 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Tracing Back Music Emotion Predictions to Sound Sources and Intuitive Perceptual Qualities
Jun 16, 2021
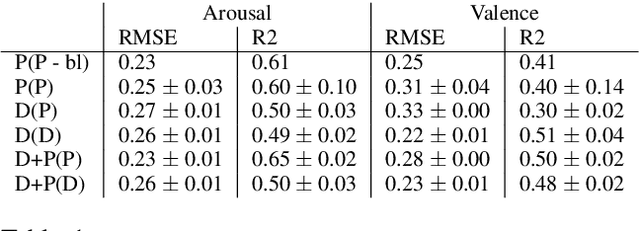
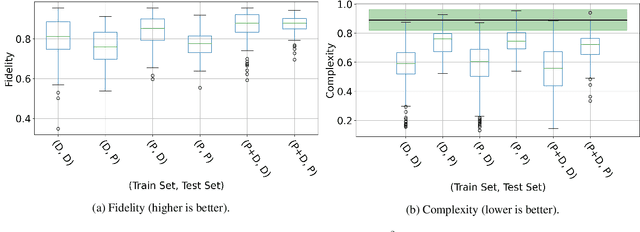
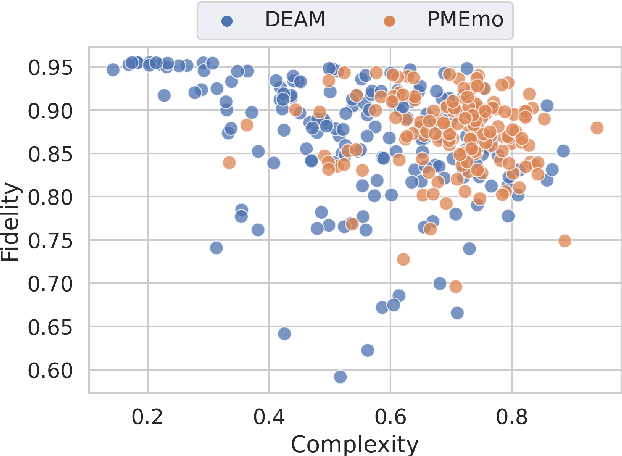
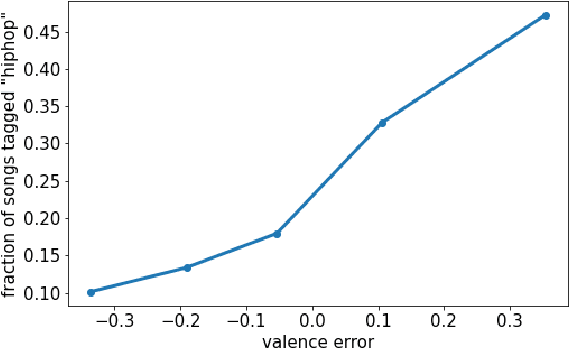
Music emotion recognition is an important task in MIR (Music Information Retrieval) research. Owing to factors like the subjective nature of the task and the variation of emotional cues between musical genres, there are still significant challenges in developing reliable and generalizable models. One important step towards better models would be to understand what a model is actually learning from the data and how the prediction for a particular input is made. In previous work, we have shown how to derive explanations of model predictions in terms of spectrogram image segments that connect to the high-level emotion prediction via a layer of easily interpretable perceptual features. However, that scheme lacks intuitive musical comprehensibility at the spectrogram level. In the present work, we bridge this gap by merging audioLIME -- a source-separation based explainer -- with mid-level perceptual features, thus forming an intuitive connection chain between the input audio and the output emotion predictions. We demonstrate the usefulness of this method by applying it to debug a biased emotion prediction model.
