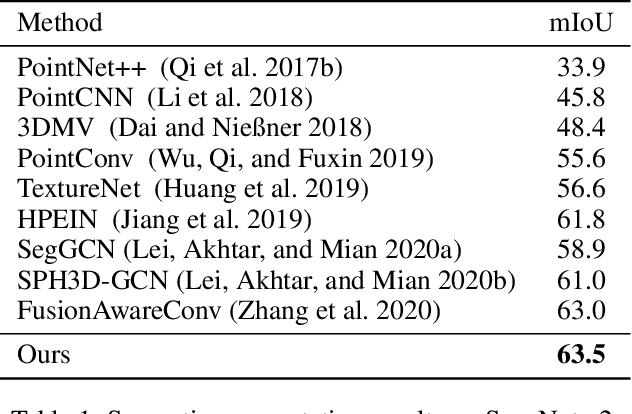
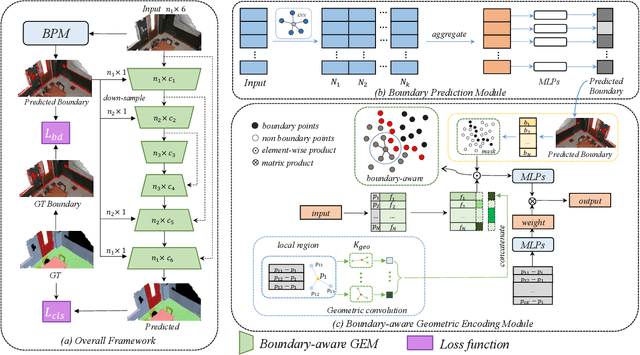
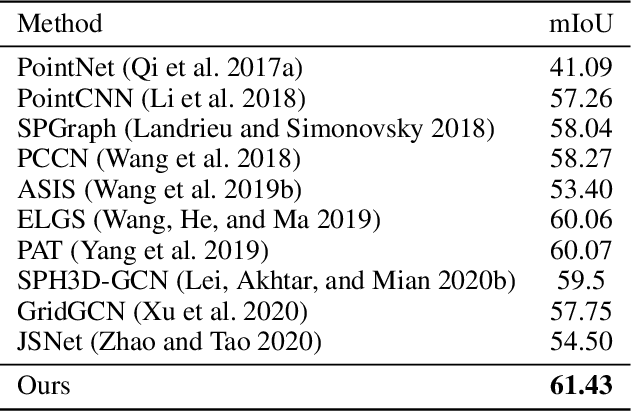
Boundary information plays a significant role in 2D image segmentation, while usually being ignored in 3D point cloud segmentation where ambiguous features might be generated in feature extraction, leading to misclassification in the transition area between two objects. In this paper, firstly, we propose a Boundary Prediction Module (BPM) to predict boundary points. Based on the predicted boundary, a boundary-aware Geometric Encoding Module (GEM) is designed to encode geometric information and aggregate features with discrimination in a neighborhood, so that the local features belonging to different categories will not be polluted by each other. To provide extra geometric information for boundary-aware GEM, we also propose a light-weight Geometric Convolution Operation (GCO), making the extracted features more distinguishing. Built upon the boundary-aware GEM, we build our network and test it on benchmarks like ScanNet v2, S3DIS. Results show our methods can significantly improve the baseline and achieve state-of-the-art performance. Code is available at https://github.com/JchenXu/BoundaryAwareGEM.
Covariate-assisted Sparse Tensor Completion
Mar 11, 2021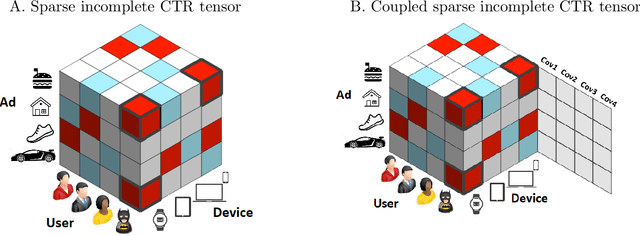

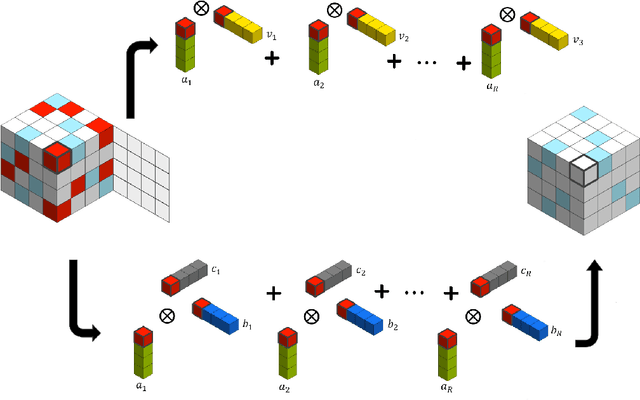
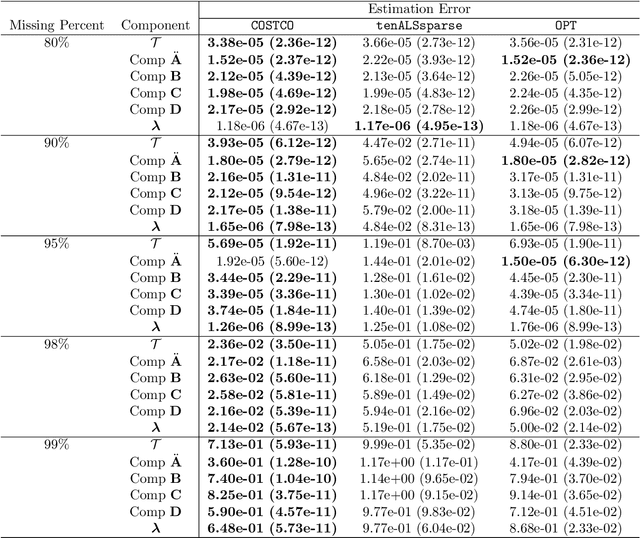
We aim to provably complete a sparse and highly-missing tensor in the presence of covariate information along tensor modes. Our motivation comes from online advertising where users click-through-rates (CTR) on ads over various devices form a CTR tensor that has about 96% missing entries and has many zeros on non-missing entries, which makes the standalone tensor completion method unsatisfactory. Beside the CTR tensor, additional ad features or user characteristics are often available. In this paper, we propose Covariate-assisted Sparse Tensor Completion (COSTCO) to incorporate covariate information for the recovery of the sparse tensor. The key idea is to jointly extract latent components from both the tensor and the covariate matrix to learn a synthetic representation. Theoretically, we derive the