 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive Methods for Real-World Domain Generalization
Mar 30, 2021
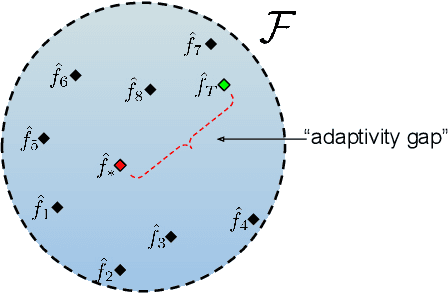

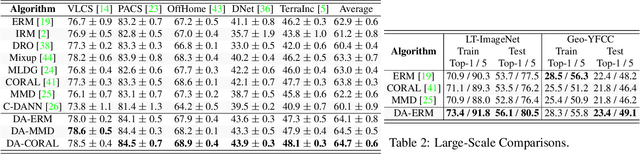
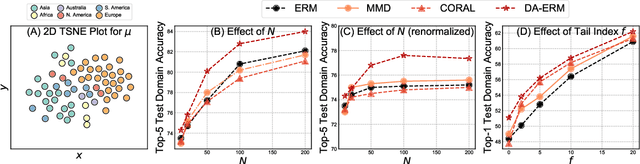
Invariant approaches have been remarkably successful in tackling the problem of domain generalization, where the objective is to perform inference on data distributions different from those used in training. In our work, we investigate whether it is possible to leverage domain information from the unseen test samples themselves. We propose a domain-adaptive approach consisting of two steps: a) we first learn a discriminative domain embedding from unsupervised training examples, and b) use this domain embedding as supplementary information to build a domain-adaptive model, that takes both the input as well as its domain into account while making predictions. For unseen domains, our method simply uses few unlabelled test examples to construct the domain embedding. This enables adaptive classification on any unseen domain. Our approach achieves state-of-the-art performance on various domain generalization benchmarks. In addition, we introduce the first real-world, large-scale domain generalization benchmark, Geo-YFCC, containing 1.1M samples over 40 training, 7 validation, and 15 test domains, orders of magnitude larger than prior work. We show that the existing approaches either do not scale to this dataset or underperform compared to the simple baseline of training a model on the union of data from all training domains. In contrast, our approach achieves a significant improvement.
Sentiment Progression based Searching and Indexing of Literary Textual Artefacts