DeepSurfels: Learning Online Appearance Fusion
Dec 28, 2020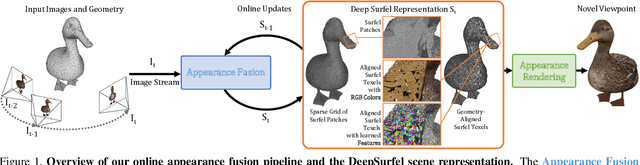
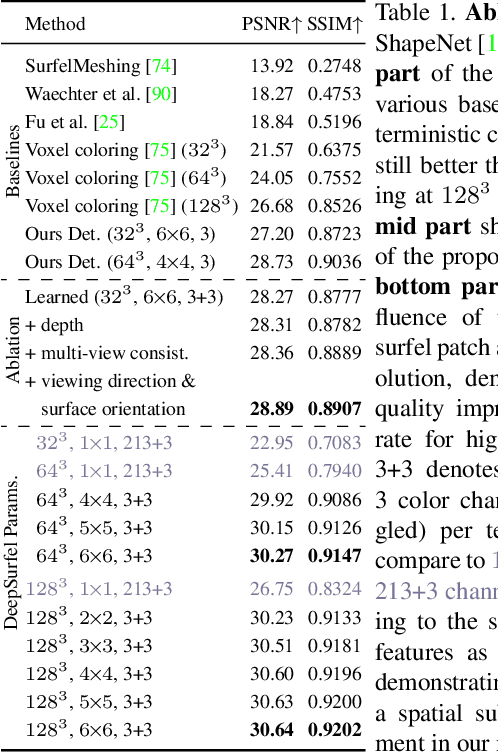

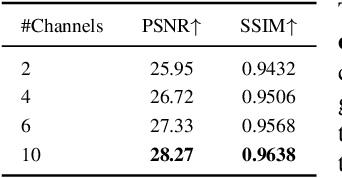
We present DeepSurfels, a novel hybrid scene representation for geometry and appearance information. DeepSurfels combines explicit and neural building blocks to jointly encode geometry and appearance information. In contrast to established representations, DeepSurfels better represents high-frequency textures, is well-suited for online updates of appearance information, and can be easily combined with machine learning methods. We further present an end-to-end trainable online appearance fusion pipeline that fuses information provided by RGB images into the proposed scene representation and is trained using self-supervision imposed by the reprojection error with respect to the input images. Our method compares favorably to classical texture mapping approaches as well as recently proposed learning-based techniques. Moreover, we demonstrate lower runtime, improved generalization capabilities, and better scalability to larger scenes compared to existing methods.
Dependency Parsing based Semantic Representation Learning with Graph Neural Network for Enhancing Expressiveness of Text-to-Speech
Apr 14, 2021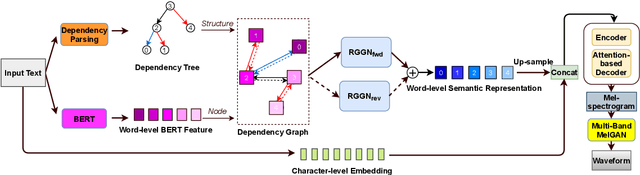

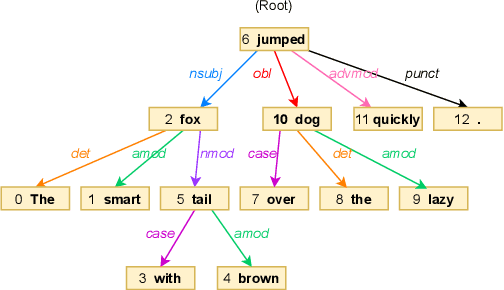
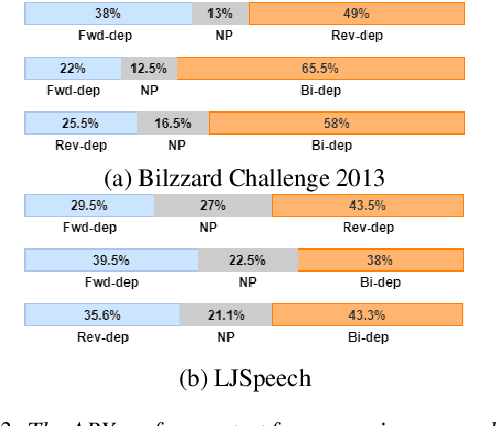
Semantic information of a sentence is crucial for improving the expressiveness of a text-to-speech (TTS) system, but can not be well learned from the limited training TTS dataset just by virtue of the nowadays encoder structures. As large scale pre-trained text representation develops, bidirectional encoder representations from transformers (BERT) has been proven to embody text-context semantic information and applied to TTS as additional input. However BERT can not explicitly associate semantic tokens from point of dependency relations in a sentence. In this paper, to enhance expressiveness, we propose a semantic representation learning method based on graph neural network, considering dependency relations of a sentence. Dependency graph of input text is composed of edges from dependency tree structure considering both the forward and the reverse directions. Semantic representations are then extracted at word level by the relational gated graph network (RGGN) fed with features from BERT as nodes input. Upsampled semantic representations and character-level embeddings are concatenated to serve as the encoder input of Tacotron-2. Experimental results show that our proposed method outperforms the baseline using vanilla BERT features both in LJSpeech and Bilzzard Challenge 2013 datasets, and semantic representations learned from the reverse direction are more effective for enhancing expressiveness.
