 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fristograms: Revealing and Exploiting Light Field Internals
Jul 22, 2021
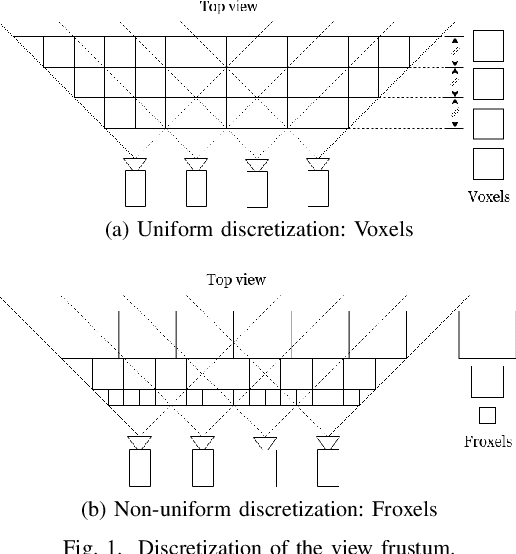
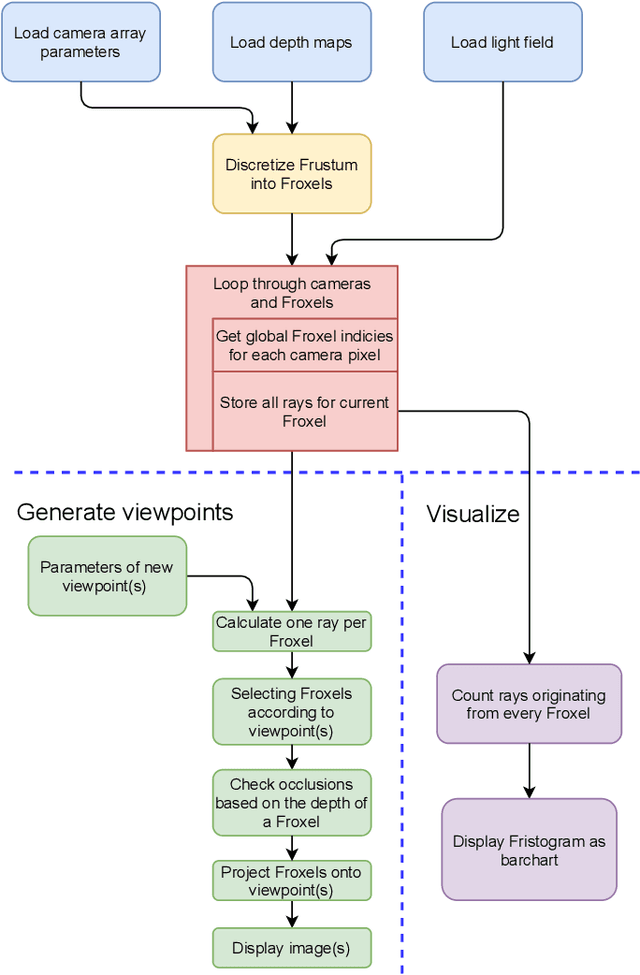


In recent years, light field (LF) capture and processing has become an integral part of media production. The richness of information available in LFs has enabled novel applications like post-capture depth-of-field editing, 3D reconstruction, segmentation and matting, saliency detection, object detection and recognition, and mixed reality. The efficacy of such applications depends on certain underlying requirements, which are often ignored. For example, some operations such as noise-reduction, or hyperfan-filtering are only possible if a scene point Lambertian radiator. Some other operations such as the removal of obstacles or looking behind objects are only possible if there is at least one ray capturing the required scene point. Consequently, the ray distribution representing a certain scene point is an important characteristic for evaluating processing possibilities. The primary idea in this paper is to establish a relation between the capturing setup and the rays of the LF. To this end, we discretize the view frustum. Traditionally, a uniform discretization of the view frustum results in voxels that represents a single sample on a regularly spaced, 3-D grid. Instead, we use frustum-shaped voxels (froxels), by using depth and capturing-setup dependent discretization of the view frustum. Based on such discretization, we count the number of rays mapping to the same pixel on the capturing device(s). By means of this count, we propose histograms of ray-counts over the froxels (fristograms). Fristograms can be used as a tool to analyze and reveal interesting aspects of the underlying LF, like the number of rays originating from a scene point and the color distribution of these rays. As an example, we show its ability by significantly reducing the number of rays which enables noise reduction while maintaining the realistic rendering of non-Lambertian or partially occluded regions.