Jun 16, 2021
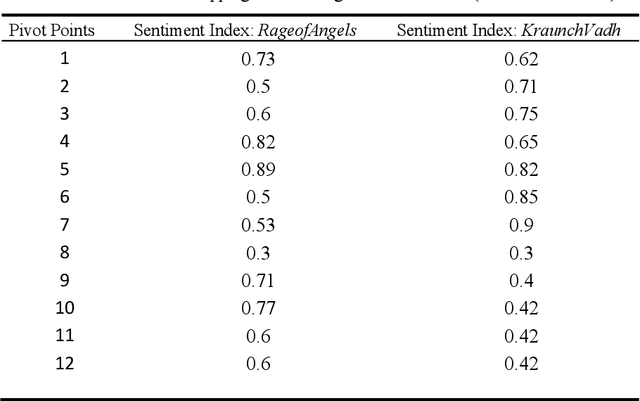
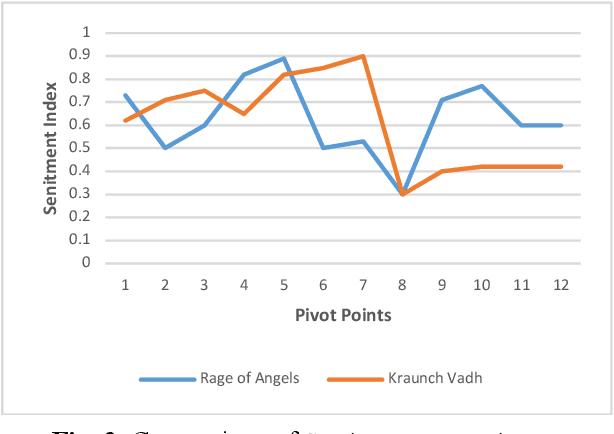
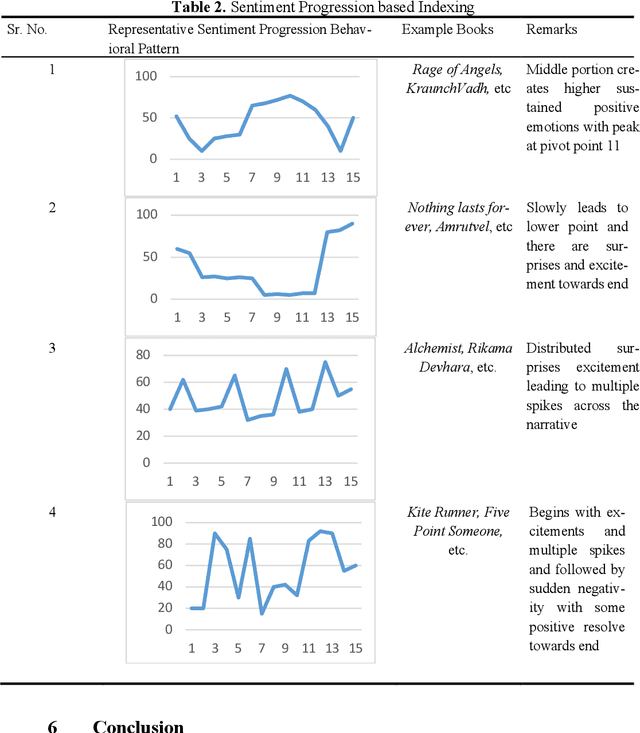
Literary artefacts are generally indexed and searched based on titles, meta data and keywords over the years. This searching and indexing works well when user/reader already knows about that particular creative textual artefact or document. This indexing and search hardly takes into account interest and emotional makeup of readers and its mapping to books. When a person is looking for a literary textual artefact, he/she might be looking for not only information but also to seek the joy of reading. In case of literary artefacts, progression of emotions across the key events could prove to be the key for indexing and searching. In this paper, we establish clusters among literary artefacts based on computational relationships among sentiment progressions using intelligent text analysis. We have created a database of 1076 English titles + 20 Marathi titles and also used database http://www.cs.cmu.edu/~dbamman/booksummaries.html with 16559 titles and their summaries. We have proposed Sentiment Progression based Indexing for searching and recommending books. This can be used to create personalized clusters of book titles of interest to readers. The analysis clearly suggests better searching and indexing when we are targeting book lovers looking for a particular type of book or creative artefact. This indexing and searching can find many real-life applications for recommending books.
Invariant components of synergy, redundancy, and unique information among three variables
Jun 27, 2017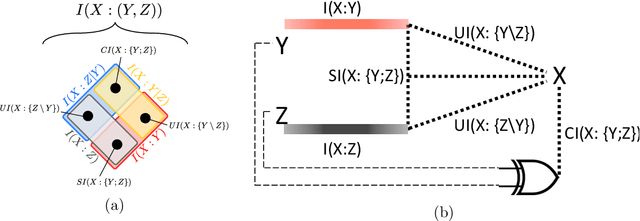