Explainable Machine Learning with Prior Knowledge: An Overview
May 21, 2021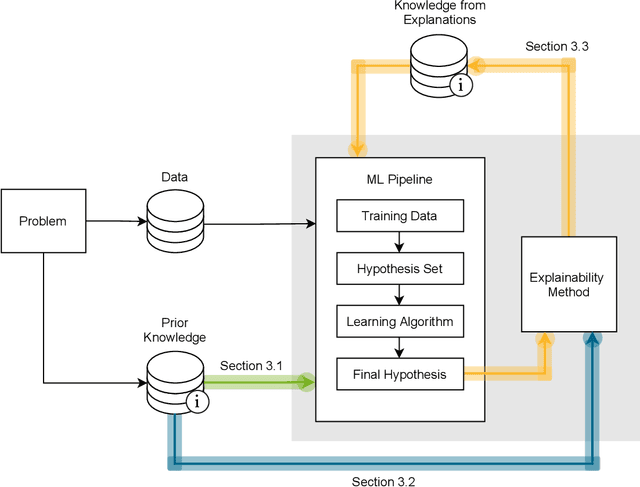

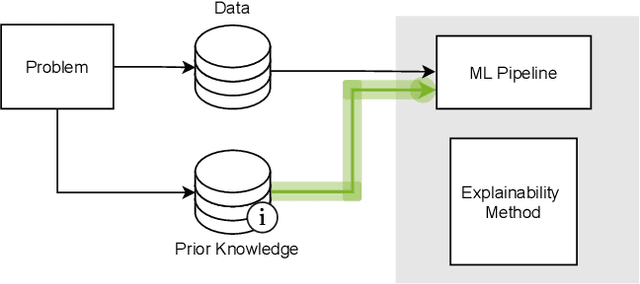
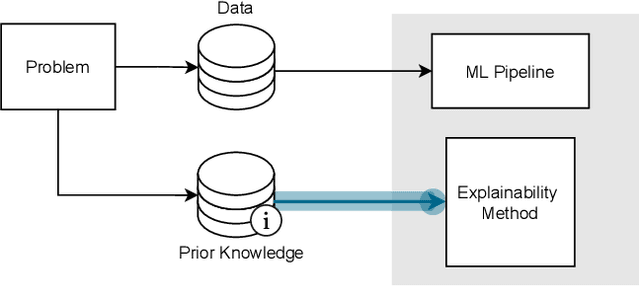
This survey presents an overview of integrating prior knowledge into machine learning systems in order to improve explainability. The complexity of machine learning models has elicited research to make them more explainable. However, most explainability methods cannot provide insight beyond the given data, requiring additional information about the context. We propose to harness prior knowledge to improve upon the explanation capabilities of machine learning models. In this paper, we present a categorization of current research into three main categories which either integrate knowledge into the machine learning pipeline, into the explainability method or derive knowledge from explanations. To classify the papers, we build upon the existing taxonomy of informed machine learning and extend it from the perspective of explainability. We conclude with open challenges and research directions.
