 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUIDE: Interpretable GUI Agent Evaluation via Hierarchical Diagnosis
Apr 06, 2026Evaluating GUI agents presents a distinct challenge: trajectories are long, visually grounded, and open-ended, yet evaluation must be both accurate and interpretable. Existing approaches typically apply a single holistic judgment over the entire action-observation sequence-a strategy that proves unreliable on long-horizon tasks and yields binary verdicts offering no insight into where or why an agent fails. This opacity limits the utility of evaluation as a diagnostic tool for agent development. We introduce GUIDE (GUI Understanding and Interpretable Diagnostic Evaluation), a framework that decomposes trajectory assessment into three sequential stages mirroring the compositional structure of GUI tasks. Trajectory Segmentation partitions the full trace into semantically coherent subtask units. Subtask Diagnosis evaluates each unit in context, assigning a completion verdict and generating a structured error analysis with corrective recommendations. Overall Summary aggregates per-subtask diagnoses into a task-level judgment. By operating on bounded subtask segments rather than full trajectories, GUIDE mitigates the context overload that degrades existing evaluators as task complexity grows. We validate GUIDE on three benchmarks: an industrial e-commerce dataset of 932 trajectories, AGENTREWARDBENCH spanning five web agent tasks with 1302 trajectories, and AndroidBench for mobile device control. Across all settings, GUIDE substantially outperforms existing evaluators-achieving up to 5.35 percentage points higher accuracy than the strongest baseline-while producing structured diagnostic reports that directly inform agent improvement.
EchoTrail-GUI: Building Actionable Memory for GUI Agents via Critic-Guided Self-Exploration
Dec 22, 2025Contemporary GUI agents, while increasingly capable due to advances in Large Vision-Language Models (VLMs), often operate with a critical limitation: they treat each task in isolation, lacking a mechanism to systematically learn from past successes. This digital ''amnesia'' results in sub-optimal performance, repeated errors, and poor generalization to novel challenges. To bridge this gap, we introduce EchoTrail-GUI, a novel framework designed to mimic human-like experiential learning by equipping agents with a dynamic, accessible memory. Our framework operates in three distinct stages. First, during Experience Exploration, an agent autonomously interacts with GUI environments to build a curated database of successful task trajectories, validated by a reward model. Crucially, the entire knowledge base construction is thus fully automated, requiring no human supervision. Second, in the Memory Injection stage, upon receiving a new task, our system efficiently retrieves the most relevant past trajectories to serve as actionable ''memories''. Finally, during GUI Task Inference, these memories are injected as in-context guidance to inform the agent's reasoning and decision-making process. We demonstrate the efficacy of our approach on benchmarks including Android World and AndroidLab. The results show that EchoTrail-GUI significantly improves the task success rate and operational efficiency of baseline agents, validating the power of structured memory in creating more robust and intelligent GUI automation.
Decorate the Newcomers: Visual Domain Prompt for Continual Test Time Adaptation
Dec 08, 2022



Continual Test-Time Adaptation (CTTA) aims to adapt the source model to continually changing unlabeled target domains without access to the source data. Existing methods mainly focus on model-based adaptation in a self-training manner, such as predicting pseudo labels for new domain datasets. Since pseudo labels are noisy and unreliable, these methods suffer from catastrophic forgetting and error accumulation when dealing with dynamic data distributions. Motivated by the prompt learning in NLP, in this paper, we propose to learn an image-level visual domain prompt for target domains while having the source model parameters frozen. During testing, the changing target datasets can be adapted to the source model by reformulating the input data with the learned visual prompts. Specifically, we devise two types of prompts, i.e., domains-specific prompts and domains-agnostic prompts, to extract current domain knowledge and maintain the domain-shared knowledge in the continual adaptation. Furthermore, we design a homeostasis-based prompt adaptation strategy to suppress domain-sensitive parameters in domain-invariant prompts to learn domain-shared knowledge more effectively. This transition from the model-dependent paradigm to the model-free one enables us to bypass the catastrophic forgetting and error accumulation problems. Experiments show that our proposed method achieves significant performance gains over state-of-the-art methods on four widely-used benchmarks, including CIFAR-10C, CIFAR-100C, ImageNet-C, and VLCS datasets.
MlTr: Multi-label Classification with Transformer
Jun 11, 2021

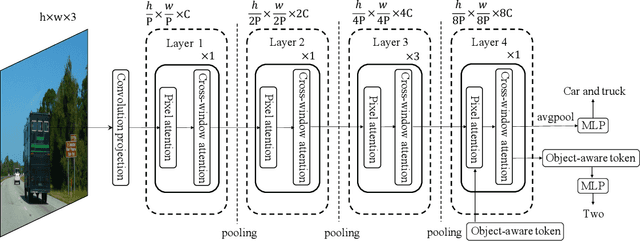
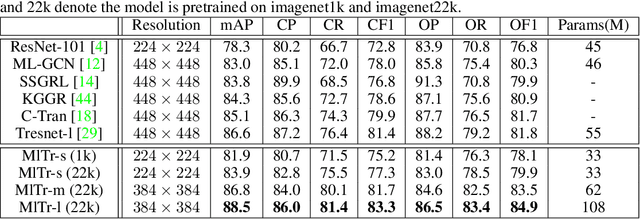
The task of multi-label image classification is to recognize all the object labels presented in an image. Though advancing for years, small objects, similar objects and objects with high conditional probability are still the main bottlenecks of previous convolutional neural network(CNN) based models, limited by convolutional kernels' representational capacity. Recent vision transformer networks utilize the self-attention mechanism to extract the feature of pixel granularity, which expresses richer local semantic information, while is insufficient for mining global spatial dependence. In this paper, we point out the three crucial problems that CNN-based methods encounter and explore the possibility of conducting specific transformer modules to settle them. We put forward a Multi-label Transformer architecture(MlTr) constructed with windows partitioning, in-window pixel attention, cross-window attention, particularly improving the performance of multi-label image classification tasks. The proposed MlTr shows state-of-the-art results on various prevalent multi-label datasets such as MS-COCO, Pascal-VOC, and NUS-WIDE with 88.5%, 95.8%, and 65.5% respectively. The code will be available soon at https://github.com/starmemda/MlTr/