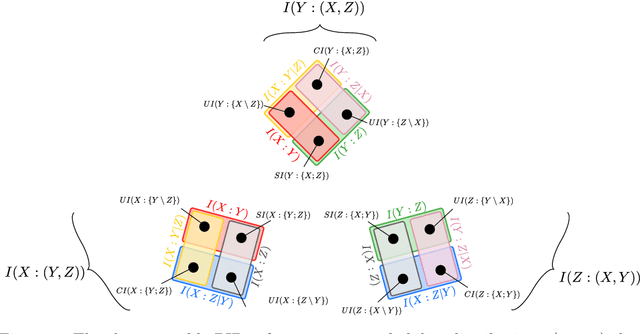
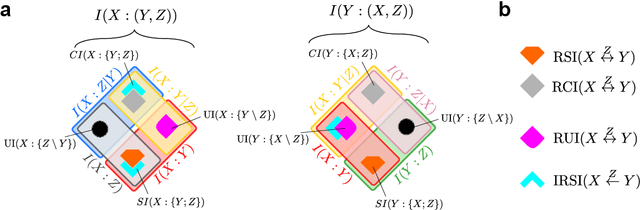
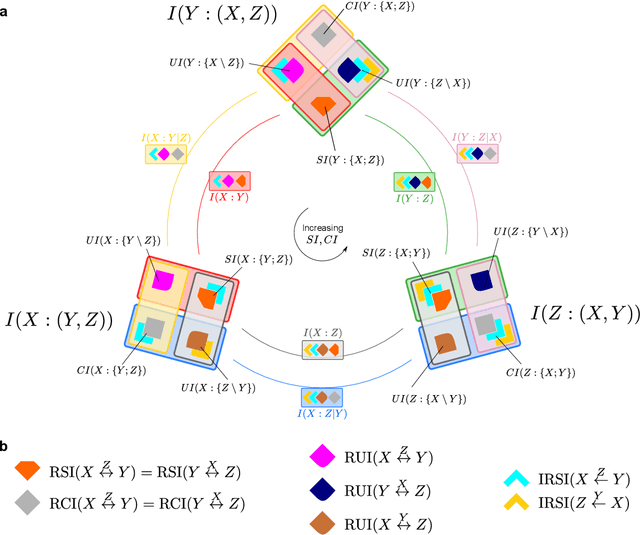
In a system of three stochastic variables, the Partial Information Decomposition (PID) of Williams and Beer dissects the information that two variables (sources) carry about a third variable (target) into nonnegative information atoms that describe redundant, unique, and synergistic modes of dependencies among the variables. However, the classification of the three variables into two sources and one target limits the dependency modes that can be quantitatively resolved, and does not naturally suit all systems. Here, we extend the PID to describe trivariate modes of dependencies in full generality, without introducing additional decomposition axioms or making assumptions about the target/source nature of the variables. By comparing different PID lattices of the same system, we unveil a finer PID structure made of seven nonnegative information subatoms that are invariant to different target/source classifications and that are sufficient to construct any PID lattice. This finer structure naturally splits redundant information into two nonnegative components: the source redundancy, which arises from the pairwise correlations between the source variables, and the non-source redundancy, which does not, and relates to the synergistic information the sources carry about the target. The invariant structure is also sufficient to construct the system's entropy, hence it characterizes completely all the interdependencies in the system.
Inferring Objectives in Continuous Dynamic Games from Noise-Corrupted Partial State Observations