Autonomous Navigation System for a Delivery Drone
Jun 16, 2021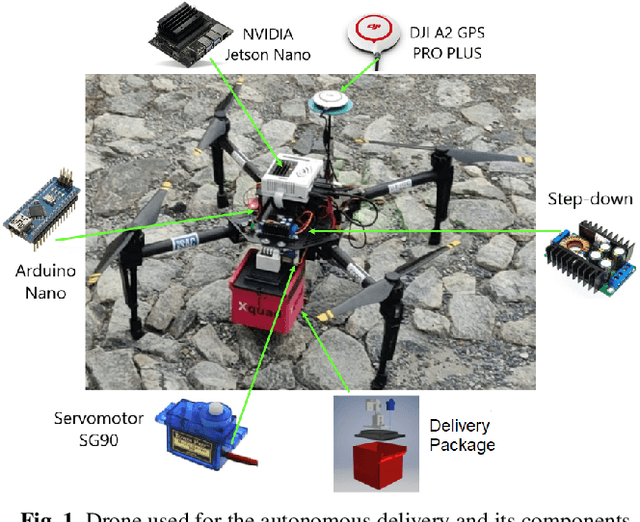

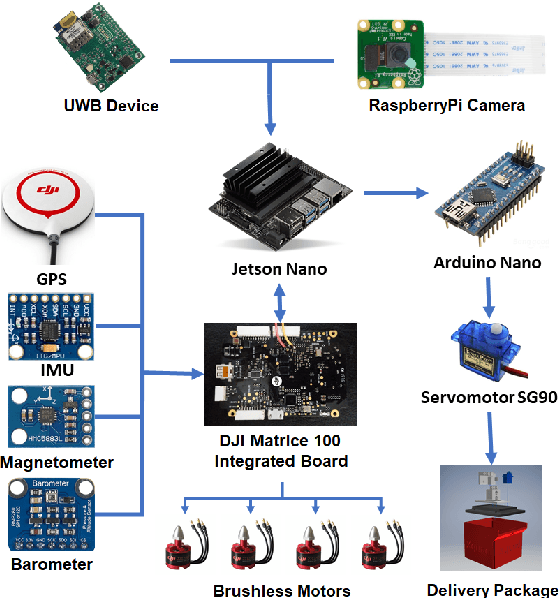
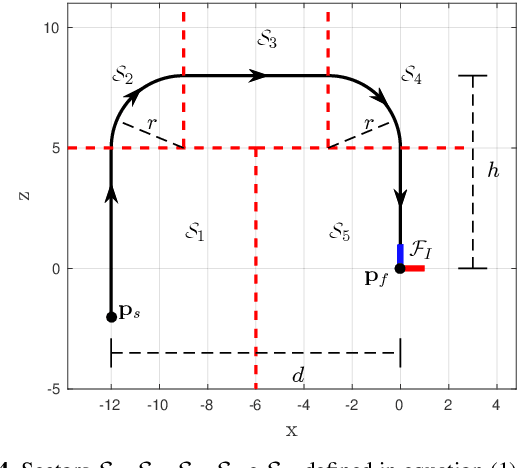
The use of delivery services is an increasing trend worldwide, further enhanced by the COVID pandemic. In this context, drone delivery systems are of great interest as they may allow for faster and cheaper deliveries. This paper presents a navigation system that makes feasible the delivery of parcels with autonomous drones. The system generates a path between a start and a final point and controls the drone to follow this path based on its localization obtained through GPS, 9DoF IMU, and barometer. In the landing phase, information of poses estimated by a marker (ArUco) detection technique using a camera, ultra-wideband (UWB) devices, and the drone's software estimation are merged by utilizing an Extended Kalman Filter algorithm to improve the landing precision. A vector field-based method controls the drone to follow the desired path smoothly, reducing vibrations or harsh movements that could harm the transported parcel. Real experiments validate the delivery strategy and allow to evaluate the performance of the adopted techniques. Preliminary results state the viability of our proposal for autonomous drone delivery.