error bound for the recovered tensor components and explicitly quantify the improvements on both the reveal probability condition and the tensor recovery accuracy due to covariates. Finally, we apply COSTCO to an advertisement dataset consisting of a CTR tensor and ad covariate matrix, leading to 23% accuracy improvement over the baseline. An important by-product is that ad latent components from COSTCO reveal interesting ad clusters, which are useful for better ad targeting.
Hierarchical Video Generation from Orthogonal Information: Optical Flow and Texture
Dec 01, 2017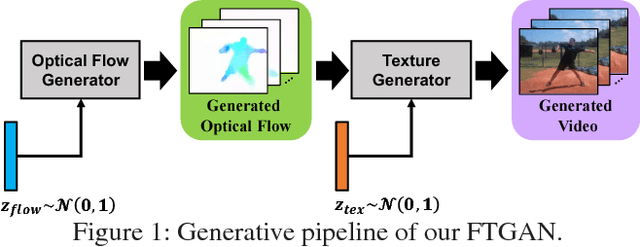
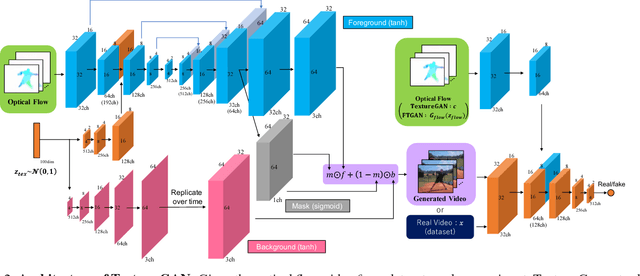


Learning to represent and generate videos from unlabeled data is a very challenging problem. To generate realistic videos, it is important not only to ensure that the appearance of each frame is real, but also to ensure the plausibility of a video motion and consistency of a video appearance in the time direction. The process of video generation should be divided according to these intrinsic difficulties. In this study, we focus on the motion and appearance information as two important orthogonal components of a video, and propose Flow-and-Texture-Generative Adversarial Networks (FTGAN) consisting of FlowGAN and TextureGAN. In order to avoid a huge annotation cost, we have to explore a way to learn from unlabeled data. Thus, we employ optical flow as motion information to generate videos. FlowGAN generates optical flow, which contains only the edge and motion of the videos to be begerated. On the other hand, TextureGAN specializes in giving a texture to optical flow generated by FlowGAN. This hierarchical approach brings more realistic videos with plausible motion and appearance consistency. Our experiments show that our model generates more plausible motion videos and also achieves significantly improved performance for unsupervised action classification in comparison to previous GAN works. In addition, because our model generates videos from two independent information, our model can generate new combinations of motion and attribute that are not seen in training data, such as a video in which a person is doing sit-up in a baseball ground.