Jun 16, 2021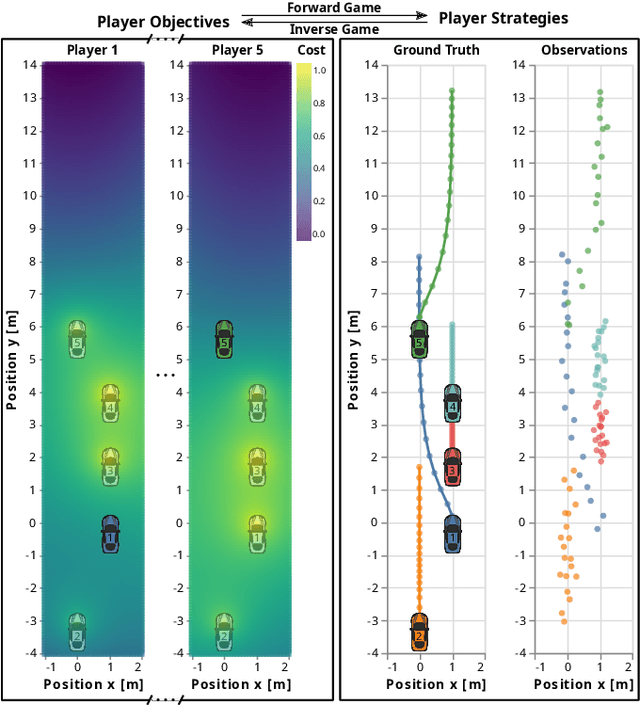
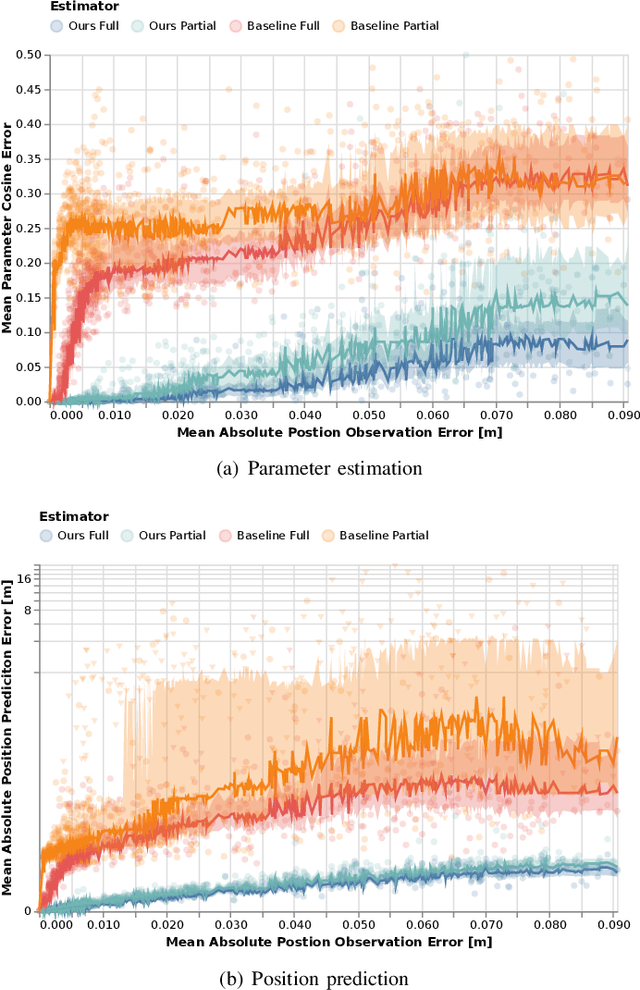
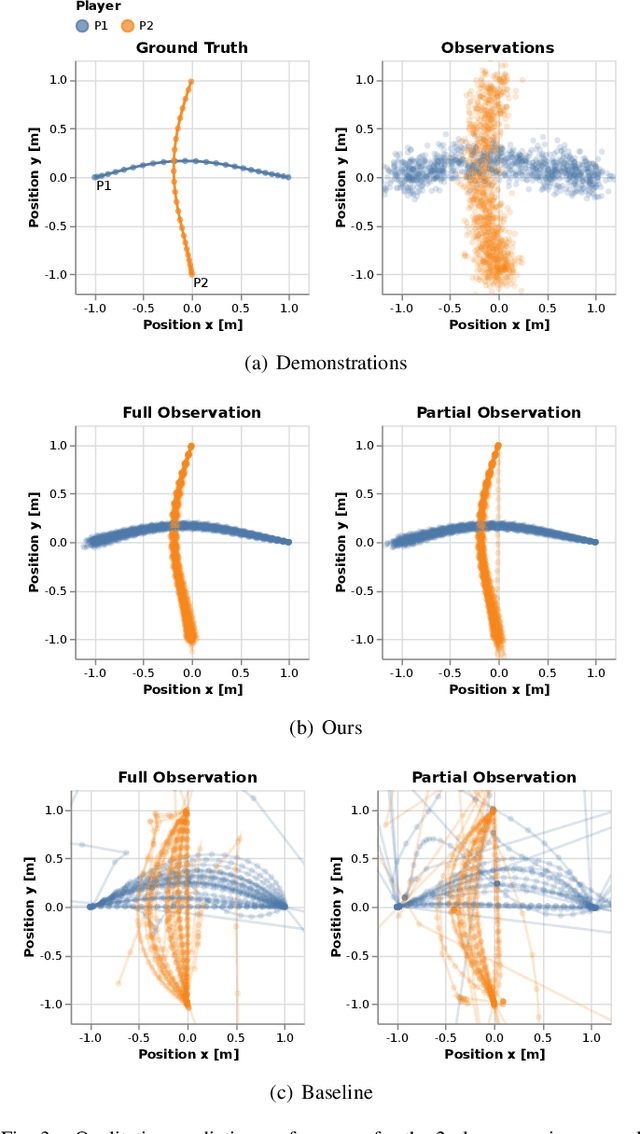
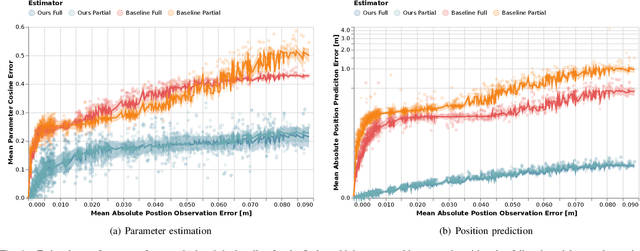
Robots and autonomous systems must interact with one another and their environment to provide high-quality services to their users. Dynamic game theory provides an expressive theoretical framework for modeling scenarios involving multiple agents with differing objectives interacting over time. A core challenge when formulating a dynamic game is designing objectives for each agent that capture desired behavior. In this paper, we propose a method for inferring parametric objective models of multiple agents based on observed interactions. Our inverse game solver jointly optimizes player objectives and continuous-state estimates by coupling them through Nash equilibrium constraints. Hence, our method is able to directly maximize the observation likelihood rather than other non-probabilistic surrogate criteria. Our method does not require full observations of game states or player strategies to identify player objectives. Instead, it robustly recovers this information from noisy, partial state observations. As a byproduct of estimating player objectives, our method computes a Nash equilibrium trajectory corresponding to those objectives. Thus, it is suitable for downstream trajectory forecasting tasks. We demonstrate our method in several simulated traffic scenarios. Results show that it reliably estimates player objectives from a short sequence of noise-corrupted partial state observations. Furthermore, using the estimated objectives, our method makes accurate predictions of each player's trajectory.