HIDA: Towards Holistic Indoor Understanding for the Visually Impaired via Semantic Instance Segmentation with a Wearable Solid-State LiDAR Sensor
Jul 07, 2021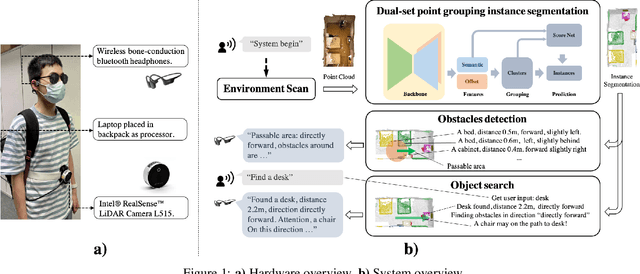
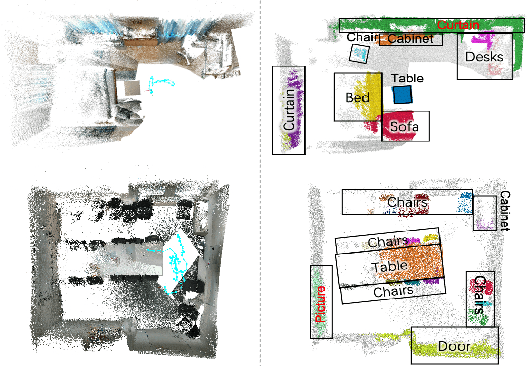
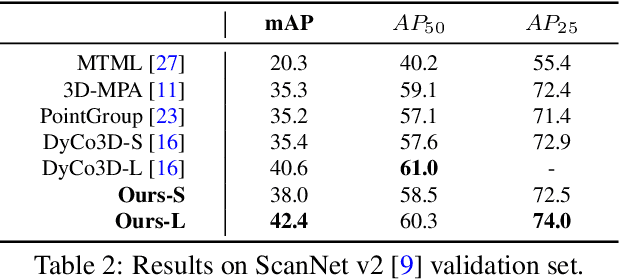
Independently exploring unknown spaces or finding objects in an indoor environment is a daily but challenging task for visually impaired people. However, common 2D assistive systems lack depth relationships between various objects, resulting in difficulty to obtain accurate spatial layout and relative positions of objects. To tackle these issues, we propose HIDA, a lightweight assistive system based on 3D point cloud instance segmentation with a solid-state LiDAR sensor, for holistic indoor detection and avoidance. Our entire system consists of three hardware components, two interactive functions~(obstacle avoidance and object finding) and a voice user interface. Based on voice guidance, the point cloud from the most recent state of the changing indoor environment is captured through an on-site scanning performed by the user. In addition, we design a point cloud segmentation model with dual lightweight decoders for semantic and offset predictions, which satisfies the efficiency of the whole system. After the 3D instance segmentation, we post-process the segmented point cloud by removing outliers and projecting all points onto a top-view 2D map representation. The system integrates the information above and interacts with users intuitively by acoustic feedback. The proposed 3D instance segmentation model has achieved state-of-the-art performance on ScanNet v2 dataset. Comprehensive field tests with various tasks in a user study verify the usability and effectiveness of our system for assisting visually impaired people in holistic indoor understanding, obstacle avoidance and object search.