Voicy: Zero-Shot Non-Parallel Voice Conversion in Noisy Reverberant Environments
Jun 16, 2021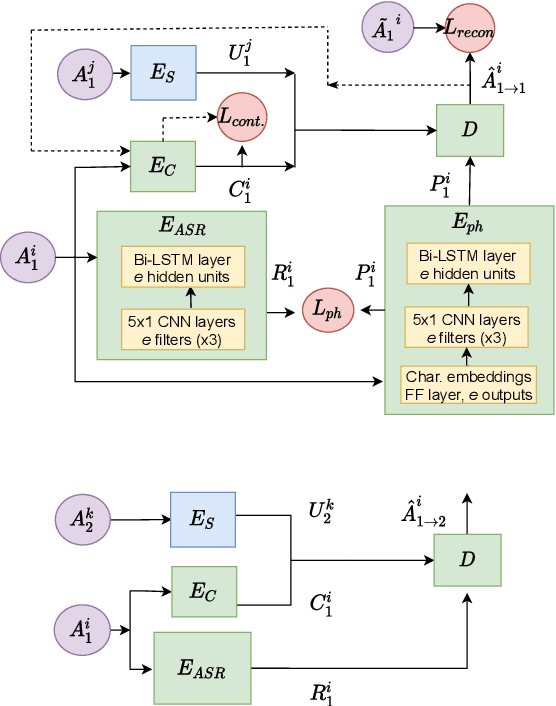
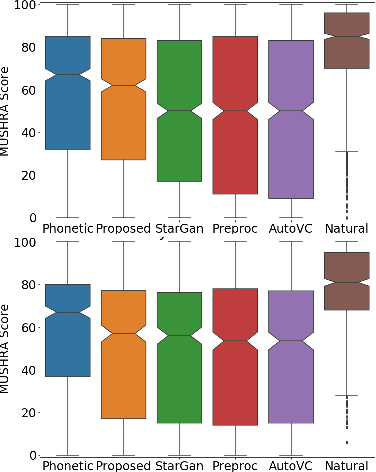
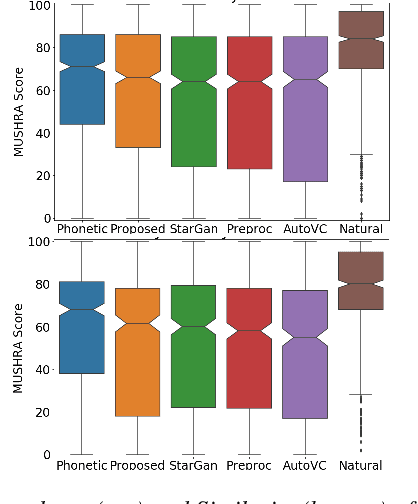
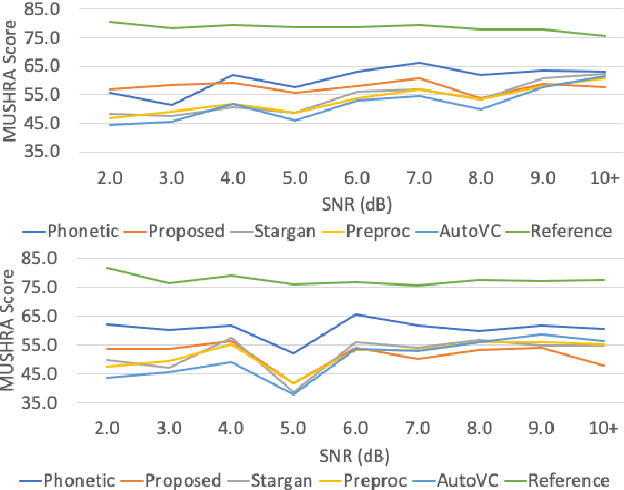
Voice Conversion (VC) is a technique that aims to transform the non-linguistic information of a source utterance to change the perceived identity of the speaker. While there is a rich literature on VC, most proposed methods are trained and evaluated on clean speech recordings. However, many acoustic environments are noisy and reverberant, severely restricting the applicability of popular VC methods to such scenarios. To address this limitation, we propose Voicy, a new VC framework particularly tailored for noisy speech. Our method, which is inspired by the de-noising auto-encoders framework, is comprised of four encoders (speaker, content, phonetic and acoustic-ASR) and one decoder. Importantly, Voicy is capable of performing non-parallel zero-shot VC, an important requirement for any VC system that needs to work on speakers not seen during training. We have validated our approach using a noisy reverberant version of the LibriSpeech dataset. Experimental results show that Voicy outperforms other tested VC techniques in terms of naturalness and target speaker similarity in noisy reverberant environments.