Audio-Oriented Multimodal Machine Comprehension: Task, Dataset and Model
Jul 04, 2021
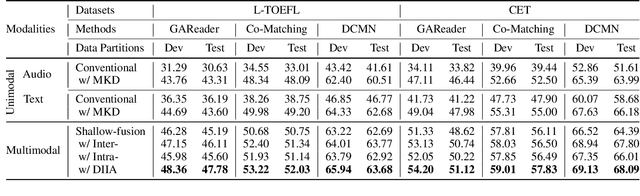
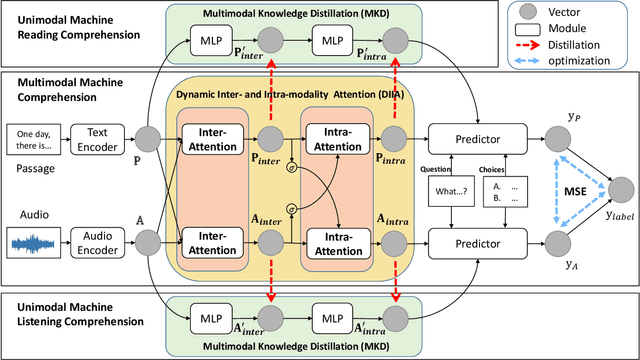
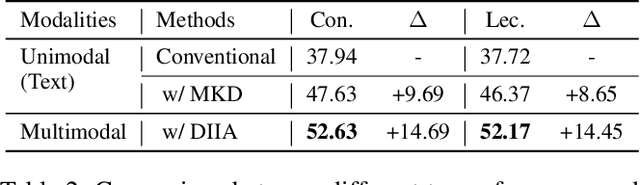
While Machine Comprehension (MC) has attracted extensive research interests in recent years, existing approaches mainly belong to the category of Machine Reading Comprehension task which mines textual inputs (paragraphs and questions) to predict the answers (choices or text spans). However, there are a lot of MC tasks that accept audio input in addition to the textual input, e.g. English listening comprehension test. In this paper, we target the problem of Audio-Oriented Multimodal Machine Comprehension, and its goal is to answer questions based on the given audio and textual information. To solve this problem, we propose a Dynamic Inter- and Intra-modality Attention (DIIA) model to effectively fuse the two modalities (audio and textual). DIIA can work as an independent component and thus be easily integrated into existing MC models. Moreover, we further develop a Multimodal Knowledge Distillation (MKD) module to enable our multimodal MC model to accurately predict the answers based only on either the text or the audio. As a result, the proposed approach can handle various tasks including: Audio-Oriented Multimodal Machine Comprehension, Machine Reading Comprehension and Machine Listening Comprehension, in a single model, making fair comparisons possible between our model and the existing unimodal MC models. Experimental results and analysis prove the effectiveness of the proposed approaches. First, the proposed DIIA boosts the baseline models by up to 21.08% in terms of accuracy; Second, under the unimodal scenarios, the MKD module allows our multimodal MC model to significantly outperform the unimodal models by up to 18.87%, which are trained and tested with only audio or textual data.