Adaptive learning for financial markets mixing model-based and model-free RL for volatility targeting
Apr 22, 2021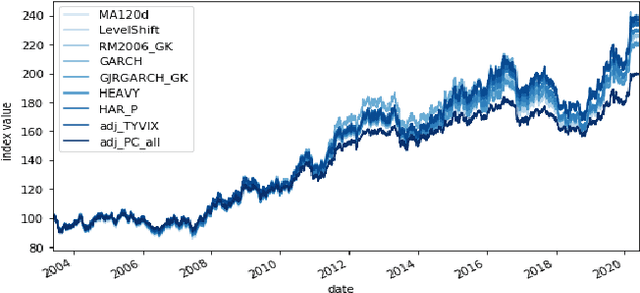
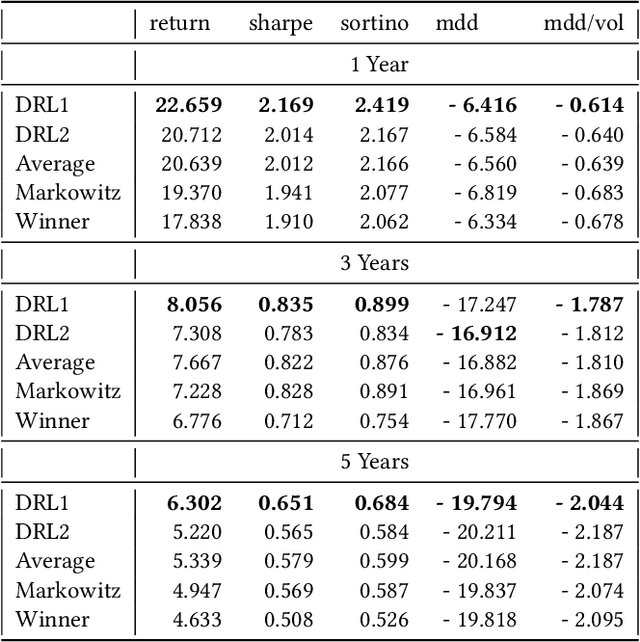
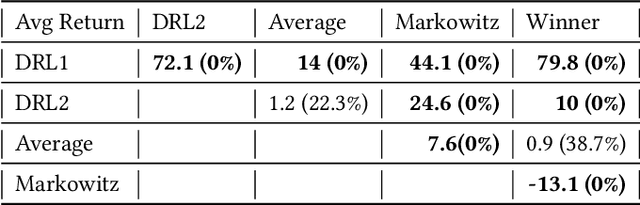
Model-Free Reinforcement Learning has achieved meaningful results in stable environments but, to this day, it remains problematic in regime changing environments like financial markets. In contrast, model-based RL is able to capture some fundamental and dynamical concepts of the environment but suffer from cognitive bias. In this work, we propose to combine the best of the two techniques by selecting various model-based approaches thanks to Model-Free Deep Reinforcement Learning. Using not only past performance and volatility, we include additional contextual information such as macro and risk appetite signals to account for implicit regime changes. We also adapt traditional RL methods to real-life situations by considering only past data for the training sets. Hence, we cannot use future information in our training data set as implied by K-fold cross validation. Building on traditional statistical methods, we use the traditional "walk-forward analysis", which is defined by successive training and testing based on expanding periods, to assert the robustness of the resulting agent. Finally, we present the concept of statistical difference's significance based on a two-tailed T-test, to highlight the ways in which our models differ from more traditional ones. Our experimental results show that our approach outperforms traditional financial baseline portfolio models such as the Markowitz model in almost all evaluation metrics commonly used in financial mathematics, namely net performance, Sharpe and Sortino ratios, maximum drawdown, maximum drawdown over volatility.
MeGA-CDA: Memory Guided Attention for Category-Aware Unsupervised Domain Adaptive Object Detection
Mar 07, 2021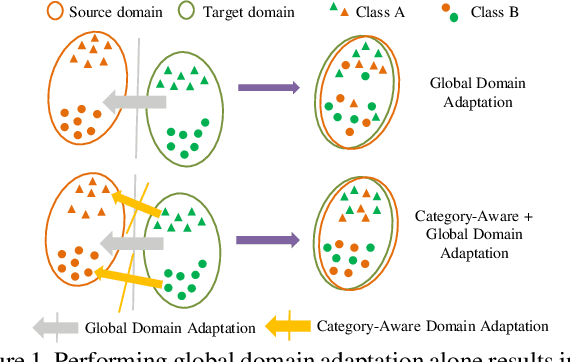
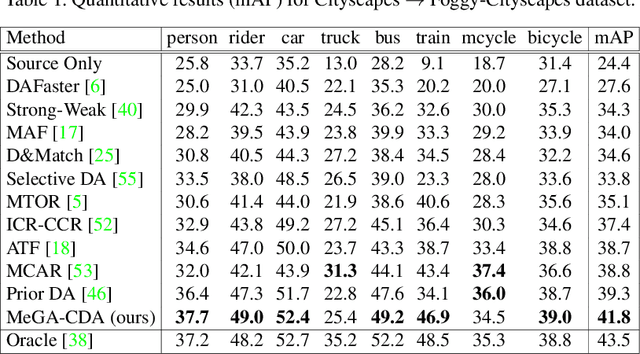
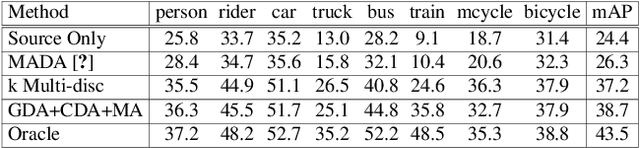
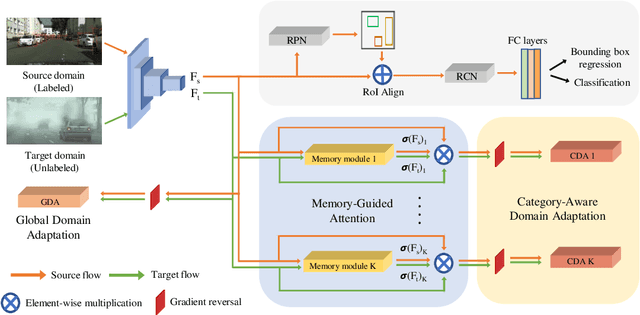