Parameter-efficient Multi-task Fine-tuning for Transformers via Shared Hypernetworks
Jun 08, 2021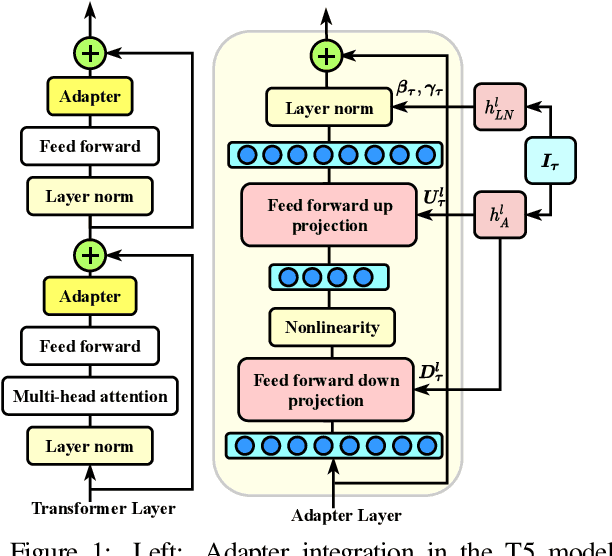
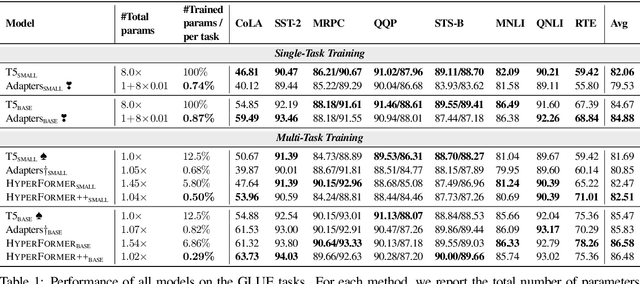
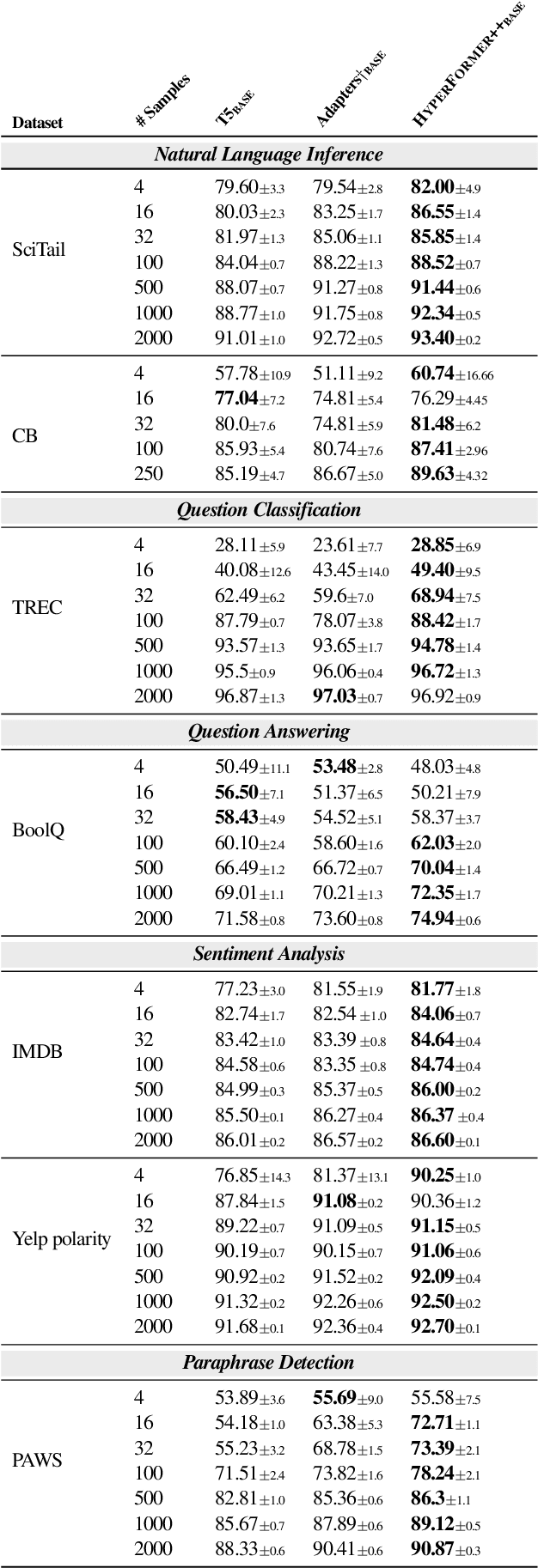
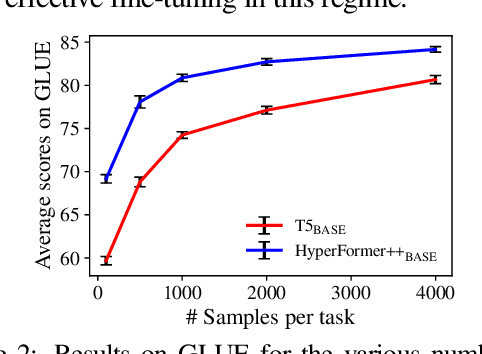
State-of-the-art parameter-efficient fine-tuning methods rely on introducing adapter modules between the layers of a pretrained language model. However, such modules are trained separately for each task and thus do not enable sharing information across tasks. In this paper, we show that we can learn adapter parameters for all layers and tasks by generating them using shared hypernetworks, which condition on task, adapter position, and layer id in a transformer model. This parameter-efficient multi-task learning framework allows us to achieve the best of both worlds by sharing knowledge across tasks via hypernetworks while enabling the model to adapt to each individual task through task-specific adapters. Experiments on the well-known GLUE benchmark show improved performance in multi-task learning while adding only 0.29% parameters per task. We additionally demonstrate substantial performance improvements in few-shot domain generalization across a variety of tasks. Our code is publicly available in https://github.com/rabeehk/hyperformer.