Knowledge AI: New Medical AI Solution for Medical image Diagnosis
Jan 08, 2021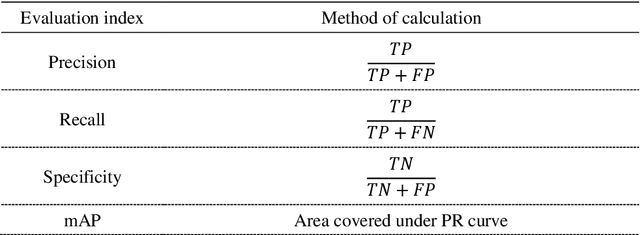

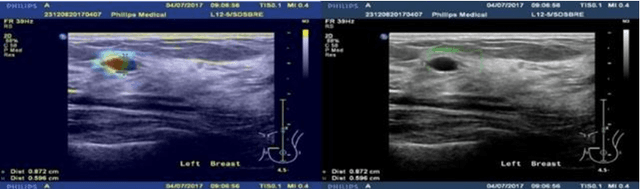
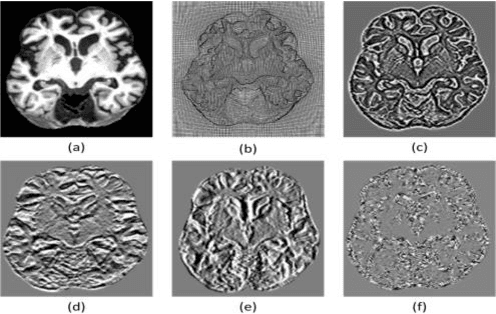
The implementation of medical AI has always been a problem. The effect of traditional perceptual AI algorithm in medical image processing needs to be improved. Here we propose a method of knowledge AI, which is a combination of perceptual AI and clinical knowledge and experience. Based on this method, the geometric information mining of medical images can represent the experience and information and evaluate the quality of medical images.
SFANet: A Spectrum-aware Feature Augmentation Network for Visible-Infrared Person Re-Identification
Feb 24, 2021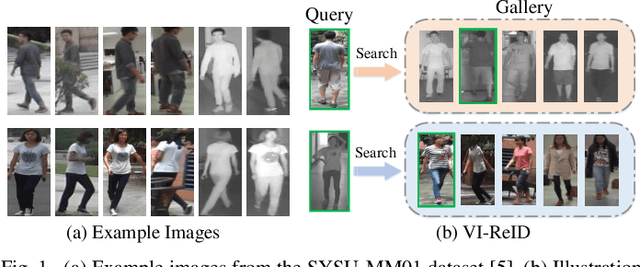
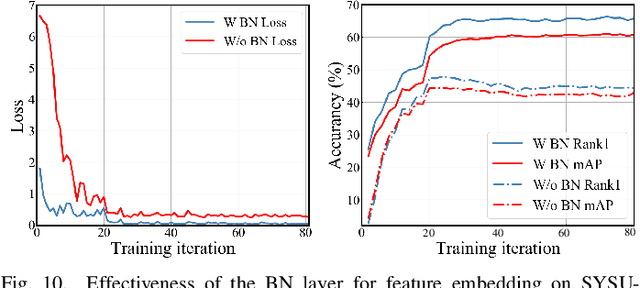

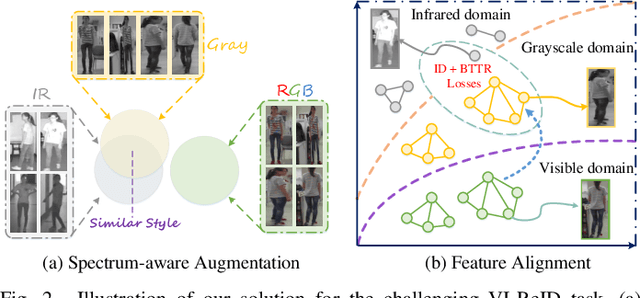
Visible-Infrared person re-identification (VI-ReID) is a challenging matching problem due to large modality varitions between visible and infrared images. Existing approaches usually bridge the modality gap with only feature-level constraints, ignoring pixel-level variations. Some methods employ GAN to generate style-consistent images, but it destroys the structure information and incurs a considerable level of noise. In this paper, we explicitly consider these challenges and formulate a novel spectrum-aware feature augementation network named SFANet for cross-modality matching problem. Specifically, we put forward to employ grayscale-spectrum images to fully replace RGB images for feature learning. Learning with the grayscale-spectrum images, our model can apparently reduce modality discrepancy and detect inner structure relations across the different modalities, making it robust to color variations. In feature-level, we improve the conventional two-stream network through balancing the number of specific and sharable convolutional blocks, which preserve the spatial structure information of features. Additionally, a bi-directional tri-constrained top-push ranking loss (BTTR) is embedded in the proposed network to improve the discriminability, which efficiently further boosts the matching accuracy. Meanwhile, we further introduce an effective dual-linear with batch normalization ID embedding method to model the identity-specific information and assits BTTR loss in magnitude stabilizing. On SYSU-MM01 and RegDB datasets, we conducted extensively experiments to demonstrate that our proposed framework contributes indispensably and achieves a very competitive VI-ReID performance.