Existing approaches for unsupervised domain adaptive object detection perform feature alignment via adversarial training. While these methods achieve reasonable improvements in performance, they typically perform category-agnostic domain alignment, thereby resulting in negative transfer of features. To overcome this issue, in this work, we attempt to incorporate category information into the domain adaptation process by proposing Memory Guided Attention for Category-Aware Domain Adaptation (MeGA-CDA). The proposed method consists of employing category-wise discriminators to ensure category-aware feature alignment for learning domain-invariant discriminative features. However, since the category information is not available for the target samples, we propose to generate memory-guided category-specific attention maps which are then used to route the features appropriately to the corresponding category discriminator. The proposed method is evaluated on several benchmark datasets and is shown to outperform existing approaches.
Image Restoration for Remote Sensing: Overview and Toolbox
Jul 01, 2021


Remote sensing provides valuable information about objects or areas from a distance in either active (e.g., RADAR and LiDAR) or passive (e.g., multispectral and hyperspectral) modes. The quality of data acquired by remotely sensed imaging sensors (both active and passive) is often degraded by a variety of noise types and artifacts. Image restoration, which is a vibrant field of research in the remote sensing community, is the task of recovering the true unknown image from the degraded observed image. Each imaging sensor induces unique noise types and artifacts into the observed image. This fact has led to the expansion of restoration techniques in different paths according to each sensor type. This review paper brings together the advances of image restoration techniques with particular focuses on synthetic aperture radar and hyperspectral images as the most active sub-fields of image restoration in the remote sensing community. We, therefore, provide a comprehensive, discipline-specific starting point for researchers at different levels (i.e., students, researchers, and senior researchers) willing to investigate the vibrant topic of data restoration by supplying sufficient detail and references. Additionally, this review paper accompanies a toolbox to provide a platform to encourage interested students and researchers in the field to further explore the restoration techniques and fast-forward the community. The toolboxes are provided in https://github.com/ImageRestorationToolbox.