Evaluating the Immediate Applicability of Pose Estimation for Sign Language Recognition
Apr 20, 2021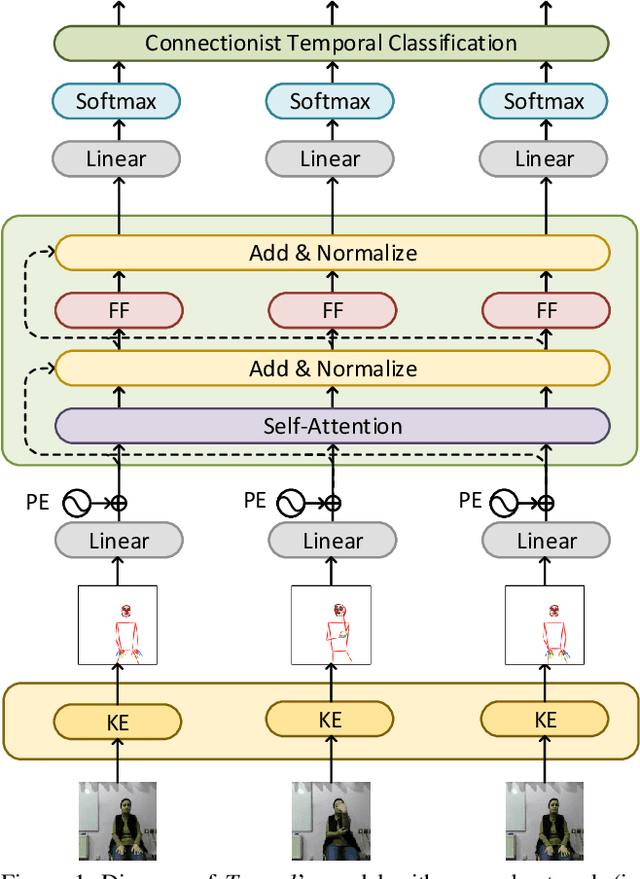
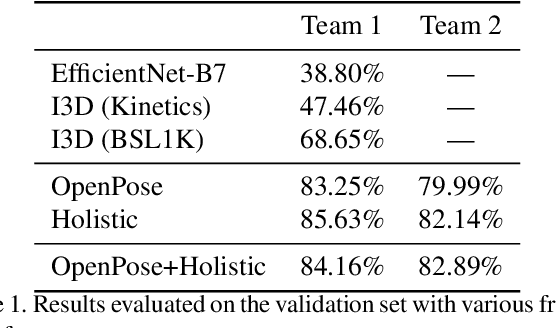
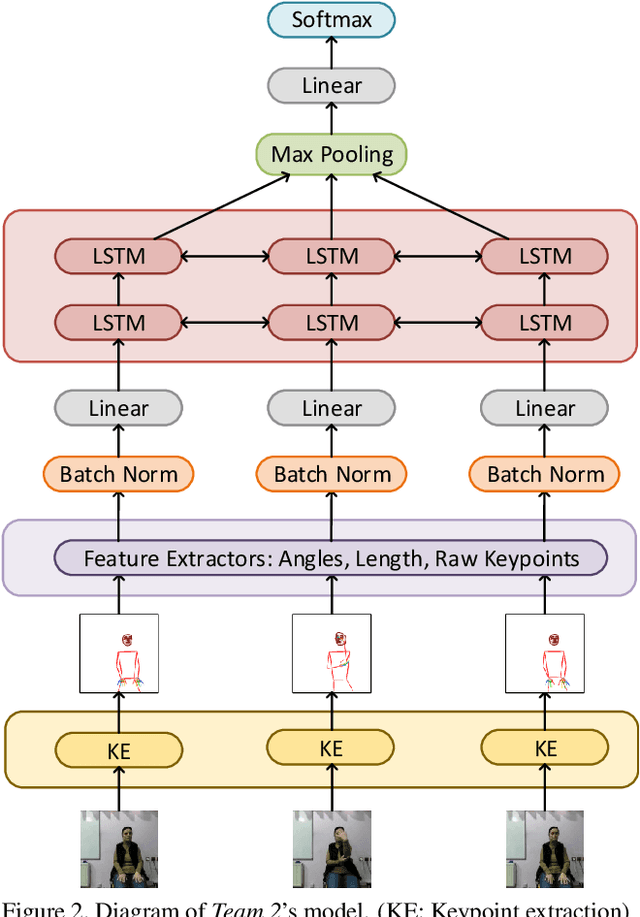
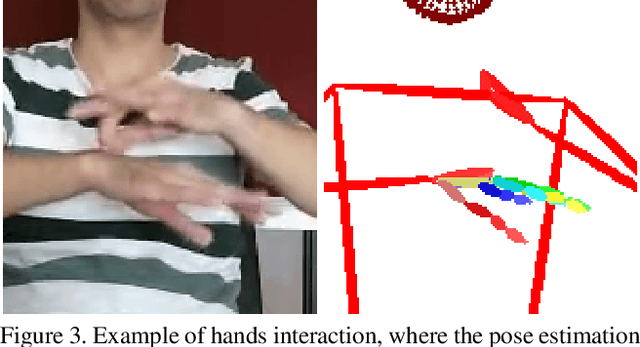
Signed languages are visual languages produced by the movement of the hands, face, and body. In this paper, we evaluate representations based on skeleton poses, as these are explainable, person-independent, privacy-preserving, low-dimensional representations. Basically, skeletal representations generalize over an individual's appearance and background, allowing us to focus on the recognition of motion. But how much information is lost by the skeletal representation? We perform two independent studies using two state-of-the-art pose estimation systems. We analyze the applicability of the pose estimation systems to sign language recognition by evaluating the failure cases of the recognition models. Importantly, this allows us to characterize the current limitations of skeletal pose estimation approaches in sign language recognition.