An Online Prediction Approach Based on Incremental Support Vector Machine for Dynamic Multiobjective Optimization
Feb 24, 2021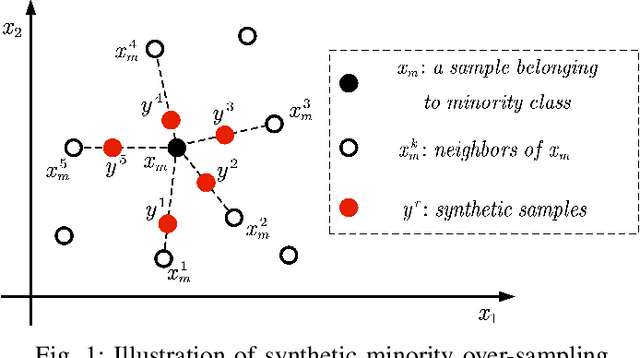

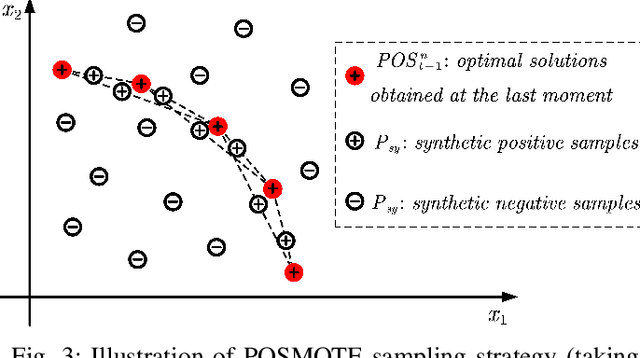
Real-world multiobjective optimization problems usually involve conflicting objectives that change over time, which requires the optimization algorithms to quickly track the Pareto optimal front (POF) when the environment changes. In recent years, evolutionary algorithms based on prediction models have been considered promising. However, most existing approaches only make predictions based on the linear correlation between a finite number of optimal solutions in two or three previous environments. These incomplete information extraction strategies may lead to low prediction accuracy in some instances. In this paper, a novel prediction algorithm based on incremental support vector machine (ISVM) is proposed, called ISVM-DMOEA. We treat the solving of dynamic multiobjective optimization problems (DMOPs) as an online learning process, using the continuously obtained optimal solution to update an incremental support vector machine without discarding the solution information at earlier time. ISVM is then used to filter random solutions and generate an initial population for the next moment. To overcome the obstacle of insufficient training samples, a synthetic minority oversampling strategy is implemented before the training of ISVM. The advantage of this approach is that the nonlinear correlation between solutions can be explored online by ISVM, and the information contained in all historical optimal solutions can be exploited to a greater extent. The experimental results and comparison with chosen state-of-the-art algorithms demonstrate that the proposed algorithm can effectively tackle dynamic multiobjective optimization problems.