A Systematic Study of Leveraging Subword Information for Learning Word Representations
Apr 16, 2019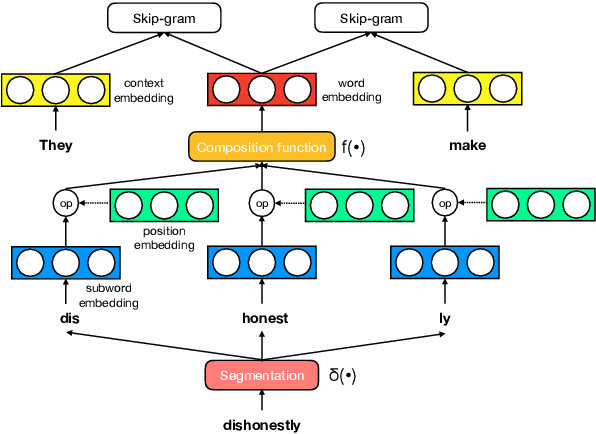
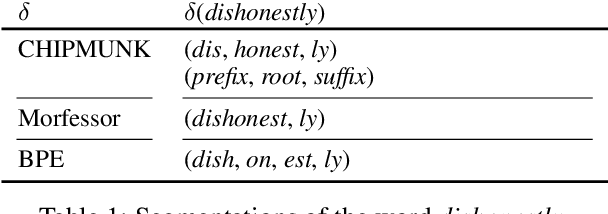
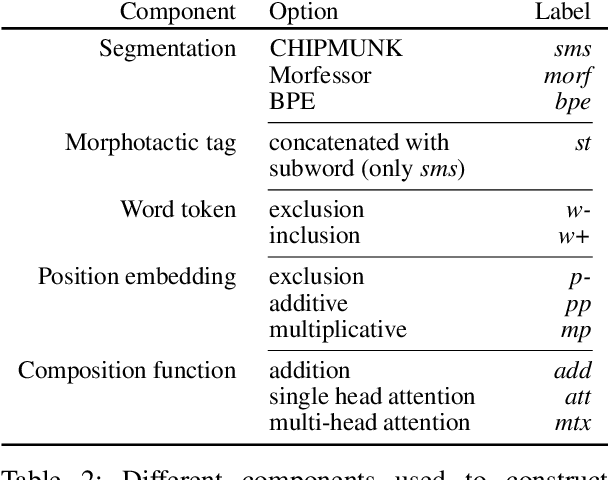
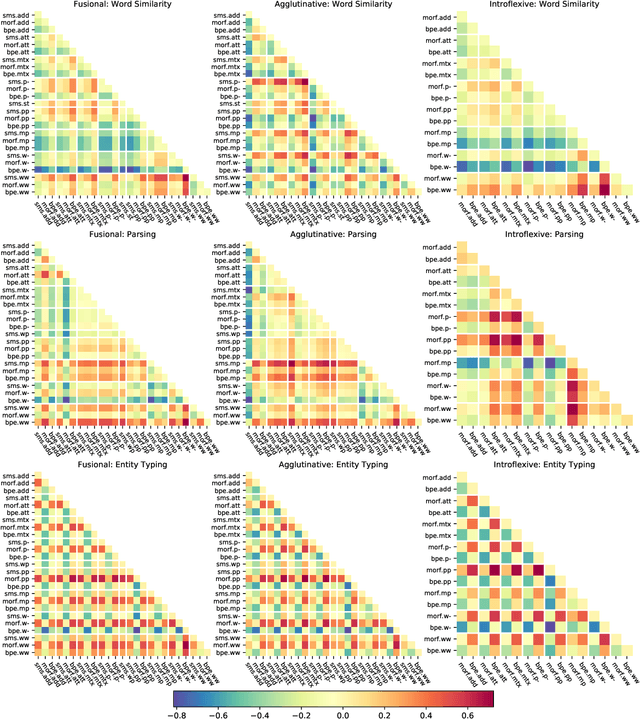
The use of subword-level information (e.g., characters, character n-grams, morphemes) has become ubiquitous in modern word representation learning. Its importance is attested especially for morphologically rich languages which generate a large number of rare words. Despite a steadily increasing interest in such subword-informed word representations, their systematic comparative analysis across typologically diverse languages and different tasks is still missing. In this work, we deliver such a study focusing on the variation of two crucial components required for subword-level integration into word representation models: 1) segmentation of words into subword units, and 2) subword composition functions to obtain final word representations. We propose a general framework for learning subword-informed word representations that allows for easy experimentation with different segmentation and composition components, also including more advanced techniques based on position embeddings and self-attention. Using the unified framework, we run experiments over a large number of subword-informed word representation configurations (60 in total) on 3 tasks (general and rare word similarity, dependency parsing, fine-grained entity typing) for 5 languages representing 3 language types. Our main results clearly indicate that there is no "one-sizefits-all" configuration, as performance is both language- and task-dependent. We also show that configurations based on unsupervised segmentation (e.g., BPE, Morfessor) are sometimes comparable to or even outperform the ones based on supervised word segmentation.