Visual Transformer with Statistical Test for COVID-19 Classification
Jul 12, 2021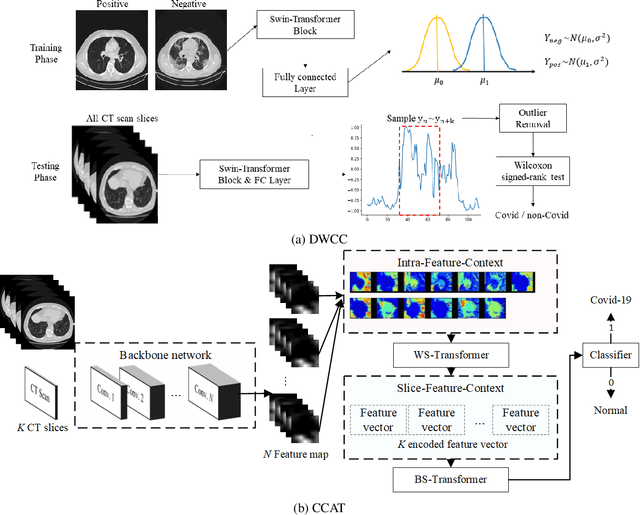
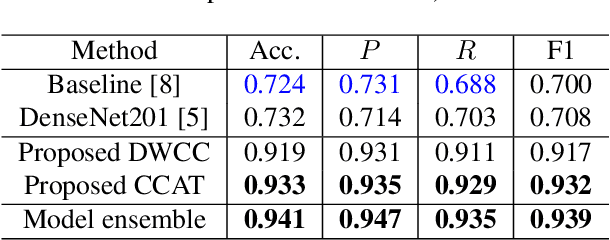
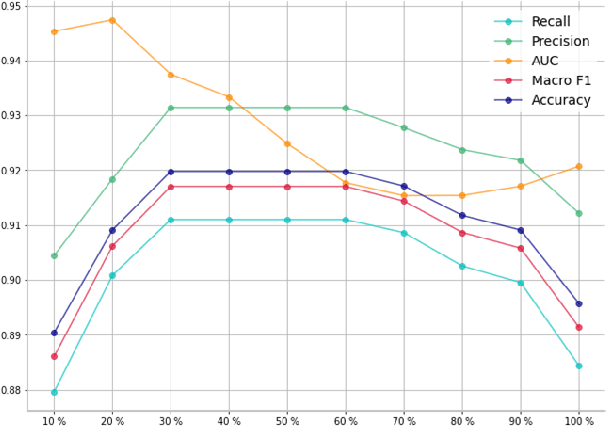
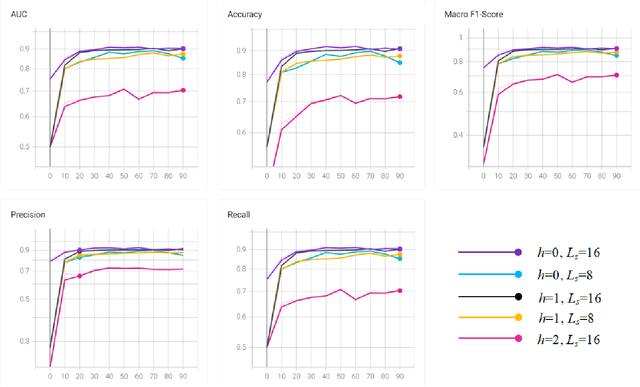
With the massive damage in the world caused by Coronavirus Disease 2019 SARS-CoV-2 (COVID-19), many related research topics have been proposed in the past two years. The Chest Computed Tomography (CT) scans are the most valuable materials to diagnose the COVID-19 symptoms. However, most schemes for COVID-19 classification of Chest CT scan is based on a single-slice level, implying that the most critical CT slice should be selected from the original CT scan volume manually. We simultaneously propose 2-D and 3-D models to predict the COVID-19 of CT scan to tickle this issue. In our 2-D model, we introduce the Deep Wilcoxon signed-rank test (DWCC) to determine the importance of each slice of a CT scan to overcome the issue mentioned previously. Furthermore, a Convolutional CT scan-Aware Transformer (CCAT) is proposed to discover the context of the slices fully. The frame-level feature is extracted from each CT slice based on any backbone network and followed by feeding the features to our within-slice-Transformer (WST) to discover the context information in the pixel dimension. The proposed Between-Slice-Transformer (BST) is used to aggregate the extracted spatial-context features of every CT slice. A simple classifier is then used to judge whether the Spatio-temporal features are COVID-19 or non-COVID-19. The extensive experiments demonstrated that the proposed CCAT and DWCC significantly outperform the state-of-the-art methods.