Theoretical Modeling of Communication Dynamics
Jun 09, 2021
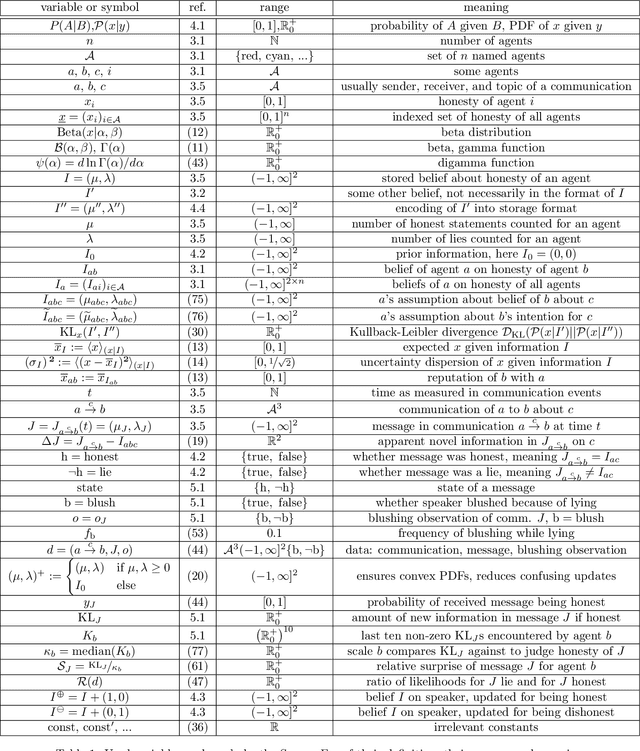
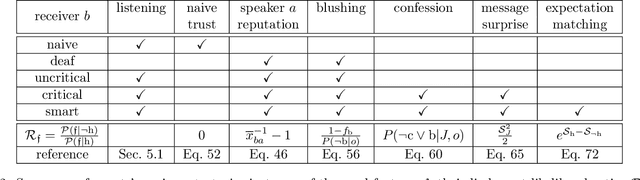
Communication is a cornerstone of social interactions, be it with human or artificial intelligence (AI). Yet it can be harmful, depending on the honesty of the exchanged information. To study this, an agent based sociological simulation framework is presented, the reputation game. This illustrates the impact of different communication strategies on the agents' reputation. The game focuses on the trustworthiness of the participating agents, their honesty as perceived by others. In the game, each agent exchanges statements with the others about their own and each other's honesty, which lets their judgments evolve. Various sender and receiver strategies are studied, like sycophant, egocentricity, pathological lying, and aggressiveness for senders as well as awareness and lack thereof for receivers. Minimalist malicious strategies are identified, like being manipulative, dominant, or destructive, which significantly increase reputation at others' costs. Phenomena such as echo chambers, self-deception, deception symbiosis, clique formation, freezing of group opinions emerge from the dynamics. This indicates that the reputation game can be studied for complex group phenomena, to test behavioral hypothesis, and to analyze AI influenced social media. With refined rules it may help to understand social interactions, and to safeguard the design of non-abusive AI systems.
Measuring and Increasing Context Usage in Context-Aware Machine Translation
Jun 02, 2021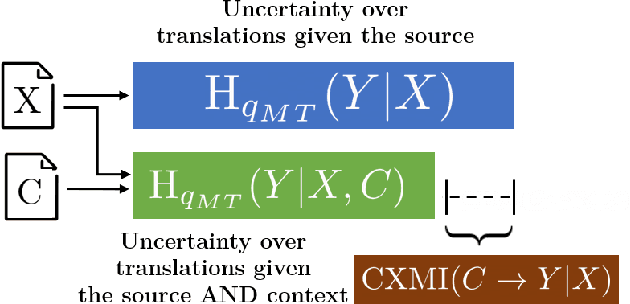

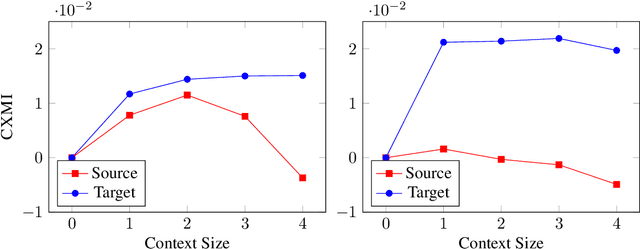
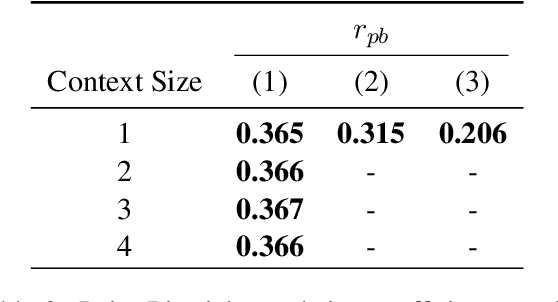
Recent work in neural machine translation has demonstrated both the necessity and feasibility of using inter-sentential context -- context from sentences other than those currently being translated. However, while many current methods present model architectures that theoretically can use this extra context, it is often not clear how much they do actually utilize it at translation time. In this paper, we introduce a new metric, conditional cross-mutual information, to quantify the usage of context by these models. Using this metric, we measure how much document-level machine translation systems use particular varieties of context. We find that target context is referenced more than source context, and that conditioning on a longer context has a diminishing effect on results. We then introduce a new, simple training method, context-aware word dropout, to increase the usage of context by context-aware models. Experiments show that our method increases context usage and that this reflects on the translation quality according to metrics such as BLEU and COMET, as well as performance on anaphoric pronoun resolution and lexical cohesion contrastive datasets.