MlTr: Multi-label Classification with Transformer
Jun 11, 2021

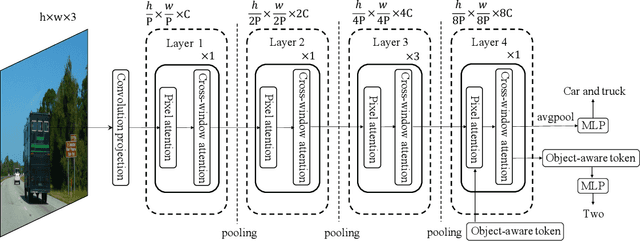
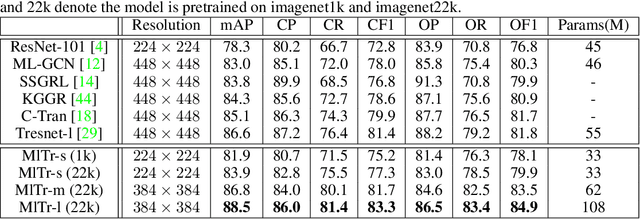
The task of multi-label image classification is to recognize all the object labels presented in an image. Though advancing for years, small objects, similar objects and objects with high conditional probability are still the main bottlenecks of previous convolutional neural network(CNN) based models, limited by convolutional kernels' representational capacity. Recent vision transformer networks utilize the self-attention mechanism to extract the feature of pixel granularity, which expresses richer local semantic information, while is insufficient for mining global spatial dependence. In this paper, we point out the three crucial problems that CNN-based methods encounter and explore the possibility of conducting specific transformer modules to settle them. We put forward a Multi-label Transformer architecture(MlTr) constructed with windows partitioning, in-window pixel attention, cross-window attention, particularly improving the performance of multi-label image classification tasks. The proposed MlTr shows state-of-the-art results on various prevalent multi-label datasets such as MS-COCO, Pascal-VOC, and NUS-WIDE with 88.5%, 95.8%, and 65.5% respectively. The code will be available soon at https://github.com/starmemda/MlTr/
Active Learning of Continuous-time Bayesian Networks through Interventions
Jun 11, 2021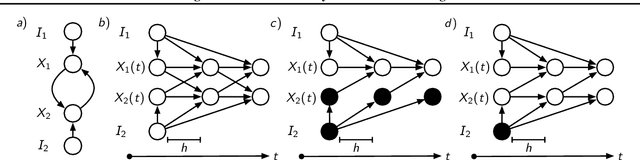
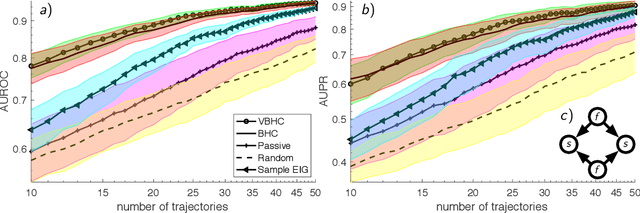
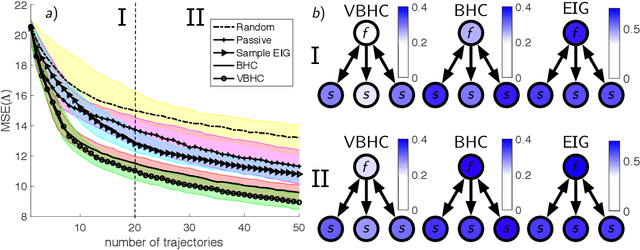
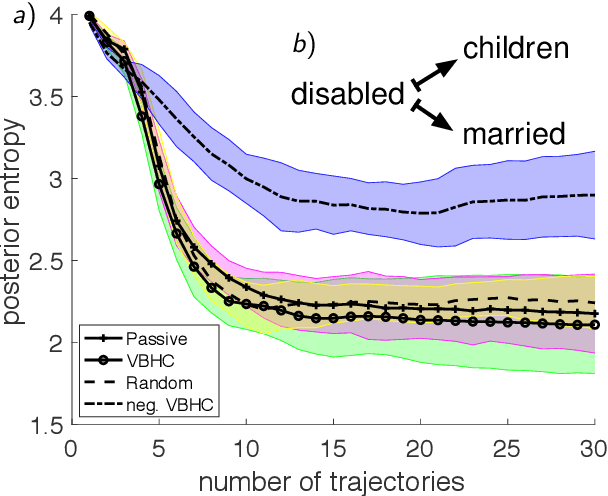
We consider the problem of learning structures and parameters of Continuous-time Bayesian Networks (CTBNs) from time-course data under minimal experimental resources. In practice, the cost of generating experimental data poses a bottleneck, especially in the natural and social sciences. A popular approach to overcome this is Bayesian optimal experimental design (BOED). However, BOED becomes infeasible in high-dimensional settings, as it involves integration over all possible experimental outcomes. We propose a novel criterion for experimental design based on a variational approximation of the expected information gain. We show that for CTBNs, a semi-analytical expression for this criterion can be calculated for structure and parameter learning. By doing so, we can replace sampling over experimental outcomes by solving the CTBNs master-equation, for which scalable approximations exist. This alleviates the computational burden of sampling possible experimental outcomes in high-dimensions. We employ this framework in order to recommend interventional sequences. In this context, we extend the CTBN model to conditional CTBNs in order to incorporate interventions. We demonstrate the performance of our criterion on synthetic and real-world data.