Reading StackOverflow Encourages Cheating: Adding Question Text Improves Extractive Code Generation
Jun 08, 2021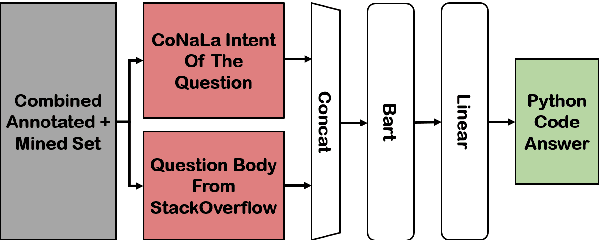

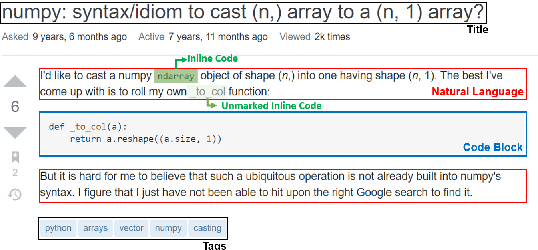

Answering a programming question using only its title is difficult as salient contextual information is omitted. Based on this observation, we present a corpus of over 40,000 StackOverflow question texts to be used in conjunction with their corresponding intents from the CoNaLa dataset (Yin et al., 2018). Using both the intent and question body, we use BART to establish a baseline BLEU score of 34.35 for this new task. We find further improvements of $2.8\%$ by combining the mined CoNaLa data with the labeled data to achieve a 35.32 BLEU score. We evaluate prior state-of-the-art CoNaLa models with this additional data and find that our proposed method of using the body and mined data beats the BLEU score of the prior state-of-the-art by $71.96\%$. Finally, we perform ablations to demonstrate that BART is an unsupervised multimodal learner and examine its extractive behavior. The code and data can be found https://github.com/gabeorlanski/stackoverflow-encourages-cheating.
Knowledge-Base Enriched Word Embeddings for Biomedical Domain
Feb 20, 2021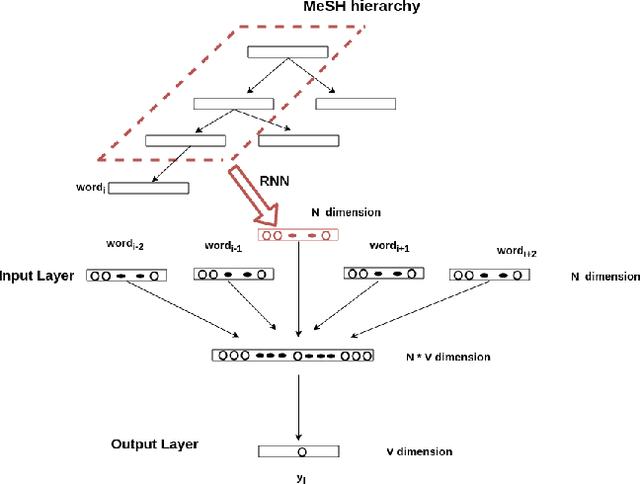


Word embeddings have been shown adept at capturing the semantic and syntactic regularities of the natural language text, as a result of which these representations have found their utility in a wide variety of downstream content analysis tasks. Commonly, these word embedding techniques derive the distributed representation of words based on the local context information. However, such approaches ignore the rich amount of explicit information present in knowledge-bases. This is problematic, as it might lead to poor representation for words with insufficient local context such as domain specific words. Furthermore, the problem becomes pronounced in domain such as bio-medicine where the presence of these domain specific words are relatively high. Towards this end, in this project, we propose a new word embedding based model for biomedical domain that jointly leverages the information from available corpora and domain knowledge in order to generate knowledge-base powered embeddings. Unlike existing approaches, the proposed methodology is simple but adept at capturing the precise knowledge available in domain resources in an accurate way. Experimental results on biomedical concept similarity and relatedness task validates the effectiveness of the proposed approach.