Leveraging Slot Descriptions for Zero-Shot Cross-Domain Dialogue State Tracking
May 10, 2021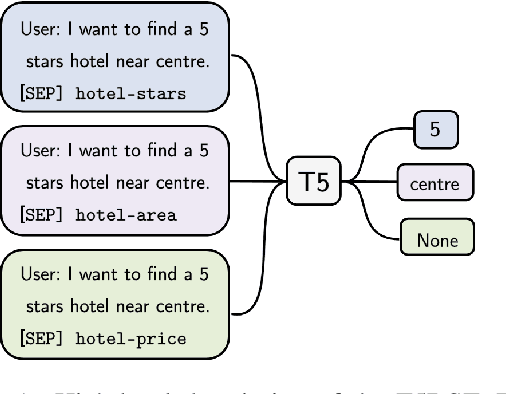
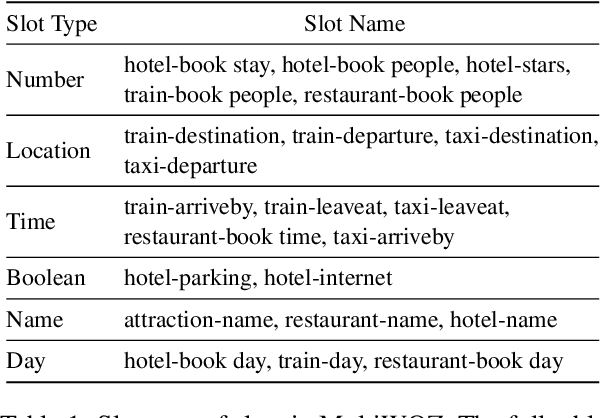

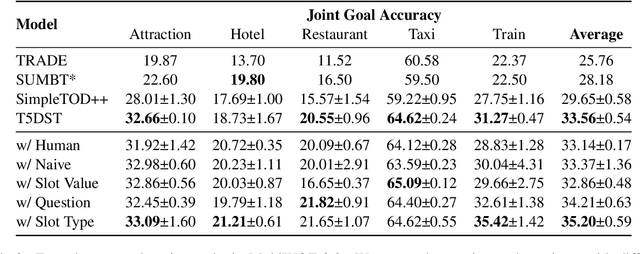
Zero-shot cross-domain dialogue state tracking (DST) enables us to handle task-oriented dialogue in unseen domains without the expense of collecting in-domain data. In this paper, we propose a slot description enhanced generative approach for zero-shot cross-domain DST. Specifically, our model first encodes dialogue context and slots with a pre-trained self-attentive encoder, and generates slot values in an auto-regressive manner. In addition, we incorporate Slot Type Informed Descriptions that capture the shared information across slots to facilitate cross-domain knowledge transfer. Experimental results on the MultiWOZ dataset show that our proposed method significantly improves existing state-of-the-art results in the zero-shot cross-domain setting.
Self-supervised Motion Learning from Static Images
Apr 01, 2021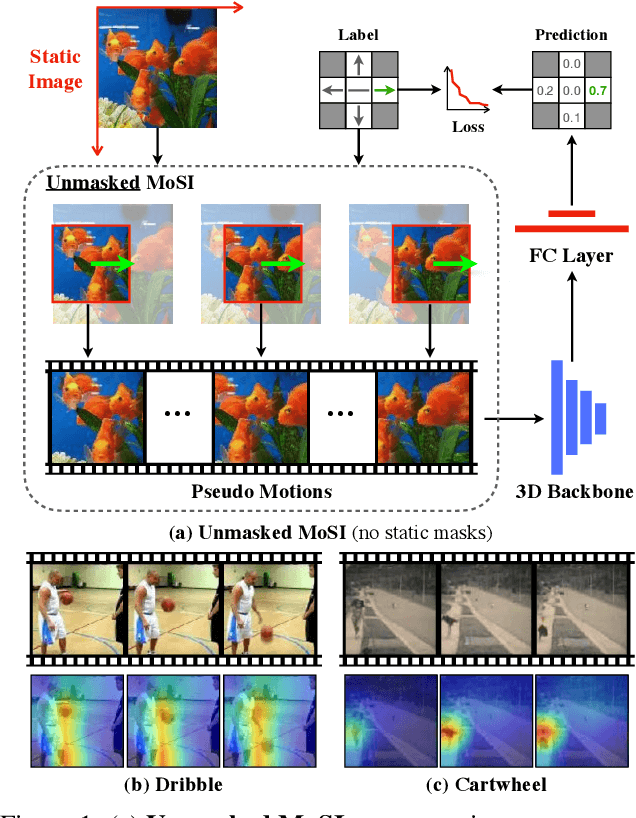
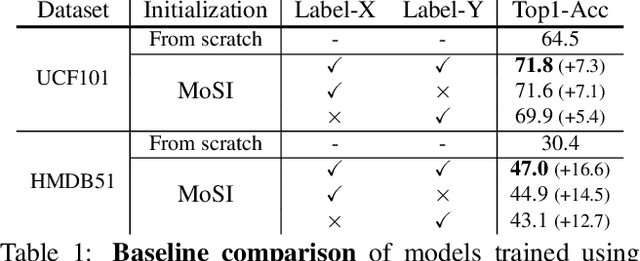
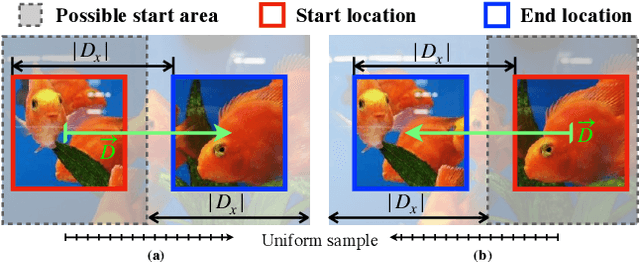
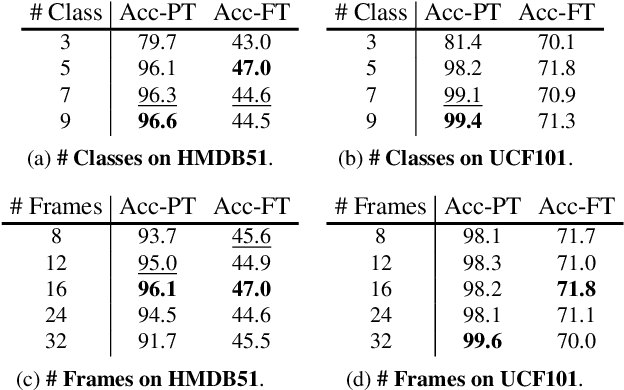
Motions are reflected in videos as the movement of pixels, and actions are essentially patterns of inconsistent motions between the foreground and the background. To well distinguish the actions, especially those with complicated spatio-temporal interactions, correctly locating the prominent motion areas is of crucial importance. However, most motion information in existing videos are difficult to label and training a model with good motion representations with supervision will thus require a large amount of human labour for annotation. In this paper, we address this problem by self-supervised learning. Specifically, we propose to learn Motion from Static Images (MoSI). The model learns to encode motion information by classifying pseudo motions generated by MoSI. We furthermore introduce a static mask in pseudo motions to create local motion patterns, which forces the model to additionally locate notable motion areas for the correct classification.We demonstrate that MoSI can discover regions with large motion even without fine-tuning on the downstream datasets. As a result, the learned motion representations boost the performance of tasks requiring understanding of complex scenes and motions, i.e., action recognition. Extensive experiments show the consistent and transferable improvements achieved by MoSI. Codes will be soon released.